Opencv中goodFeaturesToTrack函數(Harris角點、Shi-Tomasi角點檢測)運算元速度的進一步優化(1920*1080測試圖11ms處理完成)。
搜尋到某個效果很好的視訊去燥的演演算法,感覺效果比較牛逼,就是速度比較慢,如果能做到實時,那還是很有實用價值的。於是盲目的選擇了這個課題,遇到的第一個函數就是角點檢測,大概六七年用過C#實現過Harris角點以及SUSAN角點。因此相關的理論還是有所瞭解的,不過那個時候重點在於實現,對於效率沒有過多的考慮。
那個程式碼裡使用的Opencv的函數叫 goodFeaturesToTrack, 一開始我還以為是個使用者自定義的函數呢,在程式碼裡就根本沒找到,後面一搜原來是CV自帶的函數,其整個的呼叫為:
goodFeaturesToTrack(img0Gray, featurePtSet0, 10000, 0.05, 5);
這個的意思是從img0Gray影象中,找到10000個角點,角點之間的最小距離是5,使用Shi-Tomasi角點檢測運算元。
我們檢視了下Opencv的程式碼,寫的不是很複雜,但是我是想對一副1920*1080的視訊進行去燥,嘗試了下僅僅執行goodFeaturesToTrack其中的一個子函數cvCornerHarris,大概就需要50多毫秒。這怎麼玩的下去啊。
CV裡關於這個函數的程式碼位於:Opencv 3.0\opencv\sources\modules\imgproc\src\featureselect.cpp中,為了節省篇幅,我刪除其一些輔助性的程式碼和檢測,大概就是如下所示:
void cv::goodFeaturesToTrack( InputArray _image, OutputArray _corners,
int maxCorners, double qualityLevel, double minDistance,
InputArray _mask, int blockSize,
bool useHarrisDetector, double harrisK )
{
Mat image = _image.getMat(), eig, tmp;
if( useHarrisDetector )
cornerHarris( image, eig, blockSize, 3, harrisK );
else
cornerMinEigenVal( image, eig, blockSize, 3 );
double maxVal = 0;
minMaxLoc( eig, 0, &maxVal, 0, 0, _mask );
threshold( eig, eig, maxVal*qualityLevel, 0, THRESH_TOZERO );
dilate( eig, tmp, Mat());
Size imgsize = image.size();
std::vector<const float*> tmpCorners;
// collect list of pointers to features - put them into temporary image
Mat mask = _mask.getMat();
for( int y = 1; y < imgsize.height - 1; y++ )
{
const float* eig_data = (const float*)eig.ptr(y);
const float* tmp_data = (const float*)tmp.ptr(y);
const uchar* mask_data = mask.data ? mask.ptr(y) : 0;
for( int x = 1; x < imgsize.width - 1; x++ )
{
float val = eig_data[x];
if( val != 0 && val == tmp_data[x] && (!mask_data || mask_data[x]) )
tmpCorners.push_back(eig_data + x);
}
}
std::sort( tmpCorners.begin(), tmpCorners.end(), greaterThanPtr() );
std::vector<Point2f> corners;
size_t i, j, total = tmpCorners.size(), ncorners = 0;
if (minDistance >= 1)
{
// Partition the image into larger grids
}
else
{
}
Mat(corners).convertTo(_corners, _corners.fixedType() ? _corners.type() : CV_32F);
}
先呼叫cornerHarris或者cornerMinEigenVal函數,得到初步的特徵資料,後面的就是進行篩選,minMaxLoc得到最大值,然後根據最大值以及一個使用者引數得到一個閾值maxVal*qualityLevel,根據閾值剔除掉一些候選點,這裡使用的是threshold函數,然後在進行dilate求區域性最大值,然後進行非極大值抑制,再進行最小距離的驗證。
