自編碼器AE全方位探析:構建、訓練、推理與多平臺部署
本文深入探討了自編碼器(AE)的核心概念、型別、應用場景及實戰演示。通過理論分析和實踐結合,我們詳細解釋了自動編碼器的工作原理和數學基礎,並通過具體程式碼範例展示了從模型構建、訓練到多平臺推理部署的全過程。
關注TechLead,分享AI與雲服務技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
一、自編碼器簡介
自編碼器的定義
自編碼器(Autoencoder, AE)是一種資料的壓縮演演算法,其中壓縮和解壓縮函數是資料相關的、有損的、從樣本中自動學習的。自編碼器通常用於學習高效的編碼,在神經網路的形式下,自編碼器可以用於降維和特徵學習。
自編碼器的歷史發展
- 1980年代初期:自動編碼器的早期研究
- 1990年代:使用反向傳播訓練自動編碼器
- 2000年代:深度學習時代下的自動編碼器研究,例如堆疊自動編碼器
- 最近的進展:自動編碼器在生成模型、異常檢測等方向的新應用
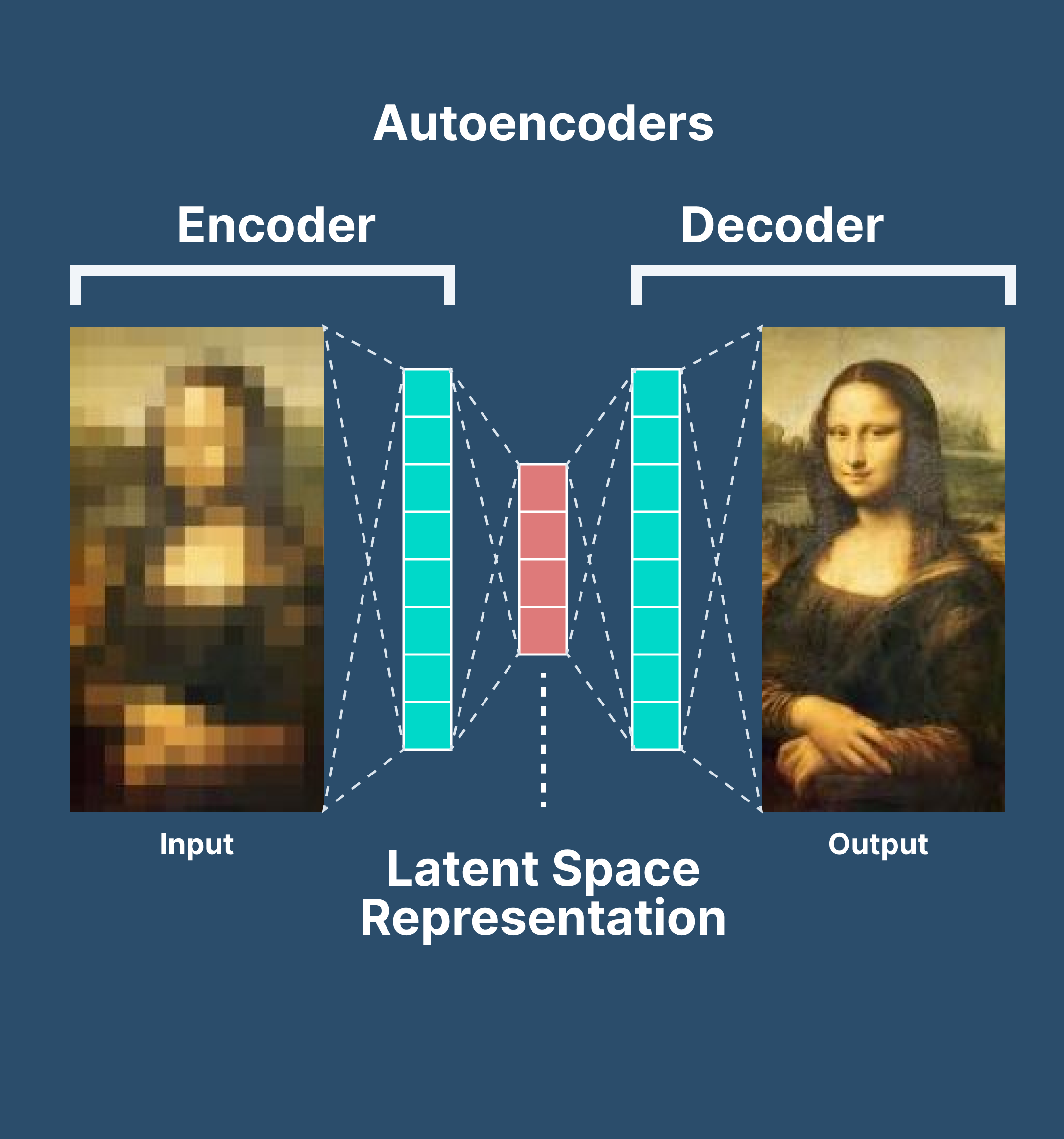
自編碼器的工作原理
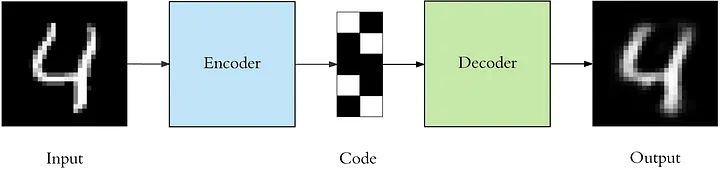
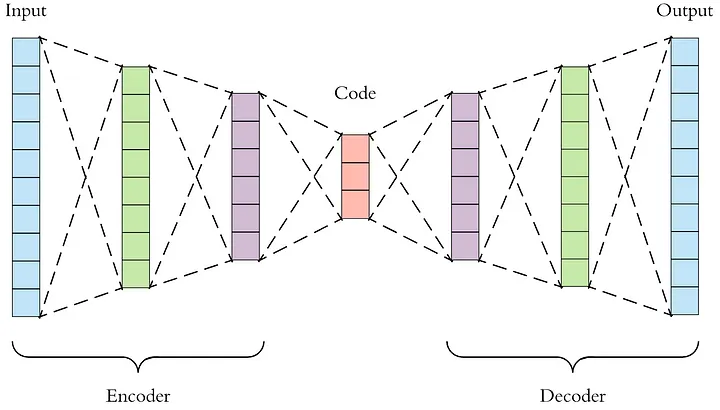
自編碼器由兩個主要部分組成:編碼器和解碼器。
-
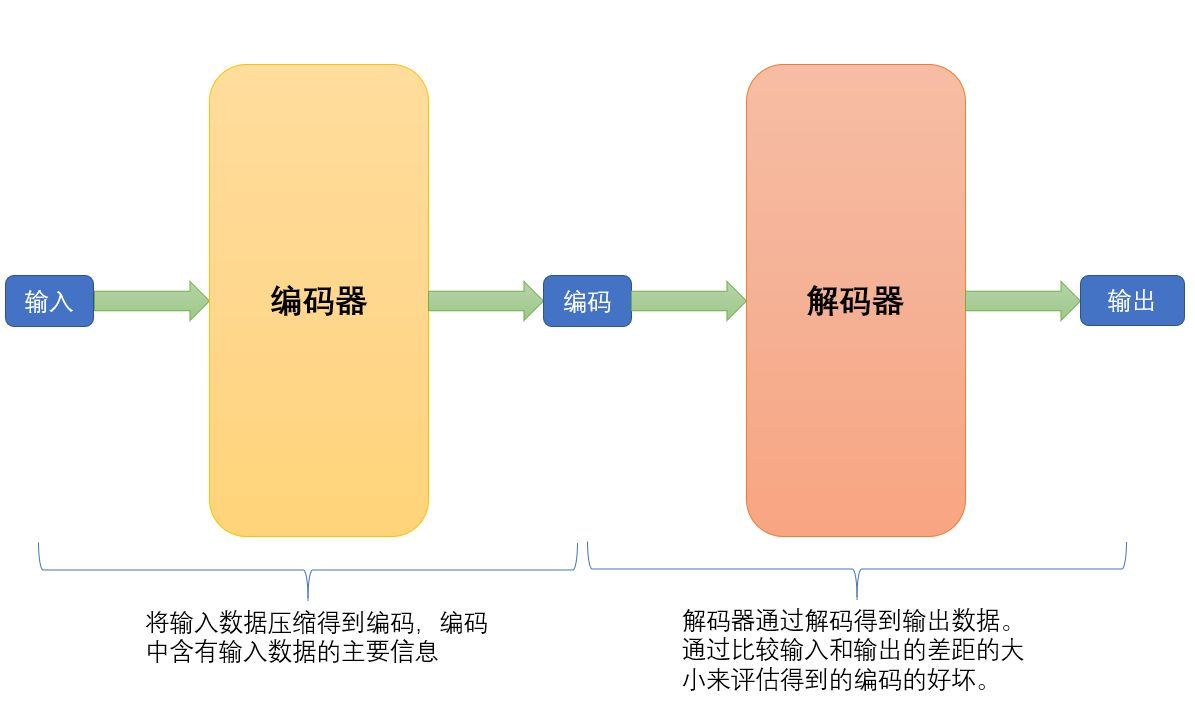
編碼器:編碼器部分將輸入資料壓縮成一個潛在空間表示。它通常由一個神經網路組成,並通過減小資料維度來學習資料的壓縮表示。
-
解碼器:解碼器部分則試圖從潛在空間表示重構原始資料。與編碼器相似,解碼器也由一個神經網路組成,但是它工作的方式與編碼器相反。
