x86平臺SIMD程式設計入門(1):SIMD基礎知識
1、簡介
SIMD(Single Instruction, Multiple Data)是一種平行計算技術,它通過向量暫存器儲存多個資料元素,並使用單條指令同時對這些資料元素進行處理,從而提高了計算效率。SIMD已被廣泛應用於需要大量資料平行計算的領域,包括影象處理、視訊編碼、訊號處理、科學計算等。許多現代處理器都提供了SIMD指令集擴充套件,例如x86平臺的SSE/AVX,以及ARM平臺的NEON,本文只討論x86平臺下的SIMD指令。
在C++程式中使用SIMD指令有兩種方案,一種是使用內聯組合,另一種是使用intrinsic函數。以簡單的陣列相乘為例,程式碼的常規寫法、內聯組合寫法以及intrinsic函數寫法分別如下:
float a[4] = { 1.0, 2.0, 3.0, 4.0 };
float b[4] = { 5.0, 6.0, 7.0, 8.0 };
float c[4];
// 常規寫法,用迴圈實現陣列相乘
for (int i = 0; i < 4; ++i)
{
c[i] = a[i] * b[i];
}
// 使用SIMD指令的內聯組合
__asm
{
movups xmm0, [a]; // 將a所指記憶體的128位元資料放入xmm0暫存器
movups xmm1, [b]; // 將b所指記憶體的128位元資料放入xmm1暫存器
mulps xmm0, xmm1; // 計算xmm0 * xmm1(4個32位元單精度浮點數對位相乘),結果放入xmm0
movups[c], xmm0; // 將xmm0的資料放入c所指記憶體
}
// 使用intrinsic函數
__m128 va = _mm_loadu_ps(a);
__m128 vb = _mm_loadu_ps(b);
__m128 vc = _mm_mul_ps(va, vb);
_mm_storeu_ps(c, vc);
intrinsic函數是對組合指令的封裝,編譯時這些函數會被內聯成組合,所以不會產生函數呼叫的開銷。當CPU不支援指令集時,intrinsic函數可能會模擬對應的功能。完整的intrinsic函數使用指南可以參考Intel官方檔案。
2、指令集的發展
2.1、MMX
1996年,Intel推出了多媒體擴充套件指令集MMX(Multi-Media Extensions),它最初是為了加速多媒體應用程式而設計的,共包含57條指令,可用於整數的加法、減法、乘法、邏輯運算和移位等。MMX引入了8個64位元暫存器,被稱為MM0~MM7,每個暫存器可以被看做是2個32位元整數、或是4個16位元整數、或是8個8位元整數。不過,這些MMX暫存器並不是獨立的暫存器,而是複用了浮點數暫存器,所以MMX指令和浮點數操作不能同時工作。
2.2、SSE
SSE(Streaming SIMD Extensions)指令集釋出於1999年,作為對MMX指令集的增強和擴充套件。SSE支援單精度浮點數運算以及整數運算等指令,並引入了8個獨立的128位元暫存器,稱為XMM0~XMM7。後續釋出的SSE2指令集則一方面新增了對雙精度浮點數的支援,另一方面也增添了整數處理指令,這些新的整數處理指令能夠覆蓋MMX指令的功能,從而讓舊的MMX指令顯得多餘。2003年,AMD推出AMD64架構時,又新增了8個XMM暫存器,它們被稱為XMM8~XMM15。當CPU處於32位元模式時,可用的XMM暫存器為XMM0~XMM7,而當CPU處於64位元模式時,可用的XMM暫存器為XMM0~XMM15。此後推出的SSE3/SSE4又新增了更多了SIMD指令。
2.3、AVX
2011年,AVX(Advanced Vector Extensions)指令集將浮點運算寬度從128位元擴充套件到了256位,新的暫存器名為YMM0~YMM15,其128位元的下半部分仍可作為XMM0~XMM15存取。2013年,AVX2將整數運算指令擴充套件至256位,同時也支援了FMA(Fused Multiply Accumulate)指令。2016年,AVX-512將浮點與整數運算寬度擴充套件到了512位元,主要用於多媒體資訊處理、科學計算、資料加密和壓縮、以及深度學習等高效能運算場景。
2.4、對比總結
每一代的指令集都相容上一代,也就是說新一代的指令集也支援使用上一代的指令和暫存器(但硬體實現可能有區別)。此外,AVX對之前的部分指令進行了重構,所以不同代際之間相同功能的函數可能具有不同的介面。不同代際的指令儘量不要混用,因為每次狀態切換會有效能消耗,從而拖慢程式的執行速度。代際之間對暫存器及其位寬的更新情況如下:
| 指令集 | 暫存器 | 浮點位寬 | 整型位寬 |
|---|---|---|---|
| MMX | MM0~MM7 | 64 | |
| SSE | XMM0~XMM7 | 128 | |
| SSE2 | XMM0~XMM15 | 128 | 128 |
| AVX | YMM0~YMM15 | 256 | 128 |
| AVX2 | YMM0~YMM15 | 256 | 256 |
3、SIMD程式設計基礎
3.1、標頭檔案
#include <mmintrin.h> // MMX
#include <xmmintrin.h> // SSE(include mmintrin.h)
#include <emmintrin.h> // SSE2(include xmmintrin.h)
#include <pmmintrin.h> // SSE3(include emmintrin.h)
#include <tmmintrin.h> // SSSE3(include pmmintrin.h)
#include <smmintrin.h> // SSE4.1(include tmmintrin.h)
#include <nmmintrin.h> // SSE4.2(include smmintrin.h)
#include <ammintrin.h> // SSE4A
#include <wmmintrin.h> // AES(include nmmintrin.h)
#include <immintrin.h> // AVX, AVX2, FMA(include wmmintrin.h)
- 每一代SIMD指令集的標頭檔案如上,實際使用時只需包含最高支援的指令集標頭檔案即可。
- SSE4A是AMD獨有的指令集,除
<ammintrin.h>之外的每一個標頭檔案都包含了它前面的那個標頭檔案。 - 部分編譯器還有
<zmmintrin.h>用於支援AVX-512。 - 如果想要包含全部標頭檔案,在GCC/Clang環境下可以包含標頭檔案
<x86intrin.h>,在MSVC環境下則需要包含<intrin.h>。
3.2、記憶體對齊
有很多SIMD指令都要求記憶體對齊。例如SSE指令_mm_load_ps就要求輸入地址是16位元組對齊的,否則可能導致程式崩潰或者得不到正確結果;如果程式無法保證輸入地址是對齊的,那就得使用不要求記憶體對齊的版本_mm_loadu_ps。記憶體不對齊的版本通常執行更慢,不過在較新的CPU上這種效能差距已經基本可以忽略了。
在棧上記憶體定義變數時,可以使用如下兩種方法進行16位元組的記憶體對齊:
_MM_ALIGN16 float a[4] = { 1.0, 2.0, 3.0, 4.0 }; //_MM_ALIGN16是標頭檔案xmmintrin.h中定義的宏
alignas(16) float b[4] = { 5.0, 6.0, 7.0, 8.0 }; //alignas是C++11中引入的關鍵字
對於堆上分配的動態記憶體,可用下列函數進行16位元組對齊記憶體的分配與釋放:
float* a = (float*)_aligned_malloc(4 * sizeof(float), 16);
_aligned_free(a);
3.3、資料型別
SIMD指令使用自定義的資料型別,例如__m64、__m128、__m128d、__m128i等。它們的命名通常由3部分組成:
- 前序:統一為
__m - 位寬:例如
64、128、256、512 - 型別:
i表示整型(int),d表示雙精度浮點型(double),什麼都不加表示單精度浮點型(float)
以AVX中的256位資料型別為例,它們的定義如下:
typedef union __declspec(intrin_type) __declspec(align(32)) __m256 {
float m256_f32[8];
} __m256;
typedef struct __declspec(intrin_type) __declspec(align(32)) __m256d {
double m256d_f64[4];
} __m256d;
typedef union __declspec(intrin_type) __declspec(align(32)) __m256i {
__int8 m256i_i8[32];
__int16 m256i_i16[16];
__int32 m256i_i32[8];
__int64 m256i_i64[4];
unsigned __int8 m256i_u8[32];
unsigned __int16 m256i_u16[16];
unsigned __int32 m256i_u32[8];
unsigned __int64 m256i_u64[4];
} __m256i;
SIMD暫存器將自己暴露為上面這樣的資料型別供C++程式設計師使用,在組合程式碼中,相同位寬的資料型別對應著同樣的暫存器,它們的區別僅在於C++的類別型檢查。
編譯器會自動為暫存器分配變數,但暫存器的數量是有限的。如果定義了太多區域性變數,並且程式碼依賴關係複雜導致編譯器無法重複使用暫存器,那麼部分變數可能會從暫存器中轉移到記憶體上,某些情況下這會使得效能下降。
對於這些向量型別,雖然編譯器將它們定義為內部包含陣列的結構體或聯合體,程式設計師可以使用這些陣列來存取向量的各個通道,但這樣的效能可能並不理想,因為編譯器在執行此類程式碼時可能會將資料在暫存器和記憶體之間來回轉移。所以建議不要這樣處理SIMD向量資料,而應當儘量使用洗牌、插入、提取等intrinsic函數來完成此類操作。
3.4、運算模式
浮點數運算模式可以分為packed和scalar兩類。packed模式一次對暫存器中的四個浮點數進行計算,而scalar模式一次只對暫存器中最低的一個浮點數進行計算。
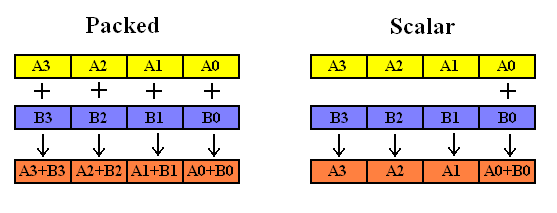
3.5、函數命名
SIMD指令的intrinsic函數命名風格如下:
_mm<bit_width>_<name>_<data_type>
第一部分mm<bit_width>表示資料向量的位寬,例如_mm代表64或128位元,_mm256代表256位,_mm512代表512位元。
第二部分<name>表示函數的功能,例如load、add、store等。此外也可以追加一個修飾字元來實現某種特殊作用,例如:
| 修飾字元 | 範例 | 作用 |
|---|---|---|
| u | loadu | [unaligned] 允許記憶體未對齊 |
| s | adds/subs | [saturate] 當運算結果超出資料範圍時,會被限制為該範圍的上限或者下限 |
| h | hadd/hsub | [horizontal] 水平方向上做加減法 |
| hi/lo | mulhi/mullo | [high/low] 相乘後保留高位/低位 |
| r | setr | [reverse] 逆序初始化向量 |
| fm | fmadd/fmsub | [fused multiply add] FMA運算 |
第三部分<data_type>表示資料型別,如下表所示:
| 資料標識 | 含義 |
|---|---|
| epi8/epi16/epi32 | 有符號的8/16/32位元整數向量 |
| epu8/epu16/epu32 | 無符號的8/16/32位元整數向量 |
| si128/si256 | 未指定的128位元/256位向量 |
| ps | packed single |
| ss | scalar single |
| pd | packed double |
| sd | scalar double |
3.6、指令集支援
MSVC沒有提供檢測指令集支援性的方法。而對於GCC來說,可以使用編譯選項來啟用各種指令集,也可以在程式碼中使用宏來判斷是否支援對應的指令集:
| GCC編譯選項 | 宏 |
|---|---|
-mmmx |
__MMX__ |
-msse |
__SSE__ |
-msse2 |
__SSE2__ |
-msse3 |
__SSE3__ |
-mssse3 |
__SSSE3__ |
-msse4.1 |
__SSE4_1__ |
-msse4.2 |
__SSE4_2__ |
-mavx |
__AVX__ |
-mavx2 |
__AVX2__ |
若要檢測CPU是否支援特定的SIMD指令集,可以參考這個開源專案,它包含了多種系統環境下檢測指令集的程式碼。下面這段程式碼改編自上述開源專案,可以在MSVC x86環境下檢測CPU對SIMD指令集的支援情況:
#include <intrin.h>
int main()
{
int info[4];
__cpuid(info, 0);
unsigned int maximum_eax = info[0];
