LangChain實戰
1.概述
最近,在研究LangChain時,發現一些比較有意思的點,今天筆者將給大家分享關於LangChain的一些內容。
2.內容
2.1 什麼是LangChain?
LangChain是一項旨在賦能開發人員利用語言模型構建端到端應用程式的強大框架。它的設計理念在於簡化和加速利用大型語言模型(LLM)和對話模型構建應用程式的過程。這個框架提供了一套全面的工具、元件和介面,旨在簡化基於大型語言模型和對話模型的應用程式開發過程。
LangChain本質上可被視為類似於開源GPT的外掛。它不僅提供了豐富的大型語言模型工具,還支援在開源模型的基礎上快速增強模型的功能。通過LangChain,開發人員可以更輕鬆地管理與語言模型的互動,無縫地連線多個元件,並整合額外的資源,如API和資料庫等,以加強應用的能力和靈活性。
LangChain的優勢在於為開發人員提供了一個便捷的框架,使其能夠更高效地構建應用程式,利用最先進的語言模型和對話系統,同時能夠靈活地客製化和整合其他必要的資源,為應用程式的開發和部署提供了更大的靈活性和便利性。
2.2 LangChain框架組成?
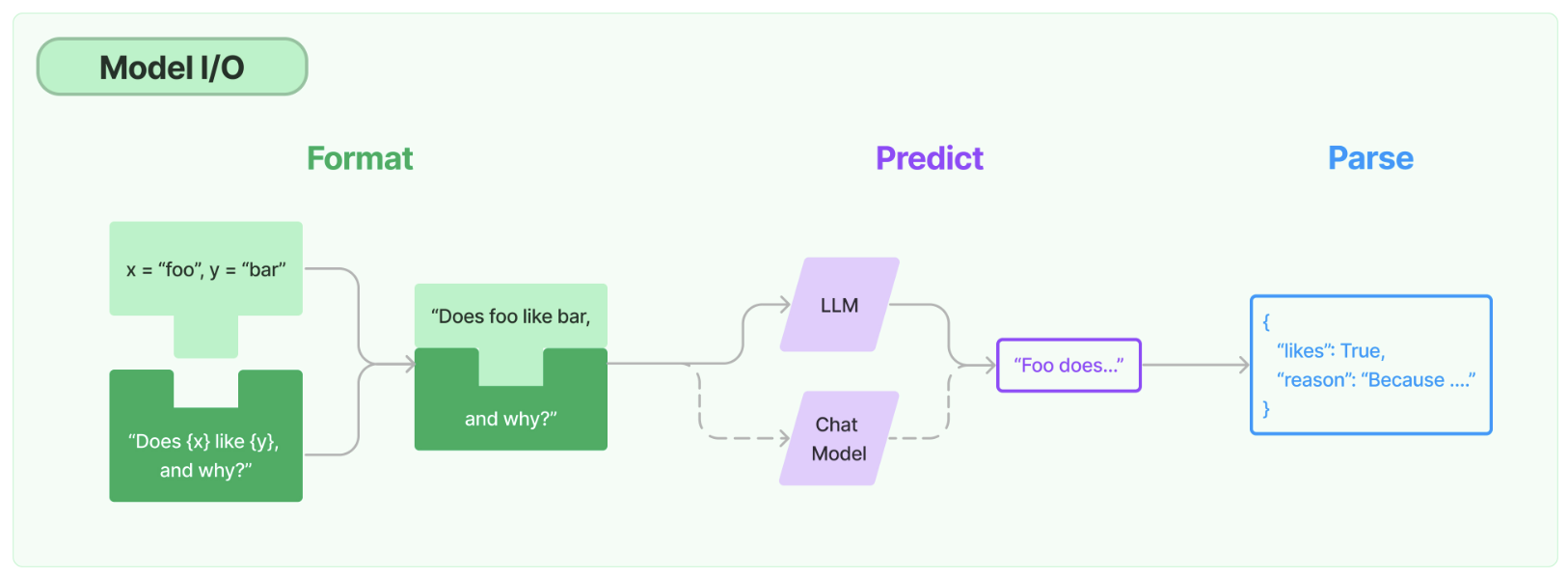
1.Model
任何語言模型應用的核心要素是…… 模型。LangChain為您提供了與任何語言模型進行介面的基本構件。
- 提示:模板化、動態選擇和管理模型輸入
- 語言模型:通過通用介面呼叫語言模型
- 輸出解析器:從模型輸出中提取資訊
此外,LangChain還提供了額外的關鍵功能,如:
- 模型介面卡:通過介面卡將不同型別的語言模型無縫整合到應用程式中。
- 模型優化器:優化和調整模型以提高效能和效率。
- 自定義元件:允許開發人員根據特定需求建立和整合自定義元件,以擴充套件和改進模型的功能。
2.Retrieval
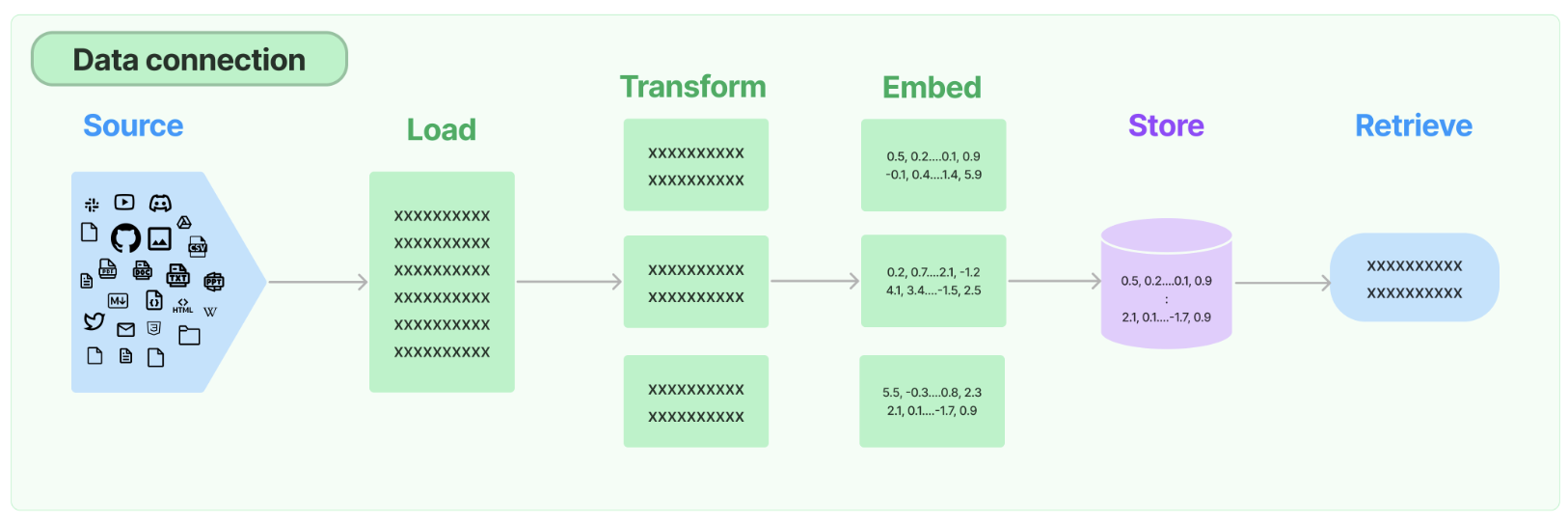
許多大型語言模型(LLM)應用需要使用者特定的資料,這些資料並不屬於模型的訓練集。實現這一點的主要方法是通過檢索增強生成(RAG)。在這個過程中,會檢索外部資料,然後在生成步驟中傳遞給LLM。
LangChain為RAG應用提供了從簡單到複雜的所有構建模組。檔案的此部分涵蓋與檢索步驟相關的所有內容,例如資料的獲取。儘管聽起來簡單,但實際上可能相當複雜。這包括幾個關鍵模組。
