深度解析NLP文字摘要技術:定義、應用與PyTorch實戰
在本文中,我們深入探討了自然語言處理中的文字摘要技術,從其定義、發展歷程,到其主要任務和各種型別的技術方法。文章詳細解析了抽取式、生成式摘要,併為每種方法提供了PyTorch實現程式碼。最後,文章總結了摘要技術的意義和未來的挑戰,強調了其在資訊超載時代的重要性。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

1. 概述

文字摘要是自然語言處理(NLP)的一個重要分支,其核心目的是提取文字中的關鍵資訊,生成簡短、凝練的內容摘要。這不僅有助於使用者快速獲取資訊,還能有效地組織和歸納大量的文字資料。
1.1 什麼是文字摘要?
文字摘要的目標是從一個或多個文字源中提取主要思想,建立一個短小、連貫且與原文保持一致性的描述性文字。
例子: 假設有一篇新聞文章,描述了一個國家領導人的存取活動,包括他的行程、會面的外國領導人和他們討論的議題。文字摘要的任務可能是生成一段如下的摘要:「國家領導人A於日期B存取了國家C,並與領導人D討論了E議題。」
1.2 為什麼需要文字摘要?
隨著資訊量的爆炸性增長,人們需要處理的文字資料量也在快速增加。文字摘要為使用者提供了一個高效的方法,可以快速獲取文章、報告或檔案的核心內容,無需閱讀整個檔案。
例子: 在學術研究中,研究者們可能需要查閱數十篇或數百篇的文獻來撰寫文獻綜述。如果每篇文獻都有一個高質量的文字摘要,研究者們可以迅速瞭解每篇文獻的主要內容和貢獻,從而更加高效地完成文獻綜述的撰寫。
文字摘要的應用場景非常廣泛,包括但不限於新聞摘要、學術文獻摘要、商業報告摘要和醫學病歷摘要等。通過自動化的文字摘要技術,不僅可以提高資訊獲取的效率,還可以在多種應用中帶來巨大的商業價值和社會效益。
2. 發展歷程
文字摘要的歷史可以追溯到電腦科學和人工智慧的早期階段。從最初的基於規則的方法,到現今的深度學習技術,文字摘要領域的研究和應用都取得了長足的進步。
2.1 早期技術
在電腦科學早期,文字摘要主要依賴基於規則和啟發式的方法。這些方法主要根據特定的關鍵詞、短語或文字的句法結構來提取關鍵資訊。
例子: 假設在一個新聞報道中,頻繁出現的詞如「總統」、「存取」和「協定」可能會被認為是文字的關鍵內容。因此,基於這些關鍵詞,系統可能會從文字中選擇包含這些詞的句子作為摘要的內容。
2.2 統計方法的崛起
隨著統計學方法在自然語言處理中的應用,文字摘要也開始利用TF-IDF、主題模型等技術來自動生成摘要。這些方法在某種程度上改善了摘要的質量,使其更加接近人類的思考方式。
例子: 通過TF-IDF權重,可以識別出文字中的重要詞彙,然後根據這些詞彙的權重選擇句子。例如,在一篇關於環境保護的文章中,「氣候變化」和「可再生能源」可能具有較高的TF-IDF權重,因此包含這些詞彙的句子可能會被選為摘要的一部分。
2.3 深度學習的應用
近年來,隨著深度學習技術的發展,尤其是迴圈神經網路(RNN)和變壓器(Transformers)的引入,文字摘要領域得到了革命性的提升。這些技術能夠捕捉文字中的深層次語意關係,生成更為流暢和準確的摘要。
例子: 使用BERT或GPT等變壓器模型進行文字摘要,模型不僅僅是根據關鍵詞進行選擇,而是可以理解文字的整體含義,並生成與原文內容一致但更為簡潔的摘要。
2.4 文字摘要的演變趨勢
文字摘要的方法和技術持續在進化。目前,研究的焦點包括多模態摘要、互動式摘要以及對抗生成網路在摘要生成中的應用等。
例子: 在一個多模態摘要任務中,系統可能需要根據給定的文字和圖片生成一個摘要。例如,對於一個報道某項體育賽事的文章,系統不僅需要提取文字中的關鍵資訊,還需要從與文章相關的圖片中提取重要內容,將二者結合生成摘要。
3. 主要任務
文字摘要作為自然語言處理的一部分,其主要任務涉及多個方面,旨在滿足不同的應用需求。以下是文字摘要中的幾個關鍵任務,以及相關的定義和範例。
3.1 單檔案摘要
這是文字摘要的最基本形式,從一個給定的檔案中提取關鍵資訊,生成一個簡潔的摘要。
定義: 對一個單獨的檔案進行處理,提取其核心資訊,生成一個凝練的摘要。
例子: 從一篇關於某地震事件的新聞報道中提取關鍵資訊,生成摘要:「日期X,在Y地區發生了Z級地震,導致A人受傷,B人死亡。」
3.2 多檔案摘要
該任務涉及從多個相關檔案中提取和整合關鍵資訊,生成一個綜合摘要。
定義: 對一組相關的檔案進行處理,合併它們的核心資訊,生成一個綜合的摘要。
