LLM在text2sql上的應用
一、前言:
目前,大模型的一個熱門應用方向text2sql它可以幫助使用者快速生成想要查詢的SQL語句。那對於使用者來說,大部分簡單的sql都是正確的,但對於一些複雜邏輯來說,需要使用者在產出SQL的基礎上進行簡單修改,Text2SQL應用主要還是幫助使用者去解決開發時間,減少開發成本。
Text to SQL: 簡稱Text2SQl,是將自然語言文字(Text)轉換成結構化查詢語言SQL的過程,屬於自然語言處理-語意分析(Semantic Parsing)領域中的子任務。
它的目的可以簡單概括為:「打破人與結構化資料之間的壁壘」,即普通使用者可以通過自然語言描述完成複雜資料庫的查詢工作,得到想要的結果。
二、背景應用:
目前大家對T2S的做法大致分為兩種,
- 一種是用現有的大模型來直接生成,例如ChatGPT、GPT-4模型,但是對於一些公司來說,資料是屬於保密資產,這種方式相當於將自己公司的資料資訊透漏給大模型,屬於資料洩露行為;
- 另一種方式是利用開源的大模型做finetune,比如chatglm2-6b來做微調,這個也是目前我們在做的,同時開源的資料集也有很多,簡單羅列如下:
| 資料集 | 資料集介紹 |
|---|---|
| WikiSQL | WikiSQL是一個大型的語意解析資料集,由80,654個自然語句表述和24,241張表格的sql標註構成。 WikiSQL中每一個問句的查詢範圍僅限於同一張表,不包含排序、分組、子查詢等複雜操作。 雖然資料規模大,SQL語法卻非常簡單;適合做NL2SQL任務入門。 |
