詞!自然語言處理之詞全解和Python實戰!
本文全面探討了詞在自然語言處理(NLP)中的多維角色。從詞的基礎概念、形態和詞性,到詞語處理技術如規範化、切分和詞性還原,文章深入解析了每一個環節的技術細節和應用背景。特別關注了詞在多語言環境和具體NLP任務,如文字分類和機器翻譯中的應用。文章通過Python和PyTorch程式碼範例,展示瞭如何在實際應用中實施這些技術。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
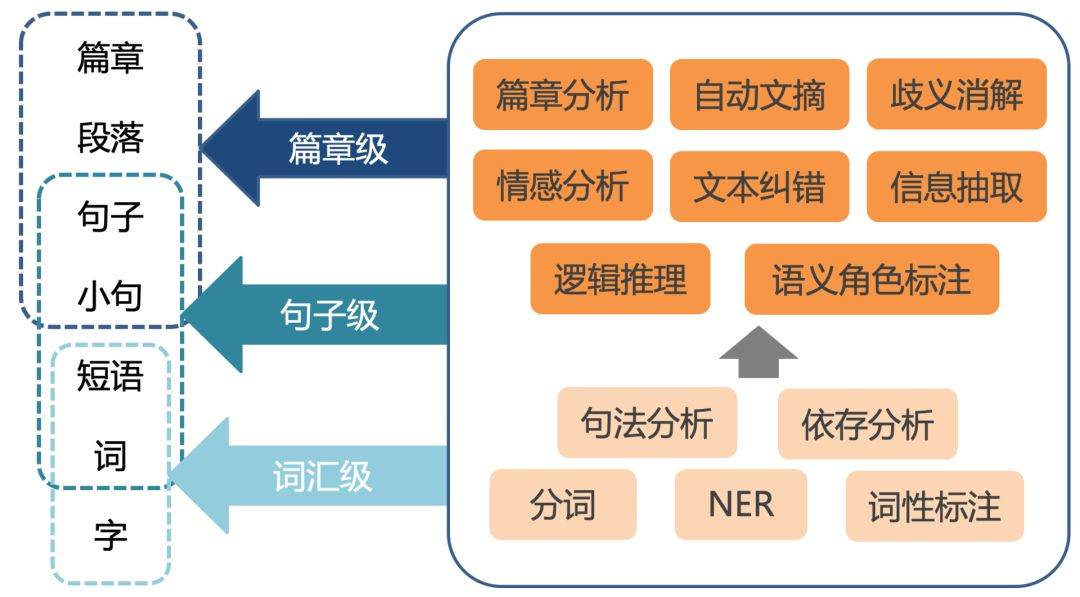
一、為什麼我們需要了解「詞」的各個方面
在自然語言處理(NLP,Natural Language Processing)領域,「詞」構成了語言的基礎單位。與此同時,它們也是構建高階語意和語法結構的基石。在解決各種NLP問題,如機器翻譯、情感分析、問答系統等方面,對「詞」的全面瞭解不僅有助於我們設計更高效的演演算法,還能加深我們對語言本質的認識。
詞是語言的基礎單位
在任何語言中,詞都是最基礎的組成單位。就像建築物是由磚塊堆砌而成的,自然語言也是由詞組合而成的。一個詞能攜帶多種資訊,包括但不限於它的意義(語意)、它在句子中的功能(語法)以及它與其他詞的關係(語境)。因此,對「詞」的研究從根本上影響了我們對更高層次自然語言處理任務的理解和處理能力。
詞的多維特性
詞不僅具有表面形態(如拼寫和發音),還有其詞性、語境和多種可能的含義。例如,詞性標註能告訴我們一個詞是名詞、動詞還是形容詞,這有助於我們理解它在句子或段落中的作用。詞的這些多維特性使得它在自然語言處理中具有多樣的應用場景和挑戰。
詞在NLP應用中的關鍵作用
-
文字分類和情感分析: 通過分析詞的頻率、順序和詞性,我們可以對文字進行分類,或者確定文字的情感傾向。
-
搜尋引擎: 在資訊檢索中,詞的重要性是顯而易見的。詞項權重(例如TF-IDF)和詞的語意關聯(例如Word2Vec)是搜尋引擎排序演演算法的關鍵要素。
-
機器翻譯: 理解詞在不同語言中的對應關係和語意差異是實現高質量機器翻譯的前提。
-
語音識別和生成: 詞在語音識別和文字到語音(TTS)系統中也扮演著關鍵角色。準確地識別和生成詞是這些系統成功的關鍵。
二、詞的基礎

在深入研究自然語言處理的高階應用之前,瞭解「詞」的基礎知識是至關重要的。這一部分將側重於詞的定義、分類、形態和詞性。
什麼是詞?
定義
在語言學中,對「詞」的定義可以多種多樣。但在自然語言處理(NLP)的環境下,我們通常將詞定義為最小的獨立意義單位。它可以是單獨出現的,也可以是與其他詞共同出現以構成更復雜的意義。在程式設計和演演算法處理中,一個詞通常由一系列字元組成,這些字元之間以空格或特定的分隔符分隔。
分類
-
實詞與虛詞
- 實詞:具有實際意義,如名詞、動詞、形容詞。
- 虛詞:主要用於連線和修飾實詞,如介詞、連詞。
-
單詞與複合詞
- 單詞:由單一的詞根或詞幹構成。
- 複合詞:由兩個或多個詞根或詞幹組合而成,如「toothbrush」。
-
開放類與封閉類
- 開放類:新詞容易新增進來,如名詞、動詞。
- 封閉類:固定不變,新詞很難加入,如介詞、代詞。
詞的形態
詞根、詞幹和詞綴
-
詞根(Root): 是詞的核心部分,攜帶了詞的主要意義。
- 例如,在「unhappiness」中,「happy」是詞根。
-
詞幹(Stem): 由詞根加上必要的詞綴組成,是詞的基礎形態。
- 例如,在「running」中,「runn」是詞幹。
-
詞綴(Affixes): 包括字首、字尾、詞中綴和詞尾綴,用於改變詞的意義或詞性。
- 字首(Prefix):出現在詞根前,如「un-」在「unhappy」。
- 字尾(Suffix):出現在詞根後,如「-ing」在「running」。
形態生成
詞的形態通過規則和不規則的變化進行生成。規則變化通常通過新增詞綴來實現,而不規則變化通常需要查詢詞形變化的資料表。
詞的詞性
詞性是描述詞在句子中充當的語法角色的分類,這是自然語言處理中非常重要的一環。
- 名詞(Noun): 用於表示人、地點、事物或概念。
- 動詞(Verb): 表示動作或狀態。
- 形容詞(Adjective): 用於描述名詞。
- 副詞(Adverb): 用於修飾動詞、形容詞或其他副詞。
- 代詞(Pronoun): 用於代替名詞。
- 介詞(Preposition): 用於表示名詞與其他詞之間的關係。
- 連詞(Conjunction): 用於連線詞、短語或子句。
- 感嘆詞(Interjection): 用於表達情感或反應。
三、詞語處理技術

在掌握了詞的基礎知識之後,我們將轉向一些具體的詞語處理技術。這些技術為詞在自然語言處理(NLP)中的更高階應用提供了必要的工具和方法。
詞語規範化
定義
詞語規範化是將不同形態或者拼寫的詞語轉換為其標準形式的過程。這一步是文字預處理中非常重要的一環。
方法
- 轉為小寫: 最基礎的規範化步驟,特別是對於大小寫不敏感的應用。
- 去除標點和特殊字元: 有助於減少詞彙表大小和提高模型的泛化能力。
詞語切分(Tokenization)
定義
詞語切分是將文字分割成詞、短語、符號或其他有意義的元素(稱為標記)的過程。
方法
- 空格切分: 最簡單的切分方法,但可能無法正確處理像「New York」這樣的複合詞。
- 正規表示式: 更為複雜但靈活的切分方式。
- 基於詞典的切分: 使用預定義的詞典來查詢和切分詞語。
詞性還原(Lemmatization)與詞幹提取(Stemming)
詞性還原
- 定義: 將一個詞轉換為其詞典形式。
- 例子: 「running」 -> 「run」,「mice」 -> 「mouse」
詞幹提取
- 定義: 剪下掉詞的詞綴以得到詞幹。
- 例子: 「running」 -> 「run」,「flies」 -> 「fli」
中文分詞
- 基於字典的方法: 如最大匹配演演算法。
- 基於統計的方法: 如隱馬爾科夫模型(HMM)。
- 基於深度學習的方法: 如Bi-LSTM。
英文分詞
- 基於規則的方法: 如使用正規表示式。
- 基於統計的方法: 如使用n-gram模型。
- 基於深度學習的方法: 如Transformer模型。
詞性標註(Part-of-Speech Tagging)
定義
詞性標註是為每個詞分配一個詞性標籤的過程。
方法
- 基於規則的方法: 如決策樹。
- 基於統計的方法: 如條件隨機場(CRF)。
- 基於深度學習的方法: 如BERT。
四、多語言詞處理

隨著全球化和多文化交流的加速,多語言詞處理在自然語言處理(NLP)領域的重要性日益增加。不同語言有各自獨特的語法結構、詞彙和文化背景,因此在多語言環境中進行有效的詞處理具有其特殊的挑戰和需求。
語言模型適應性
Transfer Learning
遷移學習是一種讓一個在特定任務上訓練過的模型適應其他相關任務的技術。這在處理低資源語言時尤為重要。
Multilingual BERT
多語言BERT(mBERT)是一個多工可適應多種語言的預訓練模型。它在多語言詞處理任務中,如多語言詞性標註、命名實體識別(NER)等方面表現出色。
語言特異性
形態豐富性
像芬蘭語和土耳其語這樣的形態豐富的語言,單一的詞可以表達一個完整的句子在其他語言中需要的資訊。這需要更為複雜的形態分析演演算法。
字元集和編碼
不同的語言可能使用不同的字元集,例如拉丁字母、漢字、阿拉伯字母等。正確的字元編碼和解碼(如UTF-8,UTF-16)是多語言處理中的基礎。
多語言詞向量
FastText
FastText 是一種生成詞向量的模型,它考慮了詞的內部結構,因此更適用於形態豐富的語言。
Byte Pair Encoding (BPE)
位元組對編碼(BPE)是一種用於處理多語言和未登入詞的詞分割演演算法。
程式碼範例:多語言詞性標註
以下是使用 Python 和 PyTorch 利用 mBERT 進行多語言詞性標註的範例程式碼。
from transformers import BertTokenizer, BertForTokenClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertForTokenClassification.from_pretrained('bert-base-multilingual-cased')
inputs = tokenizer("Hola mundo", return_tensors="pt")
labels = torch.tensor([1] * inputs["input_ids"].size(1)).unsqueeze(0)
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
# 輸出詞性標註結果
print(logits)
註釋:這個簡單的範例演示瞭如何使用mBERT進行多語言詞性標註。
五、詞在自然語言處理中的應用
在自然語言處理(NLP)中,詞是資訊的基礎單位。此部分將詳細介紹詞在NLP中的各種應用,特別是詞嵌入(Word Embeddings)的重要性和用途。
5.1 詞嵌入
定義和重要性
詞嵌入是用來將文字中的詞對映為實數向量的技術。詞嵌入不僅捕捉詞的語意資訊,還能捕捉到詞與詞之間的相似性和多樣性(例如,同義詞或反義詞)。
演演算法和模型
- Word2Vec: 通過預測詞的上下文,或使用上下文預測詞來訓練嵌入。
- GloVe: 利用全域性詞頻統計資訊來生成嵌入。
- FastText: 基於Word2Vec,但考慮了詞內字元的資訊。
程式碼範例:使用Word2Vec
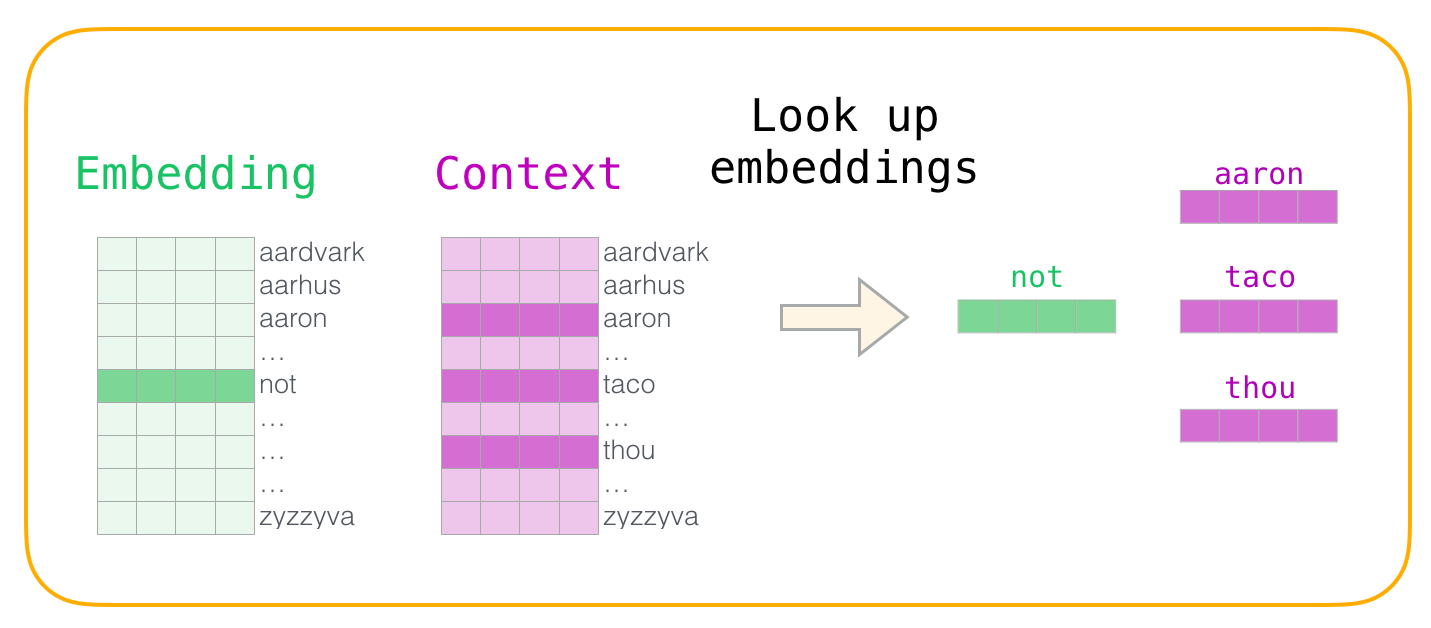
下面的例子使用Python和PyTorch實現了一個簡單的Word2Vec模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定義模型
class Word2Vec(nn.Module):
def __init__(self, vocab_size, embed_size):
super(Word2Vec, self).__init__()
self.in_embed = nn.Embedding(vocab_size, embed_size)
self.out_embed = nn.Embedding(vocab_size, embed_size)
def forward(self, target, context):
in_embeds = self.in_embed(target)
out_embeds = self.out_embed(context)
scores = torch.matmul(in_embeds, torch.t(out_embeds))
return scores
# 詞彙表大小和嵌入維度
vocab_size = 5000
embed_size = 300
# 初始化模型、損失和優化器
model = Word2Vec(vocab_size, embed_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 假設target和context已經準備好
target = torch.tensor([1, 2, 3]) # 目標詞ID
context = torch.tensor([2, 3, 4]) # 上下文詞ID
# 前向傳播和損失計算
scores = model(target, context)
loss = criterion(scores, context)
# 反向傳播和優化
loss.backward()
optimizer.step()
# 輸出嵌入向量
print(model.in_embed.weight)
註釋:
- 輸入:
target和context是目標詞和上下文詞的整數ID。 - 輸出:
scores是目標詞和上下文詞之間的相似性得分。
5.2 詞在文字分類中的應用
文字分類是自然語言處理中的一個核心任務,它涉及將文字檔案分配給預定義的類別或標籤。在這一節中,我們將重點討論如何使用詞(特別是詞嵌入)來實現有效的文字分類。
任務解析
在文字分類中,每個檔案(或句子、段落等)都被轉換成一個特徵向量,然後用這個特徵向量作為機器學習模型的輸入。這裡,詞嵌入起著至關重要的作用:它們將文字中的每個詞轉換為一個實數向量,捕捉其語意資訊。
程式碼範例:使用LSTM進行文字分類
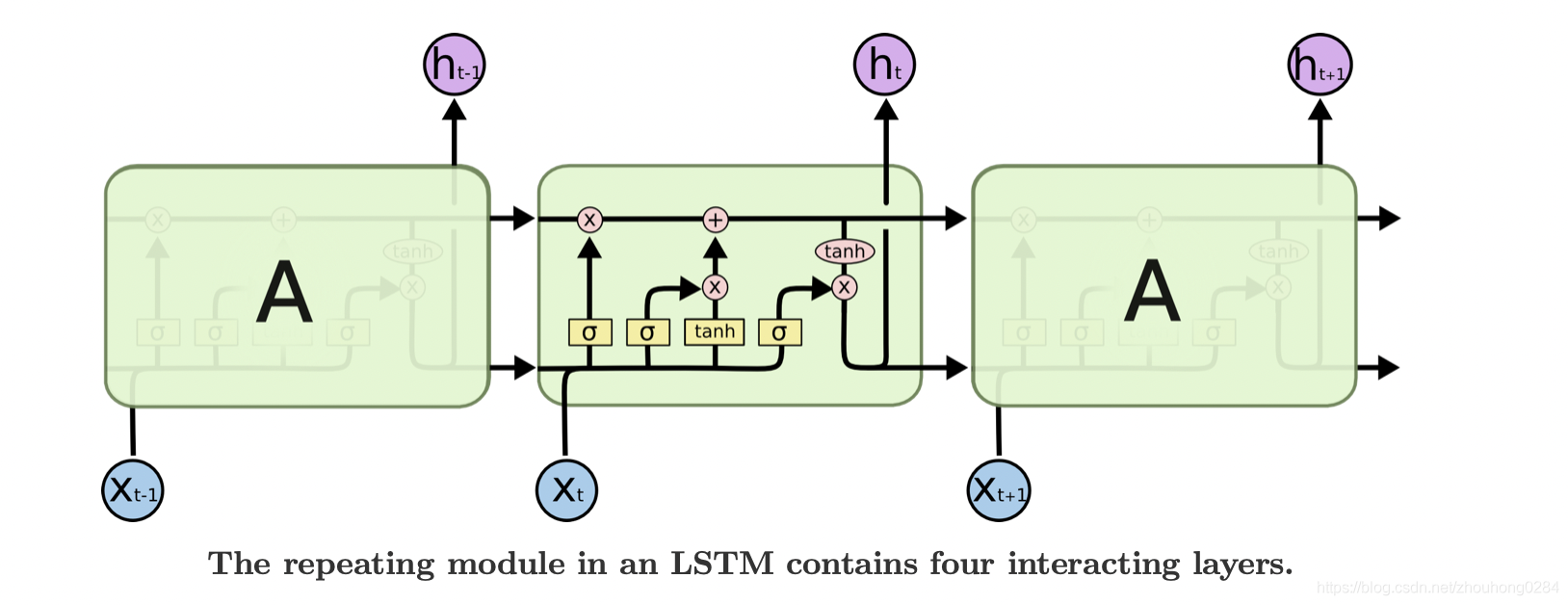
下面是一個使用PyTorch和LSTM(長短時記憶網路)進行文字分類的簡單例子:
import torch
import torch.nn as nn
import torch.optim as optim
# 定義LSTM模型
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_size, num_classes):
super(TextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, 128)
self.fc = nn.Linear(128, num_classes)
def forward(self, x):
x = self.embedding(x)
lstm_out, _ = self.lstm(x)
lstm_out = lstm_out[:, -1, :]
output = self.fc(lstm_out)
return output
# 初始化模型、損失函數和優化器
vocab_size = 5000
embed_size = 100
num_classes = 5
model = TextClassifier(vocab_size, embed_size, num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 假設輸入資料和標籤已經準備好
input_data = torch.LongTensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 文字資料(詞ID)
labels = torch.LongTensor([0, 1, 2]) # 類別標籤
# 前向傳播
output = model(input_data)
# 計算損失
loss = criterion(output, labels)
# 反向傳播和優化
loss.backward()
optimizer.step()
# 輸出結果
print("Output Class Probabilities:", torch.softmax(output, dim=1))
註釋:
- 輸入:
input_data是文字資料,每行代表一個檔案,由詞ID構成。 - 輸出:
output是每個檔案對應各個類別的預測得分。
5.3 詞在機器翻譯中的應用
機器翻譯是一種將一種自然語言(源語言)的文字自動翻譯為另一種自然語言(目標語言)的技術。在這一節中,我們將重點介紹序列到序列(Seq2Seq)模型在機器翻譯中的應用,並討論詞如何在這一過程中發揮作用。
任務解析
在機器翻譯任務中,輸入是源語言的一段文字(通常為一句話或一個短語),輸出是目標語言的等效文字。這裡,詞嵌入用於捕獲源語言和目標語言中詞的語意資訊,並作為序列到序列模型的輸入。
程式碼範例:使用Seq2Seq模型進行機器翻譯
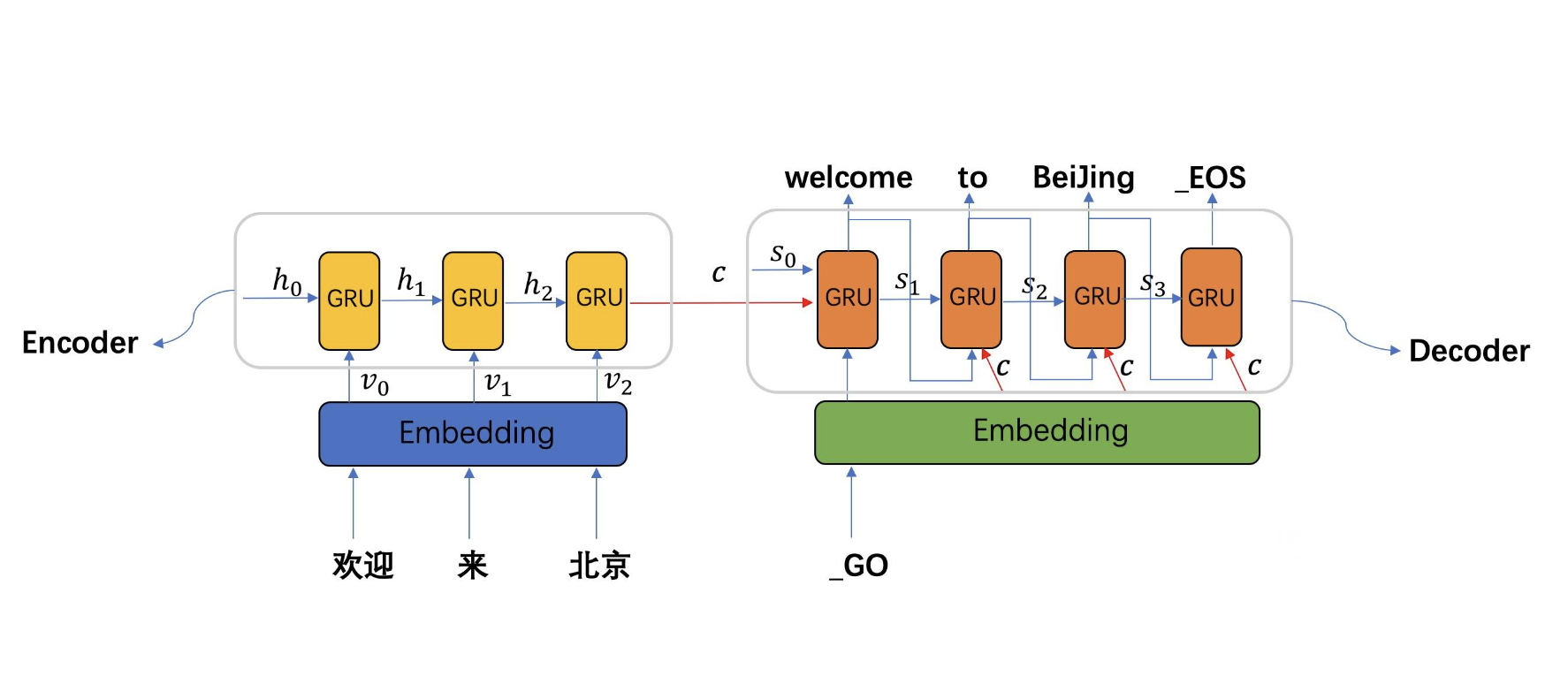
下面是一個使用PyTorch實現的簡單Seq2Seq模型範例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定義Seq2Seq模型
class Seq2Seq(nn.Module):
def __init__(self, input_vocab_size, output_vocab_size, embed_size):
super(Seq2Seq, self).__init__()
self.encoder = nn.Embedding(input_vocab_size, embed_size)
self.decoder = nn.Embedding(output_vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, 128)
self.fc = nn.Linear(128, output_vocab_size)
def forward(self, src, trg):
src_embed = self.encoder(src)
trg_embed = self.decoder(trg)
encoder_output, _ = self.rnn(src_embed)
decoder_output, _ = self.rnn(trg_embed)
output = self.fc(decoder_output)
return output
# 初始化模型、損失函數和優化器
input_vocab_size = 3000
output_vocab_size = 3000
embed_size = 100
model = Seq2Seq(input_vocab_size, output_vocab_size, embed_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 假設輸入(源語言)和輸出(目標語言)資料已經準備好
src_data = torch.LongTensor([[1, 2, 3], [4, 5, 6]]) # 源語言文字(詞ID)
trg_data = torch.LongTensor([[7, 8, 9], [10, 11, 12]]) # 目標語言文字(詞ID)
# 前向傳播
output = model(src_data, trg_data)
# 計算損失
loss = criterion(output.view(-1, output_vocab_size), trg_data.view(-1))
# 反向傳播和優化
loss.backward()
optimizer.step()
# 輸出結果
print("Output Translated IDs:", torch.argmax(output, dim=2))
註釋:
- 輸入:
src_data是源語言的文字資料,每行代表一個檔案,由詞ID構成。 - 輸出:
output是目標語言文字的預測得分。
六、總結
詞是自然語言處理的基本構建塊,但其處理絕非單一或直觀。從詞形態到詞嵌入,每一個步驟都有其複雜性和多樣性,這直接影響了下游任務如文字分類、情感分析和機器翻譯的效能。詞的正確處理,包括但不限於詞性標註、詞幹提取、和詞嵌入,不僅增強了模型的語意理解能力,還有助於緩解資料稀疏性問題和提高模型泛化。特別是在使用深度學習模型如Seq2Seq和Transformer時,對詞的精細處理更能發揮關鍵作用,例如在機器翻譯任務中通過注意力機制準確地對齊源語言和目標語言的詞。因此,對詞的全維度理解和處理是提高NLP應用效能的關鍵步驟。
關注TechLead,分享AI全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。