數據結構與演算法--圖的定義及儲存結構
一、圖的定義和術語
1.圖的定義
圖: G=(V,E)
V: 頂點(數據元素)的有窮非空集合
E: 邊的有窮集合
1) 無向圖: 每條邊都是無方向的
2) 有向圖: 每條邊都是有方向的
3) 完全圖: 任意兩個點都有一條邊相連

4) 稀疏圖: 有很少邊或弧的圖(e<nlogn)
5) 稠密圖: 有較多邊或弧的圖
6) 網: 邊/弧帶權的圖
7) 鄰接: 有邊/弧相連的兩個頂點之間的關係(圓括號是無向圖,尖括號是有向圖)
存在(Vi,Vj),則稱Vi和Vj互爲鄰接點
存在<Vi,Vj>,則稱Vi鄰接到Vi,Vj鄰接於Vi
8) 關聯(依附): 邊/弧與頂點之間的關係
存在(Vi,Vj)/<Vi,Vj>,則稱該邊/弧關聯於Vi和Vj
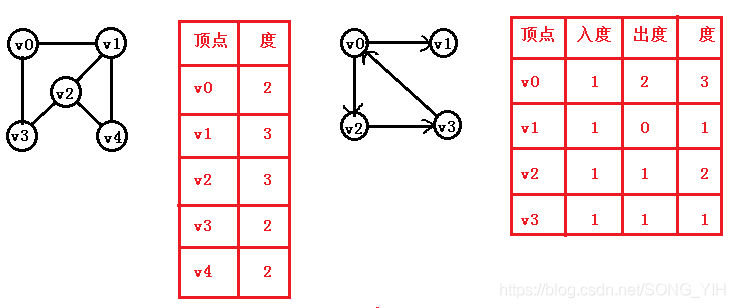
9) 頂點的度: 與該頂點相關聯的邊的數目,記爲TD(v)
在有向圖中,頂點的度等於該頂點的入度與出度之和
頂點v的入度是以v爲終點的有向邊的條數,記作ID(v)
頂點v的出度是以v爲始點的有向邊的條數,記作OD(v)
10) 當有向圖中僅1個頂點的入度爲0,其餘頂點的入度均爲1,此時是何形狀?
答: 是樹!而且是一棵有向樹!
2.圖的相關概念
1) 路徑: 接續的邊構成的頂點序列
2) 路徑長度: 路徑上邊或弧的數目/權值之和
3) 迴路(環): 第一個頂點和最後一個頂點相同的路徑
4) 簡單路徑: 除路徑起點和終點可以相同外,其餘頂點均不相同的路徑
5) 簡單迴路(簡單環): 除路徑起點和終點相同外,其餘頂點均不相同的路徑

6) 連通圖(強連通圖): 在無(有)向圖G={V,{E}}中,若對任何兩個頂點v、u都存在從v、u的路徑,則稱G是連通圖(強連通圖)

7) 權與網: 圖中邊或弧所具有的相關數稱爲權,表明從一個頂點到另一個頂點的距離或耗費
帶權的圖稱爲網
8) 子圖: 設有兩個圖G=(V,{E})、G1=(V1,{E1}),若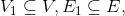 則稱G1是G的子圖
則稱G1是G的子圖
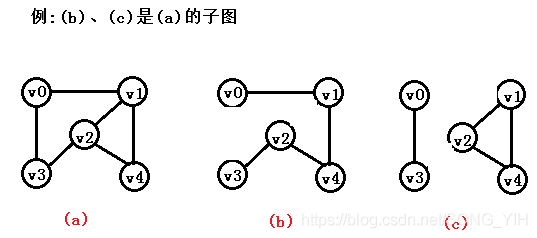
3.連通分量
1) 無向圖G的極大連通子圖稱爲G的連通分量
2) 極大連通子圖:該子圖是G的連通子圖,將G的任何不在該子圖中的頂點加入,子圖不再連通