| Spider | 耶魯大學在2018年新提出的一個大規模的NL2SQL(Text-to-SQL)資料集。 該資料集包含了10,181條自然語言問句、分佈在200個獨立資料庫中的5,693條SQL,內容覆蓋了138個不同的領域。 涉及的SQL語法最全面,是目前難度最大的NL2SQL資料集。 |
| Cspider | CSpider是Spider的中文版,西湖大學出品。 |
| Sparc | 耶魯大學在2019年提出的基於對話的Text-to-SQL資料集。 SParC是一個跨域上下文語意分析的資料集,是Spider任務的上下文互動版本。SParC由4298個對話(12k+個單獨的問題,每個對話平均4-5個子問題,由14個耶魯學生標註)組成,這些問題通過使用者與138個領域的200個複雜資料庫進行互動獲得。 |
| CHASE | 微軟亞研院和北航、西安交大聯合提出的首個大規模上下文依賴的Text-to-SQL中文資料集。 內容分為CHASE-C和CHASE-T兩部分,CHASE-C從頭標註實現,CHASE-T將Sparc從英文翻譯為中; 相比以往資料集,CHASE大幅增加了hard型別的資料規模,減少了上下文獨立樣本的資料量,彌補了Text2SQL多輪互動任務中文資料集的空白。 |
三、Text2SQL使用:
我們在Text2SQL上面的應用主要包括兩個階段,第一階段是利用LLM理解你的請求,通過請求去生成結構化的SQL;下一個階段是在生成的SQL上自動化的查詢資料庫,返回結果,然後利用LLM對結果生成總結,提供分析。
