InnoDB 儲存引擎之 Buffer Pool
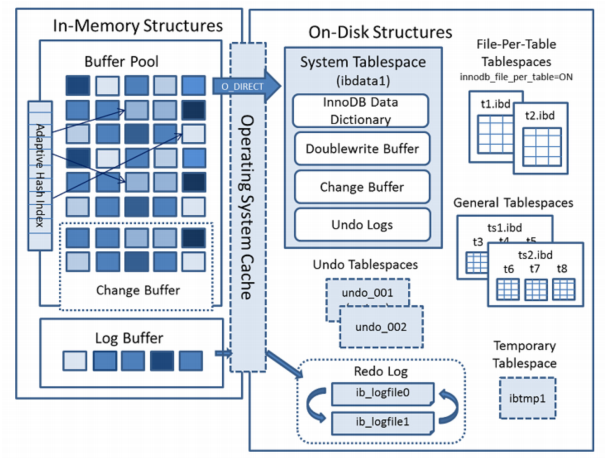
Mysql 5.7 InnoDB 儲存引擎整體邏輯架構圖
一、Buffer Pool 概述
InnoDB 作為一個儲存引擎,為了降低磁碟 IO,提升讀寫效能,必然有相應的緩衝池機制,這個緩衝池就是 Buffer Pool
為了方便理解,對於磁碟上的資料所在的頁,叫做資料頁,當資料頁載入進 Buffer Pool 之後,叫做快取頁,這兩者是一一對應的,只不過資料是在磁碟上,快取頁是在記憶體中
Buffer Pool 作為 InnoDB 儲存引擎記憶體結構的四大元件之一,它主要由以下特點
1、Buffer Pool 快取的是 最熱的資料頁和索引頁,把磁碟上的資料頁快取到記憶體中,避免每次存取資料都要進行磁碟 IO 操作,提升了資料的讀寫效能
2、Buffer Pool 以快取頁為基本單位,每個快取頁的預設大小是 16KB,Buffer Pool 底層採用雙向連結串列的資料結構管理快取頁
3、Buffer Pool 是一塊連續的記憶體區域,它的作用是為了降低磁碟 IO,提升資料的讀寫效能,所有資料的讀寫操作都需要通過 Buffer Pool 才能進行
- 讀操作: 先判斷 Buffer Pool 中是否存在對應的快取頁,如果存在就直接操作 Buffer Pool 中的快取頁,如果不存在,則需要將磁碟上的資料頁讀入到 Buffer Pool 中,然後操作 Buffer Pool 中對應的快取頁即可
- 寫操作: 先把資料和紀錄檔等資訊分別寫入 Buffer Pool 和 Log Buffer,再由後臺執行緒將 Buffer Pool 中的資料刷盤
二、Buffer Pool 控制塊
Buffer Pool 中存放的是快取頁,快取頁大小跟磁碟資料頁大小一樣,都是預設 16KB,為了更好的管理快取頁,InnoDB 為每一個快取的資料頁都建立一個單獨的區域,用於記錄資料頁的後設資料資訊,這些資訊主要包括 資料頁所屬表空間編號、資料頁編號、快取頁在 Buffer Pool 中的地址、連結串列節點資訊、索資訊、LSN 資訊等,這個特殊的區域被稱為控制塊
控制塊和快取頁是一一對應的,它們都被存放在 Buffer Pool 中,控制塊的大小大概佔快取頁大小的 5% 約為 819 個位元組(16 * 1024 * 0.05 = 819.2B)
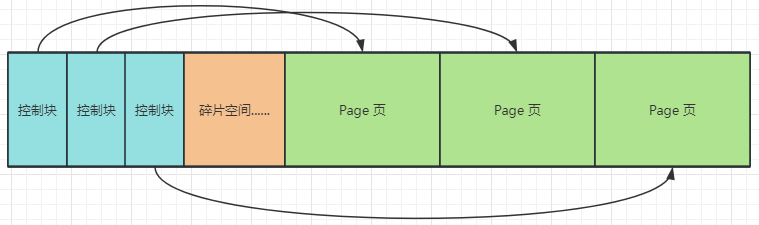
圖示中存在一個碎片空間,這個碎片空間是怎麼產生的?
