NLP機器翻譯全景:從基本原理到技術實戰全解析
機器翻譯是使計算機能夠將一種語言轉化為另一種語言的技術領域。本文從簡介、基於規則、統計和神經網路的方法入手,深入解析了各種機器翻譯策略。同時,詳細探討了評估機器翻譯效能的多種標準和工具,包括BLEU、METEOR等,以確保翻譯的準確性和質量。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

一、機器翻譯簡介
機器翻譯,作為自然語言處理的一個核心領域,一直都是研究者們關注的焦點。其目標是實現計算機自動將一種語言翻譯成另一種語言,而不需要人類的參與。
1. 什麼是機器翻譯 (MT)?

機器翻譯(MT)是一種自動將源語言文字翻譯成目標語言的技術。它使用特定的演演算法和模型,嘗試在不同語言之間實現最佳的語意對映。
範例: 當你輸入"Hello, world!"到Google翻譯,並將其從英語翻譯成法語,你會得到"Bonjour le monde!"。這就是機器翻譯的一個簡單範例。
2. 源語言和目標語言
- 源語言: 你想要翻譯的原始文字的語言。
範例: 在前面的例子中,"Hello, world!"的語言,即英語,就是源語言。
- 目標語言: 你想要將源語言文字翻譯成的語言。
範例: 在上述範例中,法語是目標語言。
3. 翻譯模型
機器翻譯的核心是翻譯模型,它可以基於規則、基於統計或基於神經網路。這些模型都試圖找到最佳的翻譯,但它們的工作原理和側重點有所不同。
範例: 一個基於規則的翻譯模型可能會有一個詞典來查詢單詞的直接對應關係。所以,它可能會將英文的"cat"直接翻譯成法文的"chat"。而一個基於統計的模型可能會考慮語料庫中的短語和句子的出現頻率,來判斷"cat"在某個上下文中是否應該翻譯成"chat"。
4. 上下文的重要性
在機器翻譯中,單獨的單詞翻譯通常是不夠的。上下文對於獲得準確翻譯至關重要。一些詞在不同的上下文中可能有不同的含義和翻譯。
範例: 英文單詞"bank"可以指"河岸"也可以指"銀行"。如果上下文中提到了"money",那麼正確的翻譯可能是"銀行"。而如果上下文中提到了"river",則"bank"應該被翻譯為"河岸"。
以上內容提供了機器翻譯的一個簡要介紹。從定義到各種細節,每一部分都是為了幫助讀者更好地理解這一複雜但令人興奮的技術領域。
二、基於規則的機器翻譯 (RBMT)
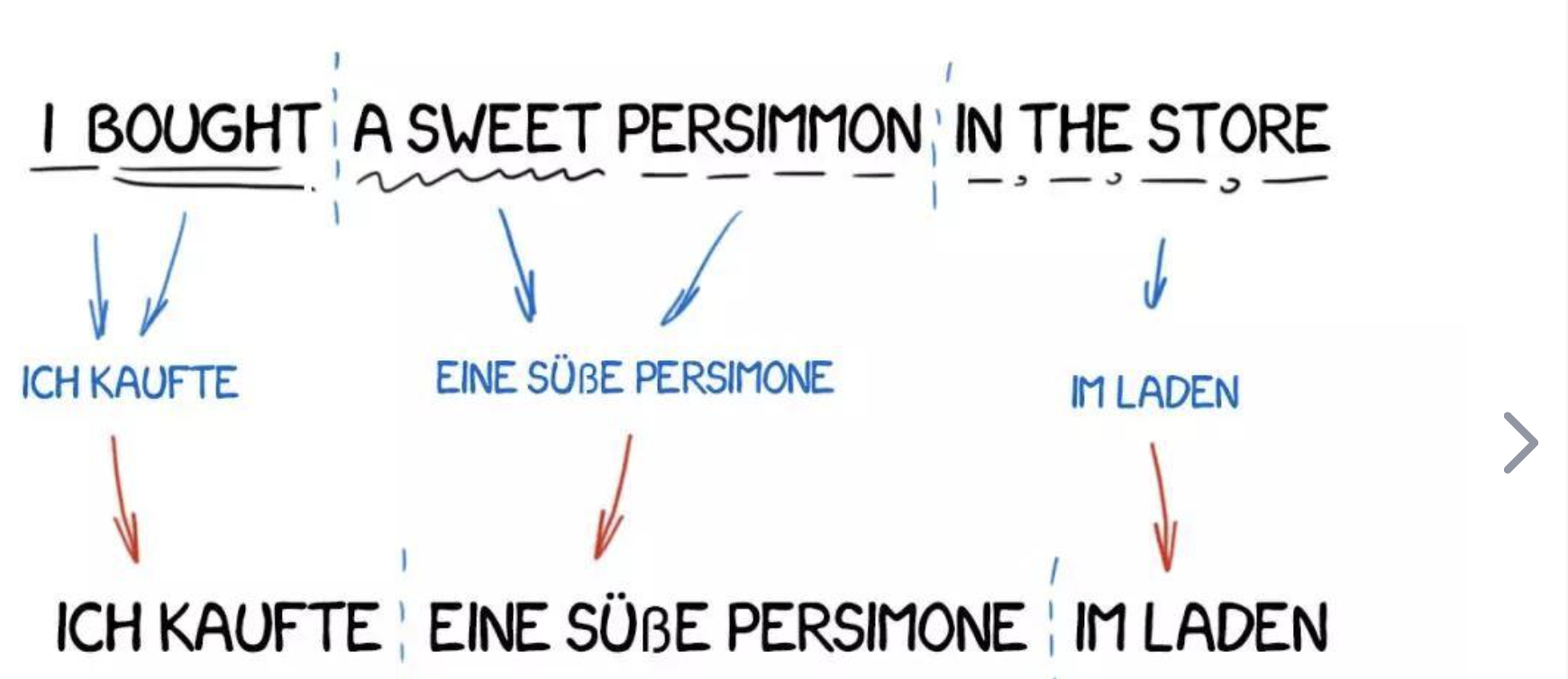
基於規則的機器翻譯(RBMT)是一種利用語言學規則將源語言文字轉換為目標語言文字的技術。這些規則通常由語言學家手工編寫,覆蓋了語法、詞彙和其他語言相關的特性。
1. 規則的制定
在RBMT中,語言學家需要為源語言和目標語言編寫大量的轉換規則。這些規則描述瞭如何根據源語言的語法結構將其轉換為目標語言的語法結構。
範例: 在英法翻譯中,英文的形容詞通常位於名詞之前,而法語的形容詞則通常位於名詞之後。因此,規則可能會指示將"red apple"翻譯為"pomme rouge"。
2. 詞典和詞彙選擇
除了語法轉換規則,RBMT還依賴於詳細的雙語詞典。這些詞典包含了源語言和目標語言之間的單詞和短語的對應關係。
範例: 詞典可能會指出英文單詞"book"可以翻譯為法文的"livre"。
3. 限制與挑戰
儘管RBMT在某些領域和應用中可以提供相對準確的翻譯,但它也面臨著一些限制。規則的數量可能會變得非常龐大,難以維護;並且,對於某些複雜和歧義的句子,規則可能無法提供準確的翻譯。
範例: "I read books on the bank." 這句話中的"bank"是指"河岸"還是"銀行"?沒有上下文,基於規則的翻譯系統可能會難以做出準確的選擇。
4. PyTorch實現
雖然現代的機器翻譯系統很少完全依賴於RBMT,但我們可以簡單地使用PyTorch來模擬一個簡化版的RBMT系統。
import torch
# 假設我們已經有了一個英法詞典
dictionary = {
"red": "rouge",
"apple": "pomme"