3.1 第一階段:
利用LLM理解文字資訊,生成SQL,目前通過spider資料集來評測,GPT家族還是笑傲群雄。但是這裡我們如果只借助GPT來做的話,就會出現之前說的資料隱私問題。
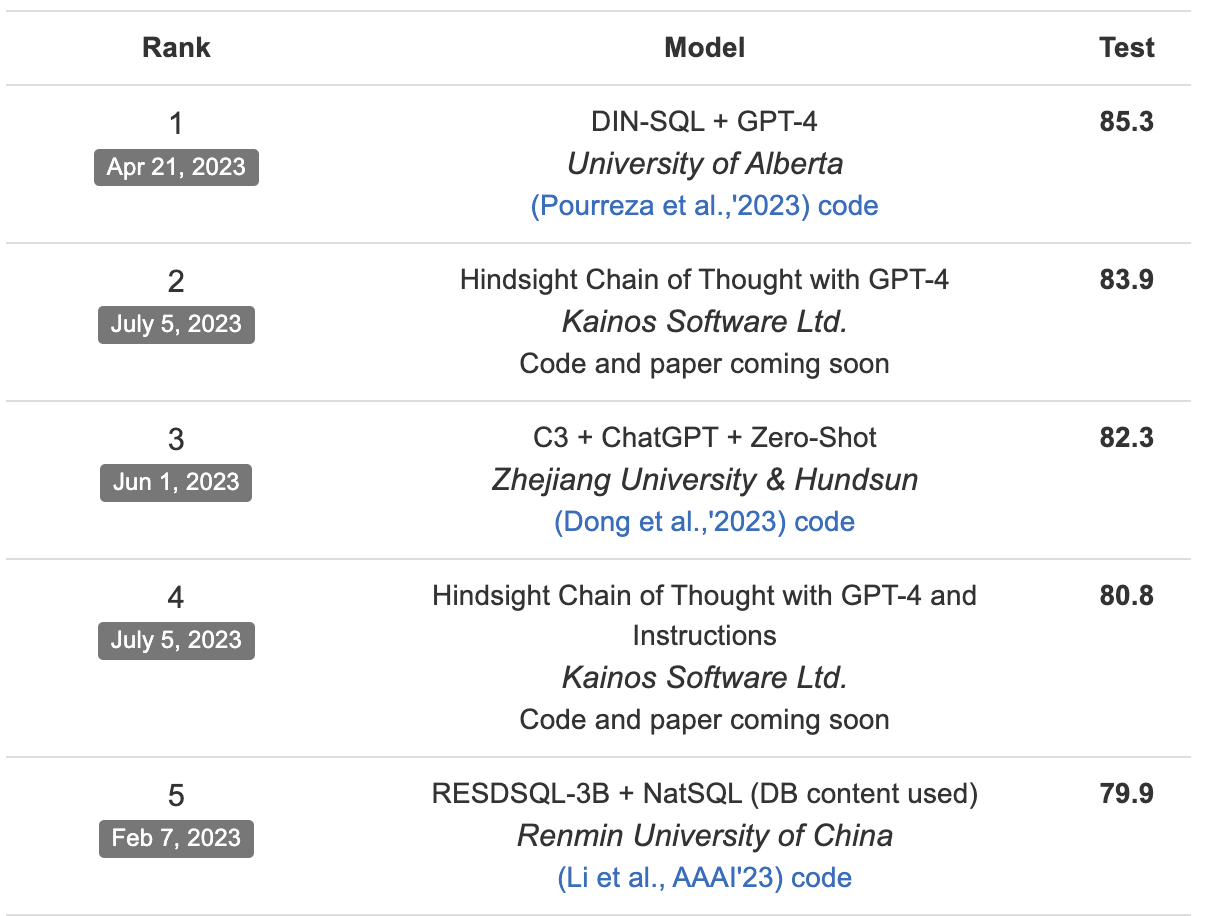
這裡我們通過兩部分來提升LLM對文字的理解,生成更符合我們要求的結果。
1. 構建資料資訊表的schema,利用LLM生成embedding
由於我們從離線評測效果來看,開源模型chatglm2-6b直接生成的SQL和GPT對比,還是有比較大的差距,所以無法直接使用。這裡我們根據使用者描述的text,讓預訓練的chatglm2-6b生成embedding,通過embedding檢索的方式,選出top1資料表,這個過程屬於先驗過濾階段。
資料表的schema設計非常重要,需要描述清楚這個表它的主體資訊以及表中重要欄位和欄位含義。
例:
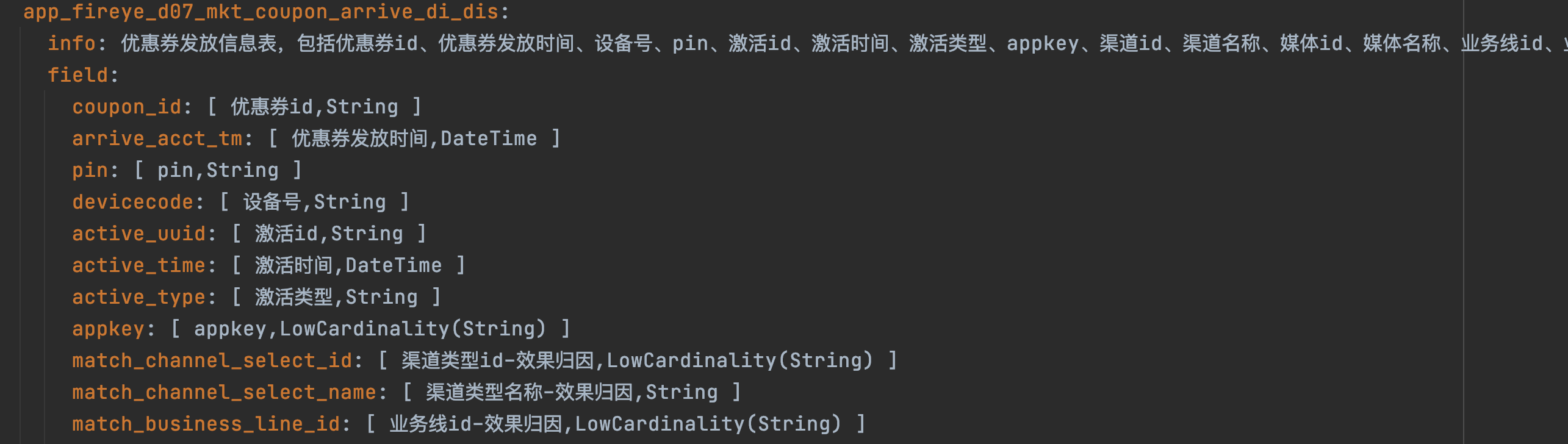
資料表的embedding可以提前計算儲存,這樣利用後期檢索效率。
2. prompt構建,生成SQL
這部分我認為最重要的還是如何去合理構建prompt,讓LLM去理解你的真實意圖,生成標準的SQL。
一是prompt的開頭需要定義構建,二是prompt整體結構以及結構中資料表的資訊也需要涵蓋進去,這裡我們prompt的開頭首先定義LLM的工作目的是生成SQL,通過我們根據第一部分返回的top1資料表,解析資料表中的資訊,加入到prompt中,以此來構建完成的prompt。
