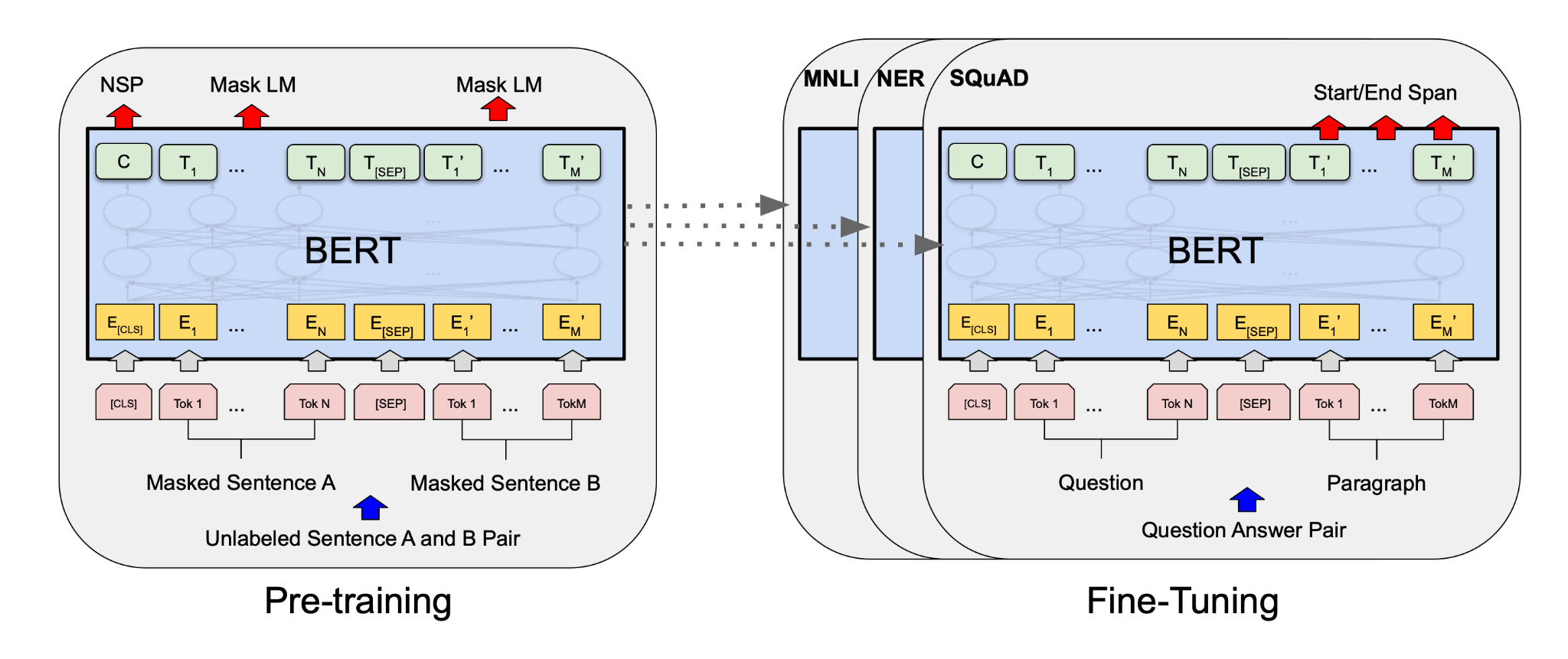
NLP技術如何為搜尋引擎賦能
在全球化時代,搜尋引擎不僅需要為使用者提供準確的資訊,還需理解多種語言和方言。本文詳細探討了搜尋引擎如何通過NLP技術處理多語言和方言,確保為不同地區和文化的使用者提供高質量的搜尋結果,同時提供了基於PyTorch的實現範例,幫助您更深入地理解背後的技術細節。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

1. NLP關鍵詞提取與匹配在搜尋引擎中的應用
在自然語言處理(NLP)的領域中,搜尋引擎的優化是一個長期研究的主題。其中,關鍵詞提取與匹配是搜尋引擎核心技術之一,它涉及從使用者的查詢中提取關鍵資訊並與資料庫中的檔案進行匹配,以提供最相關的搜尋結果。
1. 關鍵詞提取
關鍵詞提取是從文字中提取出最具代表性或重要性的詞彙或短語的過程。
例子:
對於文字 "蘋果公司是全球領先的技術公司,專注於設計和製造消費電子產品",可能的關鍵詞包括 "蘋果公司"、"技術" 和 "消費電子產品"。
2. 關鍵詞匹配
關鍵詞匹配涉及到將使用者的查詢中的關鍵詞與資料庫中的檔案進行對比,找到最符合的匹配項。
例子:
當用戶在搜尋引擎中輸入 "蘋果公司的新產品" 時,搜尋引擎會提取 "蘋果公司" 和 "新產品" 作為關鍵詞,並與資料庫中的檔案進行匹配,以找到相關的結果。
Python實現
以下是一個簡單的Python實現,展示如何使用jieba庫進行中文關鍵詞提取,以及使用基於TF-IDF的方法進行關鍵詞匹配。
import jieba
import jieba.analyse
# 關鍵詞提取
def extract_keywords(text, topK=5):
keywords = jieba.analyse.extract_tags(text, topK=topK)
return keywords
# 例子
text = "蘋果公司是全球領先的技術公司,專注於設計和製造消費電子產品"
print(extract_keywords(text))
# 關鍵詞匹配(基於TF-IDF)
from sklearn.feature_extraction.text import TfidfVectorizer
# 假設有以下檔案集合
docs = [
"蘋果公司釋出了新的iPhone",
"技術公司都在競相開發新產品",
"消費電子產品市場日新月異"
]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)
# 對使用者的查詢進行匹配
query = "蘋果公司的新產品"
response = vectorizer.transform([query])
# 計算匹配度
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarities = cosine_similarity(response, tfidf_matrix)
print(cosine_similarities)
這段程式碼首先使用jieba進行關鍵詞提取,然後使用TF-IDF方法對使用者的查詢進行匹配,最後使用餘弦相似度計算匹配度。
2. NLP語意搜尋在搜尋引擎中的應用
傳統的關鍵詞搜尋主要基於文字的直接匹配,而沒有考慮查詢的深層含義。隨著技術的發展,語意搜尋已經成為現代搜尋引擎的關鍵部分,它致力於理解使用者查詢的實際意圖和上下文,以提供更為相關的搜尋結果。
1. 語意搜尋的定義
語意搜尋是一種理解查詢的語意或意圖的搜尋方法,而不僅僅是匹配關鍵詞。它考慮了單詞的同義詞、近義詞、上下文和其他相關性因素。
例子:
使用者可能搜尋 "蘋果" 這個詞,他們可能是想要找關於「蘋果公司」的資訊,也可能是想了解「蘋果水果」的知識。基於語意的搜尋引擎可以根據上下文或使用者的歷史資料來判斷使用者的真實意圖。
2. 語意搜尋的重要性
隨著網際網路資訊的爆炸性增長,使用者期望搜尋引擎能夠理解其複雜的查詢意圖,並提供最相關的結果。語意搜尋不僅可以提高搜尋結果的準確性,還可以增強使用者體驗,因為它能夠提供與查詢更為匹配的內容。
例子:
當用戶查詢 "如何烤一個蘋果派" 時,他們期望得到的是烹飪方法或食譜,而不是關於「蘋果」或「派」這兩個詞的定義。
Python/PyTorch實現
