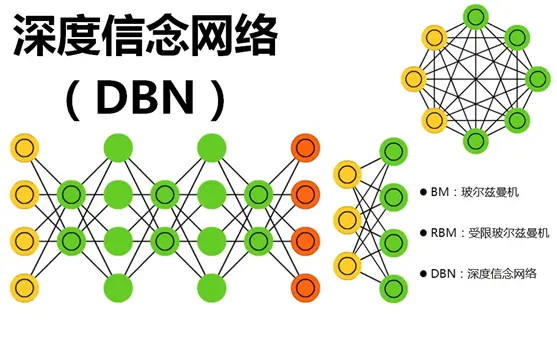
一文搞懂深度信念網路!DBN概念介紹與Pytorch實戰
本文深入探討了深度信念網路DBN的核心概念、結構、Pytorch實戰,分析其在深度學習網路中的定位、潛力與應用場景。
關注TechLead,分享AI與雲服務技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
一、概述
1.1 深度信念網路的概述
深度信念網路(Deep Belief Networks, DBNs)是一種深度學習模型,代表了一種重要的技術創新,具有幾個關鍵特點和突出能力。
首先,DBNs是由多層受限玻爾茲曼機(Restricted Boltzmann Machines, RBMs)堆疊而成的生成模型。這種多層結構使得DBNs能夠捕獲資料中的高層次抽象特徵,對於複雜的資料結構具有強大的表徵能力。
其次,DBNs採用無監督預訓練的方式逐層訓練模型。與傳統的深度學習模型不同,這種逐層學習策略使DBNs在訓練時更為穩定和高效,尤其適合處理高維資料和未標記資料。
此外,DBNs具有出色的生成學習能力。它不僅可以學習和理解資料的分佈,還能夠基於學習到的模型生成新的資料樣本。這種生成能力在影象合成、文字生成等任務上有著廣泛的應用前景。
最後,DBNs的訓練和優化涉及到一些先進的演演算法和技術,如對比散度(Contrastive Divergence, CD)演演算法等。這些演演算法的應用和改進,使DBNs在許多實際問題上表現卓越,但同時也帶來了一些挑戰,如引數調優的複雜性等。
總的來說,深度信念網路通過其獨特的結構和生成學習的能力,展示了深度學習的新方向和潛力。它的關鍵技術創新和突出能力使其在諸多領域成為一種有力的工具,為人工智慧的發展和應用提供了新的機遇。
1.2 深度信念網路與其他深度學習模型的比較
深度信念網路(DBNs)作為深度學習領域的一種重要模型,與其他深度學習模型有著許多共同點,但也有著鮮明的特色。以下我們從不同的角度來比較DBNs與其他主要深度學習模型。
結構層次
- DBNs: 由多層受限玻爾茲曼機堆疊而成,每一層都對上一層的表示進行進一步抽象。採用無監督預訓練,逐層構建複雜模型。
- 折積神經網路(CNNs): 採用折積層、池化層等特殊結構,適合空間資料如影象。
- 迴圈神經網路(RNNs): 通過時間遞迴結構,適合處理序列資料如文字。
學習方式
- DBNs: 具有生成學習能力,可以生成新的資料樣本,適用於無監督學習和半監督學習場景。
- CNNs、RNNs: 主要進行判別學習,通過監督學習進行分類或迴歸等任務。
訓練和優化
- DBNs: 使用對比散度等複雜優化演演算法,引數調優相對困難。
- CNNs、RNNs: 可以使用梯度下降等常見優化方法,訓練過程相對更為直觀和容易。
應用領域
- DBNs: 由於其生成學習和多層結構特性,特別適合處理高維資料、缺失資料等複雜場景。
- CNNs: 在影象處理領域有著廣泛的應用。
- RNNs: 在自然語言處理和時間序列分析等領域有優勢。
1.3 應用領域
深度信念網路(DBNs)作為一種強大的深度學習模型,已廣泛應用於多個領域。其能夠捕捉複雜資料結構的特性,讓DBNs在以下應用領域中表現出卓越的能力。
影象識別與處理
DBNs可以用於影象分類、物體檢測和臉部辨識等任務。其深層結構可以捕獲影象中的複雜特徵,比如紋理、形狀和顏色等。在醫學影象分析方面,DBNs也展現出強大的潛力,如用於疾病檢測和組織分割等。
自然語言處理
通過與其他神經網路結構的組合,DBNs可以處理文字分類、情感分析和機器翻譯等任務。其能夠理解和生成語言的能力為處理複雜文字提供了強有力的工具。
推薦系統
DBNs的生成模型特性使其在推薦系統中也有廣泛應用。通過學習使用者和物品之間的潛在關係,DBNs能夠生成個性化的推薦列表,從而提高推薦的準確性和使用者滿意度。
