解碼注意力Attention機制:從技術解析到PyTorch實戰
在本文中,我們深入探討了注意力機制的理論基礎和實際應用。從其歷史發展和基礎定義,到具體的數學模型,再到其在自然語言處理和計算機視覺等多個人工智慧子領域的應用範例,本文為您提供了一個全面且深入的視角。通過Python和PyTorch程式碼範例,我們還展示瞭如何實現這一先進的機制。
關注TechLead,分享AI技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
引言
在深度學習領域,模型的效能不斷提升,但同時計算複雜性和引數數量也在迅速增加。為了讓模型更高效地捕獲輸入資料中的資訊,研究人員開始轉向各種優化策略。正是在這樣的背景下,注意力機制(Attention Mechanism)應運而生。本節將探討注意力機制的歷史背景和其在現代人工智慧研究和應用中的重要性。
歷史背景
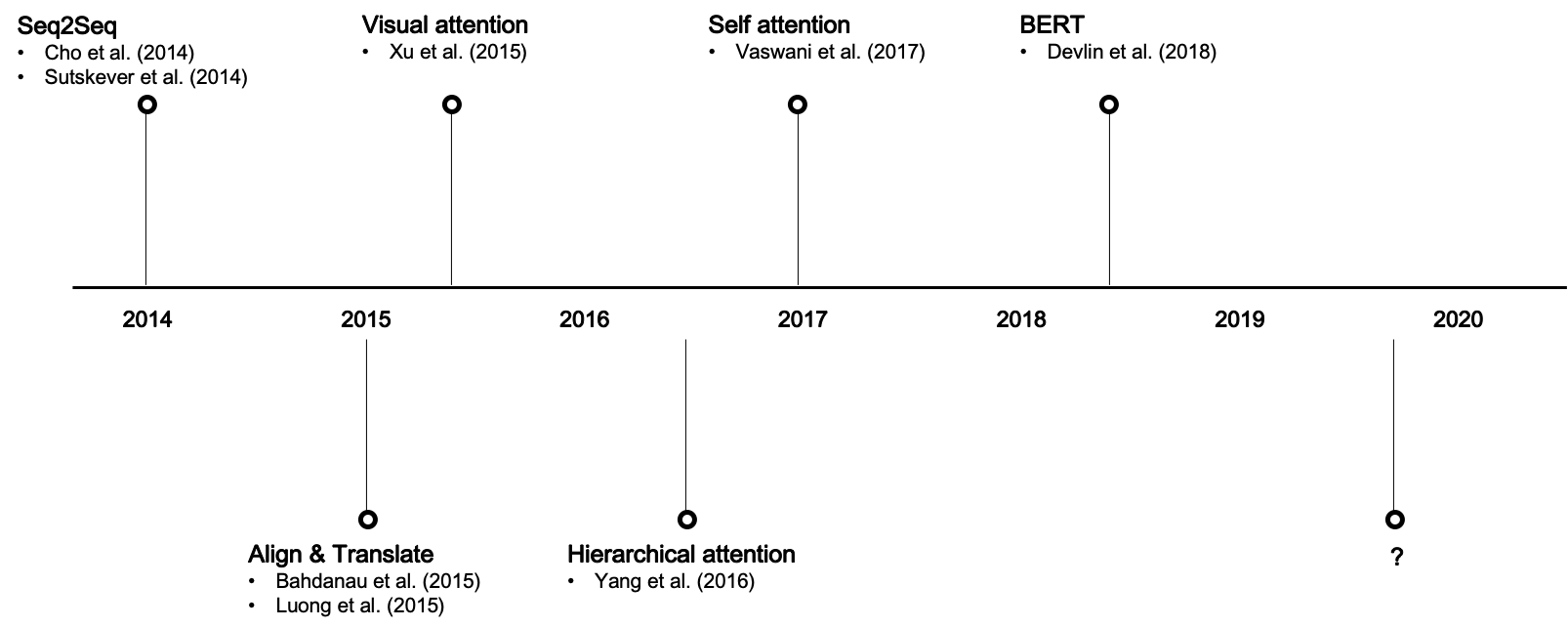
-
2014年:序列到序列(Seq2Seq)模型的出現為自然語言處理(NLP)和機器翻譯帶來了巨大的突破。
-
2015年:Bahdanau等人首次引入了注意力機制,用於改進基於Seq2Seq的機器翻譯。
-
2017年:Vaswani等人提出了Transformer模型,這是第一個完全依賴於注意力機制來傳遞資訊的模型,顯示出了顯著的效能提升。
-
2018-2021年:注意力機制開始廣泛應用於不同的領域,包括計算機視覺、語音識別和生成模型,如GPT和BERT等。
-
2021年以後:研究者們開始探究如何改進注意力機制,以便於更大、更復雜的應用場景,如多模態學習和自監督學習。
重要性
-
效能提升:注意力機制一經引入即顯著提升了各種任務的效能,包括但不限於文字翻譯、影象識別和強化學習。
-
計算效率:通過精心設計的權重分配,注意力機制有助於減少不必要的計算,從而提高模型的計算效率。
-
可解釋性:雖然深度學習模型常被批評為「黑盒」,但注意力機制提供了一種直觀的方式來解釋模型的決策過程。
-
模型簡化:在多數情況下,引入注意力機制可以簡化模型結構,如去除或減少遞迴網路的需要。
-
領域廣泛性:從自然語言處理到計算機視覺,再到醫學影象分析,注意力機制的應用幾乎無處不在。
-
模型泛化:注意力機制通過更智慧地挑選關聯性強的特徵,提高了模型在未見過資料上的泛化能力。
-
未來潛力:考慮到當前研究的活躍程度和多樣性,注意力機制有望推動更多前沿科技的發展,如自動駕駛、自然語言介面等。
綜上所述,注意力機制不僅在歷史上具有里程碑式的意義,而且在當下和未來都是深度學習和人工智慧領域內不可或缺的一部分。
二、注意力機制
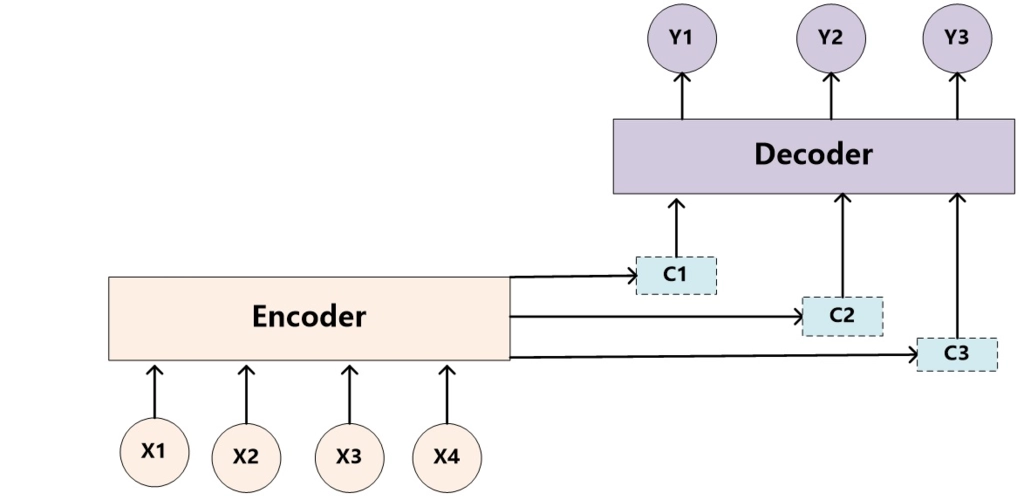
注意力機制是一種模擬人類視覺和聽覺注意力分配的方法,在處理大量輸入資料時,它允許模型關注於最關鍵的部分。這一概念最早是為了解決自然語言處理中的序列到序列模型的一些侷限性而被提出的,但現在已經廣泛應用於各種機器學習任務。