-
訓練過程:通過最小化重構損失(例如均方誤差)來訓練自動編碼器。
-
應用領域:自動編碼器可以用於降維、特徵學習、生成新的與訓練資料相似的樣本等。
二、自動編碼器的型別
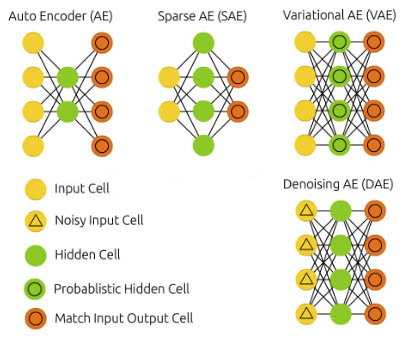
線性自動編碼器
- 定義:線性自動編碼器是一種利用線性變換進行編碼和解碼的自動編碼器。
- 工作原理:
- 編碼器:使用線性函數將輸入對映到潛在空間。
- 解碼器:使用線性函數將潛在空間對映回原始空間。
- 與PCA的關係:可以證明線性自動編碼器與主成分分析(PCA)在某些條件下等價。
深度自動編碼器
- 定義:深度自動編碼器由多個隱藏層組成,允許捕捉資料的更復雜結構。
- 工作原理:
- 多層結構:使用多個非線性隱藏層來表示更復雜的函數。
- 非線性對映:通過非線性啟用函數提取輸入資料的高階特徵。
稀疏自動編碼器
- 定義:稀疏自動編碼器是在自動編碼器的損失函數中加入稀疏性約束的自動編碼器。
- 工作原理:
- 稀疏約束:通過L1正則化或KL散度等方法強制許多編碼單元為零。
- 特徵選擇:稀疏約束有助於選擇重要的特徵,從而實現降維。
變分自動編碼器
- 定義:變分自動編碼器(VAE)是一種統計生成模型,旨在通過學習資料的潛在分佈來生成新的樣本。
- 工作原理:
- 潛在變數模型:通過變分推斷方法估計潛在變數的後驗分佈。
- 生成新樣本:從估計的潛在分佈中取樣,然後通過解碼器生成新樣本。
三、自編碼器的應用場景
資料降維
- 定義:資料降維是減小資料維度的過程,以便更有效地分析和視覺化。
- 工作原理:自動編碼器通過捕捉資料中的主要特徵,並將其對映到較低維度的空間,實現降維。
