運籌系列43:julia用於科學計算
如果出現git問題,切換shell模式,執行:
git config --global http.proxy ‘socks5://127.0.0.1:1080’
git config --global https.proxy ‘socks5://127.0.0.1:1080’
1. 基礎
1.1 Dataframe
# 新建一個DataFrame並增加4列內容
using DataFrames
df1 = DataFrame()
df1[:clo1] = Array([1.0,2.0,3.0])
df1[:clo2] = Array([4.0,5.0,6.0])
df1[:clo3] = Array([7.0,8.0,9.0])
df1[:ID] = Array(['a','b','c'])
show(df1)
>>3×4 DataFrame
│ Row │ clo1 │ clo2 │ clo3 │ ID │
│ │ Float64 │ Float64 │ Float64 │ Char │
├─────┼─────────┼─────────┼─────────┼──────┤
│ 1 │ 1.0 │ 4.0 │ 7.0 │ 'a' │
│ 2 │ 2.0 │ 5.0 │ 8.0 │ 'b' │
│ 3 │ 3.0 │ 6.0 │ 9.0 │ 'c' │
# 如果沒有指定列名,則預設是x1,x2...
df2 = DataFrame(rand(5,6))
# 在DataFrame定義時直接指定內容
df3 = DataFrame([collect(1:3),collect(4:6)], [:A, :B])
>> A B
Int64 Int64
1 1 4
2 2 5
3 3 6
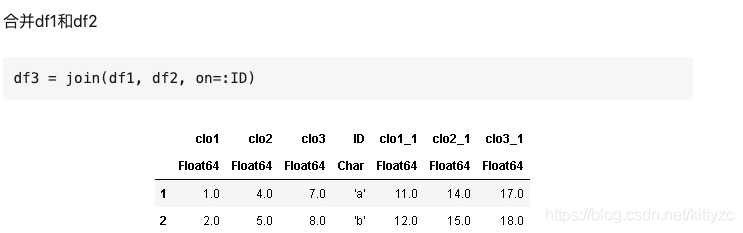
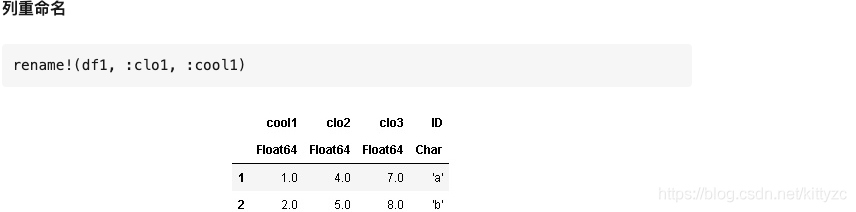


RDatasets是Julia中的一個數據集,裏面包含了很多可以學習和驗證的數據,其中就包括iris數據集。

下面 下麪是直接讀取csv、xlxs、txt檔案的方法
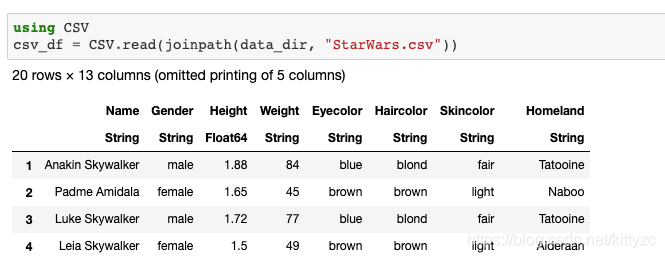
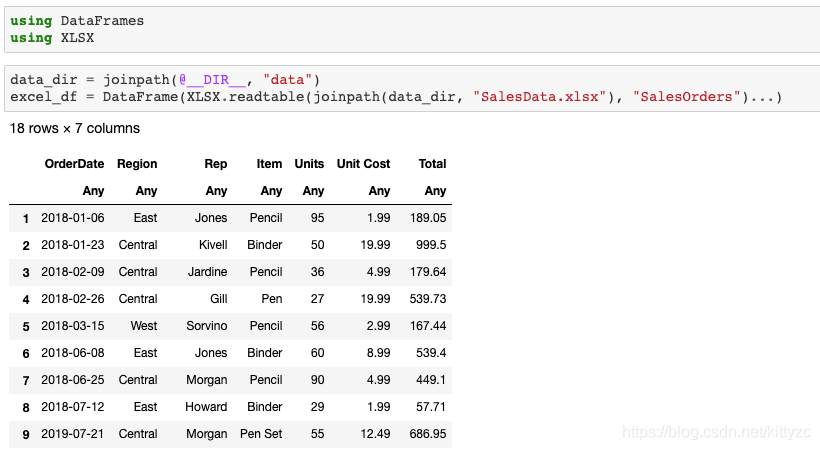
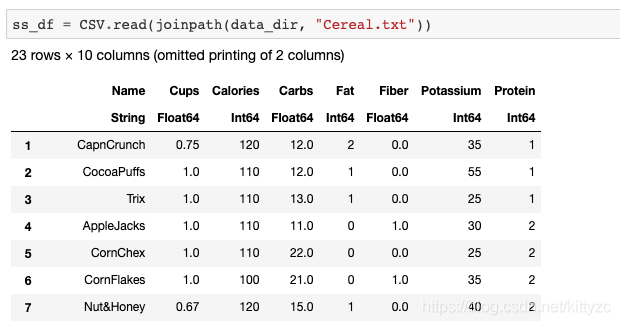
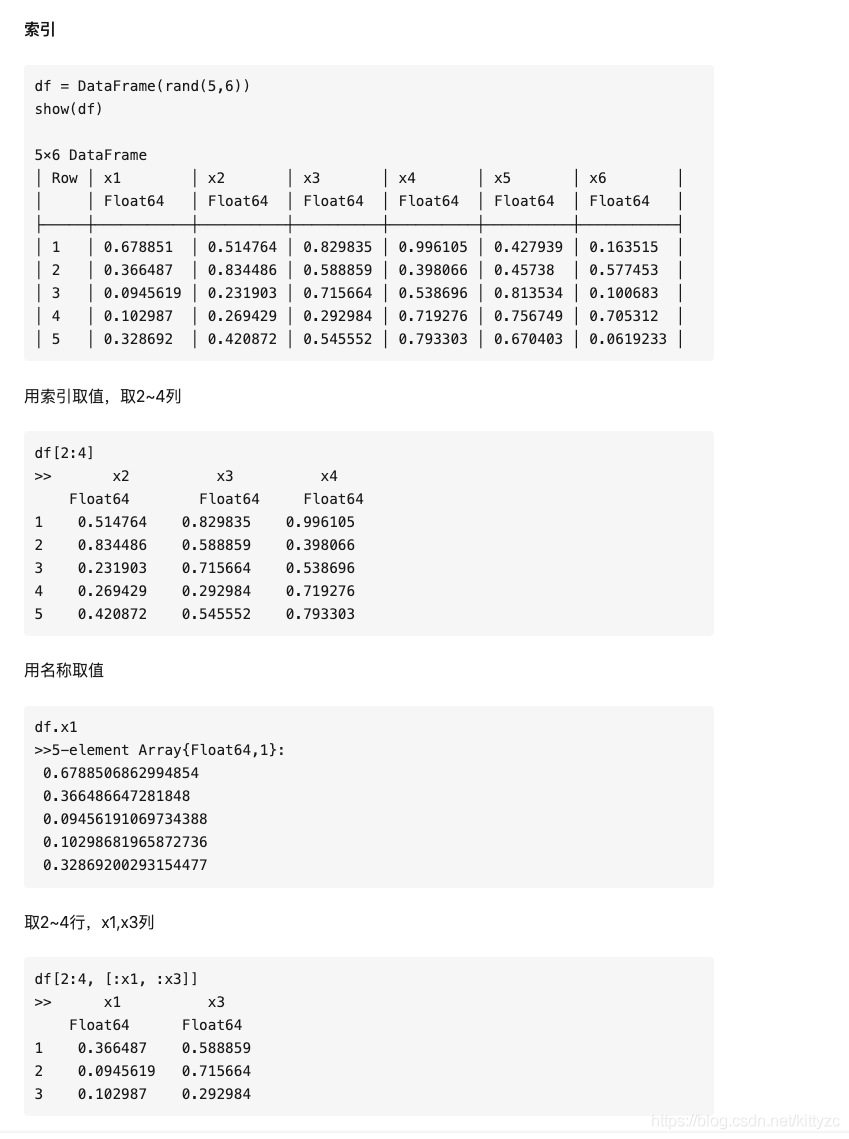
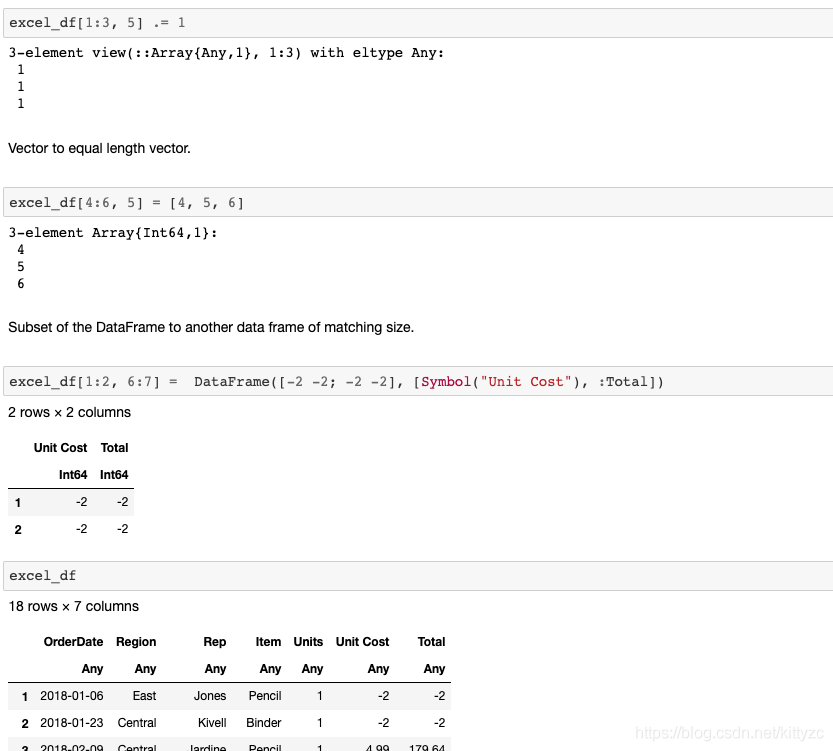
下面 下麪是一些基礎操作:
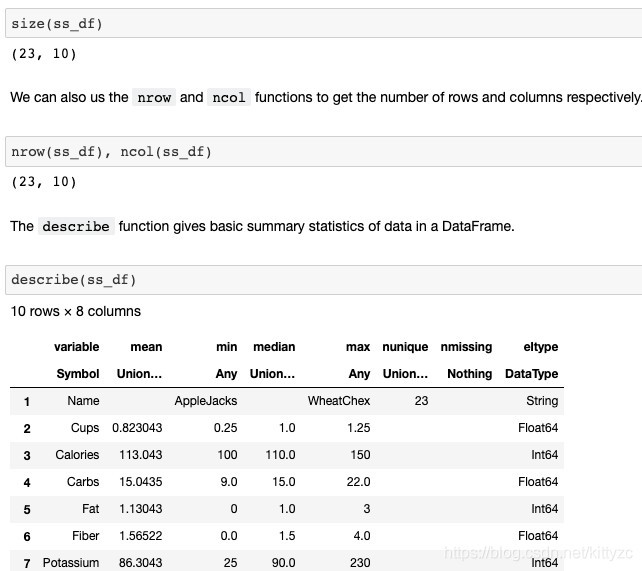