}
def rule_based_translation(sentence: str) -> str:
translated_words = []
for word in sentence.split():
translated_words.append(dictionary.get(word, word))
return ' '.join(translated_words)
# 輸入輸出範例
sentence = "red apple"
print(rule_based_translation(sentence)) # 輸出: rouge pomme
在這個簡單的例子中,我們定義了一個基本的英法詞典,並建立了一個函數來執行基於規則的翻譯。這只是一個非常簡化的範例,真實的RBMT系統將涉及更復雜的語法和結構轉換規則。
三、基於統計的機器翻譯 (SMT)

基於統計的機器翻譯 (SMT) 利用統計模型從大量雙語文字資料中學習如何將源語言翻譯為目標語言。與依賴語言學家手工編寫規則的RBMT不同,SMT自動從資料中學習翻譯規則和模式。
1. 資料驅動
SMT系統通常從雙語語料庫(包含源語言文字和其對應的目標語言翻譯)中學習。通過分析成千上萬的句子對,系統學會了詞語、短語和句子的最有可能的翻譯。
範例: 如果在許多不同的句子對中,「cat」經常被翻譯為「chat」,系統將學習到這種對應關係。
2. 短語對齊
SMT通常使用所謂的「短語表」,這是從雙語語料庫中自動提取的短語對齊的列表。
範例: 系統可能會從句子對中學習到"take a break"對應於法文中的"prendre une pause"。
3. 評分和選擇
SMT使用多個統計模型來評估和選擇最佳的翻譯。這包括語言模型(評估目標語言翻譯的流暢性)和翻譯模型(評估翻譯的準確性)。
範例: 在翻譯"apple pie"時,系統可能會生成多個候選翻譯,然後選擇評分最高的那個。
4. PyTorch實現
完整的SMT系統非常複雜,涉及多個元件和複雜的模型。但為了說明,我們可以使用PyTorch建立一個簡化的基於統計的詞對齊模型:
import torch
import torch.nn as nn
import torch.optim as optim
# 假設我們有一些雙語句子對資料
source_sentences = ["apple", "red fruit"]
target_sentences = ["pomme", "fruit rouge"]
# 將句子轉換為單詞索引
source_vocab = {"apple": 0, "red": 1, "fruit": 2}
target_vocab = {"pomme": 0, "fruit": 1, "rouge": 2}
source_indices = [[source_vocab[word] for word in sentence.split()] for sentence in source_sentences]
target_indices = [[target_vocab[word] for word in sentence.split()] for sentence in target_sentences]
# 簡單的對齊模型
class AlignmentModel(nn.Module):
def __init__(self, source_vocab_size, target_vocab_size, embedding_dim=8):
super(AlignmentModel, self).__init__()
self.source_embedding = nn.Embedding(source_vocab_size, embedding_dim)
self.target_embedding = nn.Embedding(target_vocab_size, embedding_dim)
self.alignment = nn.Linear(embedding_dim, embedding_dim, bias=False)
def forward(self, source, target):
source_embed = self.source_embedding(source)
target_embed = self.target_embedding(target)
scores = torch.matmul(source_embed, self.alignment(target_embed).transpose(1, 2))
return scores
model = AlignmentModel(len(source_vocab), len(target_vocab))
criterion = nn.CosineEmbeddingLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 訓練模型
for epoch in range(1000):
total_loss = 0
for src, tgt in zip(source_indices, target_indices):
src = torch.LongTensor(src)
tgt = torch.LongTensor(tgt)
scores = model(src.unsqueeze(0), tgt.unsqueeze(0))
loss = criterion(scores, torch.ones_like(scores), torch.tensor(1.0))
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {total_loss}")
# 輸入: apple
# 輸出: pomme (根據得分選擇最佳匹配的詞)
此程式碼為一個簡單的詞對齊模型,它試圖學習源詞和目標詞之間的對齊關係。這只是SMT的冰山一角,完整的系統會涉及句子級別的對齊、短語提取、多個統計模型等。
四、基於神經網路的機器翻譯
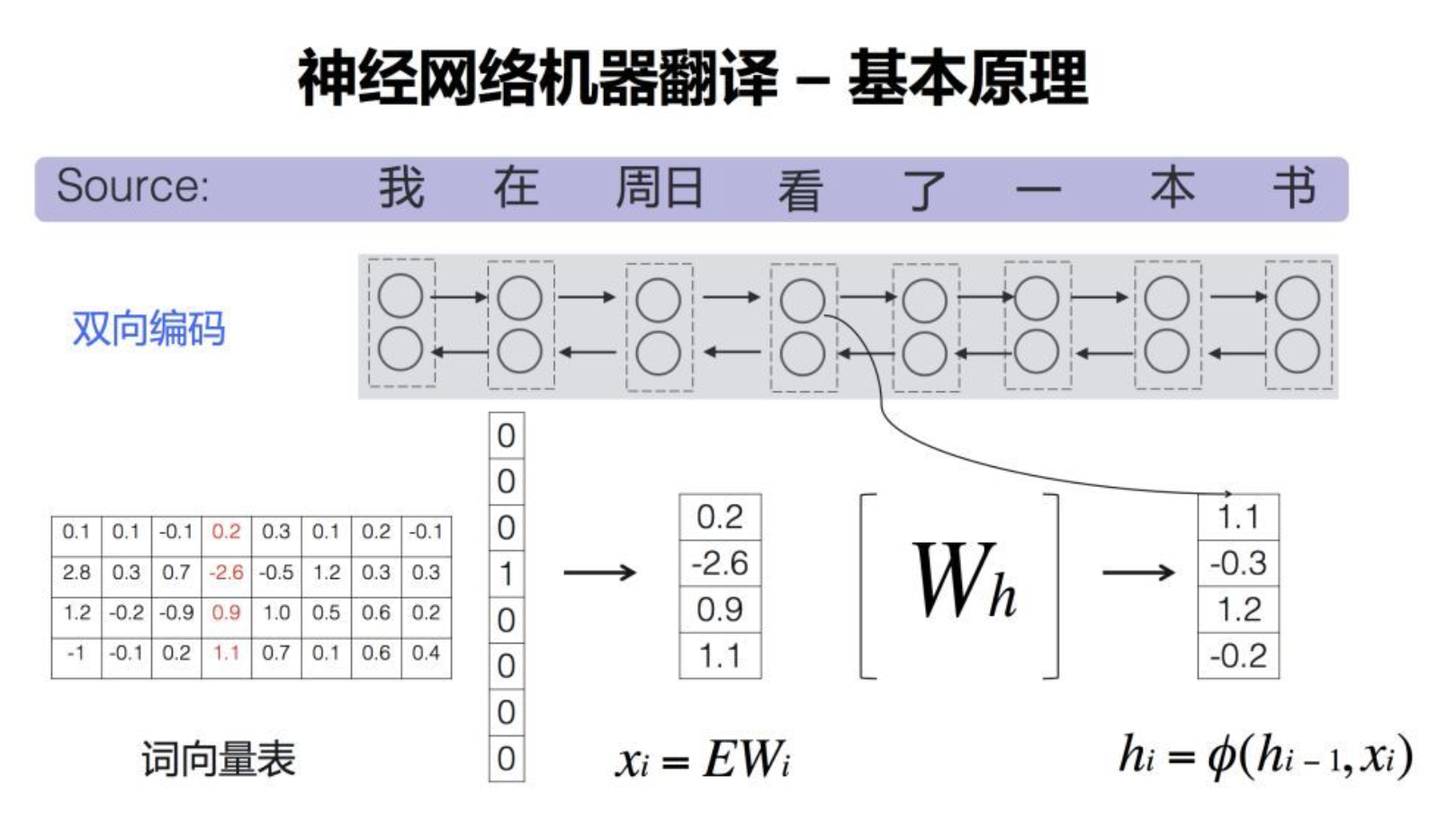
基於神經網路的機器翻譯(NMT)使用深度學習技術,特別是遞迴神經網路(RNN)、長短時記憶網路(LSTM)或Transformer結構,以端到端的方式進行翻譯。它直接從源語言到目標語言的句子或序列進行對映,不需要複雜的特性工程或中間步驟。
1. Encoder-Decoder結構
NMT的核心是Encoder-Decoder結構。Encoder將源語句編碼為一個固定大小的向量,而Decoder將這個向量解碼為目標語句。
範例: 在將英文句子 "I am learning" 翻譯成法文 "Je suis en train d'apprendre" 時,Encoder首先將英文句子轉換為一個向量,然後Decoder使用這個向量來生成法文句子。
2. Attention機制
Attention機制允許模型在解碼時「關注」源句子中的不同部分。這使得翻譯更加準確,尤其是對於長句子。
範例: 在翻譯 "I am learning to translate with neural networks" 時,當模型生成 "réseaux"(網路)這個詞時,它可能會特別關注源句中的 "networks"。
3. 詞嵌入
詞嵌入是將單詞轉換為向量的技術,這些向量捕捉單詞的語意資訊。NMT模型通常使用預訓練的詞嵌入,如Word2Vec或GloVe,但也可以在訓練過程中學習詞嵌入。
範例: "king" 和 "queen" 的向量可能會在向量空間中很接近,因為它們都是關於皇室的。
4. PyTorch實現
以下是一個簡單的基於LSTM和Attention的NMT模型實現範例:
import torch
import torch.nn as nn
import torch.optim as optim
# 為簡化,定義一個小的詞彙表和資料
source_vocab = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "I": 3, "am": 4, "learning": 5}
target_vocab = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "Je": 3, "suis": 4, "apprenant": 5}
source_sentences = [["<SOS>", "I", "am", "learning", "<EOS>"]]
target_sentences = [["<SOS>", "Je", "suis", "apprenant", "<EOS>"]]
# 引數
embedding_dim = 256
hidden_dim = 512
vocab_size = len(source_vocab)
target_vocab_size = len(target_vocab)
# Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
def forward(self, x):
x = self.embedding(x)
outputs, (hidden, cell) = self.lstm(x)
return outputs, (hidden, cell)
# Attention and Decoder
class DecoderWithAttention(nn.Module):
def __init__(self):
super(DecoderWithAttention, self).__init__()
self.embedding = nn.Embedding(target_vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim + hidden_dim, hidden_dim, batch_first=True)
self.attention = nn.Linear(hidden_dim + hidden_dim, 1)
self.fc = nn.Linear(hidden_dim, target_vocab_size)
def forward(self, x, encoder_outputs, hidden, cell):
x = self.embedding(x)
seq_length = encoder_outputs.shape[1]
hidden_repeat = hidden.repeat(seq_length, 1, 1).permute(1, 0, 2)
attention_weights = torch.tanh(self.attention(torch.cat((encoder_outputs, hidden_repeat), dim=2)))
attention_weights = torch.softmax(attention_weights, dim=1)
context = torch.sum(attention_weights * encoder_outputs, dim=1).unsqueeze(1)
x = torch.cat((x, context), dim=2)
outputs, (hidden, cell) = self.lstm(x, (hidden, cell))
x = self.fc(outputs)
return x, hidden, cell
# Training loop
encoder = Encoder()
decoder = DecoderWithAttention()
optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=0.001)
criterion = nn.CrossEntropyLoss(ignore_index=0
)
for epoch in range(1000):
for src, tgt in zip(source_sentences, target_sentences):