資料頁大小為 16KB,控制塊大概為 800B,當我們劃分好所有的控制塊與資料頁後,可能會有剩餘的空間不夠一對控制塊和快取頁的大小,這部分就是多餘的碎片空間.如果把 Buffer Pool 的大小設定的剛剛好的話,也可能不會產生碎片
三、Buffer Pool 快取頁管理機制
Buffer Pool 底層採用雙向連結串列這種資料結構來管理快取頁,在 InnoDB 存取表記錄和索引時會將對應的資料頁快取在 Buffer Pool 中,以後如果需要再次使用時直接操作 Buffer Pool 中的快取頁即可,減少了磁碟 IO 操作,提升讀寫效率
當啟動 Mysql 伺服器的時候,需要完成對 Buffer Pool 的初始化,即分配 Buffer Pool 的記憶體空間,把它劃分為若干對控制塊 + 快取頁的組合,整個初始化過程大致如下
- 申請空間: Mysql 伺服器啟動時,會根據設定的 Buffer Pool 大小(innodb_buffer_pool_size),去作業系統申請 一塊連續的記憶體區域 作為 Buffer Pool 的記憶體空間,實際的記憶體空間大小應該要大於 innodb_buffer_pool_size,主要原因是裡面還要存放每個快取頁的控制塊,這些控制塊佔用的記憶體大小不計算進入 innodb_buffer_pool_size 中
- 劃分空間: 當記憶體區域申請完畢之後,Mysql 就會按照預設的快取頁大小(16KB) 以及對應的控制塊大小(約 800B),將整個 Buffer Pool 劃分為若干個 控制塊 + 快取頁 的組合
Buffer Pool 中的快取頁根據狀態可以分為三種型別
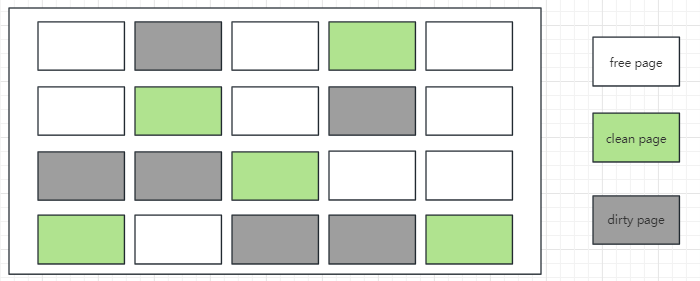
Free page: 空閒 page,未被使用的 page 頁
Clean page: 已經被使用,但是資料沒有被修改過,Buffer Pool 和磁碟上的資料是一致的
Dirty page: 髒頁,已經被使用,並且資料被修改過,Buffer Pool 和磁碟上的資料不一致
針對上面所說的三種 page 頁型別,InnoDB 通過三種連結串列來維護和管理這些 page 頁,這三種連結串列分別是 Free 連結串列、Flush 連結串列、LRU 連結串列
3.1、Free 連結串列
在 Buffer Pool 剛被初始化出來的時候,所有的控制塊和資料頁都是空的,當執行讀寫操作的時候,磁碟的資料頁會被載入到 Buffer Pool 的快取頁中,當 Buffer Pool 中有的資料頁持久化到磁碟的時候,這些快取頁又要被空閒出來,如何知道哪些資料頁是空的,哪些資料頁是有資料的,只有找到空的資料頁,才能把資料寫進行去,一種方式是遍歷所有的資料頁,挨個查詢,找到符合要求的空資料頁,還有 另外一種方式就是通過某種資料結構來進行管理,這種資料結構就是 Free 連結串列
Free 連結串列表示 空閒緩衝區,其作用是管理 Buffer Pool 中所有的 free page,它是一個雙向連結串列,由一個基節點和若干個子節點組成,記錄空閒的資料頁對應的控制塊資訊,
Free 連結串列是把所有空閒的緩衝頁對應的控制塊作為一個個節點放在一個連結串列中,
基節點: Free 連結串列中基節點是不記錄快取頁資訊的,需要單獨申請,它裡面就存放了 free 連結串列的頭結點的地址、尾節點的地址、以及整個 Free 連結串列裡面當前有多少個節點
