Kafka 在分散式系統中的 7 大應用場景
Kafka 介紹
Kafka 是一個開源的分散式流式平臺,它可以處理大量的實時資料,並提供高吞吐量,低延遲,高可靠性和高可延伸性。Kafka 的核心元件包括生產者(Producer),消費者(Consumer),主題(Topic),分割區(Partition),副本(Replica),紀錄檔(Log),偏移量(Offset)和代理(Broker)。Kafka 的主要特點有:
- 資料磁碟持久化:Kafka 將訊息直接寫入到磁碟,而不依賴於記憶體快取,從而提高了資料的永續性和容錯性。
- 零拷貝:Kafka 利用作業系統的零拷貝特性,減少了資料在核心空間和使用者空間之間的複製,降低了 CPU 和記憶體的開銷。
- 資料批次傳送:Kafka 支援生產者和消費者批次傳送和接收資料,減少了網路請求的次數和開銷。
- 資料壓縮:Kafka 支援多種壓縮演演算法,如 gzip,snappy,lz4 等,可以有效地減少資料的大小和傳輸時間。
- 主題劃分為多個分割區:Kafka 將一個主題劃分為多個分割區,每個分割區是一個有序的訊息佇列,分割區之間可以並行地讀寫資料,提高了系統的並行能力。
- 分割區副本機制:Kafka 為每個分割區設定多個副本,分佈在不同的代理節點上,保證了資料的冗餘和一致性。其中一個副本被選為領導者(Leader),負責處理該分割區的讀寫請求,其他副本為追隨者(Follower),負責從領導者同步資料,並在領導者失效時進行故障轉移。
Kafka 最初是為分散式系統中海量紀錄檔處理而設計的。它可以通過持久化功能將訊息儲存到磁碟直到過期,並讓消費者按照自己的節奏提取訊息。與它的前輩不同(RabbitMQ、ActiveMQ),Kafka 不僅僅是一個訊息佇列,它還是一個開源的分散式流處理平臺。
Kafka 的應用場景
Kafka 作為一款熱門的訊息佇列中介軟體,具備高效可靠的訊息非同步傳遞機制,主要用於不同系統間的資料交流和傳遞。下面給大家介紹一下 Kafka 在分散式系統中的 7 個常用應用場景。
- 紀錄檔處理與分析
- 推薦資料流
- 系統監控與報警
- CDC(資料變更捕獲)
- 系統遷移
- 事件溯源
- 訊息佇列
1. 紀錄檔處理與分析
紀錄檔收集是 Kafka 最初的設計目標之一,也是最常見的應用場景之一。可以用 Kafka 收集各種服務的紀錄檔,如 web 伺服器、伺服器紀錄檔、資料庫伺服器等,通過 Kafka 以統一介面服務的方式開放給各種消費者,例如 Flink、Hadoop、Hbase、ElasticSearch 等。這樣可以實現分散式系統中海量紀錄檔資料的處理與分析。
下圖是一張典型的 ELK(Elastic-Logstash-Kibana)分散式紀錄檔採集架構。
- 購物車服務將紀錄檔資料寫在 log 檔案中。
- Logstash 讀取紀錄檔檔案傳送到 Kafka 的紀錄檔主題中。
- ElasticSearch 訂閱紀錄檔主題,建立紀錄檔索引,儲存紀錄檔資料。
- 開發者通過 Kibana 連線到 ElasticSeach 即可查詢其紀錄檔索引內容。

2. 推薦資料流
流式處理是 Kafka 在巨量資料領域的重要應用場景之一。可以用 Kafka 作為流式處理平臺的資料來源或資料輸出,與 Spark Streaming、Storm、Flink 等框架進行整合,實現對實時資料的處理和分析,如過濾、轉換、聚合、視窗、連線等。
淘寶、京東這樣的線上商城網站會通過使用者過去的一些行為(點選、瀏覽、購買等)來和相似的使用者計算使用者相似度,以此來給使用者推薦可能感興趣的商品。
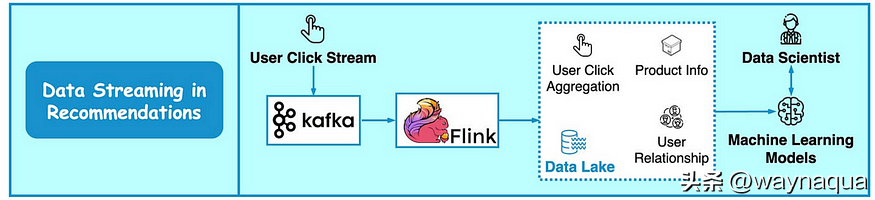
下圖展示了常見推薦系統的工作流程。
- 將使用者的點選流資料傳送到 Kafka 中。
- Flink 讀取 Kafka 中的流資料實時寫入資料湖中其進行聚合處理。
- 機器學習使用來自資料湖的聚合資料進行訓練,演演算法工程師也會對推薦模型進行調整。
這樣推薦系統就能夠持續改進對每個使用者的推薦相關性。
3. 系統監控與報警
Kafka 常用於傳輸監控指標資料。例如,大一點的分散式系統中有數百臺伺服器的 CPU 利用率、記憶體使用情況、磁碟使用率、流量使用等指標可以釋出到 Kafka。然後,監控應用程式可以使用這些指標來進行實時視覺化、警報和異常檢測。
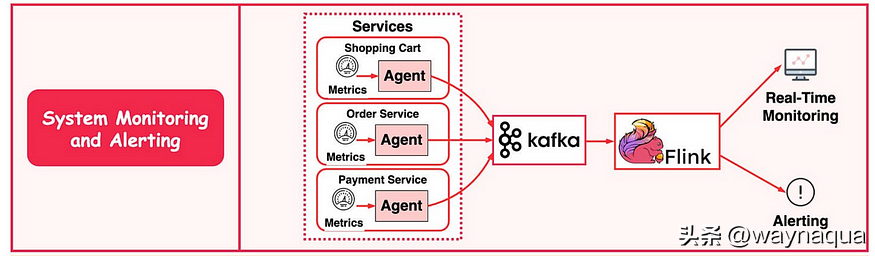
下圖展示了常見監控報警系統的工作流程。
- 採集器(agent)讀取購物車指標傳送到 Kafka 中。
- Flink 讀取 Kafka 中的指標資料進行聚合處理。
- 實時監控系統和報警系統讀取聚合資料作展示以及報警處理。
4. CDC(資料變更捕獲)
CDC(資料變更捕獲)用來將資料庫中的發生的更改以流的形式傳輸到其他系統以進行復制或者快取以及索引更新等。
Kafka 中有一個聯結器元件可以支援 CDC 功能,它需要和具體的資料來源結合起來使用。資料來源可以分成兩種:源資料來源( data source ,也叫作「源系統」)和目標資料來源( Data Sink ,也叫作「目標系統」)。Kafka 聯結器和源系統一起使用時,它會將源系統的資料導人到 Kafka 叢集。Kafka 聯結器和目標系統一起使用時,它會將 Kafka 叢集的資料導人到目標系統。
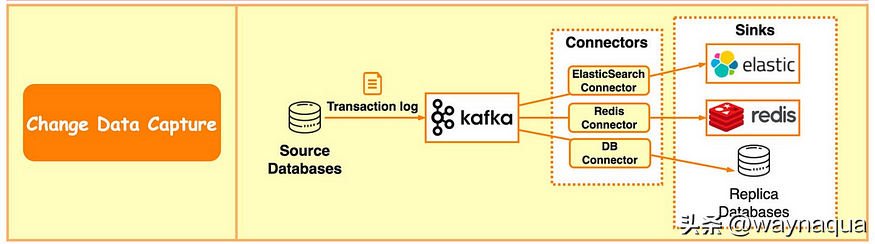
下圖展示了常見 CDC 系統的工作流程。
- 源資料來源將事務紀錄檔傳送到 Kafka。
- Kafka 的聯結器將事務紀錄檔寫入目標資料來源。
- 目標資料來源包含 ElasticSearch、Redis、備份資料來源等。
5. 系統遷移
Kafka 可以用來作為老系統升級到新系統過程中的訊息傳遞中介軟體(Kafka),以此來降低遷移風險。
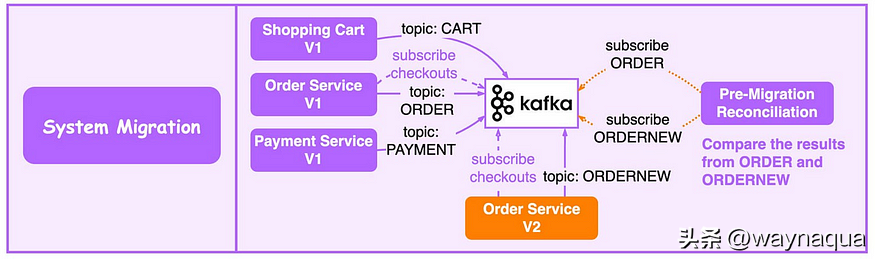
例如,在一個老系統中,有購物車 V1、訂單 V1、支付 V1 三個服務,現在我們需要將訂單 V1 服務升級到訂單 V2 服務。
下圖展示了老系統遷移到新系統的工作流程。
- 先將老的訂單 V1 服務進行改造接入 Kafka,並將輸出結果寫入 ORDER 主題。
- 新的訂單 V2 服務接入 Kafka 並將輸出結果寫入 ORDERNEW 主題。
- 對賬服務訂閱 ORDER 和 ORDERNEW 兩個主題並進行比較。如果它們的輸出結構相同,則新服務通過測試。
6. 事件溯源
事件溯源是 Kafka 在微服務架構中的重要應用場景之一。可以用 Kafka 記錄微服務間的事件,如訂單建立、支付完成、發貨通知等。這些事件可以被其他微服務訂閱和消費,實現業務邏輯的協調和同步。
簡單來說事件溯源就是將這些事件通過持久化儲存在 Kafka 內部。如果發生任何故障、回滾或需要重放訊息,我們都可以隨時重新應用 Kafka 中的事件。
7. 訊息佇列
Kafka 最常見的應用場景就是作為訊息佇列。 Kafka 提供了一個可靠且可延伸的訊息佇列,可以處理大量資料。
Kafka 可以實現不同系統間的解耦和非同步通訊,如訂單系統、支付系統、庫存系統等。在這個基礎上 Kafka 還可以快取訊息,提高系統的可靠性和可用性,並且可以支援多種消費模式,如對等或釋出訂閱。
參考資料
- https://levelup.gitconnected.com/top-8-kafka-use-cases-distributed-systems-d47fc733c7c1
- https://blog.bytebytego.com/p/ep76-netflixs-tech-stack
- Apache Kafka Benefits & Use Cases。https://www.confluent.io/learn/apache-kafka-benefits-and-use-cases/
總結
自此本文介紹了 Kafka 在分散式系統中的 7 大應用場景,感謝大家閱讀。
關注公眾號【waynblog】每週分享技術乾貨、開源專案、實戰經驗、國外優質文章翻譯等,您的關注將是我的更新動力!