基礎概念
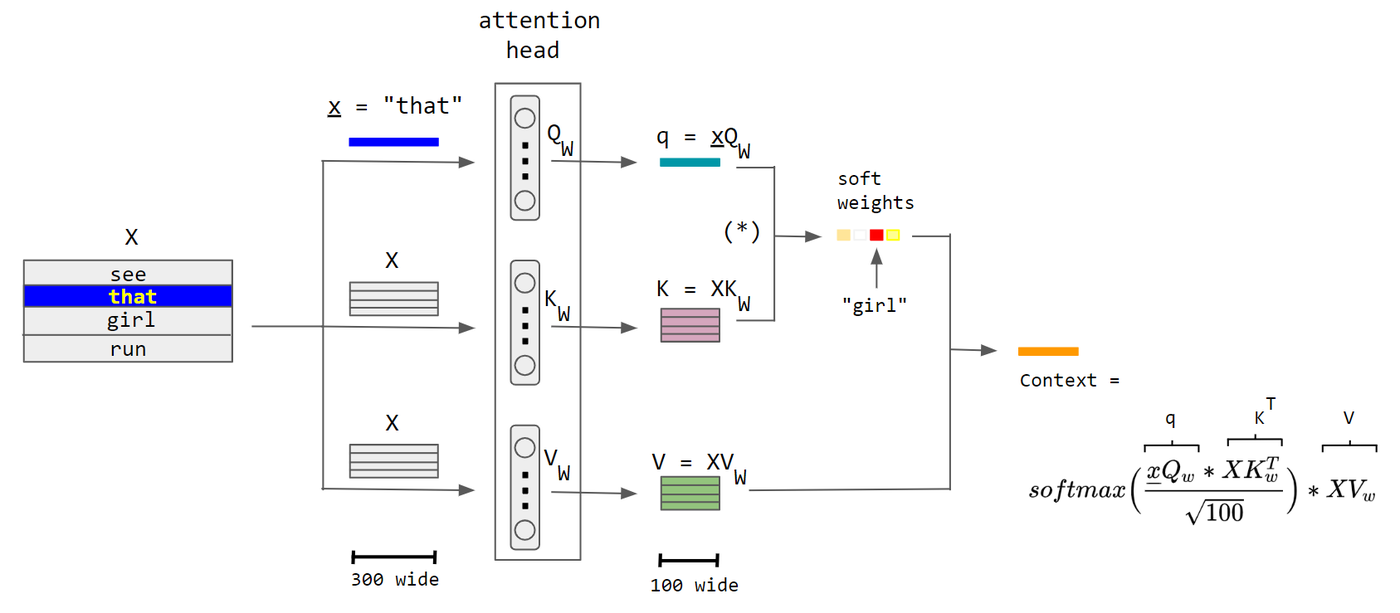
定義
在數學上,注意力函數可以被定義為一個對映,該對映接受一個查詢(Query)和一組鍵值對(Key-Value pairs),然後輸出一個聚合後的資訊,通常稱為注意力輸出。
注意力(Q, K, V) = 聚合(權重 * V)
其中,權重通常是通過查詢(Q)和鍵(K)的相似度計算得到的:
權重 = softmax(Q * K^T / sqrt(d_k))
元件
- Query(查詢): 代表需要獲取資訊的請求。
- Key(鍵): 與Query相關性的衡量標準。
- Value(值): 包含需要被提取資訊的實際資料。
- 權重(Attention Weights): 通過Query和Key的相似度計算得來,決定了從各個Value中提取多少資訊。
注意力機制的分類
- 點積(Dot-Product)注意力
- 縮放點積(Scaled Dot-Product)注意力
- 多頭注意力(Multi-Head Attention)
- 自注意力(Self-Attention)
- 雙向注意力(Bi-Directional Attention)
舉例說明
假設我們有一個簡單的句子:「貓喜歡追逐老鼠」。如果我們要對「喜歡」這個詞進行編碼,一個簡單的方法是隻看這個詞本身,但這樣會忽略它的上下文。「喜歡」的物件是「貓」,而被「喜歡」的是「追逐老鼠」。在這裡,「貓」和「追逐老鼠」就是「喜歡」的上下文,而注意力機制能夠幫助模型更好地捕獲這種上下文關係。
# 使用PyTorch實現簡單的點積注意力
import torch
import torch.nn.functional as F
# 初始化Query, Key, Value
Q = torch.tensor([[1.0, 0.8]]) # Query 對應於 "喜歡" 的編碼
K = torch.tensor([[0.9, 0.1], [0.8, 0.2], [0.7, 0.9]]) # Key 對應於 "貓", "追逐", "老鼠" 的編碼
V = torch.tensor([[1.0, 0.1], [0.9, 0.2], [0.8, 0.3]]) # Value 也對應於 "貓", "追逐", "老鼠" 的編碼
# 計算注意力權重
d_k = K.size(1)
scores = torch.matmul(Q, K.transpose(0, 1)) / (d_k ** 0.5)
weights = F.softmax(scores, dim=-1)
# 計算注意力輸出
output = torch.matmul(weights, V)
print("注意力權重:", weights)
print("注意力輸出:", output)
輸出:
注意力權重: tensor([[0.4761, 0.2678, 0.2561]])
注意力輸出: tensor([[0.9529, 0.1797]])