- 應用範例:在視覺化複雜資料集時,例如文字或影象集合。
異常檢測
- 定義:異常檢測是識別不符合預期模式的資料點的過程。
- 工作原理:自動編碼器能夠學習資料的正常分佈,然後用於識別不符合這一分佈的異常樣本。
- 應用範例:在工業裝置監測中,用於發現可能的故障和異常行為。
特徵學習
- 定義:特徵學習是從原始資料中自動學習出有效特徵的過程。
- 工作原理:自動編碼器能夠通過深度神經網路提取更抽象和有用的特徵。
- 應用範例:在計算機視覺中,用於提取影象的關鍵特徵。
生成模型
- 定義:生成模型是用於生成與訓練資料相似的新資料的模型。
- 工作原理:特定型別的自動編碼器,例如變分自動編碼器,可以用來生成新的樣本。
- 應用範例:在藝術創作和藥物設計中生成新的設計和結構。
資料去噪
- 定義:資料去噪是從帶噪聲的資料中恢復出原始訊號的過程。
- 工作原理:自動編碼器可以被訓練為識別和移除輸入資料中的噪聲。
- 應用範例:在醫學影象處理中,用於清除影象中的不必要噪聲。
半監督學習
- 定義:半監督學習使用標記和未標記的資料來構建預測模型。
- 工作原理:自動編碼器可以用於利用未標記的資料提取有用的特徵,進而增強分類或迴歸模型。
- 應用範例:在語音識別或自然語言處理中,利用大量未標記的資料進行訓練。
四、自編碼器的實戰演示
4.1 環境準備
環境準備是所有機器學習專案的起點。在進行自動編碼器的實戰演示之前,確保你的計算環境滿足以下要求:
作業系統
- 推薦使用Linux或macOS,Windows也可支援。
- 版本要求不特別嚴格,但推薦使用最近幾年的穩定版本。
Python環境
- 使用Python 3.6或更高版本。
- 建議使用虛擬環境管理工具,例如