3) 有向圖G的極大強連通子圖稱爲G的連強通分量
4) 極大強連通子圖:該子圖是G的強連通子圖,將G的任何不在該子圖中的頂點加入,子圖不再強連通

4) 極小連通子圖:該子圖是G的連通子圖,在該子圖中刪除任何一條邊,子圖不再連通
5) 生成樹: 包含無向圖G所有頂點的極小連通子圖
6) 生成森林: 對非連通圖,由各個連通分量的生成樹的集合
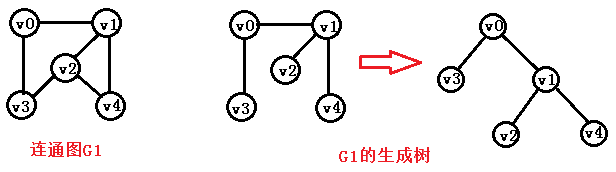
二、圖的儲存結構
1.陣列(鄰接矩陣)表示法
建立一個頂點表(記錄各個頂點資訊)和一個鄰接矩陣(表示各個頂點之間關係)
* 設圖A=(V,E)有n個頂點,則
頂點表Vexs[n] i 0 1 2 ... n-1 Vexs[i] V1 V2 V3 ... Vn * 圖的鄰接矩陣是一個二維陣列A.arc[n][n],定義爲:
如果<i,j>屬於E或者(i,j)屬於E,則A.arcs[i][j]=1
否則A.arcs[i][j]=0
1) 無向圖的鄰接矩陣表示法:

2) 有向圖的鄰接矩陣表示法:

3) 網(即有權圖)的鄰接矩陣表示法:

2.鄰接矩陣的儲存表示:用兩個陣列分別儲存頂點表和鄰接矩陣
#define MVNum 100 //最大頂點數
#define MaxInt 32767 //表示極大值,即∞
typedef char VerTexType; //設頂點的數據型別爲字元型
typedef int ArcType; //假設邊的權值型別爲整型
typedef struct
{
VerTexType vexs[MVNum]; //頂點表
ArcType arcs[MVNum][MVNum]; //鄰接矩陣
int vexnum, arcnum; //圖的當前頂點數和邊數
}AMGraph;
3.採用鄰接矩陣表示法建立無向網
1) 輸入總頂點數和總邊數
2) 依次輸入點的資訊存入頂點表中
3) 初始化鄰接矩陣,使每個權值初始化爲極大值
4) 構造鄰接矩陣
int LocateVex(AMGraph *G, VerTexType u) //在圖G中查詢頂點u回-1
{
for (int i = 0; i < G->vexnum; i++)
{
if (u == G->vexs[i])
return i; //在則返回頂點表中的下標
}
return -1; //否則返回-1
}
void CreateUDN(AMGraph *G) //採用鄰接矩陣表示法建立無向網
{
printf("請輸入頂點數: "); //輸入頂點數
scanf("%d", &G->vexnum);
printf("請輸入邊數: "); //輸入總邊數
scanf("%d", &G->arcnum);
for (int i = 0; i < G->vexnum; i++)
{
scanf("%c", &G->vexs[i]); //依次輸入點的資訊
}
for (int i = 0; i < G->vexnum; i++)
{
for (int j = 0; j < G->vexnum; j++)
{
G->arcs[i][j] = MaxInt; //邊的權值均置爲極大值
}
}
for (int k = 0; k < G->arcnum; k++) //構造鄰接矩陣
{
VerTexType v1, v2;
ArcType w;
printf("請輸入一條邊所依附的兩個頂點: ");
scanf("%c %c", &v1, &v2); //輸入一條邊所依附的頂點
printf("\n請輸入邊的權值: ");
scanf("%d", &w); //輸入邊的權值
putchar('\n');
int i = LocateVex(G, v1);
int j = LocateVex(G, v2); //確定v1和v2在G中的位置
G->arcs[i][j] = w; //邊的權值置爲w
G->arcs[j][i] = G->arcs[i][j]; //對應對稱權值也設爲w
}
}
4.鄰接矩陣表示法的優缺點
優點:
1) 直觀、簡單、好理解
2) 方便檢查任意一對頂點間是否存在邊
3) 方便找任一頂點的所有"鄰接點"(有邊直接相連的頂點)
4) 方便計算任一頂點的"度"(從該點發出的邊數爲"出度",指向該點的邊數爲"入度")
//無向圖: 對應行(或列)非0元素的個數
//有向圖: 對應行非0元素的個數是"出度";對應列非0元素的個數是"入度"
缺點:
1) 不便於增加和刪除頂點
2) 浪費空間----存稀疏圖(點很多而邊很少)有大量無效元素
3) 浪費時間----統計稀疏圖中一共有多少條邊
5.鄰接表表示法(鏈式)
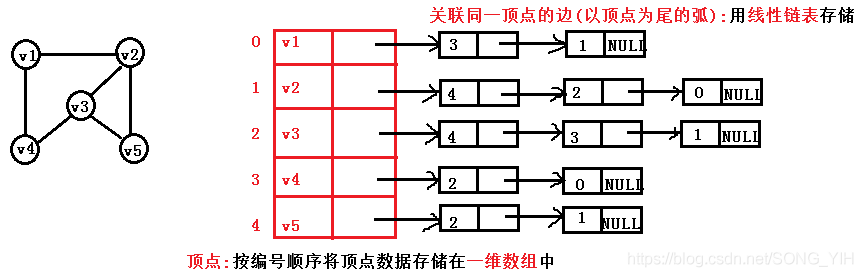
1) 無向圖的鄰接表表示法:

2) 有向圖的鄰接表表示法:
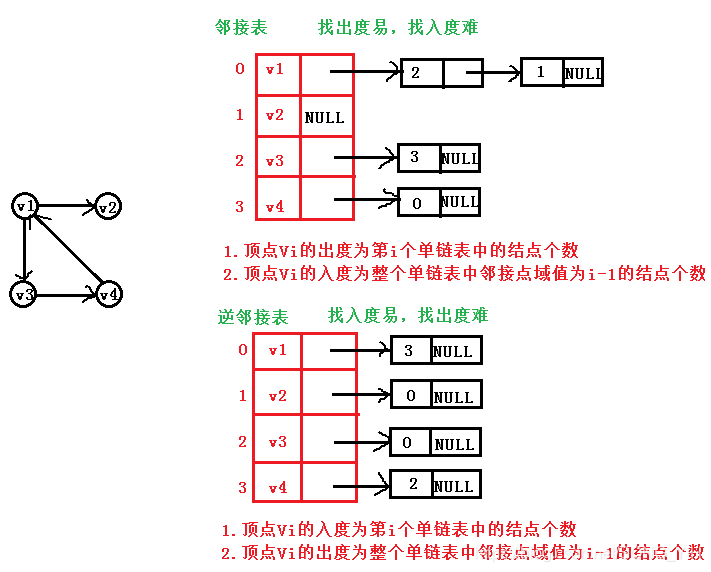
6.圖的鄰接表儲存表示
#define MVNum 100 //最大頂點數
typedef char VerTexType;
typedef struct ArcNode //邊結點
{
int avjvex; //該邊所指向的頂點位置
int info; //和邊相關的資訊
struct ArcNode *nextarc; //指向下一條邊的指針
}ArcNode;
typedef struct VNode //頂點
{
VerTexType data; //頂點資訊
ArcNode *firstarc; //指向第一條依附該頂點的邊的指針
}VNode,AdjList[MVNum]; //AdjList表示鄰接表型別
typedef struct //圖的結構定義
{
AdjList vertices; //vertices--vertex的複數
int vexnum, arcnum; //圖的當前頂點數和邊數
}ALGraph;
7.採用鄰接表表示法建立無向網
演算法思想:
1) 輸入總頂點數和邊數
2) 建立頂點表
*依次輸入點的資訊存入頂點表中
*使每個表頭結點的指針域初始化爲NULL
3) 建立鄰接表
*依次輸入每條邊依附的兩個頂點
*確定兩個頂點的序號i和j,建立邊結點
*將此邊結點分別插入到Vi和Vj對應的兩個邊鏈表的頭部
int LocateVex(ALGraph *G, VerTexType u)
{
for (int z = 0; z < G->vexnum; z++)
{
if (G->vertices[z].data == u)
return z;
}
return -1;
}
void CreateUDG(ALGraph *G) //採用鄰接表表示法,建立無向圖G
{
VerTexType v1, v2;
int i, j,w;
printf("請輸入總頂點數: "); //輸入總頂點數
scanf("%d", &G->vexnum);
printf("請輸入總邊數: "); //輸入總邊數
scanf("%d", &G->arcnum);
for (int i = 0; i < G->vexnum; i++) //輸入各點,構造表頭結點表
{
scanf("%c", &G->vertices[i].data); //輸入頂點值
G->vertices[i].firstarc = NULL; //初始化表頭結點的指針域
}
for (int k = 0; k <(2*G->arcnum); k++) //輸入各邊,構造鄰接表
{