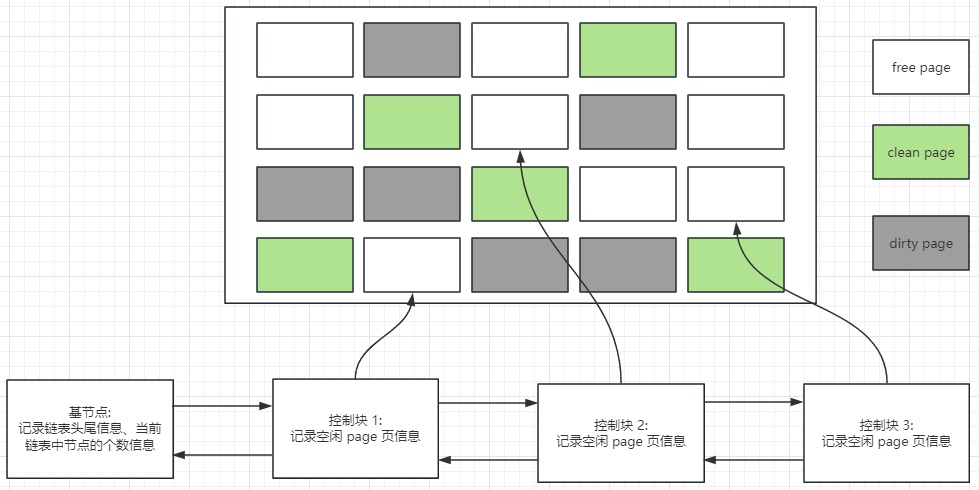
磁碟載入資料頁到 Free page 的流程
1、從 Free 連結串列中取出一個空閒的控制塊
2、把該空閒控制塊的資訊填上(快取頁所在的表空間、頁號等資訊),通過控制塊與快取頁一一對應的關係,找到 Buffer Pool 中的快取頁,然後把磁碟中的資料頁讀入到 Buffer Pool 的快取頁中
3、把該空閒控制塊從 free 連結串列中移除,這樣就代表該緩衝頁已經被使用了
如何判斷要操作的資料所在的資料頁是否已經快取在 Buffer Pool 中呢?
Mysql 中有一個雜湊表資料結構,它使用 表空間編號 + 資料頁編號作為 key,快取頁對應的控制塊作為 value
當使用資料頁時,會先在資料頁快取 Hash 表中進行查詢,找到了之後取出 value 值對應的控制塊,由於控制塊和 Bufer Pool 中的快取頁是一一對應的,通過控制塊就能定位到快取頁如果在資料頁快取的 Hash 表中查詢失敗,那麼就要從磁碟讀入了
| 資料頁快取的 Hash 表 | |
| key | value |
| 表空間號 + 資料頁號 | 控制塊 1 |
| 表空間號 + 資料頁號 | 控制塊 2 |
| 表空間號 + 資料頁號 | 控制塊 3 |
| ...... | ...... |
需要注意的是 value 是控制塊編號,而不是快取頁號
3.2、Flush 連結串列
InnoDB 為了提高處理效率,在每次修改緩衝頁之後,並不是立刻把修改重新整理到磁碟上,而是在未來的某個時間點進行刷盤操作,所以需要使用 Flush 連結串列來儲存髒頁,凡是被修改過的緩衝頁對應的控制塊都會作為節點被加入到 Flush 連結串列中
Flush 連結串列表示需要重新整理到磁碟的緩衝區,其作用是為了管理 Dirty page
Flush 連結串列的結構和 Free 連結串列結構相似,這裡就不再畫圖贅述了
需要注意的是髒頁既存在 Flush 連結串列中,也存在 LRU 連結串列中,兩種連結串列互不影響,LRU 連結串列負責管理快取頁的可用性和釋放,而 Flush 連結串列負責管理髒頁的刷盤操作
當我們寫入資料的時候,磁碟 IO 的效率是很低下的,所以 Mysql 不會直接進行磁碟重新整理操作,而是要經過以下兩個步驟
- 更新 Buffer Pool 中的資料頁(一次記憶體更新操作)
- 將更新操作順序寫 Redo log file(一次磁碟順序寫)
這樣的效率是很高的,順序寫 Redo log 大概每秒幾萬次
當髒頁對應的控制塊被加入到 Flush 連結串列後,後臺執行緒就可以遍歷 Flush 連結串列,將髒頁寫入磁碟
3.3、LRU 連結串列
表示正在使用的緩衝區,其作用是為了管理 Clean page 和 Dirty page
InnoDB 的 Buffer Pool 的大小是有限的,並不能無限快取資料,對於一些頻繁存取的資料我們希望可以一直留在記憶體中,而一些很少存取的資料希望在某些時機可以淘汰掉,從而保證記憶體不會因為滿了而導致無法再快取新的資料,要實現這個目的,我們很容易想到 LRU(Least Recently Used)演演算法
LRU 演演算法一般是使用連結串列作為資料結構來實現的,連結串列頭部的資料是最近使用的,而連結串列末尾的資料是最久沒有被使用的,那麼當空間不夠的時候,就會淘汰最久沒被使用的節點,也就是連結串列末尾的資料,從而騰出記憶體空間
傳統的 LRU 演演算法實現思路