virtualenv或conda來隔離專案環境。
安裝深度學習框架
- 使用PyTorch作為深度學習框架。
- 安裝命令:
pip install torch torchvision - GPU支援(如果可用):確保CUDA版本與PyTorch相容。
依賴庫安裝
- Numpy:用於數值計算,命令
pip install numpy。 - Matplotlib:用於視覺化,命令
pip install matplotlib。 - Scikit-learn:用於資料預處理和評估,命令
pip install scikit-learn。
資料集準備
- 根據實戰專案的需要,預先下載和準備相關資料集。
- 確保資料集的格式和質量符合實驗要求。
開發工具
- 推薦使用Jupyter Notebook或者VS Code等現代開發環境,便於程式碼編寫和結果展示。
硬體要求
- 至少4GB的RAM。
- 如果進行大型訓練,建議使用支援CUDA的NVIDIA顯示卡。
4.2 構建自編碼器模型
4.2.1 設計模型架構
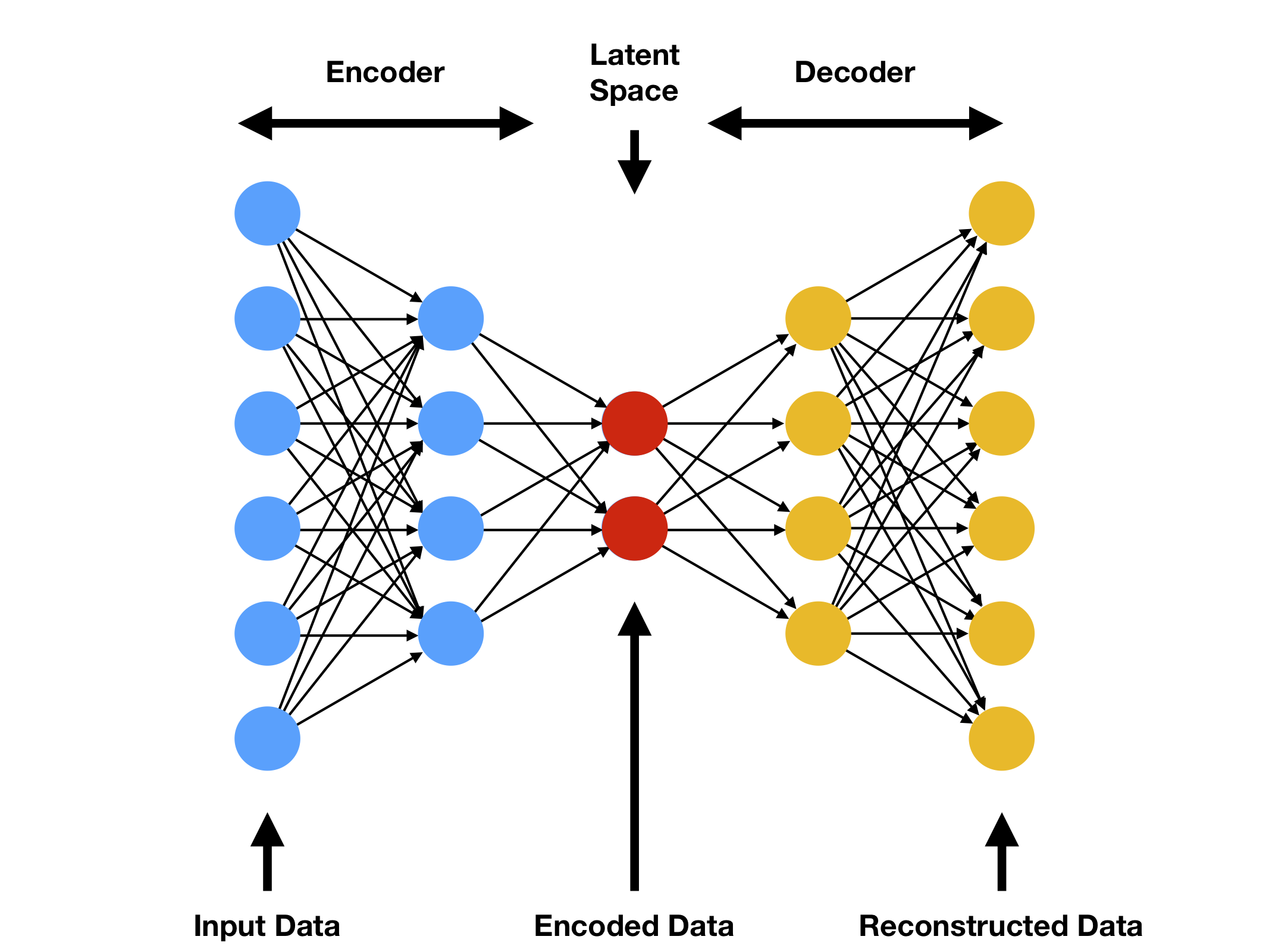
首先,我們需要設計自動編碼器的架構,確定編碼器和解碼器的層數、大小和啟用函數。
- 編碼器:通常包括幾個全連線層或折積層,用於將輸入資料對映到隱藏表示。
- 解碼器:使用與編碼器相反的結構,將隱藏表示對映回原始資料的維度。
4.2.2 編寫程式碼
以下是使用PyTorch實現自動編碼器模型的範例程式碼:
import torch.nn as nn
class Autoencoder(nn.Module):
def __init__(self, input_dim, encoding_dim):
super(Autoencoder, self).__init__()
# 編碼器部分
self.encoder = nn.Sequential(
nn.Linear(input_dim, encoding_dim * 2),
nn.ReLU(),
nn.Linear(encoding_dim * 2, encoding_dim),
nn.ReLU()
)
# 解碼器部分
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, encoding_dim * 2),
nn.ReLU(),
nn.Linear(encoding_dim * 2, input_dim),
nn.Sigmoid() # 輸出範圍為0-1
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
上述程式碼定義了一個簡單的全連線自動編碼器。
input_dim是輸入資料的維度。encoding_dim是隱藏表示的維度。- 我們使用ReLU啟用函數,並在解碼器的輸出端使用Sigmoid啟用,確保輸出範圍在0到1之間。
4.2.3 模型訓練
對於模型訓練,我們通常使用MSE損失,並選擇適合的優化器,例如Adam。
from torch.optim import Adam
# 範例化模型
autoencoder = Autoencoder(input_dim=784, encoding_dim=64)
# 定義損失和優化器
criterion = nn.MSELoss()
optimizer = Adam(autoencoder.parameters(), lr=0.001)