printf("請輸入第一個頂點: "); //輸入一條邊依附的第一個頂點
scanf("%c", &v1);
printf("請輸入第二個頂點: "); //輸入一條邊依附的第二個頂點
scanf("%c", &v2);
i = LocateVex(G, v1);
j = LocateVex(G, v2);
printf("請輸入邊的權值: ");
scanf("%d", &w);
ArcNode *p1 = (ArcNode*)malloc(sizeof(ArcNode)); //生成一個新的邊結點p1
p1->avjvex = j; //鄰接點序號爲j
p1->info = w; //賦權值
p1->nextarc=G->vertices[i].firstarc;
G->vertices[i].firstarc = p1; //將新結點*p1插入頂點Vi的邊表頭部
ArcNode *p2 = (ArcNode*)malloc(sizeof(ArcNode)); //生成一個新的邊結點p2
p2->avjvex = i; //鄰接點序號爲i
p2->info = w; //賦權值
p2->nextarc = G->vertices[j].firstarc;
G->vertices[j].firstarc = p2; //將新結點*p2插入頂點Vj的邊邊表頭部
}
}
8.鄰接表表示法的優缺點
1) 方便找任一頂點的所有鄰接點
2) 節約稀疏圖的空間--需要N個頭指針+2E個邊結點(每個邊結點至少兩個域)
3) 方便計算無向圖中任一頂點的度
4) 對有向圖來說:只能計算"出度";需要構造"逆鄰接表"(存指向自己的邊)來方便計算"入度"
5) 不方便檢查任意一對頂點間是否存在邊
9.鄰接矩陣與鄰接表表示法的關係
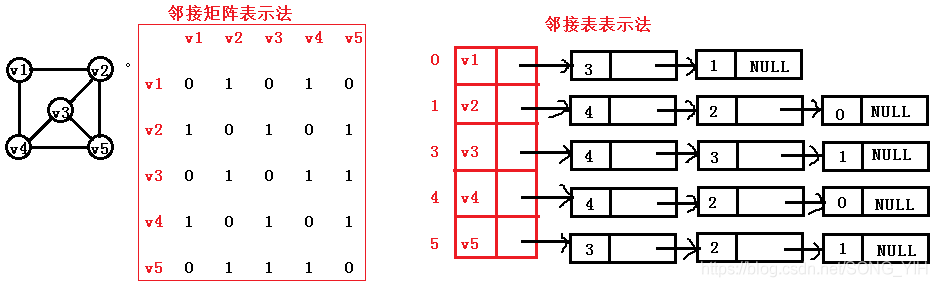
1)聯繫: 鄰接表中每個鏈表對應鄰接矩陣中的一行,鏈表中結點個數等於一行中非零元素的個數
2)區別:
(1).對於任一確定的無向圖,鄰接矩陣是唯一的(行列號與頂點編號一致),但鄰接表不唯一(鏈接次序與頂點編號無關)
(2).鄰接矩陣的空間複雜度爲O(n*n),而鄰接表的空間複雜度爲O(n+e)
3)用途: 鄰接矩陣多用於稠密圖;而鄰接表多用於稀疏圖
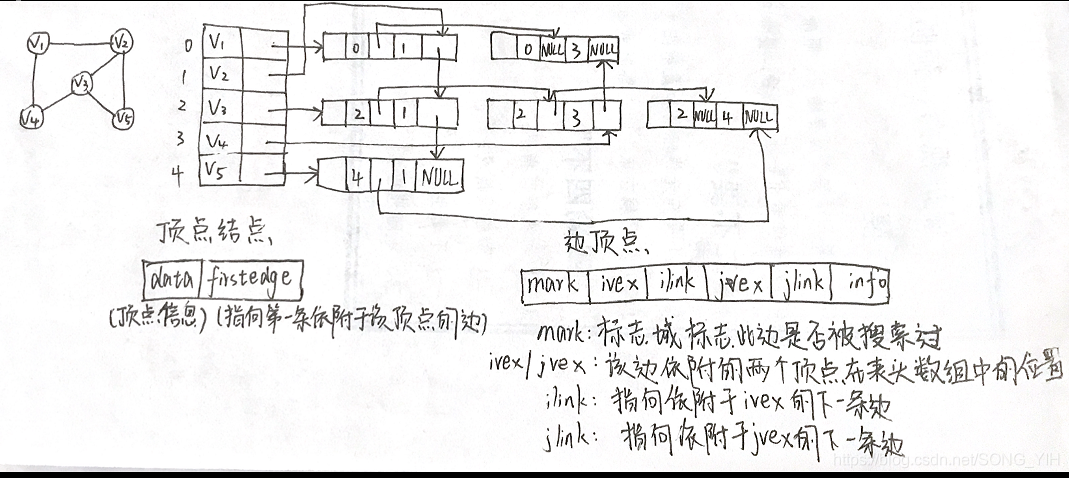
10.十字鏈表(有向圖)

1) 十字鏈表是有向圖的另一種鏈式儲存結構(可以看成將有向圖的鄰接表和逆鄰接表結合起來形成的一種鏈表)
2) 有向圖中的每一條弧對應十字鏈表中的一個弧結點
3) 有向圖中的每個頂點在十字鏈表中對應有一個結點,叫作頂點結點

11.鄰接多重表(無向圖)