檔案載入器
從許多不同來源載入檔案。LangChain提供超過100種不同的檔案載入器,並與其他主要提供者(如AirByte和Unstructured)進行整合。我們提供與各種位置(私人S3儲存桶、公共網站)的各種檔案型別(HTML、PDF、程式碼)的載入整合。
檔案轉換器
檢索的關鍵部分是僅獲取檔案的相關部分。這涉及幾個轉換步驟,以最佳準備檔案進行檢索。其中一個主要步驟是將大型檔案分割(或分塊)為較小的塊。LangChain提供了幾種不同的演演算法來執行此操作,同時針對特定檔案型別(程式碼、Markdown等)進行了優化邏輯。
文字嵌入模型
檢索的另一個關鍵部分是為檔案建立嵌入。嵌入捕獲文字的語意含義,使您能夠快速高效地查詢其他類似的文字。LangChain與超過25種不同的嵌入提供者和方法進行整合,涵蓋了從開源到專有API的各種選擇,使您可以選擇最適合您需求的方式。LangChain提供了標準介面,使您能夠輕鬆切換模型。
向量儲存
隨著嵌入技術的興起,出現了對資料庫的需求,以支援這些嵌入的有效儲存和搜尋。LangChain與超過50種不同的向量儲存進行整合,涵蓋了從開源本地儲存到雲託管專有儲存的各種選擇,使您可以選擇最適合您需求的方式。LangChain提供標準介面,使您能夠輕鬆切換向量儲存。
檢索器
一旦資料儲存在資料庫中,您仍需要檢索它。LangChain支援許多不同的檢索演演算法,這是我們增加最多價值的領域之一。我們支援易於入門的基本方法,即簡單的語意搜尋。然而,我們還在此基礎上新增了一系列演演算法以提高效能。這些包括:
- 父檔案檢索器:這允許您為每個父檔案建立多個嵌入,使您能夠查詢較小的塊,但返回更大的上下文。
- 自查詢檢索器:使用者的問題通常包含對不僅僅是語意的某些邏輯的參照,而是可以最好表示為後設資料過濾器的邏輯。自查詢允許您從查詢中提取出語意部分以及查詢中存在的其他後設資料過濾器。
- 組合檢索器:有時您可能希望從多個不同來源或使用多種不同演演算法檢索檔案。組合檢索器可以輕鬆實現此操作。
3.Chains
單獨使用LLM適用於簡單的應用程式,但更復雜的應用程式需要將LLM連結起來,要麼彼此連結,要麼與其他元件連結。