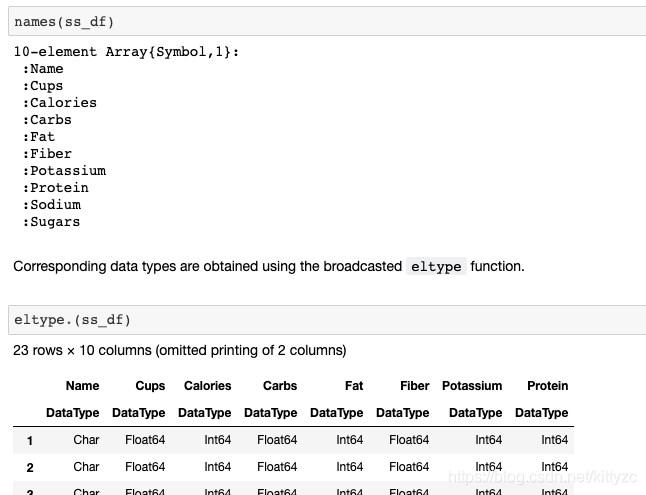

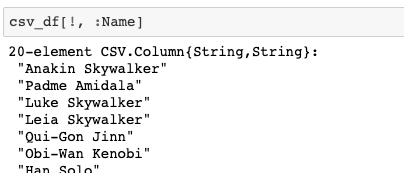

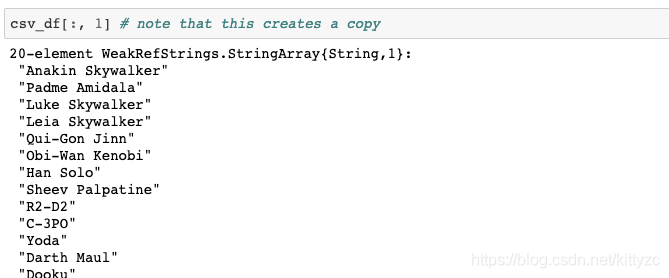
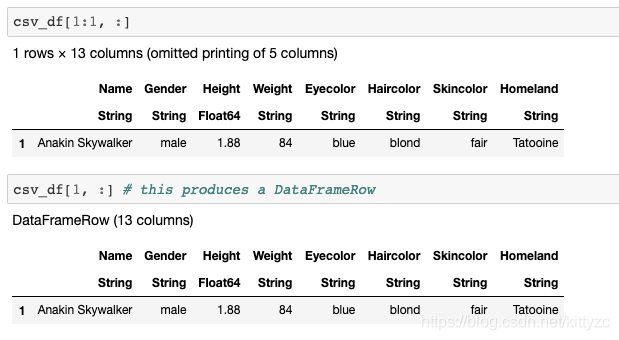
注意最後三者的差別。
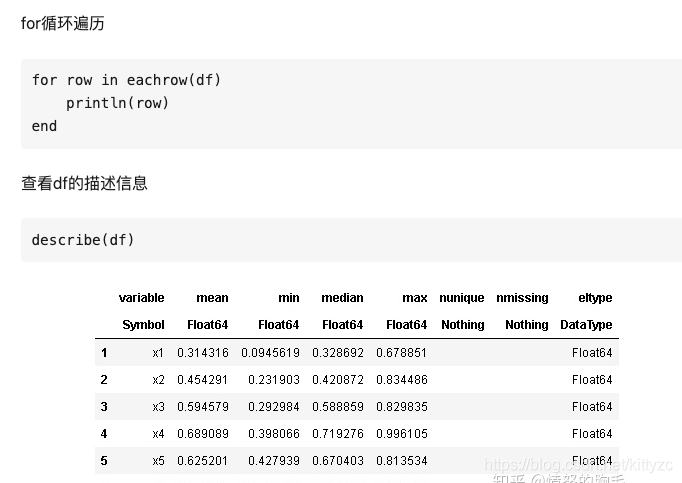
下面 下麪是修改數據的方法:
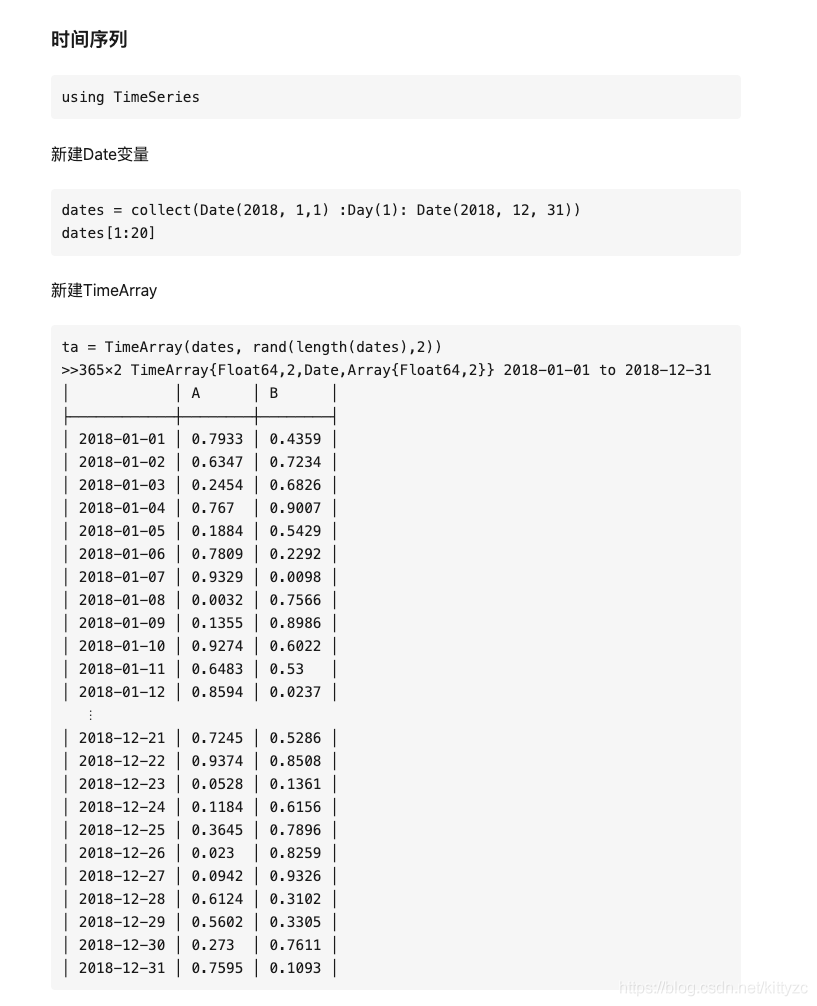
1.2 時間序列

1.3 機器學習等
機器學習庫自己可以搜
深度學習庫是Flux
1.4 加速效能
首先要關注一下特殊符號,例如eltype函數:
function eltype(::Type{<:AbstractDict{K,V}}) where {K,V}
if @isdefined(K)
if @isdefined(V)
return Pair{K,V}
else
return Pair{K}
end
elseif @isdefined(V)
return Pair{k,V} where k
else
return Pair
end
end
其中:
1.{}用來表示型別的參數化(泛型),比如說Vector{Int}表示一個整數的向量,在Java(以及C++)中用<>表示,例如List
2.[]表示陣列
3.()可以表示元組(和Haskell,Python一致),如(1,2,3),也可以表示函數呼叫,如sum([1,2,3])
3.A<:B表示型別子類化(A是B的子類,a::B表示a的型別是B)
4.where引導型別變數,例如Array{T,3} where T表示一個3維陣列,陣列元素的型別爲某個待定的T,可以提高效能
5.一個點 . ,如A.a,表示A有個屬性爲a;. 還可以用來表示broadcast,可以理解爲就是map,例如說,你有一個矩陣A,sin.(A)表示將A中元素分別求正弦後得到的新矩陣,等價於map(sin,A)
6.@表示宏呼叫(Julia本來也可以不用@標記宏,但是爲了大家方便閱讀,最後還是強制要求用@標記)
7.Julia中有生成函數(一種特殊函數),本質上是一個返回表達式的函數,然後表達式會插入函數所在處執行了。這個東西創造出來是爲了利用LLVM的多層次編譯優勢(執行時動態生成優化程式碼),主要用於優化(而且被大量使用)例如在文件中的例子:
julia> @generated function bar(x)
if x <: Integer
return :(x ^ 2)
else
return :(x)
end