if (maximum_eax >= 1)
{
__cpuid(info, 1);
unsigned int ecx = info[2];
unsigned int edx = info[3];
bool has_mmx = edx & (1 << 23);
bool has_sse = edx & (1 << 25);
bool has_sse2 = edx & (1 << 26);
bool has_sse3 = ecx & (1 << 0);
bool has_ssse3 = ecx & (1 << 9);
bool has_sse4_1 = ecx & (1 << 19);
bool has_sse4_2 = ecx & (1 << 20);
bool has_avx = ecx & (1 << 28);
bool has_aes = ecx & (1 << 25);
}
if (maximum_eax >= 7)
{
__cpuidex(info, 7, 0);
unsigned int ebx = info[1];
unsigned int ecx = info[2];
unsigned int edx = info[3];
bool has_avx2 = ebx & (1 << 5);
bool has_avx512_f = ebx & (1 << 16);
bool has_avx512_dq = ebx & (1 << 17);
bool has_avx512_ifma = ebx & (1 << 21);
bool has_avx512_pf = ebx & (1 << 26);
bool has_avx512_er = ebx & (1 << 27);
bool has_avx512_cd = ebx & (1 << 28);
bool has_avx512_bw = ebx & (1 << 30);
bool has_avx512_vl = ebx & (1 << 31);
bool has_avx512_vbmi = ecx & (1 << 1);
bool has_avx512_vbmi2 = ecx & (1 << 6);
bool has_avx512_vnni = ecx & (1 << 11);
bool has_avx512_bitalg = ecx & (1 << 12);
bool has_avx512_vpopcntdq = ecx & (1 << 14);
bool has_avx512_4vnniw = edx & (1 << 2);
bool has_avx512_4fmaps = edx & (1 << 3);
bool has_avx512_vp2intersect = edx & (1 << 8);
}
}
3.7、混用AVX/SSE
AVX採用了更寬的256位向量和新指令,並使用了新的VEX編碼格式。 不過AVX也包含128位元的VEX編碼指令,它們相當於傳統SSE的128位元指令。
| 指令 | 編碼方式 | 使用的暫存器 |
|---|---|---|
| 256位AVX指令 | VEX | 256位YMM暫存器 |
| 128位元AVX指令 | VEX | 對YMM低128位元進行操作,並將高128位元清零 |
| 128位元傳統SSE指令 | legacy | 對XMM(即YMM的低128位元)進行操作,並且不關心YMM的高128位元 |
AVX指令與傳統(非VEX編碼)SSE指令混合使用時可能會導致效能下降,因為當從AVX指令轉換到傳統SSE指令時,硬體會儲存YMM暫存器高128位元的內容,然後在SSE轉換回AVX時恢復這些值,儲存和恢復操作都會花費幾十個時鐘週期。
避免這種效能損失最簡單的方法就是使用編譯器標誌-mavx(對於Windows則是/arch:avx),這會強制編譯器為128位元指令進行VEX格式編碼。如果確實無法避免AVX與傳統SSE的轉換(例如需要呼叫使用了傳統SSE指令的庫),可以使用_mm256_zeroupper將YMM暫存器的高128位元清零,這樣硬體就無需儲存這些值,另外需要注意的是,_mm256_zeroupper指令必須在256位AVX指令之後、SSE指令之前呼叫,這樣才可以取消儲存和還原操作,其它方法(例如XOR)不起作用。關於AVX-SSE混用問題的詳細應對策略可以參考Intel官方檔案Avoiding AVX-SSE Transition Penalties。