關於「語雀故障公告」的學習與思考:可監控!可灰度!可回滾!
你好呀,我是歪歪。
昨天晚上語雀釋出了關於 10 月 23 日的故障公告,公告中關於故障的時間點梳理如下:
這是公告連結:https://mp.weixin.qq.com/s/WFLLU8R4bmiqv6OGa-QMcw
14:07 資料儲存運維團隊收到監控系統報警,定位到原因是儲存在升級中因新的運維工具 bug 導致節點機器下線; 14:15 聯絡硬體團隊嘗試將下線機器重新上線; 15:00 確認因儲存系統使用的機器類別較老,無法直接操作上線,立即調整恢復方案為從備份系統中恢復儲存資料; 15:10 開始新建儲存系統,從備份中開始恢復資料,由於語雀資料量龐大,此過程歷時較長; 19:00 完成資料恢復,同時為保障資料完整性,在完成恢復後,用時 2 個小時進行資料校驗; 21:00 儲存系統通過完整性校驗,開始和語雀團隊聯調。 22:00 恢復語雀全部服務,使用者所有資料均未丟失。
我們一起盤一下這個時間點,多從別人的事故中總結經驗教訓,學習避坑指南。

14:07
首先第一個時間點,14:07,資料儲存運維團隊收到了健康系統的報警,然後開始定位問題。
我翻了一下微博,這個時間點幾乎和微博話題「#語雀崩了#」下的一條微博的時間點能對應上,而且還早了 7 分鐘。
不要小看這 7 分鐘,這說明系統人員先於使用者感知到了問題的存在,說明監控系統的預警是有效的。
不知道在其他公司是什麼規定,但是在歪師傅所在的公司,一切生產問題,只要是有監控手段、是通過監控系統自主發現的、上報故障時間早於使用者反饋的,不管最後的情況又多嚴重,都會一定程度上的減輕懲罰力度。
甚至對於一些屬於嚴重 BUG 但是沒有造成嚴重後果的,因為有監控的存在,監控及時生效,出了問題你立馬就監控出來了的,是可以免責的。
監控,全方面、細粒度、低噪音、高觸達的監控,非常非常重要。
這一點,從公告上來,語雀的運維團隊是做到了。
但是這一點也不值得表揚,因為這樣的監控本來就是應該要做到的。
14:15
這個時間點的操作是「聯絡硬體團隊嘗試將下線機器重新上線」。
這句話我確實看不懂,就不亂評論了。
但是我盲猜一個,因為我讀到這句話的時候,看到「硬體」兩個字的時候就自動聯想到了機房裡面的硬碟,所以腦海裡面浮現出來的一個莫名其妙的畫面是這樣的:
一個運維老哥,穿著鞋套,帶著帽子,站在機房裡面,把硬碟一個個的拔出來,吹口氣,又一個個的插進去,並仔細的觀察著訊號燈的情況。

15:00
從 14:15 分到 15:00,中間有 45 分鐘的時間。
這 45 分鐘我想應該是極其精彩的 45 分鐘。
因為在這 45 分鐘內,確定了之前制定的「將下線機器重新上線」方案是不可用的,而且不可用肯定不是一句話的事情,硬體團隊的負責人或者其他的某個同事,需要給領導大致的彙報清楚,並探討新的解決方案。
是的,我猜測領導也是在這 45 分鐘內才知道發生了這麼大的事情,因為當新方案制定出來之後,需要給領導同步一個噩耗:這個方案執行完成,需要很長的時間,樂觀估計需要 3 個小時,這 3 個小時內,我們的服務將完全不可用。而且經過討論,我們當前只有這一個方案可以使用。
所以,這 45 分鐘內,發生了幾個重要的事情:原方案斃了;新方案討論;新方案執行時間太長,事件必須升級到上級領導;編寫公告,同步使用者。
由於運維工具的 BUG 導致當前的儲存系統已經不行了,我簡單的理解為就是資料庫崩了,整個崩的稀碎,裡面的資料「死傷無數」,救活的成本比重新搭一個還高。
因此制定出來的新方案就是:從備份系統中恢復儲存資料。
所以在官方的公告下,我們才看到了這樣的一句話:
預計最晚今天內,最快6點前
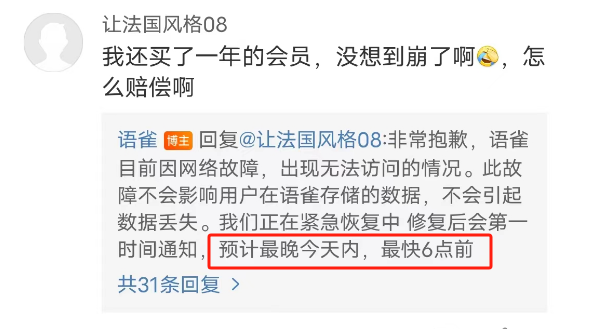
這個時間怎麼估算出來的?
15 點到 16 點,3 個小時是給領導彙報的時候最樂觀的情況,屬於老天開眼,幫一把這個可憐的孩子,恢復資料的過程異常絲滑、毫無疑問的情況。
而最晚今天內,15 點到 24 點,有 9 個小時,多出來的 6 個小時,應該是夠處理恢復過程中的異常情況了...吧?

15:10
開始架勢,正式從備份檔案中開始恢復資料。
在官方的公告中說到「由於語雀資料量龐大」,這個龐大到底到了什麼級別就不得而知了。
反正資料恢復的事件和資料量的大小成正比。
昨天我在微博看到一個評論說的是:8 個小時,我重新開始把服務全部部署一遍也綽綽有餘了。
是的,服務部署是分分鐘的事情,哪怕是人肉運維也服務全部重啟一邊也要不了 8 個小時。
其實當時我心裡就在嘀咕:不會是資料方面的問題吧。
歪師傅也算是一個久經沙場的程式猿了,以我淺薄的經驗來說,對一個生產事故,定位生產 BUG,修復生產 BUG 是一件相對容易的事情,最難受的一個環節就是修復由於 BUG 導致的資料問題。
這玩意,誰遇到過,誰就知道有多痛了。
我曾經遇到過一個生產 BUG,由於引數設定錯誤,導致跨了好幾個系統的一串資料全都算錯了,而且資料的量級還不少,而且還疊加了正常業務下這些資料還在動態變化的 BUFF,要把這一批資料修復正確,我搞了半個月的時間,基本上每天都搞到 23 點之後。
從第二週的時候,心態就完全崩成渣渣了,一邊搞資料一邊嘟囔著:這波搞完了,我 TM 的必須要離職了,太難受了。
後來你猜怎麼著?
資料搞完之後,心情一下就舒暢了,發現自己又能支稜起來了,同事私下問感受如何,我也只是輕描淡寫的說了一句:這能有啥感受,能通過修數修復的問題,都不是大問題。
所以我非常理解這個「恢復時間」長的原因,涉及到資料了,沒辦法,急也沒用。

19:00
從 15 點開始恢復,到 19 點恢復完成,用時 4 個小時,比樂觀預計時間只長了一小時而已,可以說是老天保佑了,沒出啥大岔子。
資料修復完成之後,語雀幹了一件什麼事情?
看看公告上的這句話:為保障資料完整性,在完成恢復後,用時 2 個小時進行資料校驗。
首先我不管他們是真的在進行資料校驗,還是為了從公告上縮短恢復資料的時間,或者其實這個時間段內還有其他步驟,或者其他什麼不方便透露的原因等等,我都不關心。
我只關心這個動作:在完成恢復後,用時 2 個小時進行資料校驗。
這個動作真的是太重要了,你想想,如果語雀團隊在資料修復完成之後,不做這個事情,或者說只是花了幾分鐘時間進行了一些極其簡單的驗證,最後導致使用者發現他的資料丟了,勢必會掀起更加瘋狂的輿論浪潮,導致更加嚴重的使用者流失和口誅筆伐。
所以我認為這兩個小時雖然很長,但是是非常重要的一環,哪怕最後驗證的結果是確實沒有資料丟失,也是非常值得的,團隊心裡有了底。
而在時間已經到了 19 點,宕機 6 個小時的情況下,願意拍板再拿出 2 小時時間進行資料完整性校驗的人,是個團隊大心臟,穩得一筆。
處理生產事件,大家都是火急火燎的,這個時候出來一個說話有分量的人說:大家千萬別急,既然事情已經發生了,我們就一點點的把事情做好,不要引入新的問題,防止事態進一步擴散。
這個人,他簡直就是在發光。

之後的這兩個時間點,就不再展開說了:
21:00 儲存系統通過完整性校驗,開始和語雀團隊聯調。 22:00 恢復語雀全部服務,使用者所有資料均未丟失。
語雀再次強調了「使用者所有資料均未丟失」,這點確實很重要,從各個平臺的反饋來看,也沒有看到有使用者反饋資料丟失的情況。
(但是歪師傅還是不明白,明明是從備份中恢復的資料,怎麼可能不丟失資料呢?哪怕一小時一備份,也至少丟一小時的資料呀。)
關於改進措施

這裡面以這次故障為抓手,結合各團隊通力共同作業,上下游拉通對齊,打出了一套組合拳,對焦本次事故,沉澱出了一份可複用的方法論,想要給系統更好的賦能:
保命箴言:可監控,可灰度,可回滾 能力建設:從同 Region 多副本容災升級為兩地三中心的高可用能力 定時演練:進行定期的容災應急演練
在改進措施的部分,我建議所有開發,運維,包括測試同學,都應該把「可監控,可灰度,可回滾」這九個字貼在工位上,刻在腦子裡,做方案、寫程式碼、提測前、上線前都把這九個字拿出來咂摸一下。

這九個字,說起來簡單,但是落地是真的難。
雖然落地難,但是是真的可以保命的,至少保過我的命。
另外這次事件從描述上來看,是運維人員的鍋,所以改進措施裡面也多次提到了「運維」這個關鍵詞。
不知道這個運維老哥是否被開除了,這很難說。
但是通過這個事情,或者我遇到過的一些生產事故來說,我想要表達的,如果一個公司或者團隊,遇到事情之後,第一反應是找對應的責任人出來處罰、開除某些人、扣某些人的績效等等這些懲罰手段,那麼帶來的後果是大家再次遇到事情的時候,第一反應就是先甩鍋,把自己撇乾淨,或者先隱瞞,瞞住了就過去了,瞞不住就導致更大的問題,這樣很不好。
正確的做法應該是拿著相關人員進行整個事件的覆盤,看看這次事件到底暴露了哪些問題。
就拿語雀的這次事件來說:生產運維操作,運維工具有 BUG,那麼是否經過充分的測試?是否留有足夠的灰度觀察時間?是否有雙人複核機制?是否有生產緊急事件預案?等等...
這些都是流程上的問題,而不是某個運維人員的問題。
或者說應該是先找流程上的問題,那麼最後才是找到某個具體的人身上。
有了流程,經過了流程評審,形成了規則制度,宣講了規章制度,操作的人沒有按照流程來,那麼這個人確實該罰。
而且這個流程,應該是通過一次又一次大大小小的事件不斷演進優化的流程。
最後
以上就是歪師傅通過語雀這個事情的一點看法吧,它的嚴重生產故障,對於我來說也是一個學習的過程。
最後,語雀給的賠償方案還是比較有誠意的,直接給六個月會員:

那沒啥說的了,反正對我沒有產生什麼實質上的影響,還蹭到了一波熱度《語雀,這波故障,放眼整個網際網路也是炸裂般的存在。》
還免費領了六個月會員。
好了,我就當沒事發生了。