end
bar (generic function with 1 method)
julia> bar(4)
16
julia> bar("baz")
"baz"
- 在Julia中,值只有具體型別,不可能有抽象型別,只有抽象型別能被子類化,具體型別不可以,具體說來,就是上述型別樹中,只有葉子節點才能 纔能被構造出來,其他的節點是不可構造的。這是很有趣的一個地方,這表明,Julia的tag系統全都是具體型別組成的,那抽象型別有什麼用呢?抽象型別用來確定子類化關係,以做多重派發以實現ad hoc多型(並且只有這個用處)
避免全域性變數,把全域性變數宣告爲常數可以巨大的提升效能。如果必須要宣告全域性變數,可以在使用它的地方標註他們的型別來優化效率。
任何注重效能或者需要測試效能的程式碼都應該被放置在函數之中。
可以通過@code來檢視用於code generation的宏
下面 下麪是測試例子:
global x = rand(10000)
function lp1() # 直接動用全域性變數
s = 0.0
for i in x
s += i
end
end
function lp2() # 指定全域性變數型別
s = 0.0
for i in x::Vector{Float64}
s += i
end
end
function lp3(x) # 將變數以參數形式傳入
s = 0.0
for i in x
s += i
end
end
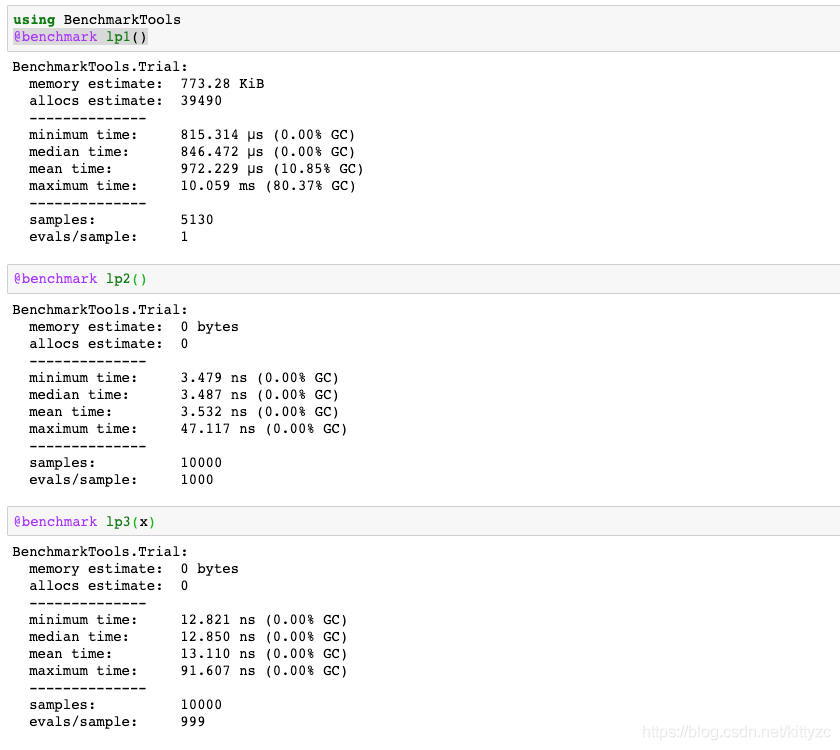
指定型別是速度最快的,原理如下:
當我們定義一個函數時,如果函數參數的型別是固定的,比如是一個Int64的Array[1,2,3,4],那他們在記憶體中會連續存放;
但如果函數參數的型別是Any,那麼記憶體中連續存放只是他們的「指針」,會指向其實際的位置。這樣一來,數據存取就慢下來了。計算concrete型別會比計算abstract型別要節省時間,我們可以使用@code_warntype來檢視執行的函數中是否有abstract型別,對於有abstract型別的地方,會用紅色的標出。
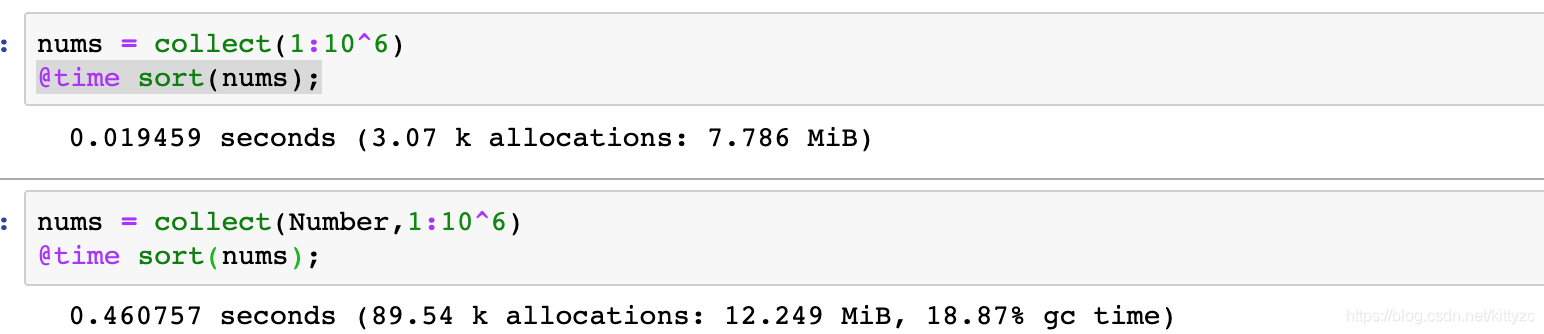
可以用如下函數來獲得相同的數據型別:
zero(value)
eltype(array)
one(value)
similar(array)
向量化並不會提高Julia的執行速度,@simd 可以在運算支援被重新recorded時加速運算
輸出預分配可以提高效能
避免不必要的Array,比如計算x,y,z的和時,使用x+y+z,不要用sum([x,y,z])
用div(x,y)代替trunc(x/y),用fld(x,y)代替floor(x/y),用cld(x,y)代替ceil(x/y),有現成的函數就不要自己寫計算過程