這裡,「喜歡」通過注意力權重與「貓」和「追逐老鼠」進行了資訊的融合,並得到了一個新的編碼,從而更準確地捕獲了其在句子中的語意資訊。
通過這個例子,我們可以看到注意力機制是如何運作的,以及它在理解序列資料,特別是文字資料中的重要性。
三、注意力機制的數學模型
在深入瞭解注意力機制的應用之前,我們先來解析其背後的數學模型。注意力機制通常由一系列數學操作組成,包括點積、縮放、Softmax函數等。這些操作不僅有助於計算注意力權重,而且也決定了資訊如何從輸入傳遞到輸出。
基礎數學表示式
注意力函數
注意力機制最基礎的形式可以用以下函數表示:
[
\text{Attention}(Q, K, V) = \text{Aggregate}(W \times V)
]
其中,( W ) 是注意力權重,通常通過 ( Q )(查詢)和 ( K )(鍵)的相似度計算得出。
計算權重
權重 ( W ) 通常是通過 Softmax 函數和點積運算計算得出的,表示式為:
[
W = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)
]
這裡,( d_k ) 是鍵和查詢的維度,( \sqrt{d_k} ) 的作用是縮放點積,以防止梯度過大或過小。
數學意義
-
點積 ( QK^T ):這一步測量了查詢和鍵之間的相似性。點積越大,意味著查詢和相應的鍵更相似。
-
縮放因子 ( \sqrt{d_k} ):縮放因子用於調整點積的大小,使得模型更穩定。
-
Softmax 函數:Softmax 用於將點積縮放的結果轉化為概率分佈,從而確定每個值在最終輸出中的權重。
舉例解析
假設我們有三個單詞:'apple'、'orange'、'fruit',用三維向量 ( Q, K_1, K_2 ) 表示。
import math
import torch
# Query, Key 初始化
Q = torch.tensor([2.0, 3.0, 1.0])
K1 = torch.tensor([1.0, 2.0, 1.0]) # 'apple'
K2 = torch.tensor([1.0, 1.0, 2.0]) # 'orange'
# 點積計算
dot_product1 = torch.dot(Q, K1)
dot_product2 = torch.dot(Q, K2)
# 縮放因子
d_k = Q.size(0)
scale_factor = math.sqrt(d_k)
# 縮放點積
scaled_dot_product1 = dot_product1 / scale_factor
scaled_dot_product2 = dot_product2 / scale_factor
# Softmax 計算
weights = torch.nn.functional.softmax(torch.tensor([scaled_dot_product1, scaled_dot_product2]), dim=0)
print("權重:", weights)
輸出:
權重: tensor([0.6225, 0.3775])
