聊聊魔塔社群MGeo模型的部署與執行
從現今與今後的發展來看,單一的業務不再僅僅依靠於傳統的技術開發,而是應該結合AI模型來應用、實踐。只有這樣,才能更數智化,更高效化,更貼合時代的發展。
魔塔 社群就類似國外的Hugging Face,是一個模型即服務的執行平臺。在這個平臺上執行著很多的大模型範例,網站直接提供了試執行的環境,也可以下載程式碼到本地部署執行或是在阿里雲的PAI平臺執行。
pytorch環境搭建
我是跟著 Pytorch-Gpu環境設定 博文一步一步搭建起來的。唯一不同的是,我不是基於Anaconda虛擬環境搭建,而是直接在本地環境部署pytorch與CUDA。
開著西部世界的VPN,下載pytorch與CUDA會快一些,在本地下載好了pytorch的whl檔案後,直接在下載目錄中開啟cmd視窗,使用pip install xxxx.whl安裝pytorch即可。
RaNER 模型搭建與執行
進入魔塔官網,找到MGeo模型,首先必須要下載modelscope包。在MGeo的模型介紹中,以及有詳細的命令說明,如下:
# GPU版本
conda create -n py37testmaas python=3.7
pip install cryptography==3.4.8 tensorflow-gpu==1.15.5 torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
但是對於我來說,並沒有用到conda虛擬環境,所以我只是執行了最後的pip命令,如下:
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
命令輸出內容如下:
最好是開著VPN執行命令,否則會很慢。下載完後有一個報錯,可以忽略,最後我成功安裝的元件有:
如此,便完成了modelscope包的安裝。然後拷貝範例程式碼在本地執行即可,範例程式碼如下:
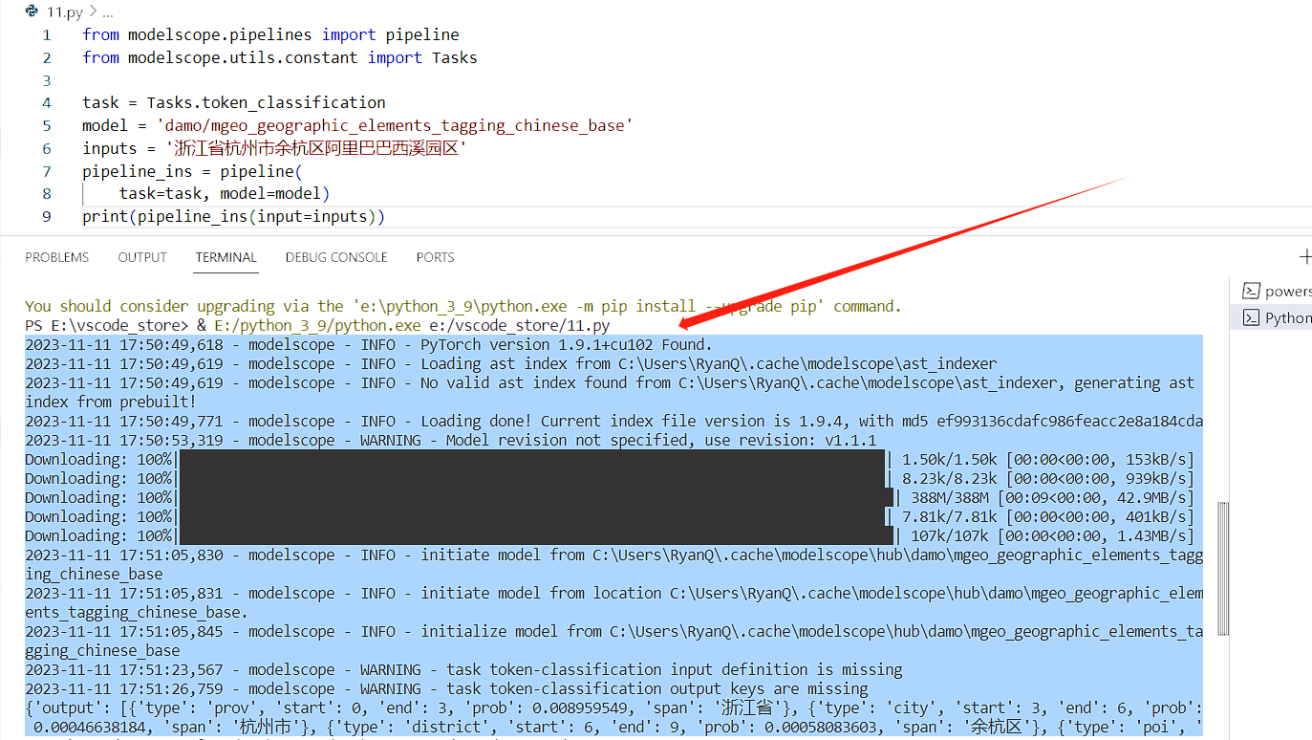
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
task = Tasks.token_classification
model = 'damo/mgeo_geographic_elements_tagging_chinese_base'
inputs = '浙江省杭州市餘杭區阿里巴巴西溪園區'
pipeline_ins = pipeline(
task=task, model=model)
print(pipeline_ins(input=inputs))
# 輸出
# {'output': [{'type': 'prov', 'start': 0, 'end': 3, 'span': '浙江省'}, {'type': 'city', 'start': 3, 'end': 6, 'span': '杭州市'}, {'type': 'district', 'start': 6, 'end': 9, 'span': '餘杭區'}, {'type': 'poi', 'start': 9, 'end': 17, 'span': '阿里巴巴西溪園區'}]}
執行過程中,也會有一些提示,還是很有意思的,可以看看.