LangChain提供了兩個高階框架來「連結」元件。傳統方法是使用Chain介面。更新的方法是使用LangChain表達語言(LCEL)。在構建新應用程式時,我們建議使用LCEL進行鏈式組合。但是,我們繼續支援許多有用的內建Chain,因此我們在這裡對兩個框架進行了檔案化。正如我們將在下面提到的,Chain本身也可以用於LCEL,因此兩者並不是互斥的。
新內容補充:
此外,LangChain還提供了其他關於鏈式組合的重要內容:
- 模組相容性:LangChain旨在確保不同模組之間的相容性,使得可以無縫地將不同型別的LLMs和其他元件相互連結,以構建更加複雜和高效的應用程式。
- 動態調整:框架允許動態調整不同模組和LLMs之間的連線方式,從而使得應用程式的功能和效能得到靈活的調整和優化。
- 可延伸性:LangChain提供了靈活的擴充套件機制,允許開發人員根據具體需求客製化新的連結策略和模組組合,以適應不同場景下的需求。
LCEL最顯著的部分是它提供了直觀且易讀的組合語法。但更重要的是,它還提供了一流的支援。為一個簡單且常見的例子,我們可以看到如何將提示(prompt)、模型和輸出解析器結合起來:
from langchain.chat_models import ChatAnthropic from langchain.prompts import ChatPromptTemplate from langchain.schema import StrOutputParser model = ChatAnthropic() prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}"), ]) runnable = prompt | model | StrOutputParser()
Chain 是「鏈式」應用程式的傳統介面。我們通常很泛化地定義 Chain 為對元件的一系列呼叫,其中可能包括其他鏈。基本介面很簡單:
class Chain(BaseModel, ABC): """Base interface that all chains should implement.""" memory: BaseMemory callbacks: Callbacks def __call__( self, inputs: Any, return_only_outputs: bool = False, callbacks: Callbacks = None, ) -> Dict[str, Any]: ...