語音識別
在語音識別領域,DBNs可以用於提取聲音訊號的特徵,並結合其他模型如隱馬爾可夫模型(HMM)進行語音識別。其在複雜聲音環境下的魯棒性使其在這一領域有著顯著優勢。
無監督學習與異常檢測
DBNs的無監督學習能力也使其在無監督聚類和異常檢測等任務上表現出色。特別是在資料標籤缺失或稀缺的場景下,DBNs可以提取有用的資訊,用於發現資料中的潛在結構或異常模式。
藥物發現與生物資訊學
在藥物發現和生物資訊學方面,DBNs可以用於預測藥物的生物活性、發現新的藥物靶點等。其對高維資料的處理能力為解析複雜生物系統提供了有效手段。
二、結構
2.1 受限玻爾茲曼機(RBM)
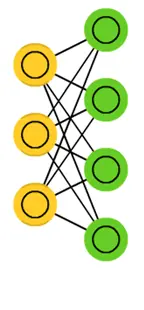
受限玻爾茲曼機(Restricted Boltzmann Machine, RBM)是深度信念網路的基本構建塊。以下將詳細介紹RBM的關鍵組成、工作原理和學習演演算法。
結構與組成
RBM是一種生成隨機神經網路,由兩層完全連線的神經元組成:可見層和隱藏層。
- 可見層(Visible Layer): 包括對資料直接進行編碼的神經元。
- 隱藏層(Hidden Layer): 包括從可見層學習特徵的神經元。
RBM中的連線是無向的,即連線是對稱的。同一層中的神經元之間沒有連線。
工作原理
RBM的工作原理基於能量函數,該函數定義了網路狀態的能量。
- 能量函數: RBM通過一個稱為能量函數的數學公式來表示不同狀態之間的關係。
- 聯合概率分佈: RBM的能量與其狀態的聯合概率分佈有關,其中較低的能量對應較高的概率。
學習演演算法
RBM的學習演演算法包括以下主要步驟:
- 前向傳播: 從可見層到隱藏層的啟用。
- 後向傳播: 從隱藏層到可見層的重構。
- 梯度計算: 通過對比散度(Contrastive Divergence, CD)計算權重更新的梯度。
- 權重更新: 通過學習率更新權重。
應用
RBM被廣泛用於特徵學習、降維、分類等任務。作為深度信念網路的基本組成部分,RBM的應用也直接擴充套件到更復雜的資料建模任務中。
2.2 DBN的結構和組成
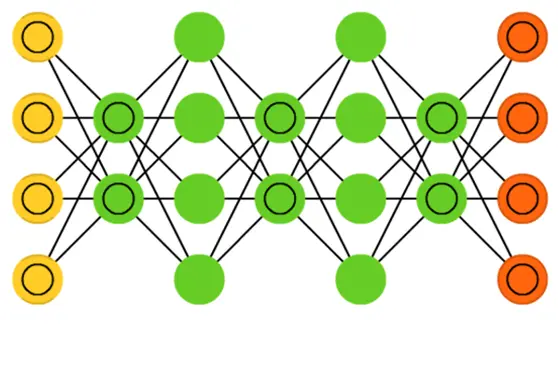
深度信念網路(Deep Belief Network,DBN)是一種深度學習模型,可以捕捉資料中的複雜層次結構。下面詳細介紹DBN的結構和組成部分。
層次結構
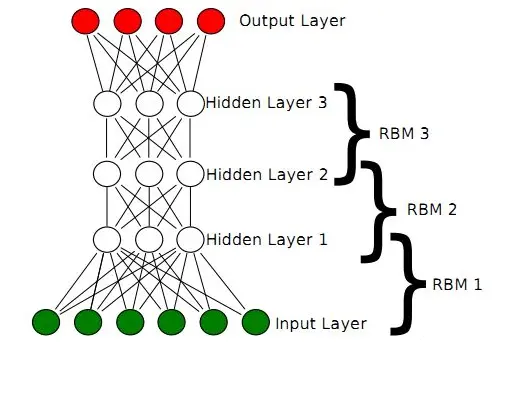
DBN的結構由多個層組成,通常包括多個受限玻爾茲曼機(RBM)層和一個頂層。每一層由一組神經元組成,通過雙向連線與相鄰層的神經元相連。
- 輸入層: 對應資料的可見表示。
- 隱藏層: 包括多個RBM層,每一層對應資料的更高層次抽象。
- 頂層: 通常由一個RBM或其他模型組成,負責最終特徵的提取和表示。
網路連線
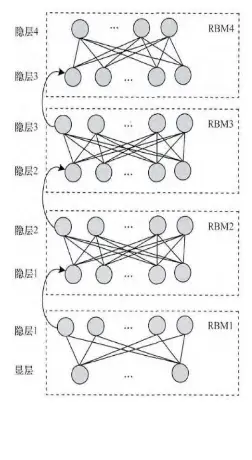
DBN的連線結構遵循以下規則:
- 同一層的神經元之間沒有連線。
- 每一層的神經元與上下層的所有神經元都有連線。
- 連線是無向的(對於前幾層的RBM)或有向的(對於頂層)。
訓練過程
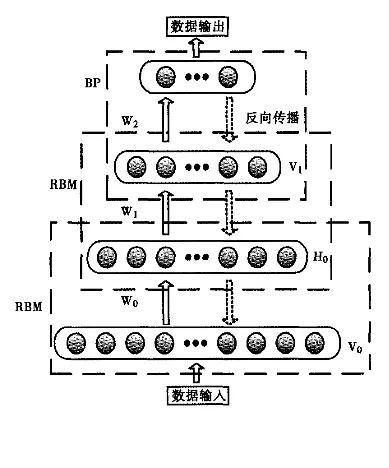
DBN的訓練過程分為兩個主要階段:
- 預訓練階段: 每個RBM層按照從底到頂的順序進行貪婪逐層訓練。
- 微調階段: 使用監督學習方法(如反向傳播)對整個網路進行微調。
應用領域
DBN的結構和訓練策略使其適用於許多複雜的建模任務,包括:
- 特徵學習: 學習輸入資料的多層次抽象表示。
- 分類: 基於學習的特徵執行分類任務。
- 生成建模: 生成與訓練資料相似的新樣本。
2.3 訓練和學習演演算法
深度信念網路的訓練是一個複雜且重要的過程。這一節將詳細介紹DBN的訓練和學習演演算法。
