字串匹配演演算法:KMP
Knuth–Morris–Pratt(KMP)是由三位數學家克努斯、莫里斯、普拉特同時發現,所有人們用三個人的名字來稱呼這種演演算法,KMP是一種改進的字串匹配演演算法,它的核心是利用匹配失敗後的資訊,儘量減少模式串與主串的匹配次數以達到快速匹配的目的。它的時間複雜度是 O(m+n)
字元匹配:給你兩個字串 haystack 和 needle ,請你在 haystack 字串中找出 needle 字串的第一個匹配項的下標(下標從 0 開始)。如果 needle 不是 haystack 的一部分,則返回 -1
在介紹KMP演演算法之前,我們先看一下另一種暴力演演算法(BF演演算法)去解字元匹配應該怎麼做
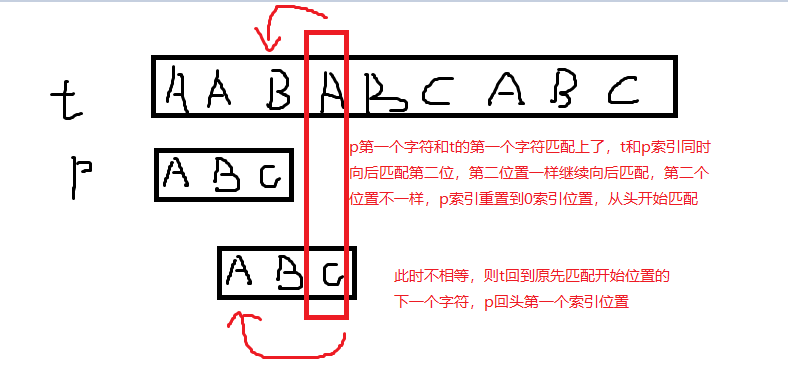
BF演演算法:時間複雜度O(m*n)
class Solution: def strStr(self, haystack: str, needle: str) -> int: #hi是haystack的當前索引 hi = 0 haystackLength = len(haystack) needleLength = len(needle) for i in range(haystackLength - needleLength+1): #每次匹配等於和完整的needle的字串逐一匹配 if haystack[i:i+needleLength] == needle: return i return -1
KMP演演算法:時間複雜度O(m+n)
KMP構造了一個next列表來對應改位置索引如果匹配失敗應該追溯回到什麼位置,這樣我們講減少了匹配次數
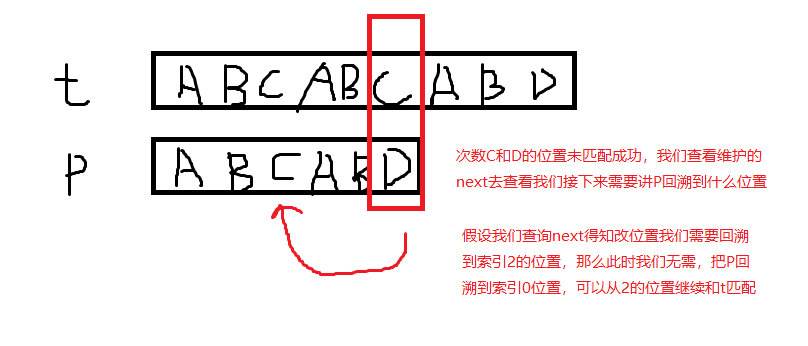
那麼我們如何去構造維護我們的next(最長相同前字尾)
構造方法為:next[i] 對應的下標,為 P[0...i - 1] 的最長公共字首字尾的長度,令 next[0] = -1。 具體解釋如下:
例如對於字串 abcba:
字首:它的字首包括:a, ab, abc, abcb,不包括本身;
字尾:它的字尾包括:bcba, cba, ba, a,不包括本身;
最長公共字首字尾:abcba 的字首和字尾中只有 a 是公共部分,字串 a 的長度為 1
我們通過動態規劃來維護next,假設你知道next[0:i-1]位置上所有的回溯值,那麼next[i-1]和next[i]相比僅僅多了一個位置,如果這個多的字元可以匹配上,那麼next[i]一定等於next[i-1]+1(如下圖所示)

那麼如果匹配不上呢,匹配不上我們回溯到next[i-1]所需要回溯的位置,直到可以匹配上或到達無法追溯的位置next[0] = -1
@staticmethod def same_start_end_str(p): """ 通過needle串來知道每個索引位置對應的最長前字尾 例如ababa的最長前字尾是aba,前字尾是不和needle等長的最長相同前字尾 """ next = [-1] * (len(p)+1) si = -1 ei = 0 pl = len(p) while ei < pl : if si == -1 or p[si] == p[ei]: si += 1 ei += 1 next[ei] = si else: #無法匹配上,繼續向前追溯 si = next[si] return next
那我們有了next就可以取實現我們KMP演演算法了,完整程式碼如下
class Solution: def strStr(self, haystack: str, needle: str) -> int: next = self.same_start_end_str(needle) #hi是haystack當前索引,ni是needle當前索引 hi = ni = 0 hl = len(haystack) nl = len(needle) while hi < hl and ni < nl: if ni == -1 or haystack[hi] == needle[ni]: hi += 1 ni += 1 else: ni = next[ni] if ni == nl: return hi - ni else: return -1 @staticmethod def same_start_end_str(p): """ 通過needle串來知道每個索引位置對應的最長前字尾 例如ababa的最長前字尾是aba,前字尾是不和needle等長的最長相同前字尾 """ next = [-1] * (len(p)+1) si = -1 ei = 0 pl = len(p) while ei < pl : if si == -1 or p[si] == p[ei]: si += 1 ei += 1 next[ei] = si else: #無法匹配上,繼續向前追溯 si = next[si] return next
作者: yetangjian
出處: https://www.cnblogs.com/yetangjian/p/17809233.html
關於作者: yetangjian
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出, 原文連結 如有問題, 可郵件([email protected])諮詢.