4.Memory
在與模型互動時,用於儲存上下文狀態。模型本身不具備上下文記憶,因此在與模型互動時,需要傳遞聊天內容的上下文。
大多數大型語言模型應用具有對談式介面。對話的一個基本組成部分是能夠參照先前在對話中提到的資訊。至少,對談系統應能直接存取一定範圍內的先前訊息。更復雜的系統需要具有一個持續更新的世界模型,使其能夠保持關於實體及其關係的資訊。
我們稱儲存關於先前互動的資訊的能力為「記憶」。LangChain為向系統新增記憶提供了許多實用工具。這些實用工具可以單獨使用,也可以無縫地整合到鏈中。
一個記憶系統需要支援兩種基本操作:讀取和寫入。要記住,每個鏈定義了一些核心執行邏輯,期望得到某些輸入。其中一些輸入直接來自使用者,但有些輸入可能來自記憶。在給定執行中,一個鏈將兩次與其記憶系統互動。
在接收到初始使用者輸入之後,但在執行核心邏輯之前,鏈將從其記憶系統中讀取並增補使用者輸入。
在執行核心邏輯後,但在返回答案之前,鏈將把當前執行的輸入和輸出寫入記憶,以便在將來的執行中參照。
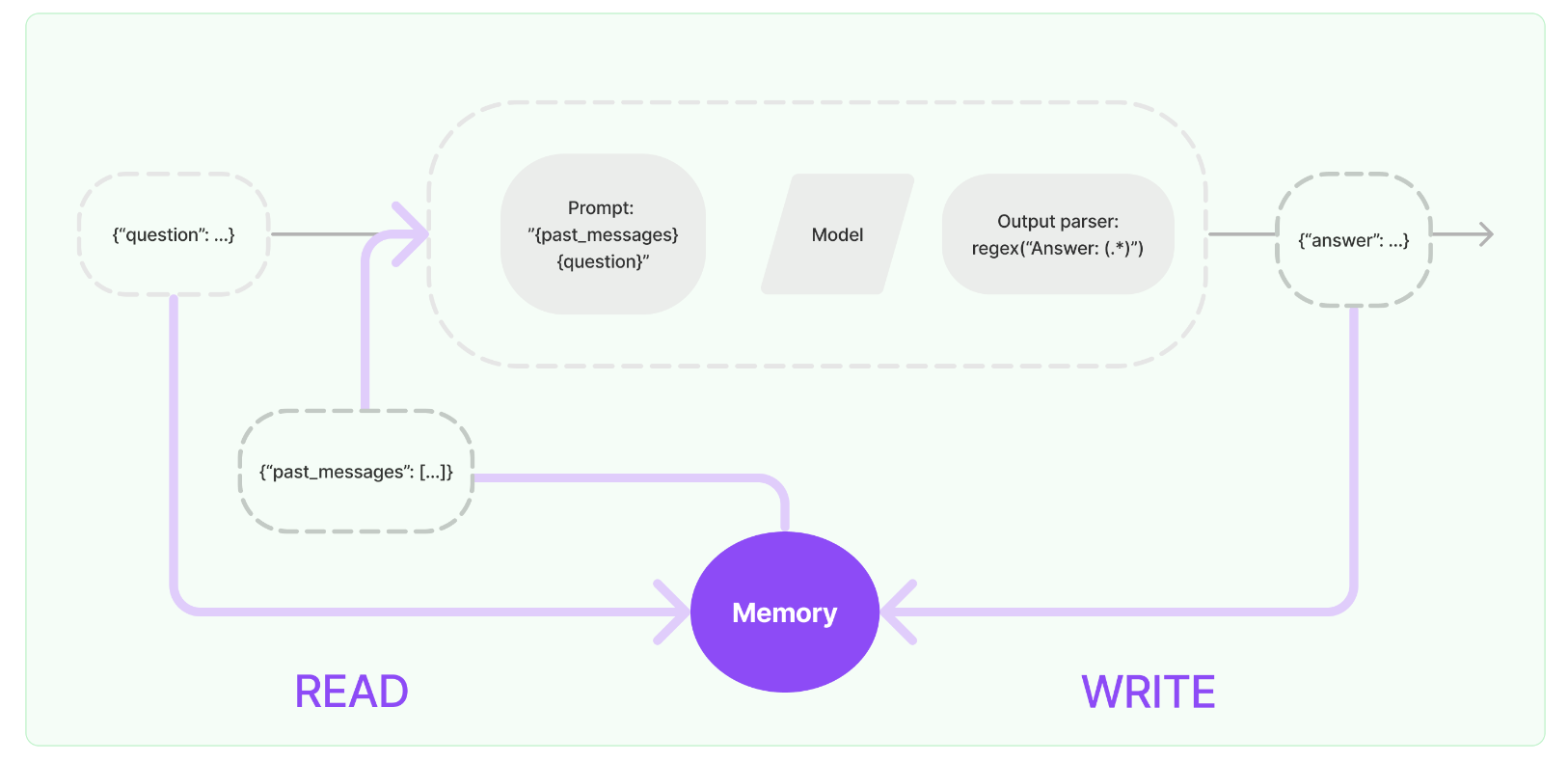
讓我們看一看如何在鏈中使用 ConversationBufferMemory。ConversationBufferMemory 是一種極其簡單的記憶體形式,它只是在緩衝區中保留了一系列聊天訊息,並將其傳遞到提示模板中。
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory() memory.chat_memory.add_user_message("hi!") memory.chat_memory.add_ai_message("what's up?")
