PyTorch框架學習五——影象預處理transforms(一)
PyTorch框架學習五——影象預處理transforms(一)
一、transforms執行機制 機製
介紹transforms之前先簡單介紹一下torchvision。
torchvision是PyTorch的計算機視覺工具包,包含了一些與CV相關的處理。有三個需要重要介紹:
- torchvision.transforms:包含了常用的影象預處理方法,如數據中心化、標準化、縮放、裁剪等。
- torchvision.datasets:包含了常用數據集的dataset實現,如MNIST、CIFAR-10、ImageNet等。
- torchvision.model:包含了常用的預訓練模型,如AlexNet、VGG、ResNet、GoogleNet等。
在transforms中除了具體的預處理方法之外,有一個Compose操作,這裏提前介紹,它可以將一系列transforms操作有序地組合包裝,以此按順序執行每一項操作。
torchvision.transforms.Compose(transforms)
參數:

如:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
二、transforms的具體方法
transforms的操作一般的目的是爲了影象預處理和數據增強,所謂數據增強,又稱數據增廣、數據擴增,它是對訓練集進行變換,使訓練集更豐富,從而讓模型更具泛化能力。下面 下麪將介紹二十多種具體的transforms的方法。
1.裁剪
(1)隨機裁剪:transforms.RandomCrop()
功能:從圖片中隨機裁剪出尺寸爲size的部分,影象可以是PIL格式或者是張量。
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
參數如下:

- size:(序列或int)若爲int,則是(size,size)的大小,若爲序列如(h,w),則大小爲(h,w)。
- padding:(序列或int,可選)預設爲None,當爲整數a時,上下左右的邊均要填充a個畫素;當爲(a, b)時,上下兩邊填充b個畫素,左右兩邊填充a個;當爲(a, b, c, d)時,左、上、右、下分別填充a、b、c、d個畫素。
- pad_if_need:(布爾型)如果輸入的影象尺寸小於要裁剪的尺寸size,則填充,以防報錯。
- fill:padding_mode中constant模式時設定填充的畫素值,預設爲0。
- padding_mode:填充模式,有四種,constant、edge、reflect和symmetric,預設爲constant,而且目前symmetric模式不支援輸入爲張量(Tensor)。constant模式:畫素值由fill設定;edge模式:由影象邊緣畫素決定;reflect模式:映象填充,最後一個畫素不映象,如[1, 2, 3, 4]→[3, 2, 1, 2, 3, 4, 3, 2];symmetric模式:映象填充,最後一個畫素也映象,如[1, 2, 3, 4]→[2, 1, 1, 2, 3, 4, 4, 3]。
下面 下麪看一下隨機裁剪的幾個例子及其效果,變換前圖片的原始尺寸爲224×224,如下圖所示:

(1)隨機裁剪尺寸爲224,padding=16,即四邊都填充16個畫素,就是在256×256的範圍隨機裁剪224×224的大小,效果如下圖所示:
transforms.RandomCrop(224, padding=16)

(2)隨機裁剪尺寸爲224,padding=(16, 64),即左右填充16個畫素,上下填充64個畫素,就是在256×352 的範圍隨機裁剪224×224的大小,效果如下圖所示:
transforms.RandomCrop(224, padding=(16, 64))

(3)與(1)不同之處就在於畫素的填充,這裏設定了填充的畫素值爲(255, 0, 0),效果如下圖所示:
transforms.RandomCrop(224, padding=16, fill=(255, 0, 0))