1)開頭prompt定義:

2)資料表prompt定義:

3)In-context-prompt:如果想強化prompt,可以增加一些正樣本「問答」式的結構,讓LLM去學習理解,最終生成更理想的結果

prompt的構建對最終結果的影響非常重要,構建一個完美的prompt可能已經成功了一半。
通過以上的prompt構建,我們就可以給LLM讓模型生成最終的SQL結果。

3.2 第二階段:
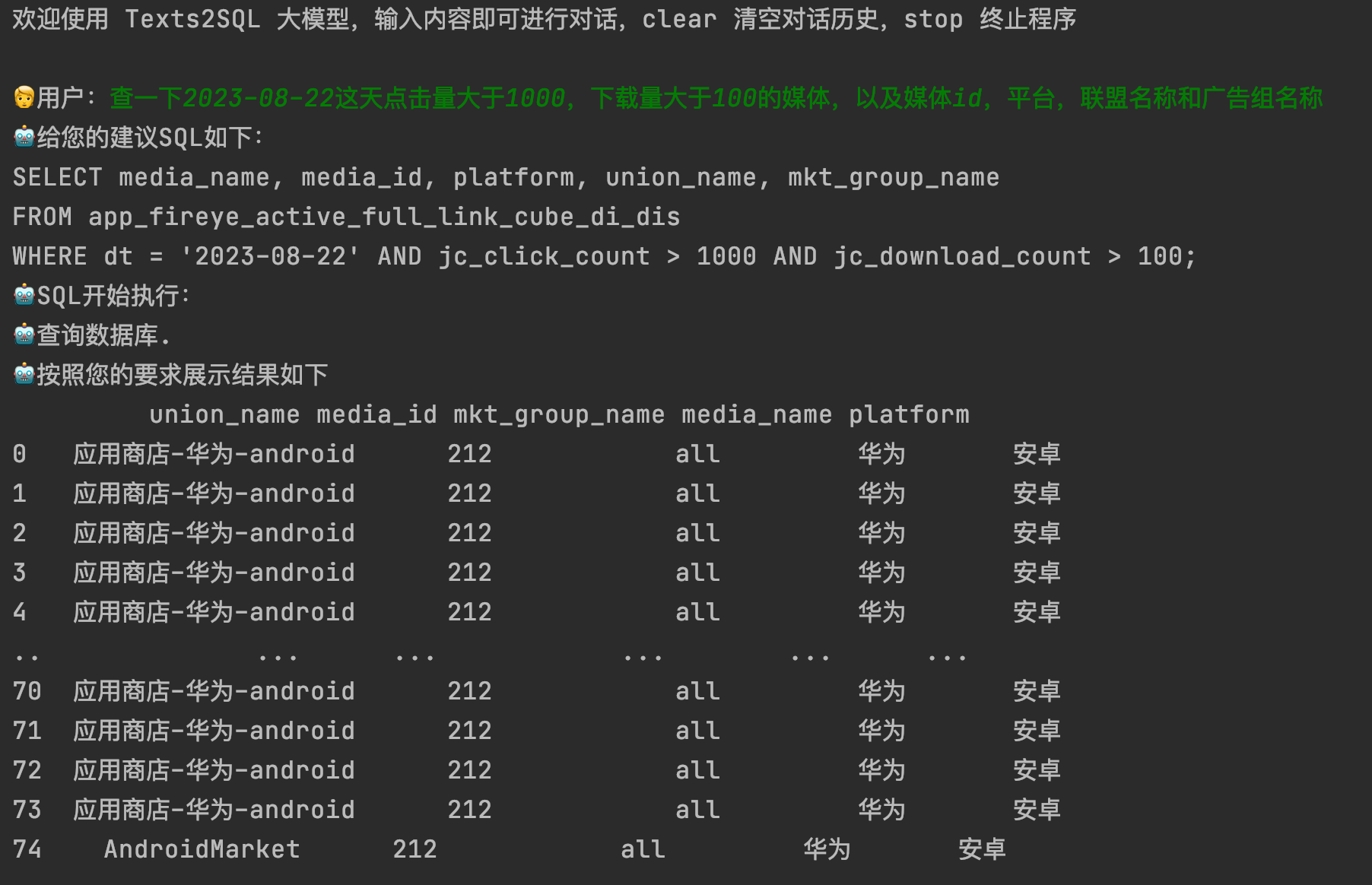
其實很多場景上一階段生成SQL就已經達到我們想要的結果,但這裡我們還想進一步根據SQL生成最終的資料,所以需要連線資料庫,SQL執行返回結果。這裡我們通過連線集團CK資料庫,以介面的形式進行部署,我們在執行SQL的時候,其實就是呼叫介面,這樣方便簡潔,對介面返回的結果進行結構化的輸出就可以。
通過介面存取結構化輸出:

四、結果:
以上就是目前我們根據LLM來生成SQL,同時讓SQL自動執行產生結果。前期我們利用GPT模型去跑通整個pipeline,同時生成一些訓練資料集,來提供chatglm2-6b微調,後期我們還會對產出的結果進行資料分析,這個階段也是利用LLM來完成,通過這種方式給使用者一些指導性的意見或總結。
以下是整個pipeline的流程:
作者:京東零售 鄭少強
來源:京東雲開發者社群 轉載請註明來源