在鏈中使用記憶時,有一些關鍵概念需要理解。請注意,這裡我們介紹了適用於大多數記憶型別的一般概念。每種單獨的記憶型別可能都有其自己的引數和概念,需要理解。
通常情況下,連結收或返回多個輸入/輸出鍵。在這些情況下,我們如何知道要儲存到聊天訊息歷史記錄的鍵是哪些?這通常可以通過記憶型別的 input_key 和 output_key 引數來控制。這些引數預設為 None - 如果只有一個輸入/輸出鍵,那麼會自動使用該鍵。但是,如果有多個輸入/輸出鍵,則必須明確指定要使用哪一個的名稱。最後,讓我們來看看如何在鏈中使用這個功能。我們將使用一個 LLMChain,並展示如何同時使用 LLM 和 ChatModel。
使用一個LLM:
from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChain from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0) # Notice that "chat_history" is present in the prompt template template = """You are a nice chatbot having a conversation with a human. Previous conversation: {chat_history} New human question: {question} Response:""" prompt = PromptTemplate.from_template(template) # Notice that we need to align the `memory_key` memory = ConversationBufferMemory(memory_key="chat_history") conversation = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory )
使用一個ChatModel:
from langchain.chat_models import ChatOpenAI from langchain.prompts import ( ChatPromptTemplate, MessagesPlaceholder, SystemMessagePromptTemplate, HumanMessagePromptTemplate, ) from langchain.chains import LLMChain from langchain.memory import ConversationBufferMemory llm = ChatOpenAI() prompt = ChatPromptTemplate( messages=[ SystemMessagePromptTemplate.from_template( "You are a nice chatbot having a conversation with a human." ), # The `variable_name` here is what must align with memory MessagesPlaceholder(variable_name="chat_history"), HumanMessagePromptTemplate.from_template("{question}") ] ) # Notice that we `return_messages=True` to fit into the MessagesPlaceholder # Notice that `"chat_history"` aligns with the MessagesPlaceholder name. memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) conversation = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory )
5.Agents
Agents的核心理念是利用LLM選擇要採取的一系列行動。在鏈式結構中,行動序列是寫死的(在程式碼中)。而在Agents中,語言模型被用作推理引擎,決定要採取哪些行動以及順序。
一些重要的術語(和模式)需要了解:
- AgentAction:這是一個資料類,代表Agents應該執行的操作。它具有一個tool屬性(應該呼叫的工具的名稱)和一個tool_input屬性(該工具的輸入)。
- AgentFinish:這是一個資料類,表示Agent已經完成並應該返回給使用者。它有一個return_values引數,這是要返回的字典。通常它只有一個鍵 - output - 是一個字串,因此通常只返回這個鍵。
- intermediate_steps:這些表示傳遞的先前Agent操作和對應的輸出。這些很重要,以便在將來的迭代中傳遞,以便Agent知道它已經完成了哪些工作。它的型別被定義為List[Tuple[AgentAction, Any]]。請注意,observation目前以Any型別留下以保持最大的靈活性。在實踐中,這通常是一個字串。
6.Callbacks
LangChain提供了回撥系統,允許您連線到LLM應用程式的各個階段。這對於紀錄檔記錄、監控、流處理和其他任務非常有用。
您可以通過使用API中始終可用的callbacks引數來訂閱這些事件。該引數是處理程式物件的列表,這些處理程式物件應該詳細實現下面描述的一個或多個方法。
CallbackHandlers 是實現 CallbackHandler 介面的物件,該介面為可以訂閱的每個事件都有一個方法。當事件觸發時,CallbackManager 將在每個處理程式上呼叫適當的方法。
class BaseCallbackHandler: """Base callback handler that can be used to handle callbacks from langchain.""" def on_llm_start( self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any ) -> Any: """Run when LLM starts running.""" def on_chat_model_start( self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any ) -> Any: """Run when Chat Model starts running.""" def on_llm_new_token(self, token: str, **kwargs: Any) -> Any: """Run on new LLM token. Only available when streaming is enabled.""" def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any: """Run when LLM ends running.""" def on_llm_error( self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any ) -> Any: """Run when LLM errors.""" def on_chain_start( self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any ) -> Any: """Run when chain starts running.""" def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any: """Run when chain ends running.""" def on_chain_error( self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any ) -> Any: """Run when chain errors.""" def on_tool_start( self, serialized: Dict[str, Any], input_str: str, **kwargs: Any ) -> Any: """Run when tool starts running.""" def on_tool_end(self, output: str, **kwargs: Any) -> Any: """Run when tool ends running.""" def on_tool_error( self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any ) -> Any: """Run when tool errors.""" def on_text(self, text: str, **kwargs: Any) -> Any: """Run on arbitrary text.""" def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any: """Run on agent action.""" def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any: """Run on agent end."""