(4)隨機裁剪的尺寸爲512,大於原始影象的尺寸224,所以pad_if_needed必須設定爲True來進行自動填充,擴大尺寸(填充是隨機的),效果如下圖所示:
transforms.RandomCrop(512, pad_if_needed=True)
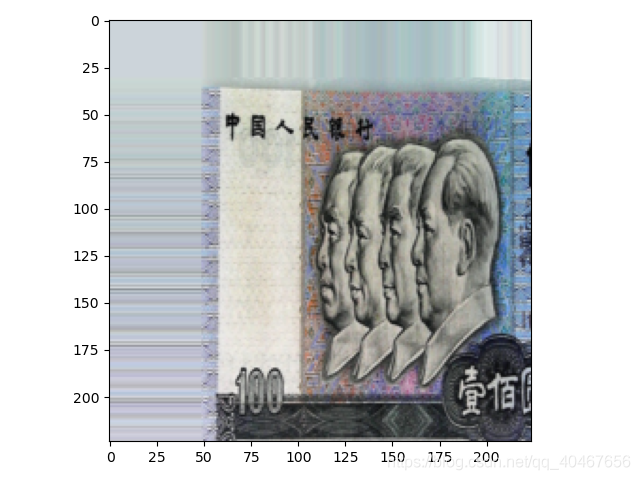
(5)與(1)或(3)不同的是,填充模式設定爲‘edge’,效果如下圖所示:
transforms.RandomCrop(224, padding=64, padding_mode='edge')
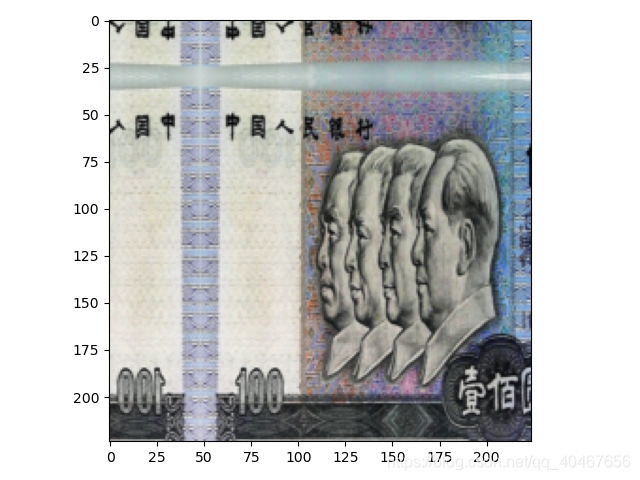
(6)與(1)或(3)或(5)不同的是,填充模式設定爲 ‘reflect’ ,效果如下圖所示:
transforms.RandomCrop(224, padding=64, padding_mode='reflect')
(7)最後看一個綜合一點的:
transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric')
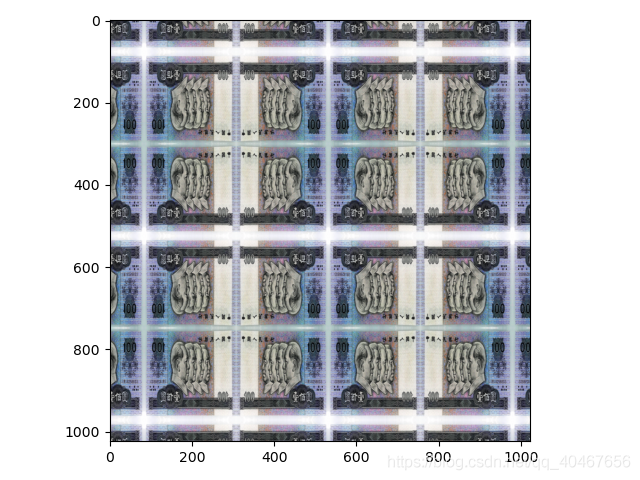
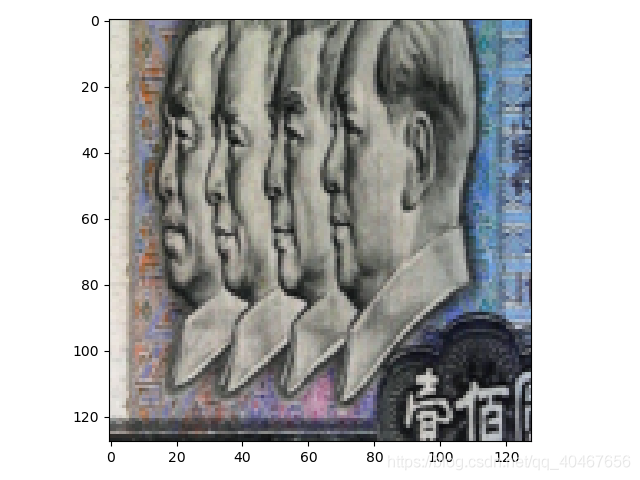
(2)中心裁剪:transforms.CenterCrop()
功能:從影象中心裁剪圖片,圖片可以是PIL格式或是張量。
torchvision.transforms.CenterCrop(size)