2. GPU使用
2.1 安裝與測試
pkg> add CUDA
pkg> test CUDA
先測試一下CPU的序列和並行版本:
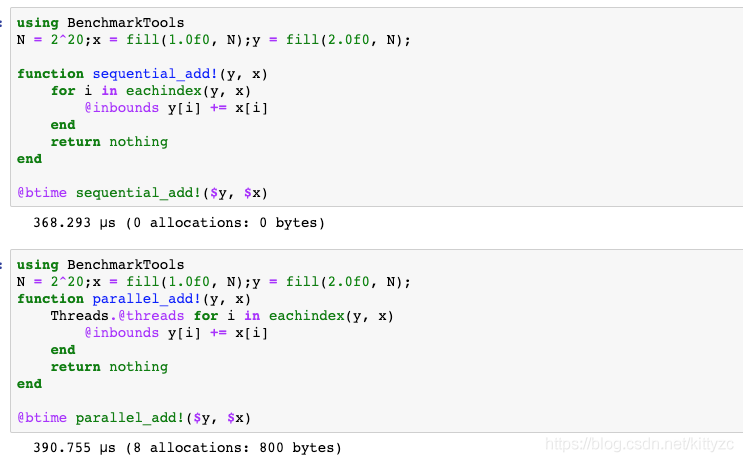
下面 下麪是cuda版本
使用GPU簡單到令人感動,pkg中add CUDAdrv即可:
julia> using CUDAdrv
julia> CUDAdrv.name(CuDevice(0))
"Tesla P4"
關於GPU的一些注意事項:
GPU是一個獨立的硬體,具有自己的記憶體空間和不同的架構。 因此,從RAM到GPU記憶體(VRAM)的傳輸時間很長。 即使在GPU上啓動內核(換句話說,排程函數呼叫)也會帶來較大的延遲。 GPU的時間約爲10us,而CPU的時間則爲幾納秒。
較低的精度是預設值,而較高的精度計算可以輕鬆地消除所有效能增益
GPU函數(內核)本質上是並行的,所以編寫GPU內核至少和編寫並行CPU程式碼一樣困難,因此許多演算法都不能很好地移植到GPU上。內核通常是用C/ C++編寫的,這並不是寫演算法的最佳語言。
CUDA和OpenCL之間存在分歧,OpenCL是用於編寫低階GPU程式碼的主要框架。雖然CUDA只支援英偉達硬體,但OpenCL支援所有硬體,但有些粗糙。