當存取的資料頁在記憶體中,就直接把該頁對應的連結串列節點移動到 LRU 連結串列的頭部
當存取的頁不在記憶體中,除了要把該頁對應的節點放入到 LRU 連結串列的頭部,還要淘汰連結串列最末尾的頁
假設有一個 LRU 連結串列,初始狀態如下圖所示

如果存取了 3 號頁,由於 3 號頁在記憶體中,需要將 3 號頁移動到連結串列的頭部,表示最近被存取了,同時 1,2 號頁需要向後移動

假設此時再次存取了一個記憶體中不存在的 9 號頁,需要將 9 號頁移動到 LRU 連結串列的頭部,其它節點向後移動,由於整個連結串列長度是 8,所以要將原來末尾的 8 號頁淘汰掉

傳統的 LRU 演演算法並沒有被 Mysql 使用,因為傳統的 LRU 演演算法無法避免下面兩個問題
- 預讀失效導致快取命中率下降;
- Buffer Pool 汙染導致快取命中率下降
什麼是預讀機制?
預讀是 InnoDB 儲存引擎的一種優化機制,當 Mysql 從磁碟載入頁時,會提前把它相鄰的頁一併載入進來
InnoDB 為什麼要預讀呢?
一般來說,資料的讀取會遵循集中讀寫的原則,也就是說當我們需要使用某一些資料的時候,很大概率也會用到附近的資料(即區域性性原理),如果要使用的資料頁是連續的,一次讀取多個資料頁相較於多次讀取但是每次唯讀一個頁來說,速度是更快的,因為一次讀取連續的多個資料頁是順序 IO,由於磁碟快速旋轉,磁頭只要在對應的磁軌上就能快速獲取資料,而多次讀取每次唯讀一個頁是隨機 IO,磁頭要不斷的移動,尋找磁軌然後才能讀取資料,磁頭的移動是機械性的,速度很慢
在兩種情況下會觸發 InnoDB 的預讀機制
1、順序存取了磁碟上一個區的多個資料頁,當這個數量超過一個閾值時,InnoDB 就會認為你對下一個區的資料也感興趣,因此觸發預讀機制,將下個區的資料頁也全部載入進 Buffer Pool,這個閾值由引數 innodb_read_ahead_threshold,預設值為 56,可以通過如下命令檢視
show variables like '%innodb_read_ahead_threshold%';

2、Buffer Pool 中已經快取了同一個區資料頁的個數超過 13 時,InnoDB 就會將這個區的其它資料頁也讀取到 Buffer Pool 中,這個開關由引數 innodb_random_read_ahead 控制,預設是關閉的,可以通過如下命令檢視
show variables like 'innodb_random_read_ahead';

什麼是預讀失效,預讀失效會帶來什麼影響?
如果這些提前載入進來的頁,並沒有被存取,相當於這個預讀的工作是白做的,這就是所謂的預讀失效
如果使用傳統的 LRU 演演算法,就會把預讀頁放到 LRU 連結串列的頭部,當記憶體空間不足的時候,還需要把連結串列末尾的頁淘汰掉
如果這些預讀頁一直不被存取,就會出現一個很奇怪的問題,不會被存取的預讀頁反而佔據了整個 LRU 連結串列的前排位置,而連結串列末尾的頁,可能是真正的熱點資料,這樣就大大降低了快取的命中率
如何避免預讀失效造成的影響?
我們不能因為害怕預讀失效,而將預讀機制去掉,在大部分的情況下,空間區域性性原理還是成立的
要避免預讀失效帶來的影響,最好的做法就是讓預讀頁在記憶體中停留的時間儘可能的短,這樣真正被存取的頁才能移動到 LRU 連結串列的頭部,從而保證真正被讀取的熱資料停留在記憶體中的時間儘可能長
那要怎麼做才能達成上面的預期呢?
