資料庫系列:使用高區分度索引列提升效能
資料庫系列:MySQL慢查詢分析和效能優化
資料庫系列:MySQL索引優化總結(綜合版)
資料庫系列:高並行下的資料欄位變更
1 背景
我們常常在建立組合索引的時候,會糾結一個問題,組合索引包含多個索引欄位,它的順序應該怎麼放,怎樣能達到更大的效能利用。
正確的索引欄位順序應該取決於使用該索引的查詢的最高效率利用,並且同時需要考慮如何更好地滿足排序和分組的需要。下面我們詳細來說說。
2 索引檢索的原理
以innodb為例子, innodb是MySQL預設的儲存引擎,使用範圍較廣,而 innodb的資料組織結構是B+Tree模式。
B+Tree是在B-Tree基礎上的一種優化,使其更適合實現外儲存索引結構,InnoDB儲存引擎就是用B+Tree實現其索引結構。
從上面的B-Tree結構圖中可以看到每個節點中不僅包含資料的key值,還有data值。而每一個頁的儲存空間是有限的,如果data資料較大時將會導致每個節點(即一個頁)能儲存的key的數量很小,當儲存的資料量很大時同樣會導致B-Tree的深度較大,增大查詢時的磁碟I/O次數,進而影響查詢效率。在B+Tree中,所有資料記錄節點都是按照鍵值大小順序存放在同一層的葉子節點上,而非葉子節點上只儲存key值資訊,這樣可以大大加大每個節點儲存的key值數量,降低B+Tree的高度,提高查詢效率。
B+Tree相比較於B-Tree的不同點:
1、非葉子節點只儲存鍵值資訊。
2、所有葉子節點之間都有一個鏈指標。
3、資料記錄都存放在葉子節點中。
將上面的B-Tree優化,由於B+Tree的非葉子節點只儲存鍵值資訊,假設每個磁碟塊能儲存4個鍵值及指標資訊,則變成B+Tree後其結構如下圖所示:
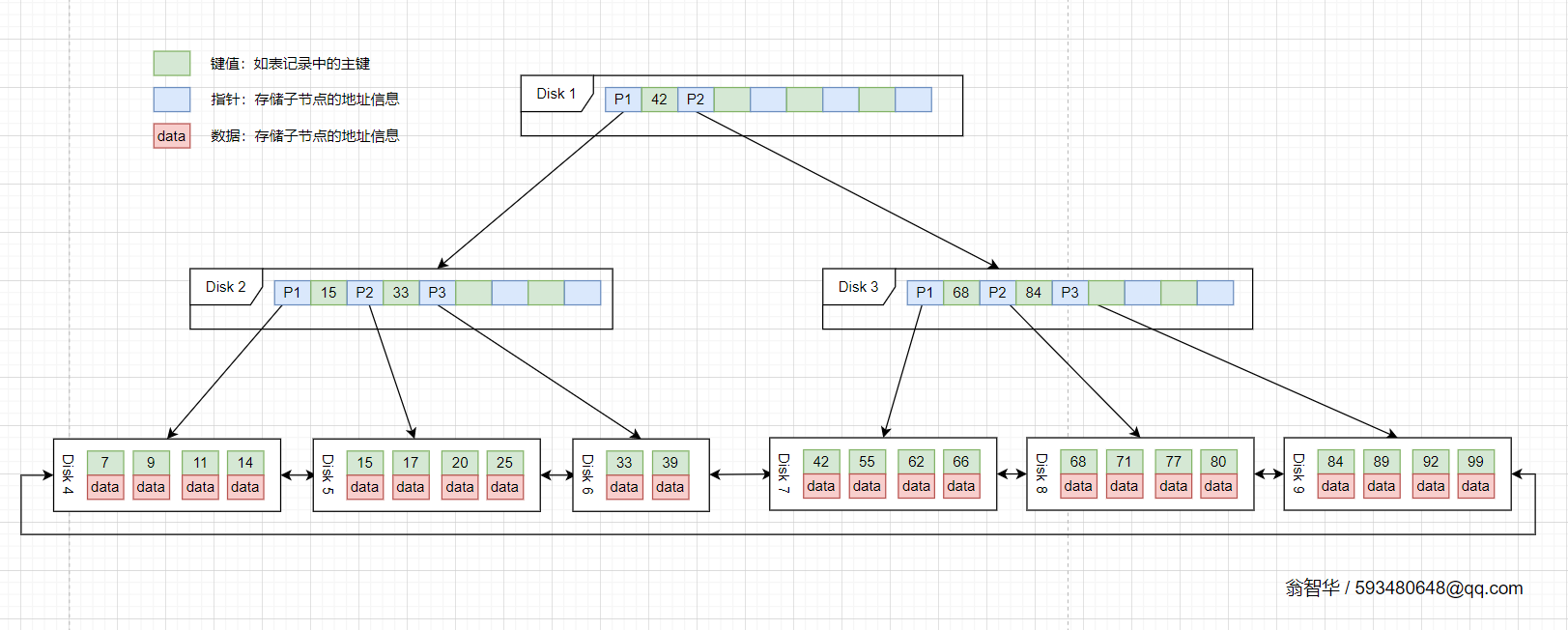
InnoDB儲存引擎中頁的大小為16KB,一般表的主鍵型別為INT(佔用4個位元組)或BIGINT(佔用8個位元組),指標型別也一般為4或8個位元組,也就是說一個頁(B+Tree中的一個節點)中大概儲存16KB/(8B+8B)=1K個鍵值(因為是估值,為方便計算,這裡的K取值為〖10〗^3 )。也就是說一個深度為3的B+Tree索引可以維護10^3 * 10^3 * 10^3 = 10億 條記錄。
★ 當你查詢的資料越大的時候,儲存的空間需求就越大,你這棵屬樹的深度也就越大,越往下搜尋,IO次數越多,效能也就越差。
所以說,優質的索引是儘量壓縮搜尋次數,更快的查到資料結果為最佳。
索引的詳細說明可以參考我得這一篇《MySQL全面瓦解23:MySQL索引實現和使用》
3 索引區分度的分析
3.1 索引區分度衡量策略
假設我們有一個500w資料容量的部門表 emp,想在 僱員名稱 和 部門編號 這兩個欄位上做索引,哪個欄位的索引區分度更高,執行效率更高呢?
下面以兩個有序的陣列為例子,都包含10條記錄,分別代表 僱員名稱 和 部門編號 的索引。
[ali , brand , candy , david , ela , fin , gagn , halande , ivil , jay , kikol]
和
[dep-a , dep-a , dep-a , dep-a , dep-a, dep-b , dep-b , dep-b , dep-b , dep-b]
如果要檢索值為 empname ='brand' 和 depno='dep-b' 的所有記錄,哪個效率會高一點?
使用二分法查詢執行步驟如下:
- 僱員名稱查詢
- 使用二分法找到最後一個小於指定值 brand(就是上面陣列中標紅色的 ali 的記錄)
- 沿著這條記錄向後掃描,和指定值 brand 對比,直到遇到第一個大於指定值即結束,或者直到掃描完所有資料。
- 部門編號查詢
- 使用二分法找到最後一個小於指定值 dep-b(就是上面陣列中標紅色的 dep-a的記錄)
- 沿著這條記錄向後掃描,和指定值 dep-b 對比,直到遇到第一個大於指定值即結束,或者直到掃描完所有資料。
採用上面的方法找到需要檢索的記錄,第一個陣列中更快的一些。因為第二個陣列中含有dep-b的基數更大,需要存取和比較的次數也更多一點。
所以說區分度越高的。
舉個例子就明白了,假如一個班級50名學生(25名男生、25名女生),所用性別作為索引欄位,你需要掃描25次才能把資料完全掃出。
使用是學生姓名,就不需要計算那麼多次。明顯的過濾範圍不是一個量級。
這種區分是有一種計算公式來衡量的:
selecttivity = count(distinct c_name)/count(*)
當索引區分度越高,檢索速度越快,索引區分度低,則說明重複的資料比較多,檢索的時候需要存取更多的記錄才能夠找到所有目標資料。
當索引區分度小到無限趨近於0的時候,基本等同於全表掃描了,此時檢索效率肯定是慢的。
第一個陣列沒有重複資料,索引區分度為1,第二個區分度為0.2,所以第一個檢索效率更高。
我們建立索引的時候,儘量選擇區分度高的列作為索引,如果是組合索引,也儘量以區分度更高的排在前面。
3.2 真實資料對比
我們回過頭來看看emp 表中的兩個欄位,empname 和 depno 欄位,
empname基本不重複,所以每個empname只有一條資料;而 500W的資料大約分配了10個部門,所以每個的depno下有約50W的資料。
1 mysql> select count(distinct empname)/count(*),count(distinct depno)/count(*) from emp;
2 +----------------------------------+--------------------------------+
3 | count(distinct empname)/count(*) | count(distinct depno)/count(*) |
4 +----------------------------------+--------------------------------+
5 | 0.1713 | 0.0000 |
6 +----------------------------------+--------------------------------+
7 1 row in set
再看看兩種不同組合索引查詢的效率對比,耗時不是一個級別的
- 按照 empname,depno 組合
mysql> create index idx_emp_empname_depno on emp(empname,depno);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from emp where empname='LsHfFJA' and depno='106';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.021 sec)
- 按照 depno,empname 組合
mysql> create index idx_emp_depno_empname on emp(depno,empname);
Query OK, 0 rows affected
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from emp where depno='106' and empname='LsHfFJA';
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| id | empno | empname | job | mgr | hiredate | sal | comn | depno |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
| 4582071 | 4582071 | LsHfFJA | SALEMAN | 1 | 2021-01-23 16:46:03 | 2000 | 400 | 106 |
+---------+---------+---------+---------+-----+---------------------+------+------+-------+
1 row in set (0.393 sec)
4 總結
匹配度分析和基數容量的計演演算法則是非常值得借鑑的,但在真實的環境下,查詢的複雜度要高的多,WHERE子句中的排序、分組和範圍條件等其他因素,都可能對查詢的效能造成非常大的影響。後面我們結合實際的排序、分組、範圍條件變化的情況來做更深入的分析。