一、我們拋開最小距離的驗證不說,因為那個的計算量可以忽略不計。先來看看後面的幾個部分。
大的開源軟體之類的一般都比較講究函數呼叫,一般最小粒度的函數會進行一些特別的優化,然後其他一些複雜的函數就實行函數呼叫,這是一種比較正常的思維,但這種做法必然不可避免的會出現一些重複的計算和冗餘,在我這個演演算法的後半半部分這個就有比較明顯的表現,我們先來看看啊:
minMaxLoc這個函數找到最大值沒有辦法,必須進行,threshold、dilate(三成三的最大值)以及後續的候選點選擇,我們仔細分析下,完全是可以寫到一個函數裡的。在候選點選擇裡,它使用了判斷語句:
if( val != 0 && val == tmp_data[x] && (!mask_data || mask_data[x]) )
拋開後續的mask的判斷部分,前面的 val != 0 的判斷依據是前面進行threshold後,所有小於maxVal*qualityLevel的部分都已經等於零0,那也就是等價於判斷 val >= maxVal*qualityLevel是否成立。
判斷val == tmp_data[x]兩者是否相等,是判斷當前值是否是3*3領域內的最大值的意思,程式裡先求出3*3領域的最大值,然後在判斷是否相等,這裡其實是有所浪費資源的。
我們知道,每次載入記憶體和儲存資料到記憶體在某種程度上來說都是有著較大的消耗的,但是在CPU核心裡進行一些計算速度是相當快的,因此,既然上述這是幾個功能其實可以集中到一起實現,我們就沒有必然分散到各個函數中,而是可以全部集中到一個程式碼中,
下面是我使用C語言初步整理的一個過程:

在CV的程式碼裡,也是忽略了邊緣以一圈的判斷的,因為邊緣部分不太可能符合角點的定義的。
我們看上述程式碼,其中的Max >= MaxValue取代了threshold的功能, Max == P4完成了最大值計算以及後續的判斷是否相等的問題。而整個過程只需要遍歷一次全圖,且內部的判斷量是一樣的,而原始的程式碼需要遍歷三次記憶體資料,並且需要儲存到臨時的記憶體中。
上述程式碼也非常容易進行指令集的優化。
另外,當我們使用註釋掉的 // float Max = IM_Max(Max0, Max1)語句時, 後面的判斷Max == P4修改為Max <= P4,還可以減少一次判斷。
二、cornerHarris或者cornerMinEigenVal的優化
這兩個函數位於Opencv 3.0\opencv\sources\modules\imgproc\src\corner.cpp路徑下,核心的部分如下所示:
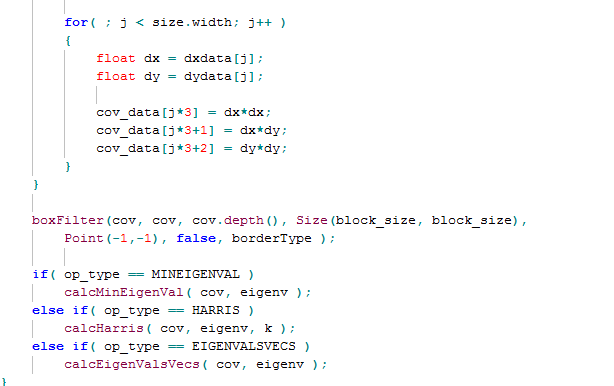
dx\dy是X和Y方向的一階導數,cv實現的比較複雜,可以支援較大尺寸的,但是常用的就是3*3領域的,我前面用CV做速度測試也是用的3*3的,這個的優化獲取可以見我部落格的SSE影象演演算法優化系列九:靈活運用SIMD指令16倍提升Sobel邊緣檢測的速度(4000*3000的24位元影象時間由480ms降低到30ms) 。
為了速度起見,我覺得這裡的dx,dy沒有必要用float型別來表達,直接使用int型別應該是足夠的,但是opencv這種資料的排布方式我覺得不太科學,他是dx*dx, dy*dy,dx*dy儲存在連續的記憶體中,類似於影象格式中的RGB24格式,這個格式在一些涉及到領域的演演算法裡不太友好,而本例後續就需要使用有關的領域演演算法。因此,我覺得應該是把他們分別儲存到單獨的記憶體空間中。
後續的boxFilter必須有,而且一般我覺得半徑為1,即block_size等於3就完全可以滿足要求了,而這個半徑的模糊是可以做一些特別的優化的。
後續的calcHarris函數沒有啥特別的,只能按部就班的計算,但是可以考慮的是,上面的minMaxLoc獲取最大值函數其實是可以在calcHarris函數裡一併執行的,這樣又可以減少一次遍歷和迴圈。
這裡要優化的重點還是這個dx*dx, dy*dy,dx*dy的獲取以及方框模糊的優化。
第一: 肯定是可以用指令集去處理的。當我們的中間結果都用int型別來表達時,我們中間涉及到部分的優化細節如下(純做記錄):
我們通過某些計算得到了dx和dy值,他們值是可以用short型別來記錄的,這個時候我們求dx * dy一般情況是通過如下語句實現:
__m128i DxDy_L = _mm_mullo_epi32(_mm_cvtepi16_epi32(Dx), _mm_cvtepi16_epi32(Dy)); __m128i DxDy_H = _mm_mullo_epi32(_mm_cvtepi16_epi32(_mm_srli_si128(Dx, 8)), _mm_cvtepi16_epi32(_mm_srli_si128(Dy, 8)));
其實我們也可以通過如下程式碼實現:
__m128i L = _mm_mullo_epi16(Dx, Dy); __m128i H = _mm_mulhi_epi16(Dx, Dy); __m128i DxDy_L = _mm_unpacklo_epi16(L, H); __m128i DxDy_H = _mm_unpackhi_epi16(L, H);
效果是相同的,但是會少兩條指令,速度要稍微優異一點。
第二:如果我們將dx\dy歸整到-255到255之間(這個也是正常的需求,一般這些一階二階的運算元的係數之和都應該是0,這樣,他們所能取到的最大值就是這個範圍),那麼dx *dx以及dy*dy的範圍就在unsigned short所能表達的範圍內了,而dx * dy還是必須使用int型別來表示。這樣做的好處有很多。 首先是資料型別的變小,是的我們可以用指令集一次性處理更多的資料,二是寫入記憶體或者從記憶體讀取資料的工作量變小了。
別看這點改動,我們實測發現至少有15%以上的速度提升。
第三:我們看看boxFilter這裡的優化,當我們使用半徑為1的優化時,這也是這個運算元最常用的取值, 我們需要,計算3*3的領域後除以9,如果老老實實的除以9,不管是浮點數,還是整形,也不管是用乘以0.1111111111代替,還是咋樣,反正都要計算量,其實我們完全可以不用除,前期是dx*dx, dy*dy,dx*dy大家都不除,因為我們發現後續的計算裡這個分母是可以消除的。 這樣只要儲存3*3的和就OK了。
更進一步,如果我們將dx\dy歸整到-127到127之間,我們發現dx*dx以及dy*dy的最大值就將被限制在16129之間,這樣在做boxFilter時,其中四個dx * dx的累加可以直接使用_mm_adds_epu16實現,而不用轉換到32位元使用_mm_add_epi32,可進一步提高速度。
而如果極限壓縮dx\dy歸整到-63到63之間,則3*3的累加完全可以直接使用_mm_adds_epu16而不溢位,此時對於 dx * dy,一方面他也可以直接使用short型別來儲存,另外,9次領域的這個值相加也是可以直接藉助_mm_adds_epi16而保證不溢位的(相鄰的9點的dx * dy 不可能同時到最大值)。
比如使用規整到-63到63之間的 boxFilter就可以使用如下運算元實現:
int IM_FastestBoxBlur3X3_I16(short *Src, short *Dest, int Width, int Height) { if ((Src == NULL) || (Dest == NULL)) return IM_STATUS_NULLREFRENCE; if ((Width <= 0) || (Height <= 0)) return IM_STATUS_INVALIDPARAMETER; short *RowCopy = (short *)malloc((Width + 2) * 3 * sizeof(short)); if (RowCopy == NULL) return IM_STATUS_OUTOFMEMORY; short *First = RowCopy; short *Second = RowCopy + (Width + 2); short *Third = RowCopy + (Width + 2) * 2; memcpy(Second, Src, sizeof(short)); memcpy(Second + 1, Src, Width * sizeof(short)); // 拷貝資料到中間位置 memcpy(Second + (Width + 1), Src + (Width - 1), sizeof(short)); memcpy(First, Second, (Width + 2) * sizeof(short)); // 第一行和第二行一樣 memcpy(Third, Src + Width, sizeof(short)); // 拷貝第二行資料 memcpy(Third + 1, Src + Width, Width * sizeof(short)); memcpy(Third + (Width + 1), Src + Width + (Width - 1), sizeof(short)); int BlockSize = 8, Block = Width / BlockSize; // 測試表面一次性處理4個畫素處理8個要快一些 for (int Y = 0; Y < Height; Y++) { short *LinePS = Src + Y * Width; short *LinePD = Dest + Y * Width; if (Y != 0) { short *Temp = First; First = Second; Second = Third; Third = Temp; } if (Y == Height - 1) { memcpy(Third, Second, (Width + 2) * sizeof(short)); } else { memcpy(Third, Src + (Y + 1) * Width, sizeof(short)); memcpy(Third + 1, Src + (Y + 1) * Width, Width * sizeof(short)); // 由於備份了前面一行的資料,這裡即使Src和Dest相同也是沒有問題的 memcpy(Third + (Width + 1), Src + (Y + 1) * Width + (Width - 1), sizeof(short)); } for (int X = 0; X < Block * BlockSize; X += BlockSize) { __m128i P0 = _mm_loadu_si128((__m128i *)(First + X)); __m128i P1 = _mm_loadu_si128((__m128i *)(First + X + 1)); __m128i P2 = _mm_loadu_si128((__m128i *)(First + X + 2)); __m128i P3 = _mm_loadu_si128((__m128i *)(Second + X)); __m128i P4 = _mm_loadu_si128((__m128i *)(Second + X + 1)); __m128i P5 = _mm_loadu_si128((__m128i *)(Second + X + 2)); __m128i P6 = _mm_loadu_si128((__m128i *)(Third + X)); __m128i P7 = _mm_loadu_si128((__m128i *)(Third + X + 1)); __m128i P8 = _mm_loadu_si128((__m128i *)(Third + X + 2)); __m128i Sum0123 = _mm_adds_epi16(_mm_adds_epi16(P0, P1), _mm_adds_epi16(P2, P3)); __m128i Sum5678 = _mm_adds_epi16(_mm_adds_epi16(P5, P6), _mm_adds_epi16(P7, P8)); __m128i Sum = _mm_adds_epi16(_mm_adds_epi16(Sum0123, Sum5678), P4); _mm_storeu_si128((__m128i *)(LinePD + X), Sum); } for (int X = Block * BlockSize; X < Width; X++) { int P0 = First[X], P1 = First[X + 1], P2 = First[X + 2]; int P3 = Second[X], P4 = Second[X + 1], P5 = Second[X + 2]; int P6 = Third[X], P7 = Third[X + 1], P8 = Third[X + 2]; LinePD[X] = P0 + P1 + P2 + P3 + P4 + P5 + P6 + P7 + P8; } } free(RowCopy); return IM_STATUS_OK; }
三、其他小細節的優化
還有很多細節上的東西對速度有一定的影響,我們發現,要儘量減少記憶體的分配,如果能共用的記憶體,就一定要共用,特別是讀和寫的記憶體如果是同一個,會對速度產生一定的加速,比如,我們分配的dx 和 dy記憶體就可以和後續的Eignev記憶體共用同一個地址,因為dx和dy後續就不需要使用了,這樣即節省了記憶體又提高了速度。
另外, 因為角點不會存在於影象周邊一圈畫素中,因此,邊緣就不可以不用計算,這在減少計算量的同時,對於部分演演算法,也可以減少一些記憶體複製。
四、速度優化結果探討
經過一系列的操作,我做了5個版本的測試,第一個是基本重複Opencv的程式碼,第二個是按照上述描述吧threshold, dilate等過程集中到一起,第三個使用-255到255範圍內的dx/dy,第四個是用使用-127到127範圍內的dx/dy,第五個是用-63到63範圍內的dx/dy, 對一副1920*1024大小的測試影象,做同引數的角點測試,耗時基本如下:
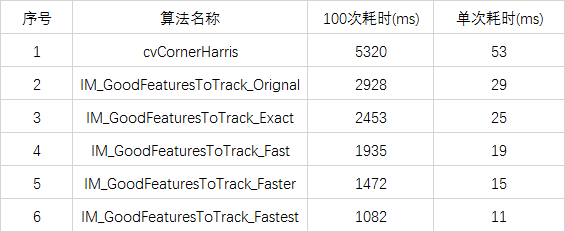
Opencv中我測試的還只是其goodFeaturesToTrack中的部分運算元,估計全部加起來可能要90ms一次,因此,可以看到提速的比例和空間相當大。
當然,這裡並不是說CV不好,而是針對某些具體的場景,我們還可以進一步增強其實用性。
在回到我們的初衷,我們想實現的視訊的實時增強,這個一般要求單幀的處理耗時不易大於20ms, 看來即使使用我這個最簡化的版本,實時的夢想還是不太靠譜啊,哎,還是得靠GPU來做。 不夠如果把視訊大小改為1024*768呢,那這個的耗時可以減低到5ms,也許還有希望。
五、結果比較
選擇了幾個比較常用的測試圖做比較,發現原始的版本和最速版基本上麼有大的區別,只有區域性有幾個點有偏移,而且從視覺上看也不能說最速版的結果就不正確。