src = torch.tensor([source_vocab[word] for word in src]).unsqueeze(0)
tgt = torch.tensor([target_vocab[word] for word in tgt]).unsqueeze(0)
optimizer.zero_grad()
encoder_outputs, (hidden, cell) = encoder(src)
decoder_input = tgt[:, :-1]
decoder_output, _, _ = decoder(decoder_input, encoder_outputs, hidden, cell)
loss = criterion(decoder_output.squeeze(1), tgt[:, 1:].squeeze(1))
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
# 輸入: <SOS> I am learning <EOS>
# 輸出: <SOS> Je suis apprenant <EOS>
此程式碼展示了一個基於注意力的NMT模型,從源語句到目標語句的對映。這只是NMT的基礎,更高階的模型如Transformer會有更多的細節和技術要點。
五、評價和評估方法
機器翻譯的評價是衡量模型效能的關鍵部分。準確、流暢和自然的翻譯輸出是我們的目標,但如何量化這些目標並確定模型的質量呢?
1. BLEU Score
BLEU(Bilingual Evaluation Understudy)分數是機器翻譯中最常用的自動評估方法。它通過比較機器翻譯輸出和多個參考翻譯之間的n-gram重疊來工作。
範例: 假設機器的輸出是 "the cat is on the mat",而參考輸出是 "the cat is sitting on the mat"。1-gram精度是5/6,2-gram精度是4/5,以此類推。BLEU分數會考慮到這些各級的精度。
2. METEOR
METEOR(Metric for Evaluation of Translation with Explicit ORdering)是另一個評估機器翻譯的方法,它考慮了同義詞匹配、詞幹匹配以及詞序。
範例: 如果機器輸出是 "the pet is on the rug",而參考翻譯是 "the cat is on the mat",儘管有些詞不完全匹配,但METEOR會認為"pet"和"cat"、"rug"和"mat"之間有某種相似性。
3. ROUGE
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 通常用於評估自動文摘,但也可以用於機器翻譯。它考慮了機器翻譯輸出和參考翻譯之間的n-gram的召回率。
範例: 對於同樣的句子 "the cat is on the mat" 和 "the cat is sitting on the mat",ROUGE-1召回率為6/7。
4. TER
TER (Translation Edit Rate) 衡量了將機器翻譯輸出轉換為參考翻譯所需的最少編輯次數(如插入、刪除、替換等)。
範例: 對於 "the cat sat on the mat" 和 "the cat is sitting on the mat",TER是1/7,因為需要新增一個"is"。
5. 人工評估
儘管自動評估方法提供了快速的反饋,但人工評估仍然是確保翻譯質量的金標準。評估者通常會根據準確性、流暢性和是否忠實於源文字來評分。
範例: 一個句子可能獲得滿分的BLEU分數,但如果其翻譯內容與源內容的意圖不符,或者讀起來不自然,那麼人類評估者可能會給予較低的評分。
總的來說,評估機器翻譯的效能是一個多方面的任務,涉及到多種工具和方法。理想情況下,研究者和開發者會結合多種評估方法,以獲得對模型效能的全面瞭解。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。