在這個例子中,權重顯示「fruit」與「apple」(0.6225)相比「orange」(0.3775)更相似。這種計算方式為我們提供了一種量化「相似度」的手段,進一步用於資訊聚合。
通過深入理解注意力機制的數學模型,我們可以更準確地把握其如何提取和聚合資訊,以及它在各種機器學習任務中的應用價值。這也為後續的研究和優化提供了堅實的基礎。
四、注意力網路在NLP中的應用

注意力機制在自然語言處理(NLP)中有著廣泛的應用,包括機器翻譯、文字摘要、命名實體識別(NER)等。本節將深入探討幾種常見應用,並提供相應的程式碼範例。
機器翻譯
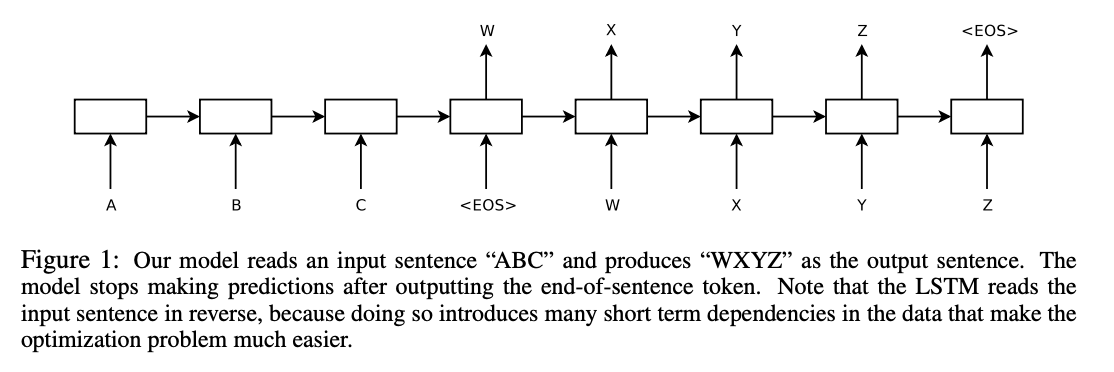
機器翻譯是最早採用注意力機制的NLP任務之一。傳統的Seq2Seq模型在處理長句子時存在資訊損失的問題,注意力機制通過動態權重分配來解決這一問題。
程式碼範例
import torch
import torch.nn as nn
class AttentionSeq2Seq(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(AttentionSeq2Seq, self).__init__()
self.encoder = nn.LSTM(input_dim, hidden_dim)
self.decoder = nn.LSTM(hidden_dim, hidden_dim)
self.attention = nn.Linear(hidden_dim * 2, 1)
self.output_layer = nn.Linear(hidden_dim, output_dim)
def forward(self, src, tgt):
# Encoder
encoder_output, (hidden, cell) = self.encoder(src)
# Decoder with Attention
output = []
for i in range(tgt.size(0)):
# 計算注意力權重
attention_weights = torch.tanh(self.attention(torch.cat((hidden, encoder_output), dim=2)))
attention_weights = torch.softmax(attention_weights, dim=1)
# 注意力加權和
weighted = torch.sum(encoder_output * attention_weights, dim=1)
# Decoder
out, (hidden, cell) = self.decoder(weighted.unsqueeze(0), (hidden, cell))
out = self.output_layer(out)
output.append(out)
return torch.stack(output)
文字摘要