例子如下:
transforms.CenterCrop(128)
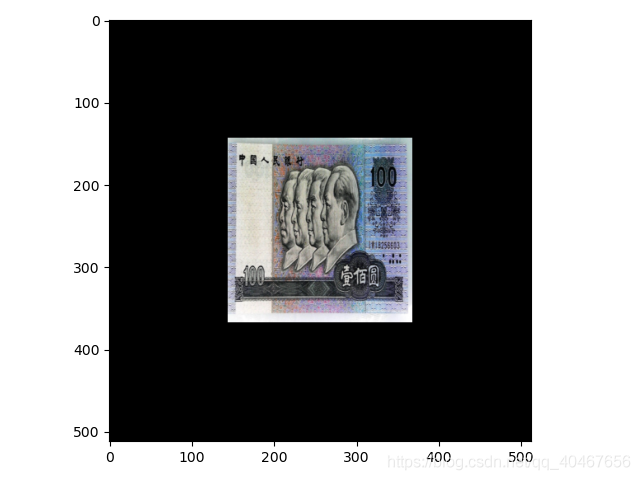
transforms.CenterCrop(512)
(3)隨機長寬比裁剪:transforms.RandomCrop()
功能:隨機大小、長寬比裁剪圖片,圖片可以是PIL格式或是張量。
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
參數如下:

- size:同上。
- scale:隨機裁剪的大小區間,如scale=(0.08, 1.0),即隨機裁剪出的圖片面積會在原始面積的0.08倍至1.0倍之間。
- ratio:隨機長寬比的範圍,預設爲(3/4,4/3)。
- interpolation:插值方法,有三種,分別爲PIL.Image.NEAREST、PIL.Image.BILINEAR、PIL.Image.BICUBIC,預設爲PIL.Image.BILINEAR。
例子如下:裁剪出來的部分是原來部分面積的0.5倍,但是大小又必須爲224不變,所以用了默認了插值方法PIL.Image.BILINEAR。
transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5))

(4)上下左右中心裁剪:transforms.FiveCrop()
功能:對給定影象的四個角以及中心進行裁剪,圖片可以是PIL格式或是張量,返回一個包含五個元素的元組(tuple),一般都要緊跟一個將元組轉變爲張量的操作,而且還要注意前後程式碼尺寸上的匹配。
torchvision.transforms.FiveCrop(size)
參數size同上。
例子如下,緊跟了一個將元組變換爲張量的操作:
transforms.FiveCrop(112),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),

(5)上下左右中心裁剪後翻轉:transforms.TenCrop()
功能:在影象(PIL格式或者是張量)的上下左右四個角以及中心裁剪出尺寸爲size的5張圖片,TenCrop對這5張圖片進行水平或垂直映象從而獲得10張圖片。
torchvision.transforms.TenCrop(size, vertical_flip=False)
參數如下:

- size:同上。
- vertical_flip:設定爲True時,會垂直翻轉,爲False時,會水平翻轉,預設爲False。
transforms.TenCrop(112, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),

2.翻轉、旋轉
(1)依概率p水平翻轉:transforms.RandomHorizontalFlip()
功能:依概率水平翻轉,輸入影象爲PIL格式或是張量。
torchvision.transforms.RandomHorizontalFlip(p=0.5)
參數:

例子如下:
transforms.RandomHorizontalFlip(p=1)

(2)依概率p垂直翻轉:transforms.RandomVerticalFlip()
功能:依概率垂直翻轉,輸入影象爲PIL格式或是張量。
torchvision.transforms.RandomVerticalFlip(p=0.5)

例子如下:
transforms.RandomVerticalFlip(p=1)

(3)隨機旋轉:transforms.RandomRotation()
功能:隨機旋轉圖片。
torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None)
參數如下:

- degrees:旋轉的角度,當爲a時,在(-a, a)之間選擇旋轉角度;當爲(a, b)時,在(a, b)之間選擇角度。
- resample:(可選)重採樣方法(以後細學)。
- expand:(布爾,可選)若爲True,則會自動擴大輸出尺寸,以保證原圖資訊不丟失;若爲False或省略,輸出尺寸保持和輸入一致。
- center:(可選)旋轉中心,以左上角爲原點(0,0),預設旋轉中心爲影象中心點。
- fill:畫素填充值,預設爲0,只支援pillow>=5.2.0版本。
注意:expand的計算公式是針對中心點旋轉的,若設定爲左上角旋轉或者其他點爲旋轉中心,則不能保證保持原圖資訊。
下面 下麪看幾個例子:
(1)中心點旋轉,範圍(-90度,90度):
transforms.RandomRotation(90)

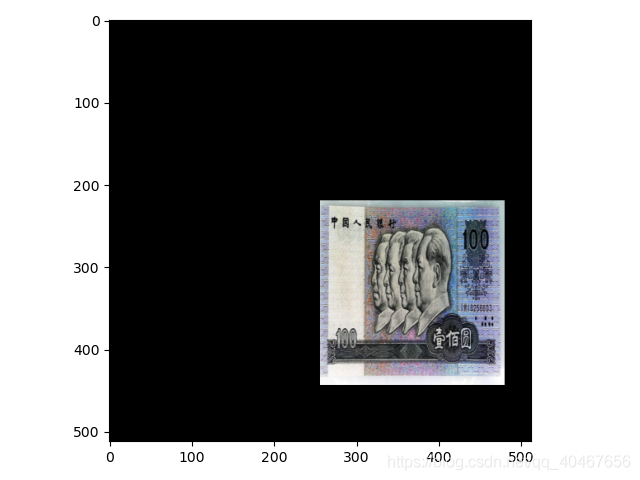
(2)設定expand保持原圖資訊,影象尺寸自動擴大:
transforms.RandomRotation((90), expand=True)

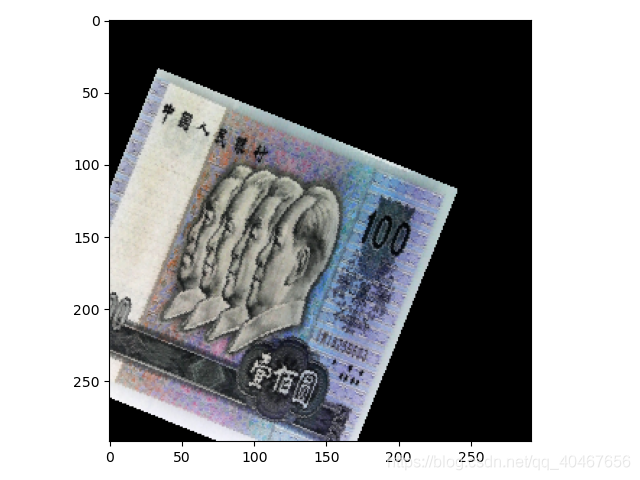
(3)旋轉中心改爲左上角:
transforms.RandomRotation(30, center=(0, 0))

(4)旋轉中心爲左上角並進行expand:
transforms.RandomRotation(30, center=(0, 0), expand=True)
結果不能保證保持原圖資訊: