解密長短時記憶網路(LSTM):從理論到PyTorch實戰演示
本文深入探討了長短時記憶網路(LSTM)的核心概念、結構與數學原理,對LSTM與GRU的差異進行了對比,並通過邏輯分析闡述了LSTM的工作原理。文章還詳細演示瞭如何使用PyTorch構建和訓練LSTM模型,並突出了LSTM在實際應用中的優勢。
關注TechLead,分享AI與雲服務技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。

1. LSTM的背景
人工神經網路的進化
人工神經網路(ANN)的設計靈感來源於人類大腦中神經元的工作方式。自從第一個感知器模型(Perceptron)被提出以來,人工神經網路已經經歷了多次的演變和優化。
- 前饋神經網路(Feedforward Neural Networks): 這是一種基本的神經網路,資訊只在一個方向上流動,沒有反饋或迴圈。
- 折積神經網路(Convolutional Neural Networks, CNN): 專為處理具有類似網格結構的資料(如影象)而設計。
- 迴圈神經網路(Recurrent Neural Networks, RNN): 為了處理序列資料(如時間序列或自然語言)而引入,但在處理長序列時存在一些問題。
迴圈神經網路(RNN)的侷限性
迴圈神經網路(RNN)是一種能夠捕捉序列資料中時間依賴性的網路結構。但是,傳統的RNN存在一些嚴重的問題:
- 梯度消失問題(Vanishing Gradient Problem): 當處理長序列時,RNN在反向傳播時梯度可能會接近零,導致訓練緩慢甚至無法學習。
- 梯度爆炸問題(Exploding Gradient Problem): 與梯度消失問題相反,梯度可能會變得非常大,導致訓練不穩定。
- 長依賴性問題: RNN難以捕捉序列中相隔較遠的依賴關係。
由於這些問題,傳統的RNN在許多應用中表現不佳,尤其是在處理長序列資料時。
LSTM的提出背景
長短時記憶網路(LSTM)是一種特殊型別的RNN,由Hochreiter和Schmidhuber於1997年提出,目的是解決傳統RNN的問題。
- 解決梯度消失問題: 通過引入「記憶單元」,LSTM能夠在長序列中保持資訊的流動。
- 捕捉長依賴性: LSTM結構允許網路捕捉和理解長序列中的複雜依賴關係。
- 廣泛應用: 由於其強大的效能和靈活性,LSTM已經被廣泛應用於許多序列學習任務,如語音識別、機器翻譯和時間序列分析等。
LSTM的提出不僅解決了RNN的核心問題,還開啟了許多先前無法解決的複雜序列學習任務的新篇章。
2. LSTM的基礎理論
2.1 LSTM的數學原理

長短時記憶網路(LSTM)是一種特殊的迴圈神經網路,它通過引入一種稱為「記憶單元」的結構來克服傳統RNN的缺點。下面是LSTM的主要元件和它們的功能描述。
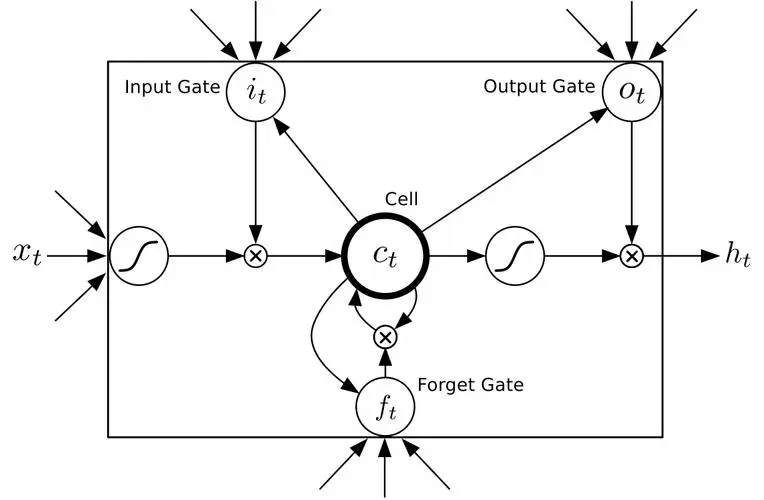
遺忘門(Forget Gate)
遺忘門的作用是決定哪些資訊從記憶單元中遺忘。它使用sigmoid啟用函數,可以輸出在0到1之間的值,表示保留資訊的比例。
[
f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
]
其中,(f_t)是遺忘門的輸出,(\sigma)是sigmoid啟用函數,(W_f)和(b_f)是權重和偏置,(h_{t-1})是上一個時間步的隱藏狀態,(x_t)是當前輸入。
輸入門(Input Gate)
輸入門決定了哪些新資訊將被儲存在記憶單元中。它包括兩部分:sigmoid啟用函數用來決定更新的部分,和tanh啟用函數來生成候選值。
[
i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
]
[
\tilde{C}t = \tanh(W_C \cdot [h, x_t] + b_C)
]
記憶單元(Cell State)
記憶單元是LSTM的核心,它能夠在時間序列中長時間保留資訊。通過遺忘門和輸入門的相互作用,記憶單元能夠學習如何選擇性地記住或忘記資訊。
[
C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t
]
輸出門(Output Gate)
輸出門決定了下一個隱藏狀態(也即下一個時間步的輸出)。首先,輸出門使用sigmoid啟用函數來決定記憶單元的哪些部分將輸出,然後這個值與記憶單元的tanh啟用的值相乘得到最終輸出。
[
o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)
]
[
h_t = o_t \cdot \tanh(C_t)
]
LSTM通過這些精心設計的門和記憶單元實現了對資訊的精確控制,使其能夠捕捉序列中的複雜依賴關係和長期依賴,從而大大超越了傳統RNN的效能。
2.2 LSTM的結構邏輯
長短時記憶網路(LSTM)是一種特殊的迴圈神經網路(RNN),專門設計用於解決長期依賴問題。這些網路在時間序列資料上的效能優越,讓我們深入瞭解其邏輯結構和運作方式。
遺忘門:決定丟棄的資訊
遺忘門決定了哪些資訊從單元狀態中丟棄。它考慮了當前輸入和前一隱藏狀態,並通過sigmoid函數輸出0到1之間的值。
輸入門:選擇性更新記憶單元
輸入門決定了哪些新資訊將儲存在單元狀態中。它由兩部分組成:
- 選擇性更新:使用sigmoid函數確定要更新的部分。
- 候選層:使用tanh函數產生新的候選值,可能新增到狀態中。
更新單元狀態
通過結合遺忘門的輸出和輸入門的輸出,可以計算新的單元狀態。舊狀態的某些部分會被遺忘,新的候選值會被新增。
輸出門:決定輸出的隱藏狀態
輸出門決定了從單元狀態中讀取多少資訊來輸出。這個輸出將用於下一個時間步的LSTM單元,並可以用於網路的預測。
門的相互作用
- 遺忘門: 負責控制哪些資訊從單元狀態中遺忘。
- 輸入門: 確定哪些新資訊被儲存。
- 輸出門: 控制從單元狀態到隱藏狀態的哪些資訊流動。
這些門的互動允許LSTM以選擇性的方式在不同時間步長的間隔中保持或丟棄資訊。
邏輯結構的實際應用
LSTM的邏輯結構使其在許多實際應用中非常有用,尤其是在需要捕捉時間序列中長期依賴關係的任務中。例如,在自然語言處理、語音識別和時間序列預測等領域,LSTM已經被證明是一種強大的模型。
總結
LSTM的邏輯結構通過其獨特的門控機制為處理具有複雜依賴關係的序列資料提供了強大的手段。其對資訊流的精細控制和長期記憶的能力使其成為許多序列建模任務的理想選擇。瞭解LSTM的這些邏輯概念有助於更好地理解其工作原理,並有效地將其應用於實際問題。
2.3 LSTM與GRU的對比
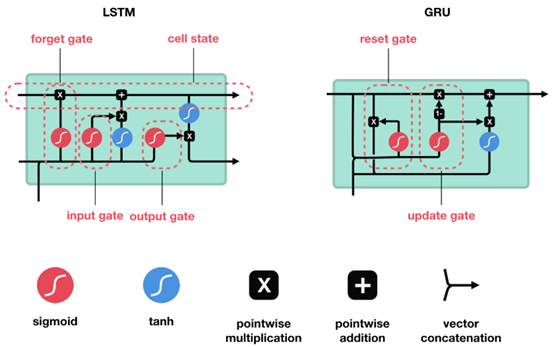
長短時記憶網路(LSTM)和門控迴圈單元(GRU)都是迴圈神經網路(RNN)的變體,被廣泛用於序列建模任務。雖然它們有許多相似之處,但也有一些關鍵差異。
1. 結構
LSTM
LSTM包括三個門:輸入門、遺忘門和輸出門,以及一個記憶單元。這些元件共同控制資訊在時間序列中的流動。
GRU
GRU有兩個門:更新門和重置門。它合併了LSTM的記憶單元和隱藏狀態,並簡化了結構。
2. 數學表達
LSTM
LSTM的數學表達包括以下方程:
[
\begin{align}
f_t & = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \
i_t & = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \
\tilde{C}t & = \tanh(W_C \cdot [h, x_t] + b_C) \
C_t & = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}t \
o_t & = \sigma(W_o \cdot [h, x_t] + b_o) \
h_t & = o_t \cdot \tanh(C_t)
\end{align}
]
GRU
GRU的數學表達如下:
[
\begin{align}
z_t & = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z) \
r_t & = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r) \
n_t & = \tanh(W_n \cdot [r_t \cdot h_{t-1}, x_t] + b_n) \
h_t & = (1 - z_t) \cdot n_t + z_t \cdot h_{t-1}
\end{align}
]
3. 效能和應用
- 複雜性: LSTM具有更復雜的結構和更多的引數,因此通常需要更多的計算資源。GRU則更簡單和高效。
- 記憶能力: LSTM的額外「記憶單元」可以提供更精細的資訊控制,可能更適合處理更復雜的序列依賴性。
- 訓練速度和效果: 由於GRU的結構較簡單,它可能在某些任務上訓練得更快。但LSTM可能在具有複雜長期依賴的任務上表現更好。
小結
LSTM和GRU雖然都是有效的序列模型,但它們在結構、複雜性和應用效能方面有所不同。選擇哪一個通常取決於具體任務和資料。LSTM提供了更精細的控制,而GRU可能更高效和快速。實際應用中可能需要針對具體問題進行實驗以確定最佳選擇。
3. LSTM在實際應用中的優勢

長短時記憶網路(LSTM)是迴圈神經網路(RNN)的一種擴充套件,特別適用於序列建模和時間序列分析。LSTM的設計獨具匠心,提供了一系列的優勢來解決實際問題。
處理長期依賴問題
LSTM的關鍵優勢之一是能夠捕捉輸入資料中的長期依賴關係。這使其在理解和建模具有複雜時間動態的問題上具有強大的能力。
遺忘門機制
通過遺忘門機制,LSTM能夠學習丟棄與當前任務無關的資訊,這對於分離重要特徵和減少噪音干擾非常有用。
梯度消失問題的緩解
傳統的RNN易受梯度消失問題的影響,LSTM通過引入門機制和細胞狀態來緩解這個問題。這提高了網路的訓練穩定性和效率。
廣泛的應用領域
LSTM已被成功應用於許多不同的任務和領域,包括:
- 自然語言處理: 如機器翻譯,情感分析等。
- 語音識別: 用於理解和轉錄人類語音。
- 股票市場預測: 通過捕捉市場的時間趨勢來預測股票價格。
- 醫療診斷: 分析患者的歷史醫療記錄來進行早期預警和診斷。
靈活的架構選項
LSTM可以與其他深度學習元件(如折積神經網路或注意力機制)相結合,以建立複雜且強大的模型。
成熟的開源實現
現有許多深度學習框架,如TensorFlow和PyTorch,都提供了LSTM的高質量實現,這為研究人員和工程師提供了方便。
小結
LSTM網路在許多方面表現出色,特別是在處理具有複雜依賴關係的序列資料方面。其能夠捕捉長期依賴,緩解梯度消失問題,和廣泛的應用潛力使其成為許多實際問題的理想解決方案。隨著深度學習技術的不斷進步,LSTM可能會繼續在新的應用場景和挑戰中展示其強大的實用價值。
4. LSTM的實戰演示
4.1 使用PyTorch構建LSTM模型

LSTM在PyTorch中的實現相對直觀和簡單。下面,我們將演示如何使用PyTorch構建一個LSTM模型,以便於對時間序列資料進行預測。
定義LSTM模型
我們首先定義一個LSTM類,該類使用PyTorch的nn.Module作為基礎類別。
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x) # LSTM層
out = self.fc(out[:, -1, :]) # 全連線層
return out
input_size: 輸入特徵的大小。hidden_size: 隱藏狀態的大小。num_layers: LSTM層數。output_size: 輸出的大小。
訓練模型
接下來,我們定義訓練迴圈來訓練模型。
import torch.optim as optim
# 定義超引數
input_size = 10
hidden_size = 64
num_layers = 1
output_size = 1
learning_rate = 0.001
epochs = 100
# 建立模型範例
model = LSTMModel(input_size, hidden_size, num_layers, output_size)
# 定義損失函數和優化器
loss_function = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 訓練迴圈
for epoch in range(epochs):
outputs = model(inputs)
optimizer.zero_grad()
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
這裡,我們使用均方誤差損失,並通過Adam優化器來訓練模型。
評估和預測
訓練完成後,我們可以使用模型進行預測,並評估其在測試資料上的效能。
# 在測試資料上進行評估
model.eval()
with torch.no_grad():
predictions = model(test_inputs)
# ... 進一步評估預測 ...
5. LSTM總結
長短時記憶網路(LSTM)自從被提出以來,已經成為深度學習和人工智慧領域的一個重要組成部分。以下是關於LSTM的一些關鍵要點的總結:
解決長期依賴問題
LSTM通過其獨特的結構和門控機制,成功解決了傳統RNNs在處理長期依賴時遇到的挑戰。這使得LSTM在許多涉及序列資料的任務中都表現出色。
廣泛的應用領域
從自然語言處理到金融預測,從音樂生成到醫療分析,LSTM的應用領域廣泛且多樣。
靈活與強大
LSTM不僅可以單獨使用,還可以與其他神經網路架構(如CNN、Transformer等)結合,創造更強大、更靈活的模型。
開源支援
流行的深度學習框架如TensorFlow和PyTorch都提供了易於使用的LSTM實現,促進了研究和開發的便利性。
持戰與展望
雖然LSTM非常強大,但也有其持戰和侷限性,例如計算開銷和超引數調整。新的研究和技術進展可能會解決這些持戰或提供替代方案,例如GRU等。
總結反思
LSTM的出現推動了序列建模和時間序列分析的前沿發展,使我們能夠解決以前難以處理的問題。作為深度學習工具箱中的一個關鍵元件,LSTM為學者、研究人員和工程師提供了強大的工具來解讀和預測世界的複雜動態。
關注TechLead,分享AI與雲服務技術的全維度知識。作者擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人。
如有幫助,請多關注
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。