# 訓練程式碼(迴圈、前向傳播、反向傳播等)
# ...
4.2.4 模型評估和視覺化
模型訓練後,可以通過對比原始輸入和解碼輸出來評估其效能。可以使用matplotlib進行視覺化。
4.3 訓練自編碼器
訓練自動編碼器是一個迭代的過程,需要正確地組織資料、設定合適的損失函數和優化器,並通過多次迭代優化模型的權重。以下是詳細步驟:
4.3.1 資料準備
準備適合訓練的資料集。通常,自動編碼器的訓練資料不需要標籤,因為目標是重構輸入。
- 資料載入:使用PyTorch的DataLoader來批次載入資料。
- 預處理:根據需要進行標準化、歸一化等預處理。
4.3.2 設定損失函數和優化器
通常,自動編碼器使用均方誤差(MSE)作為損失函數,以測量重構誤差。優化器如Adam通常是一個不錯的選擇。
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.001)
4.3.3 訓練迴圈
以下是標準的訓練迴圈,其中包括前向傳播、損失計算、反向傳播和權重更新。
# 設定訓練週期
epochs = 50
for epoch in range(epochs):
for data in dataloader:
# 獲取輸入資料
inputs, _ = data
# 清零梯度
optimizer.zero_grad()
# 前向傳播
outputs = autoencoder(inputs)
# 計算損失
loss = criterion(outputs, inputs)
# 反向傳播
loss.backward()
# 更新權重
optimizer.step()
# 列印訓練進度
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}")
4.3.4 驗證和測試
在訓練過程中或訓練結束後,對自動編碼器的效能進行驗證和測試。
- 使用單獨的驗證集評估模型在未見資料上的效能。
- 可以通過視覺化原始影象和重構影象來定性評估模型。
4.3.5 模型儲存
儲存訓練好的模型,以便以後使用或進一步優化。
torch.save(autoencoder.state_dict(), 'autoencoder_model.pth')
4.4 模型推理用於生成環境
部署自動編碼器到生成環境是一個複雜的任務,涉及模型的載入、預處理、推理以及後處理等步驟。以下是一些核心環節的指南:
4.4.1 模型載入
首先,需要從儲存的檔案中載入訓練好的模型。假設模型已儲存在'autoencoder_model.pth'中,載入的程式碼如下:
model = Autoencoder(input_dim=784, encoding_dim=64)
model.load_state_dict(torch.load('autoencoder_model.pth'))
model.eval() # 將模型設定為評估模式
4.4.2 資料預處理
在生成環境中,輸入資料可能來自不同的源,並且可能需要進行預處理以滿足模型的輸入要求。
- 載入資料:從檔案、資料庫或網路服務載入資料。
- 轉換資料:例如,將影象轉換為模型所需的維度和型別。
4.4.3 模型推理
使用處理過的輸入資料對模型進行推理,並獲取重構的輸出。
with torch.no_grad(): # 不需要計算梯度
outputs = model(inputs)
4.4.4 結果後處理和展示
根據具體應用,可能需要將模型的輸出進行進一步的處理和展示。
- 轉換輸出:將輸出轉換為適當的格式或維度。
- 展示結果:通過Web服務、圖表或其他方式展示結果。
4.4.5 整合到Web服務
在許多情況下,可能需要將自動編碼器整合到Web服務中,以便通過API進行存取。這可能涉及以下步驟:
- 構建API:使用諸如Flask或Django的框架構建API。
- 封裝模型:將推理程式碼封裝為可以通過HTTP呼叫的函數。
- 處理請求和響應:解析來自使用者端的請求,格式化模型的響應。
4.4.6 效能優化和擴充套件
在生成環境中,模型的效能和可延伸性可能是關鍵問題。
- 優化推理速度:可能涉及模型量化、硬體加速等。
- 擴充套件支援:可能需要叢集或其他技術來支援多使用者並行存取。
4.5 多平臺推理部署

在許多實際應用場景中,可能需要將訓練好的自動編碼器模型部署到不同的平臺或裝置上。這可能包括雲端伺服器、邊緣裝置、移動應用等。使用ONNX(Open Neural Network Exchange)格式可以方便地在不同平臺上部署模型。
4.5.1 轉換為ONNX格式
首先,需要將訓練好的PyTorch模型轉換為ONNX格式。這可以使用PyTorch的torch.onnx.export函數實現。
import torch.onnx
# 假設model是訓練好的模型
input_example = torch.rand(1, 784) # 建立一個輸入樣例
torch.onnx.export(model, input_example, "autoencoder.onnx")
4.5.2 ONNX模型驗證
可以使用ONNX的工具進行模型的驗證,確保轉換正確。
import onnx
onnx_model = onnx.load("autoencoder.onnx")
onnx.checker.check_model(onnx_model)
4.5.3 在不同平臺上部署
有了ONNX格式的模型,就可以使用許多支援ONNX的工具和框架在不同平臺上部署。
- 雲端部署:使用諸如Azure ML、AWS Sagemaker等雲服務部署模型。
- 邊緣裝置部署:使用ONNX Runtime或其他相容框架在IoT裝置上執行模型。
- 移動裝置部署:可使用像ONNX Runtime Mobile這樣的工具在iOS和Android裝置上部署。
4.5.4 效能調優
部署到特定平臺時,可能需要進行效能調優以滿足實時或資源受限的需求。
- 量化:通過減少權重和計算的精度降低資源消耗。
- 加速器支援:針對GPU、FPGA等硬體加速器優化模型。
4.5.5 持續監控和更新
部署後的持續監控和定期更新是確保模型在生產環境中穩定執行的關鍵。
- 監控:監視模型的效能、資源使用和預測質量。
- 更新:根據新資料和反饋定期更新和優化模型。
五、總結
本文詳細介紹了自動編碼器的理論基礎、不同型別、應用場景以及實戰部署。以下是主要的實戰細節總結:
理論與實踐結合
我們不僅深入探討了自動編碼器的工作原理和數學基礎,還通過實際程式碼範例展示瞭如何構建和訓練模型。理論與實踐的結合可以增強對自動編碼器複雜性的理解,併為實際應用打下堅實基礎。
多場景應用
自動編碼器的靈活性在許多應用場景中得到了體現,從影象重構到異常檢測等。瞭解這些應用可以啟發更廣泛和深入的使用。
實戰演示
本文的實戰演示部分涵蓋了從環境準備、模型構建、訓練,到生成環境部署和多平臺推理的全過程。這些細節反映了模型從實驗到生產的整個生命週期,並涉及許多實際問題和解決方案。
多平臺推理
通過ONNX等開放標準,我們展示瞭如何將自動編碼器部署到不同平臺上。這一部分反映了現代AI模型部署的複雜性和多樣性,並提供了一些實用的工具和技巧。
關注TechLead,分享AI與雲服務技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。