Mysql InnoDB 儲存引擎通過改進傳統的 LRU 連結串列來避免預讀失效帶來的負面影響,具體的改進方式如下
Mysql 的 InnoDB 儲存引擎在一個 LRU 連結串列上劃分出兩個區域,young 區域和 old 區域,young 區域在 LRU 連結串列的前半部分,old 區域在後半部分,這兩個區域都有各自的頭節點和尾節點
young 區域和 old 區域在 LRU 連結串列中的佔比關係並不是 1:1,比例關係由 innodb_old_blocks_pct 引數進行控制,預設熱資料區域佔 63%,冷資料區域佔 37%

劃分好這兩個區域之後,預讀的頁就只需要加入到 old 區域的頭部,當資料頁真正被存取的時候,才將頁插入到 young 區域的頭部,如果預讀的頁一直沒有被存取,就會從 old 區域移除,整個過程並不會影響 young 區域中的熱點資料
假設有一個 LRU 連結串列初始長度為 8

現在有個編號為 9 的頁被預讀了,這個頁只會被插入到 old 區域頭部,而 old 區域末尾的頁 (8號) 會被淘汰掉

如果 9 號頁一直不會被存取,它也沒有佔用到 young 區域的位置,也就不會影響到熱資料區域,而且還會比 young 區域的資料更早被淘汰出去
如果 9號頁被預讀後,立刻被存取了,那麼就會將它插入到 young 區域的頭部,young 區域末尾的頁 (5號) 會被擠到 old 區域,作為 old 區域的頭部,這個過程並不會有頁被淘汰

從上可知,通過 young 和 old 區域的劃分,可以很好的解決預讀失效的問題
什麼是 Buffer Pool 汙染?
雖然 Mysql 通過改進傳統的 LRU 連結串列(劃分兩個區域),避免了預讀失效帶來的負面影響,但是如果還是使用只要資料被存取一次就加入到 LRU 連結串列的頭部這種方式的話,那麼還存在快取汙染的問題
當我們批次讀取資料的時候,由於資料被存取了一次,這些大量的資料就會被加入到 young 區域頭部,之前快取在 young 區域的熱點資料就被淘汰了,下次存取熱點資料的時候又要重新去磁碟讀取,大量的 IO 操作導致資料庫的效能下降,這個過程就是 Buffer Pool 汙染
Buffer Pool 汙染會帶來什麼問題?
Buffer Pool 汙染帶來的影響是致命的,當某一個 SQL 語句掃描了大量資料的時候,在 Buffer Pool 空間比較有限的情況下,可能會將 Buffer Pool 中的所有頁都替換出去,導致大量的熱資料被淘汰了,等這些熱資料又再次被存取的時候,由於快取未命中,又要重新去磁碟載入,這樣就會產生大量的磁碟 IO,Mysql 效能就會急劇下降
注意: 快取汙染並不只是查詢語句查詢除了大量的資料才出現的問題,即使查詢出來的結果集很小,也會造成快取汙染
比如,在一個資料量非常大的表,執行了下面這條 SQL 語句
select * from user where name like "%xiaomaomao";
從磁碟讀取資料頁加入到 LRU 連結串列的 old 區域頭部
從資料頁中讀取行記錄時,也就是頁被存取的時候,就要將該頁放入到 young 區域的頭部
接著拿行記錄中的 name 欄位和字串 xiaomaomao 進行模糊匹配,如果符合條件,加入到結果集中
如此往復,直到掃描完表中的所有記錄,經過這一番折騰,由於這條 SQL 語句存取的的頁非常多,每存取一個頁就會將其加入到 young 區域的頭部,那麼原本 young 區域的熱點資料都會被替換掉,導致快取命中率下降,那些在批次掃描時,而被加入到 young 區域的頁,如果在很長的一段時間都不會再被存取的話,那麼就汙染了 young 區域
如何解決 Buffer Pool 汙染?