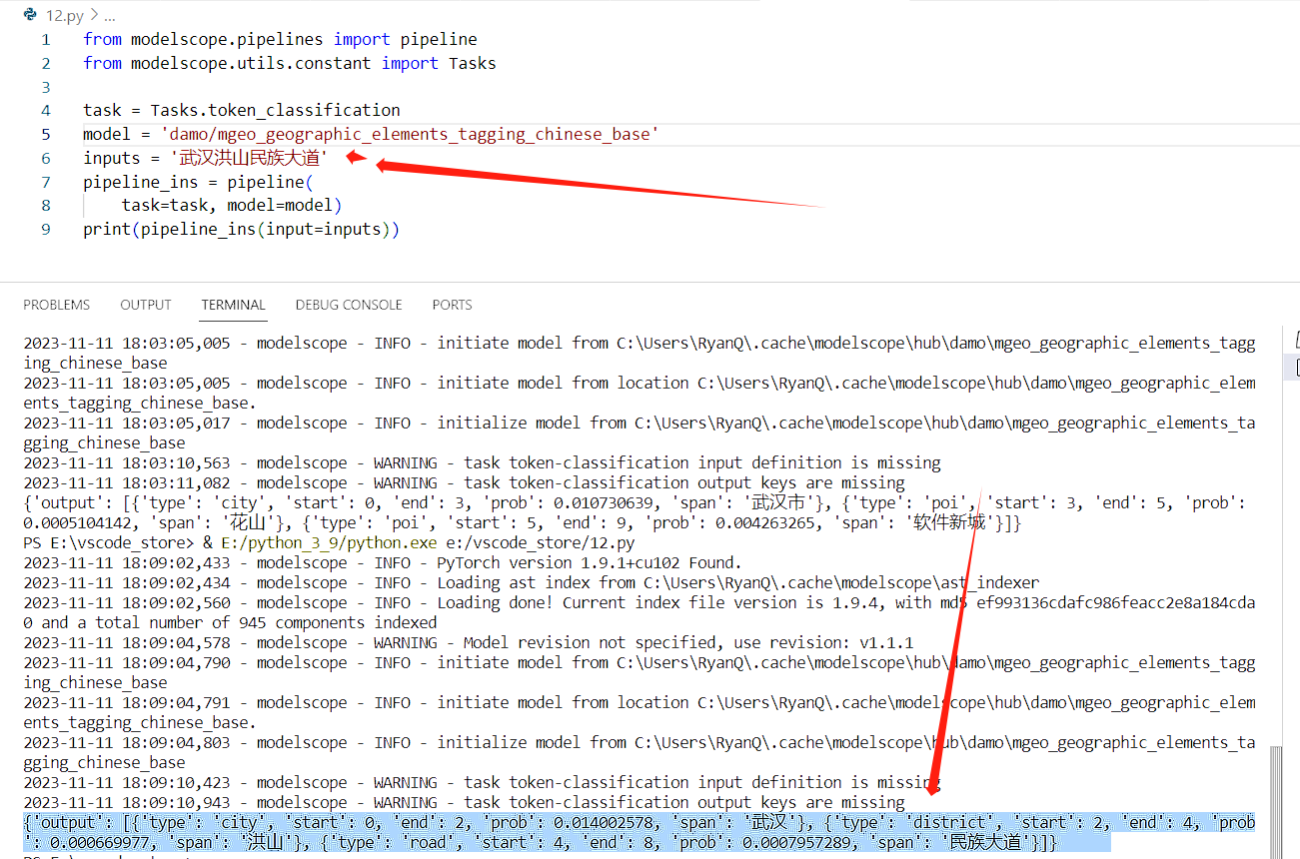
最後的結果也是正常的輸出了,對於輸出結果的解釋,我就不多說,可以看API檔案解釋。我換成其它地址繼續測試:
總結
最後說一下自己的實際感受。首先這個MGEO的AI模型,在我上家公司我主導做的專案就用到了,當時是花錢在阿里雲的 地址標準化 產品上購買使用,用於在實際的專案中根據客戶輸入的地址提取省市區並再次輸入到目標網站。當時一開始想的是自己找開源的庫來實現,後來發現有點難,因為客戶輸入的辨識度太低,可能性太多,而且我們不能規範客戶的輸入(主要是歷史資料太多)。因此當時找了好多方案,最後發現阿里雲有這個支援,就花錢購買呼叫解決問題。
從現在來看,其實整個模型與應用完全可以自己搭建部署起來,作為基礎設施層,省錢又能自我管控,而且還能二次開發,畢竟現在以及前幾年做AI演演算法的人還是不少的(當時我們公司也有少數做AI相關的人,自己現在也算是個半吊子水平,看得懂也能改一點),唉,總的來說還是當時的能力限制了,還是得多學多思考多瞭解,尤其是現在AI模型的普遍性與高速發展,程式猿學習成本與門檻降低很多很多。