例子: 從五篇關於同一項技術大會的報道中提取關鍵資訊,生成摘要:「在日期X的技術大會上,公司Y、Z和W分別釋出了他們的最新產品,並討論了未來技術的發展趨勢。」
3.3 資訊性摘要 vs. 背景摘要
資訊性摘要重點關注檔案中的主要新聞或事件,而背景摘要則關注為讀者提供背景或上下文資訊。
定義: 資訊性摘要提供檔案的核心內容,而背景摘要提供與該內容相關的背景或上下文資訊。
例子:
- 資訊性摘要:「國家A和國家B簽署了貿易協定。」
- 背景摘要:「國家A和國家B自去年開始進行貿易談判,旨在增加兩國間的商品和服務交易。」
3.4 實時摘要
這是一種生成動態摘要的任務,特別是當資訊源持續更新時。
定義: 根據不斷流入的新資訊,實時地更新並生成摘要。
例子: 在一項體育賽事中,隨著比賽的進行,系統可以實時生成摘要,如:「第一節結束,隊伍A領先隊伍B 10分。隊伍A的球員C已經得到15分。」
4. 主要型別
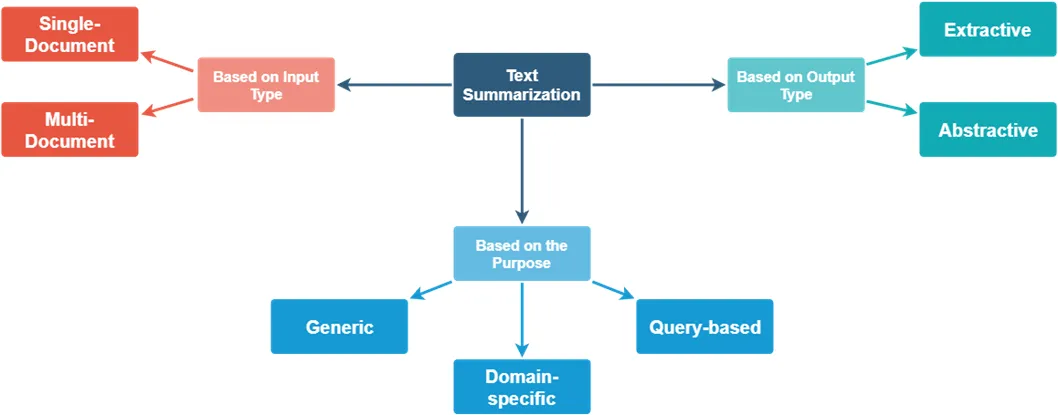
文字摘要可以根據其生成方式和特點劃分為多種型別。以下是文字摘要領域中的主要型別及其定義和範例。
4.1 抽取式摘要
這種型別的摘要直接從原文中提取句子或短語來構成摘要,而不生成新的句子。
定義: 直接從原始檔案中選擇性地提取句子或短語,以生成摘要。
例子:
原文: 「北京是中國的首都。它有著悠久的歷史和豐富的文化遺產。故宮、長城和天安門都是著名的旅遊景點。」
抽取式摘要: 「北京是中國的首都。故宮、長城和天安門都是著名的旅遊景點。」
4.2 生成式摘要
與抽取式摘要不同,生成式摘要會產生新的句子,為讀者提供更為簡潔和流暢的文字摘要。
定義: 基於原始檔案的內容,生成新的句子來構成摘要。
例子:
原文: 「北京是中國的首都。它有著悠久的歷史和豐富的文化遺產。故宮、長城和天安門都是著名的旅遊景點。」
生成式摘要: 「北京,中國的首都,以其歷史遺蹟如故宮、長城和天安門而聞名。」
4.3 指示性摘要
這種型別的摘要旨在提供檔案的大致內容,通常較為簡短。
定義: 對檔案進行快速概括,給出主要內容的簡短描述。
例子:
原文: 「微軟公司是一家總部位於美國的跨國技術公司。它是世界上最大的軟體制造商,並且生產多種消費電子產品。」
指示性摘要: 「微軟是一家大型的美國技術公司,生產軟體和消費電子。」
4.4 資訊性摘要
這種摘要提供更詳細的資訊,通常較長,涵蓋檔案的多個方面。
定義: 提供檔案的詳細內容概括,涵蓋檔案的核心資訊。
例子:
原文: 「微軟公司是一家總部位於美國的跨國技術公司。它是世界上最大的軟體制造商,並且生產多種消費電子產品。」
資訊性摘要: 「位於美國的微軟公司是全球最大的軟體生產商,同時還製造了多種消費電子產品。」
5. 抽取式文字摘要
抽取式文字摘要方法通過從原始檔案中直接提取句子或短語來形成摘要,而不重新構造新的句子。
5.1 定義
定義: 抽取式文字摘要是從原始檔案中選擇性地提取句子或短語以生成摘要的過程。該方法通常依賴於檔案中句子的重要性評分。
例子:
原文: 「北京是中國的首都。它有著悠久的歷史和豐富的文化遺產。故宮、長城和天安門都是著名的旅遊景點。」
抽取式摘要: 「北京是中國的首都。故宮、長城和天安門都是著名的旅遊景點。」
5.2 抽取式摘要的主要技術
- 基於統計:使用詞頻、逆檔案頻率等統計方法為檔案中的句子分配重要性分數。
- 基於圖:如TextRank演演算法,將句子視為圖中的節點,基於它們之間的相似性建立邊,並通過迭代過程為每個句子分配得分。
5.3 Python實現
下面是一個簡單的基於統計的抽取式摘要的Python實現:
import re
from collections import defaultdict
from nltk.tokenize import word_tokenize, sent_tokenize
def extractive_summary(text, num_sentences=2):
# 1. Tokenize the text
words = word_tokenize(text.lower())
sentences = sent_tokenize(text)
# 2. Compute word frequencies
frequency = defaultdict(int)
for word in words:
if word.isalpha(): # ignore non-alphabetic tokens
frequency[word] += 1
# 3. Rank sentences
ranked_sentences = sorted(sentences, key=lambda x: sum([frequency[word] for word in word_tokenize(x.lower())]), reverse=True)
# 4. Get the top sentences
return ' '.join(ranked_sentences[:num_sentences])
# Test
text = "北京是中國的首都。它有著悠久的歷史和豐富的文化遺產。故宮、長城和天安門都是著名的旅遊景點。"
print(extractive_summary(text))
輸入:原始文字
輸出:抽取的摘要
處理過程:該程式碼首先計算檔案中每個詞的頻率,然後根據其包含的詞頻為每個句子分配重要性得分,並返回得分最高的句子作為摘要。
6. 生成式文字摘要
與直接從檔案中提取句子的抽取式摘要方法不同,生成式文字摘要旨在為原始檔案內容生成新的、更簡潔的表達。
6.1 定義
定義: 生成式文字摘要涉及利用原始檔案內容創造新的句子和短語,為讀者提供更為簡潔且相關的資訊。
例子:
原文: 「北京是中國的首都。它有著悠久的歷史和豐富的文化遺產。故宮、長城和天安門都是著名的旅遊景點。」
生成式摘要: 「北京,中國的首都,以其歷史遺蹟如故宮、長城和天安門而聞名。」
6.2 主要技術
- 序列到序列模型 (Seq2Seq):這是一種深度學習方法,通常用於機器翻譯任務,但也被廣泛應用於生成式摘要。
- 注意力機制:在Seq2Seq模型中加入注意力機制可以幫助模型更好地關注原始檔案中的重要部分。
6.3 PyTorch實現
下面是一個簡單的Seq2Seq模型的概述,由於其複雜性,這裡只提供一個簡化版本:
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hidden_dim)
def forward(self, src):
embedded = self.embedding(src)
outputs, hidden = self.rnn(embedded)
return hidden
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim + hidden_dim, hidden_dim)
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden, context):
input = input.unsqueeze(0)
embedded = self.embedding(input)
emb_con = torch.cat((embedded, context), dim=2)
output, hidden = self.rnn(emb_con, hidden)
prediction = self.out(output.squeeze(0))
return prediction, hidden
# 注: 這是一個簡化的模型,僅用於展示目的。在實際應用中,您需要考慮新增更多細節,如注意力機制、優化器、損失函數等。
輸入: 原始檔案的詞向量序列
輸出: 生成的摘要的詞向量序列
處理過程: 編碼器首先將輸入檔案轉換為一個固定大小的隱藏狀態。然後,解碼器使用這個隱藏狀態作為上下文,逐步生成摘要的詞向量序列。
7. 總結
隨著科技的迅速發展,自然語言處理已從其原始的文書處理任務進化為複雜的多模態任務,如我們所見,文字摘要正是其中的一個明顯例子。從基本的抽取式和生成式摘要到現今的多模態摘要,每一個階段都反映了我們對資訊和知識的不斷深化和重新定義。
重要的是,我們不僅僅要關注技術如何實現這些摘要任務,更要明白為什麼我們需要這些摘要技術。摘要是對大量資訊的簡化,它可以幫助人們快速捕獲主要觀點、節省時間並提高效率。在一個資訊超載的時代,這種能力變得尤為重要。
但是,與此同時,我們也面臨著一個挑戰:如何確保生成的摘要不僅簡潔,而且準確、客觀,並且不失真。這需要我們不斷完善和調整技術,確保其在各種場景下都能提供高質量的摘要。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。