文字摘要任務中,注意力機制能夠幫助模型挑選出文章中的關鍵句子或者詞,生成一個內容豐富、結構緊湊的摘要。
程式碼範例
class TextSummarization(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(TextSummarization, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.encoder = nn.LSTM(embed_size, hidden_size)
self.decoder = nn.LSTM(hidden_size, hidden_size)
self.attention = nn.Linear(hidden_size * 2, 1)
self.output = nn.Linear(hidden_size, vocab_size)
def forward(self, src, tgt):
embedded = self.embedding(src)
encoder_output, (hidden, cell) = self.encoder(embedded)
output = []
for i in range(tgt.size(0)):
attention_weights = torch.tanh(self.attention(torch.cat((hidden, encoder_output), dim=2)))
attention_weights = torch.softmax(attention_weights, dim=1)
weighted = torch.sum(encoder_output * attention_weights, dim=1)
out, (hidden, cell) = self.decoder(weighted.unsqueeze(0), (hidden, cell))
out = self.output(out)
output.append(out)
return torch.stack(output)
命名實體識別(NER)
在命名實體識別任務中,注意力機制可以用於捕捉文字中不同實體之間的依賴關係。
程式碼範例
class NERModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, output_size):
super(NERModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, hidden_size, bidirectional=True)
self.attention = nn.Linear(hidden_size * 2, 1)
self.fc = nn.Linear(hidden_size * 2, output_size)
def forward(self, x):
embedded = self.embedding(x)
rnn_output, _ = self.rnn(embedded)