LangChain提供了一些內建處理程式,供開發者快速開始使用。這些處理程式位於 langchain/callbacks 模組中。最基本的處理程式是 StdOutCallbackHandler,它簡單地將所有事件記錄到標準輸出(stdout)。
注意:當物件的 verbose 標誌設定為 true 時,即使未顯式傳入,StdOutCallbackHandler 也會被呼叫。
from langchain.callbacks import StdOutCallbackHandler from langchain.chains import LLMChain from langchain.llms import OpenAI from langchain.prompts import PromptTemplate handler = StdOutCallbackHandler() llm = OpenAI() prompt = PromptTemplate.from_template("1 + {number} = ") # Constructor callback: First, let's explicitly set the StdOutCallbackHandler when initializing our chain chain = LLMChain(llm=llm, prompt=prompt, callbacks=[handler]) chain.run(number=2) # Use verbose flag: Then, let's use the `verbose` flag to achieve the same result chain = LLMChain(llm=llm, prompt=prompt, verbose=True) chain.run(number=2) # Request callbacks: Finally, let's use the request `callbacks` to achieve the same result chain = LLMChain(llm=llm, prompt=prompt) chain.run(number=2, callbacks=[handler])
結果如下:
> Entering new LLMChain chain... Prompt after formatting: 1 + 2 = > Finished chain. > Entering new LLMChain chain... Prompt after formatting: 1 + 2 = > Finished chain. > Entering new LLMChain chain... Prompt after formatting: 1 + 2 = > Finished chain. '\n\n3'
3.快速使用
3.1 環境設定
使用LangChain通常需要與一個或多個模型提供商、資料儲存、API等進行整合。在本範例中,我們將使用OpenAI的模型API。
首先,我們需要安裝他們的Python包:
pip install langchain pip install openai
在初始化OpenAI LLM類時直接通過名為 openai_api_key 的引數傳遞金鑰:
from langchain.llms import OpenAI llm = OpenAI(openai_api_key="...")