以下是一個基於PyTorch的簡單語意搜尋實現,我們將使用預訓練的BERT模型來計算查詢和檔案之間的語意相似性。
import torch
from transformers import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity
# 載入預訓練的BERT模型和分詞器
model_name = "bert-base-chinese"
model = BertModel.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
model.eval()
# 計算文字的BERT嵌入
def get_embedding(text):
tokens = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=512)
with torch.no_grad():
outputs = model(**tokens)
return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
# 假設有以下檔案集合
docs = [
"蘋果公司釋出了新的iPhone",
"蘋果是一種非常受歡迎的水果",
"很多人喜歡吃蘋果派"
]
doc_embeddings = [get_embedding(doc) for doc in docs]
# 對使用者的查詢進行匹配
query = "告訴我一些關於蘋果的資訊"
query_embedding = get_embedding(query)
# 計算匹配度
cosine_similarities = cosine_similarity([query_embedding], doc_embeddings)
print(cosine_similarities)
在這段程式碼中,我們首先使用預訓練的BERT模型來為檔案和查詢計算嵌入。然後,我們使用餘弦相似度來比較查詢和每個檔案嵌入之間的相似性,從而得到最相關的檔案。
3. NLP個性化搜尋建議在搜尋引擎中的應用
隨著技術的進步和巨量資料的發展,搜尋引擎不再滿足於為所有使用者提供相同的搜尋建議。相反,它們開始提供個性化的搜尋建議,以更好地滿足每個使用者的需求。
1. 個性化搜尋建議的定義
個性化搜尋建議是基於使用者的歷史行為、偏好和其他上下文資訊為其提供的搜尋建議,目的是為使用者提供更為相關的搜尋體驗。
例子:
如果一個使用者經常搜尋「籃球比賽」的相關資訊,那麼當他下次輸入「籃」時,搜尋引擎可能會推薦「籃球比賽」、「籃球隊」或「籃球新聞」等相關的搜尋建議。
2. 個性化搜尋建議的重要性
為使用者提供個性化的搜尋建議可以減少他們查詢資訊的時間,並提供更為準確的搜尋結果。此外,個性化的建議也可以提高使用者對搜尋引擎的滿意度和忠誠度。
例子:
當用戶計劃外出旅遊並在搜尋引擎中輸入「旅」時,搜尋引擎可能會根據該使用者之前的旅遊歷史和偏好,推薦「海灘旅遊」、「山區露營」或「城市觀光」等相關建議。
Python實現
以下是一個簡單的基於使用者歷史查詢的個性化搜尋建議的Python實現:
from collections import defaultdict
# 假設有以下使用者的搜尋歷史
history = {
'user1': ['籃球比賽', '籃球新聞', 'NBA賽程'],
'user2': ['旅遊景點', '山區旅遊', '海灘度假'],
}
# 構建一個查詢建議的庫
suggestion_pool = {
'籃': ['籃球比賽', '籃球新聞', '籃球鞋', '籃球隊'],
'旅': ['旅遊景點', '山區旅遊', '海灘度假', '旅遊攻略'],
}
def personalized_suggestions(user, query_prefix):
common_suggestions = suggestion_pool.get(query_prefix, [])
user_history = history.get(user, [])
# 優先推薦使用者的歷史查詢
personalized = [s for s in common_suggestions if s in user_history]
for s in common_suggestions:
if s not in personalized:
personalized.append(s)
return personalized
# 範例
user = 'user1'
query_prefix = '籃'
print(personalized_suggestions(user, query_prefix))
此程式碼首先定義了一個使用者的歷史查詢和一個基於查詢字首的建議池。然後,當用戶開始查詢時,該函數將優先推薦與該使用者歷史查詢相關的建議,然後再推薦其他普通建議。
4. NLP多語言和方言處理在搜尋引擎中的應用
隨著全球化的程序,搜尋引擎需要處理各種語言和方言的查詢。為了提供跨語言和方言的準確搜尋結果,搜尋引擎必須理解並適應多種語言的特點和差異。
1. 多語言處理的定義
多語言處理是指計算機程式或系統能夠理解、解釋和生成多種語言的能力。
例子:
當用戶在英國搜尋「手機」時,他們可能會使用「mobile phone」這個詞;而在美國,使用者可能會使用「cell phone」。
2. 方言處理的定義
方言處理是指對同一種語言中不同的方言或變種進行處理的能力。
例子:
在普通話中,「你好」是問候;而在廣東話中,相同的問候是「你好嗎」。
3. 多語言和方言處理的重要性
- 多樣性: 世界上有數千種語言和方言,搜尋引擎需要滿足不同使用者的需求。
- 文化差異: 語言和方言往往與文化緊密相關,正確的處理可以增強使用者體驗。
- 資訊獲取: 為了獲取更廣泛的資訊,搜尋引擎需要跨越語言和方言的障礙。
Python/PyTorch實現
以下是一個基於PyTorch和transformers庫的簡單多語言翻譯實現:
from transformers import MarianMTModel, MarianTokenizer
# 選擇一個翻譯模型,這裡我們選擇從英語到中文的模型
model_name = 'Helsinki-NLP/opus-mt-en-zh'
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
def translate_text(text, target_language='zh'):
"""
翻譯文字到目標語言
"""
# 對文字進行編碼
encoded = tokenizer.encode(text, return_tensors="pt", max_length=512)
# 使用模型進行翻譯
translated = model.generate(encoded)
# 將翻譯結果轉換為文字
return tokenizer.decode(translated[0], skip_special_tokens=True)
# 範例
english_text = "Hello, how are you?"
chinese_translation = translate_text(english_text)
print(chinese_translation)
這段程式碼使用了一個預訓練的多語言翻譯模型,可以將英文文字翻譯為中文。通過使用不同的預訓練模型,我們可以實現多種語言間的翻譯。
5. 總結
隨著資訊時代的到來,搜尋引擎已經成為我們日常生活中不可或缺的工具。但是,背後支援這一切的技術進步,特別是自然語言處理(NLP),往往被大多數使用者所忽視。在我們深入探討搜尋引擎如何處理多語言和方言的過程中,可以看到這其中涉及的技術深度與廣度。
語言,作為人類文明的基石,有著其獨特的複雜性。不同的文化、歷史和地理因素導致了語言和方言的多樣性。因此,使得計算機理解和解釋這種多樣性成為了一項極具挑戰性的任務。而搜尋引擎正是在這樣的挑戰中,藉助NLP技術,成功地為全球數億使用者提供了跨語言的搜尋體驗。
而其中最值得關注的,是這樣的技術創新不僅僅滿足了功能需求,更在無形中拉近了不同文化和地區之間的距離。當我們可以輕鬆地搜尋和理解其他文化的資訊時,人與人之間的理解和交流將更加流暢,這正是技術為社會帶來的深遠影響。
最後,我們不應該僅僅停留在技術的應用層面,更應該思考如何將這些技術與人文、社會和文化更緊密地結合起來,創造出真正有價值、有意義的解決方案。在未來的技術探索中,NLP將持續地為我們展示其無盡的可能性和魅力。

關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。