預訓練
預訓練是DBN訓練的第一階段,主要目的是初始化網路權重。
- 逐層訓練: DBN的每個RBM層單獨訓練,自底向上逐層進行。
- 無監督學習: 使用無監督學習演演算法(如對比散度)訓練RBM。
- 生成權重: 每一層訓練後,其權重用於下一層的輸入。
微調
微調是DBN訓練的第二階段,調整預訓練後的權重以改善效能。
- 反向傳播演演算法: 通常使用反向傳播演演算法進行監督學習。
- 誤差最小化: 微調過程旨在通過調整權重最小化訓練資料的預測誤差。
- 早停法: 通過在驗證集上監控效能來防止過擬合。
優化方法
深度信念網路的訓練通常涉及許多優化技術。
- 學習率調整: 動態調整學習率可以加速訓練並提高效能。
- 正則化: 如L1和L2正則化有助於防止過擬合。
- 動量優化: 動量可以幫助優化演演算法更快地收斂到最優解。
評估和驗證
訓練過程還包括對模型的評估和驗證。
- 交叉驗證: 使用交叉驗證來評估模型的泛化能力。
- 效能指標: 使用如準確率、召回率等指標來評估模型效能。
三、實戰
3.1 DBN模型的構建
深度信念網路是一種由多個受限玻爾茲曼機(RBM)層堆疊而成的生成模型。下面是構建DBN模型的具體步驟。
定義RBM層
RBM是DBN的基本構建塊。它包括可見層和隱藏層,並通過權重矩陣連線。
class RBM(nn.Module):
def __init__(self, visible_units, hidden_units):
super(RBM, self).__init__()
self.W = nn.Parameter(torch.randn(hidden_units, visible_units) * 0.1)
self.h_bias = nn.Parameter(torch.zeros(hidden_units))
self.v_bias = nn.Parameter(torch.zeros(visible_units))
def forward(self, v):
# 定義前向傳播
# 省略其他程式碼...
- 權重初始化: 權重矩陣的初始化非常重要,通常使用較小的隨機值。
- 偏置項: 可見層和隱藏層都有偏置項,通常初始化為零。
構建DBN模型
DBN模型由多個RBM層組成,每一層的隱藏單元與下一層的可見單元相連。
class DBN(nn.Module):
def __init__(self, layers):
super(DBN, self).__init__()
self.rbms = nn.ModuleList([RBM(layers[i], layers[i + 1]) for i in range(len(layers) - 1)])
def forward(self, v):
h = v
for rbm in self.rbms:
h = rbm(h)
return h
- 逐層連線: 每個RBM層的輸出成為下一個RBM層的輸入。
- 模組列表: 使用
nn.ModuleList來儲存RBM層,確保它們都被正確註冊。
定義DBN的超引數
DBN的構建也涉及到選擇合適的超引數,例如每個RBM層的可見和隱藏單元的數量。
# 定義DBN的層大小
layers = [784, 500, 200, 100]
# 建立DBN模型
dbn = DBN(layers)
3.2 預訓練
預訓練是DBN訓練過程中的一個關鍵階段,通過逐層訓練RBM來完成。以下是具體的預訓練步驟。
RBM的逐層訓練
DBN的每個RBM層都分別進行訓練。訓練一個RBM層的目的是找到可以重構輸入資料的權重。
# 預訓練每個RBM層
for index, rbm in enumerate(dbn.rbms):
for epoch in range(epochs):
# 使用對比散度訓練RBM
# 省略具體程式碼...
print(f"RBM {index} trained.")
- 逐層訓練: 每個RBM層都獨立訓練,並使用上一層的輸出作為下一層的輸入。
對比散度(CD)演演算法
對比散度是訓練RBM的常用方法。它通過對可見層和隱藏層的樣本進行取樣來更新權重。
# 對比散度訓練
def contrastive_divergence(rbm, data, learning_rate):
v0 = data
h0_prob, h0_sample = rbm.sample_h(v0)
v1_prob, _ = rbm.sample_v(h0_sample)
h1_prob, _ = rbm.sample_h(v1_prob)
positive_grad = torch.matmul(h0_prob.T, v0)
negative_grad = torch.matmul(h1_prob.T, v1_prob)
rbm.W += learning_rate * (positive_grad - negative_grad) / data.size(0)
rbm.v_bias += learning_rate * torch.mean(v0 - v1_prob, dim=0)
rbm.h_bias += learning_rate * torch.mean(h0_prob - h1_prob, dim=0)
- 正相位和負相位: 正相位與資料分佈有關,而負相位與模型分佈有關。
- 梯度更新: 權重更新基於正相位和負相位之間的差異。
3.3 微調
微調階段是DBN訓練流程中的最後部分,其目的是對網路進行精細調整以優化特定任務的效能。
監督訓練
在微調階段,DBN與一個或多個額外的監督層(例如全連線層)結合,以便進行有監督的訓練。
# 在DBN上新增監督層
class SupervisedDBN(nn.Module):
def __init__(self, dbn, output_size):
super(SupervisedDBN, self).__init__()
self.dbn = dbn
self.classifier = nn.Linear(dbn.rbms[-1].hidden_units, output_size)
def forward(self, x):
h = self.dbn(x)
return self.classifier(h)
- 額外的監督層: 可以新增全連線層進行分類或迴歸任務。
微調訓練
微調訓練使用標準的反向傳播演演算法,並可以採用任何常見的優化器和損失函數。
# 定義優化器和損失函數
optimizer = torch.optim.Adam(supervised_dbn.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
# 微調訓練
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = supervised_dbn(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
- 優化器: 如Adam或SGD等。
- 損失函數: 取決於任務,例如交叉熵損失用於分類任務。
模型驗證和測試
微調階段還涉及在驗證和測試資料集上評估模型的效能。
# 模型驗證和測試
def evaluate(model, data_loader):
correct = 0
with torch.no_grad():
for data, target in data_loader:
output = model(data)
pred = output.argmax(dim=1)
correct += (pred == target).sum().item()
accuracy = correct / len(data_loader.dataset)
return accuracy
3.4 應用
分類或迴歸任務
例如,DBN可用於影象分類、股價預測等。
特徵學習
DBN可用於無監督的特徵學習,以捕捉輸入資料的有用表示。
轉移學習
訓練有素的DBN可以用作預訓練的特徵提取器,以便在相關任務上進行遷移學習。
線上應用
DBN可以整合到線上系統中,實時進行預測。
# 實時預測範例
def real_time_prediction(model, new_data):
with torch.no_grad():
prediction = model(new_data)
return prediction
四、總結
深度信念網路(DBN)作為一種強大的生成模型,近年來在許多機器學習和深度學習任務中取得了成功。在這篇文章中,我們詳細探討了DBN的基礎結構、訓練過程以及評估和應用。以下是一些關鍵要點的總結:
-
結構和組成: DBN是由多個受限玻爾茲曼機(RBM)堆疊而成的,每個RBM層負責捕獲資料的特定特徵。
-
訓練和學習演演算法: 訓練過程包括預訓練和微調兩個階段。預訓練負責初始化權重,而微調則使用監督學習來優化模型的特定任務效能。
-
應用: 分類、迴歸、特徵學習、轉移學習等。
-
工具和實現: 使用PyTorch等深度學習框架,可以方便地實現DBN。文章提供了清晰的程式碼範例,幫助讀者理解並實現這一複雜的模型。
關注TechLead,分享AI與雲服務技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。