3.2 LLM
在LangChain中有兩種型別的語言模型,分別被稱為:
- LLMs:這是一個以字串作為輸入並返回字串的語言模型。
- ChatModels:這是一個以訊息列表作為輸入並返回訊息的語言模型。
LLMs的輸入/輸出簡單易懂 - 字串。但ChatModels呢?那裡的輸入是一個ChatMessages列表,輸出是一個單獨的ChatMessage。ChatMessage有兩個必需的組成部分:
- content:這是訊息的內容。
- role:這是產生ChatMessage的實體的角色。
LangChain提供了幾個物件來輕鬆區分不同的角色:
- HumanMessage:來自人類/使用者的ChatMessage。
- AIMessage:來自AI/助手的ChatMessage。
- SystemMessage:來自系統的ChatMessage。
- FunctionMessage:來自函數呼叫的ChatMessage。
如果這些角色都不合適,還有一個ChatMessage類,可以手動指定角色。
LangChain提供了標準介面,但瞭解這種差異有助於構建特定語言模型的提示。LangChain提供的標準介面有兩種方法:
- predict:接受一個字串,返回一個字串。
- predict_messages:接受一個訊息列表,返回一個訊息。
from langchain.llms import OpenAI from langchain.chat_models import ChatOpenAI llm = OpenAI() chat_model = ChatOpenAI() llm.predict("hi!") >>> "Hi" chat_model.predict("hi!") >>> "Hi"
OpenAI 和 ChatOpenAI 物件基本上只是設定物件。開發者可以使用諸如 temperature 等引數來初始化它們,並在各處傳遞它們。
接下來,讓我們使用 predict 方法來處理一個字串輸入。
text = "What would be a good company name for a company that makes colorful socks?" llm.predict(text) # >> Feetful of Fun chat_model.predict(text) # >> Socks O'Color
最後,讓我們使用 predict_messages 方法來處理一個訊息列表。
from langchain.schema import HumanMessage text = "What would be a good company name for a company that makes colorful socks?" messages = [HumanMessage(content=text)] llm.predict_messages(messages) # >> Feetful of Fun chat_model.predict_messages(messages) # >> Socks O'Color
3.3 Prompt 模版
PromptTemplates也可以用於生成訊息列表。在這種情況下,提示不僅包含有關內容的資訊,還包含每條訊息的資訊(其角色、在列表中的位置等)。在這裡,最常見的情況是ChatPromptTemplate是ChatMessageTemplate列表。每個ChatMessageTemplate包含了如何格式化ChatMessage的指令 - 其角色以及內容。
from langchain.prompts.chat import ChatPromptTemplate template = "You are a helpful assistant that translates {input_language} to {output_language}." human_template = "{text}" chat_prompt = ChatPromptTemplate.from_messages([ ("system", template), ("human", human_template), ]) chat_prompt.format_messages(input_language="English", output_language="French", text="I love programming.")
3.3 Output parsers
OutputParsers 將LLM的原始輸出轉換為可在下游使用的格式。其中主要的OutputParsers型別包括:
- 將LLM的文字轉換為結構化資訊(例如 JSON)
- 將 ChatMessage 轉換為純字串
- 將呼叫返回的除訊息外的額外資訊(例如 OpenAI 函數呼叫)轉換為字串。
from langchain.schema import BaseOutputParser class CommaSeparatedListOutputParser(BaseOutputParser): """Parse the output of an LLM call to a comma-separated list.""" def parse(self, text: str): """Parse the output of an LLM call.""" return text.strip().split(", ") CommaSeparatedListOutputParser().parse("hi, bye") # >> ['hi', 'bye']
3.4 PromptTemplate + LLM + OutputParser
我們現在可以將所有這些組合成一個鏈條。該鏈條將接收輸入變數,將其傳遞到提示模板以建立提示,將提示傳遞給語言模型,然後通過(可選的)輸出解析器傳遞輸出。這是打包模組化邏輯的便捷方式。
from langchain.chat_models import ChatOpenAI from langchain.prompts.chat import ChatPromptTemplate from langchain.schema import BaseOutputParser class CommaSeparatedListOutputParser(BaseOutputParser): """Parse the output of an LLM call to a comma-separated list.""" def parse(self, text: str): """Parse the output of an LLM call.""" return text.strip().split(", ") template = """You are a helpful assistant who generates comma separated lists. A user will pass in a category, and you should generate 5 objects in that category in a comma separated list. ONLY return a comma separated list, and nothing more.""" human_template = "{text}" chat_prompt = ChatPromptTemplate.from_messages([ ("system", template), ("human", human_template), ]) chain = chat_prompt | ChatOpenAI() | CommaSeparatedListOutputParser() chain.invoke({"text": "colors"}) # >> ['red', 'blue', 'green', 'yellow', 'orange']
請注意,我們使用 | 符號將這些元件連線在一起。這種 | 符號稱為 LangChain 表達語言。
4.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!
另外,博主出書了《Kafka並不難學》和《Hadoop巨量資料挖掘從入門到進階實戰》,喜歡的朋友或同學, 可以在公告欄那裡點選購買連結購買博主的書進行學習,在此感謝大家的支援。關注下面公眾號,根據提示,可免費獲取書籍的教學視訊。
郵箱:[email protected]
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社群1):424769183
QQ群(Kafka並不難學): 825943084
溫馨提示:請大家加群的時候寫上加群理由(姓名+公司/學校),方便管理員稽核,謝謝!