attention_weights = torch.tanh(self.attention(rnn_output))
attention_weights = torch.softmax(attention_weights, dim=1)
weighted = torch.sum(rnn_output * attention_weights, dim=1)
output = self.fc(weighted)
return output
這些只是注意力網路在NLP中應用的冰山一角,但它們清晰地展示了注意力機制如何增強模型的效能和準確性。隨著研究的不斷深入,我們有理由相信注意力機制將在未來的NLP應用中發揮更加重要的作用。
五、注意力網路在計算機視覺中的應用
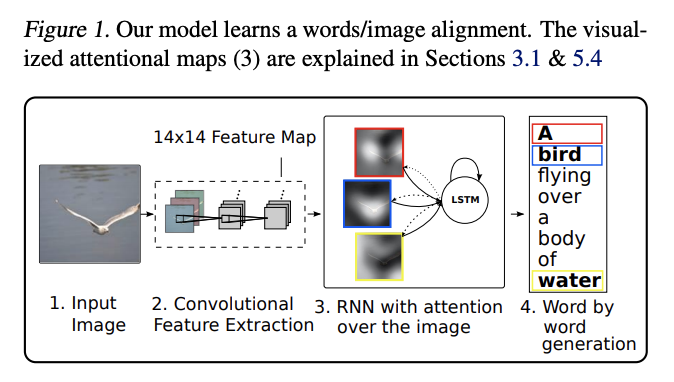
注意力機制不僅在NLP中有廣泛應用,也在計算機視覺(CV)領域逐漸嶄露頭角。本節將探討注意力機制在影象分類、目標檢測和影象生成等方面的應用,並通過程式碼範例展示其實現細節。
影象分類
在影象分類中,注意力機制可以幫助網路更加聚焦於與分類標籤密切相關的影象區域。
程式碼範例
import torch
import torch.nn as nn
class AttentionImageClassification(nn.Module):
def __init__(self, num_classes):
super(AttentionImageClassification, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.attention = nn.Linear(64, 1)
self.fc = nn.Linear(64, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))
attention_weights = torch.softmax(attention_weights, dim=2)
x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)
x = self.fc(x)
return x
目標檢測
在目標檢測任務中,注意力機制能夠高效地定位和識別影象中的多個物件。
程式碼範例
class AttentionObjectDetection(nn.Module):
def __init__(self, num_classes):
super(AttentionObjectDetection, self).__init__()
self.conv = nn.Conv2d(3, 64, 3)
self.attention = nn.Linear(64, 1)
self.fc = nn.Linear(64, 4 + num_classes) # 4 for bounding box coordinates
def forward(self, x):
x = self.conv(x)
attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))
attention_weights = torch.softmax(attention_weights, dim=2)
x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)
x = self.fc(x)
return x
影象生成
影象生成任務,如GANs,也可以從注意力機制中受益,尤其在生成具有複雜結構和細節的影象時。
程式碼範例
class AttentionGAN(nn.Module):
def __init__(self, noise_dim, img_channels):
super(AttentionGAN, self).__init__()
self.fc = nn.Linear(noise_dim, 256)
self.deconv1 = nn.ConvTranspose2d(256, 128, 4)
self.attention = nn.Linear(128, 1)
self.deconv2 = nn.ConvTranspose2d(128, img_channels, 4)
def forward(self, z):
x = self.fc(z)
x = self.deconv1(x.view(x.size(0), 256, 1, 1))
attention_weights = torch.tanh(self.attention(x.view(x.size(0), x.size(1), -1)))
attention_weights = torch.softmax(attention_weights, dim=2)
x = torch.sum(x.view(x.size(0), x.size(1), -1) * attention_weights, dim=2)
x = self.deconv2(x.view(x.size(0), 128, 1, 1))
return x
這些應用範例明確地展示了注意力機制在計算機視覺中的潛力和多樣性。隨著更多的研究和應用,注意力網路有望進一步推動計算機視覺領域的發展。
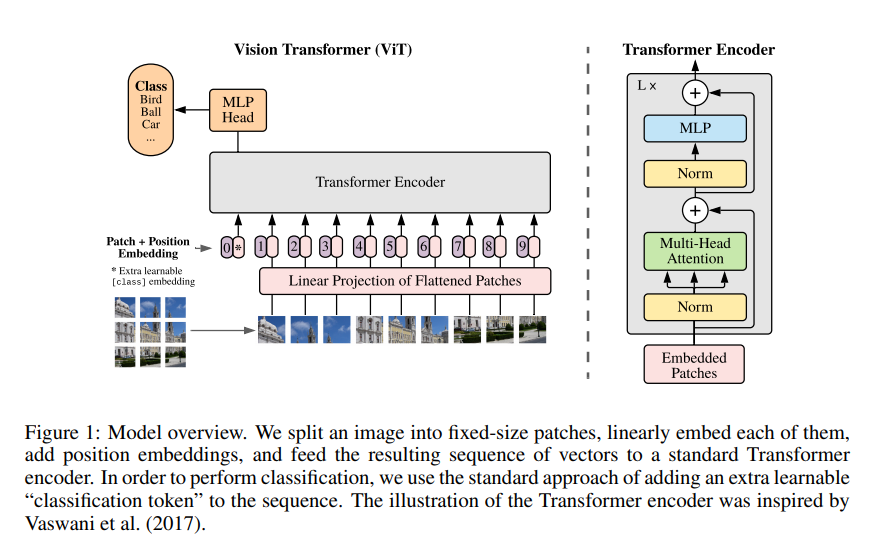
六、總結
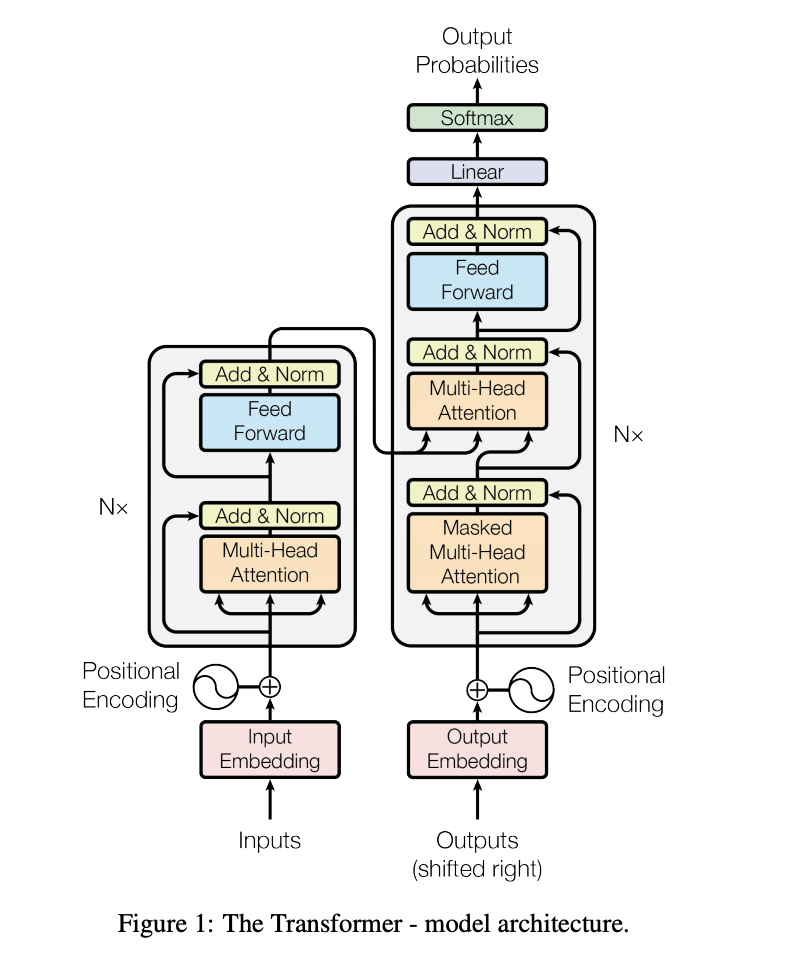
注意力機制在人工智慧行業中的應用已經遠遠超出了其初始的研究領域,從自然語言處理到計算機視覺,乃至其他多種複雜的任務和場景。通過動態地分配不同級別的「注意力」,這一機制有效地解決了資訊處理中的關鍵問題,提升了模型效能,並推動了多個子領域的前沿研究和應用。這標誌著人工智慧從「寫死」規則轉向了更為靈活、自適應的計算模型,進一步拓寬了該領域的應用範圍和深度。
關注TechLead,分享AI技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。