造成 Buffer Pool 汙染的原因是,全表掃描導致載入大量資料頁到 old 區域,緊接著這些資料頁只被存取一次就從 old 區域移動到了 young 區域,導致原本快取在 young 區域的熱點資料失效
全表掃描有一個特點,就是相同的資料頁在短時間內被頻繁存取
select * from t_user where id >= 1
例如上面這條 SQL,假設 id = 1 這行資料所在的頁號是 page 10,該頁有 10000 條記錄,那麼執行這條 SQL 時會在短時間內對 page 10 掃描 10000 次
老年代時間停留視窗機制
全表掃描之所以會替換淘汰原有的 LRU 連結串列 young 區域資料,主要是因為我們將原本只會存取一次的資料頁載入到 young 區,這些資料實際上剛剛從磁碟被載入到 Buffer Pool,然後就被存取,之後就不會用,基於此,我們是不是可以將資料移動到 young 區的門檻提高有點,從而把這種存取一次就不會用的資料過濾掉,把它停留在 old 區域,這樣就不會汙染 young 區的熱點資料了
我們只需要提前設定一個時間閾值,然後記錄下兩次存取同一個資料頁的時間間隔,如果兩次的時間間隔大於這個閾值,就證明不是全表掃描(全表掃描的特點是相同的資料頁短時間內被頻繁存取)
Mysql 先設定一個間隔時間 innodb_old_blocks_time,然後將 old 區域資料頁的第一次存取時間在其對應的控制塊中記錄下來
如果後續的存取時間與第一次存取的時間小於 innodb_old_blocks_time 則不將該快取頁從 old 區域移動到 young 區域
如果後續的存取時間與第一次存取的時間大於 innodb_old_blocks_time 才會將該快取頁移動到 young 區域的頭部
這樣看,其實這個間隔時間 innodb_old_blocks_time 就是資料頁必須在 old 區域停留的時間,有了這個 old 區域停留機制,那些短時間內被多次存取的頁,並不會立刻插入新生代頭部(完美的避開了全表掃描).而是優先淘汰老年代中短期內僅僅存取了一次的頁
這個老年代時間停留引數,可以通過如下命令檢視,預設值是 1秒
show variables like '%innodb_old_blocks_time%';

所以在 InnoDB 中,只有同時滿足 資料頁被存取 與 資料頁在 old 區域停留時間超過 1 秒 兩個條件,才會被插入到 young 區域頭部
實際上,Mysql 在冷熱分離的基礎上還做了一層更深入的優化
當一個快取頁處於熱資料區域的時候,我們去存取這個快取頁,這個時候我們真的有必要把它移動到 young 區域的頭部嗎?
將連結串列中的資料移動到頭部,實際上就是修改節點的指標指向,這個操作是非常快的,但是為了安全期間,在修改連結串列指標期間,我們需要對連結串列加上鎖,否則會出現並行問題,在並行量大的時候,因為要加鎖,會存在鎖競爭,每次移動顯然效率就會下降,因此 Mysql 針對這一點又做了一層優化
- 如果一個快取頁處於熱資料區域,並且在熱資料區域的前 1/4 區域(注意是熱資料區域的 1/4,而不是整個 LRU 連結串列的 1/4),那麼存取這個快取頁的時候,就不用把它移動到熱資料區域的頭部,
- 如果快取頁處於熱資料的 3/4 區域,那麼存取這個快取頁的時候,會把它移動到熱資料區域的頭部
四、多範例 Buffer Pool
Buffer Pool 本質是 InnoDB 向作業系統申請的一塊連續的記憶體空間,既然是記憶體空間,那麼在多執行緒環境下,為了保證資料安全,存取 Buffer Pool 中的資料都需要 加鎖 處理,當多執行緒並行存取量特別高時,單一個 Buffer Pool 可能會影響請求的處理速度,因此當 Buffer Pool 的記憶體空間很大的時候,可以將單一的 Buffer Pool 拆分成若干個小的 Buffer Pool,每個 Buffer Pool 都稱為一個獨立的範例,各自去申請記憶體空間、分配記憶體空間、管理各種連結串列,以此保證在多執行緒並行存取時不會相互影響,從而提高並行能力
通過設定 innodb_buffer_pool_instances 的值來修改 Buffer Pool 範例的個數,預設為 1,最大可以設定為 64
[server]
innodb_buffer_pool_instances = 2
上面設定標識建立兩個 Buffer Pool 範例(每個 Buffer Pool 的大小為 innodb_buffer_pool_size / 2)
單個 Buffer Pool 實際佔用記憶體空間 = innodb_buffer_pool_size / innodb_buffer_pool_instances
由於管理 Buffer Pool 需要額外的效能開銷,因此 innodb_buffer_pool_instances 的個數並不是越多越好
特別需要注意,在 InnoDB 中,當 innodb_buffer_pool_size 小於 1GB 時,innodb_buffer_pool_instances 無效,即使設定的 innodb_buffer_pool_instances 值不為 1,InnoDB 預設也會把它改為 1,這是需要同時考慮單個 Buffer Pool 大小和多範例管理的效能開銷而作出的選擇
關於 Buffer Pool 的詳細引數可以通過如下命令檢視
show variables like '%innodb_buffer_pool%'
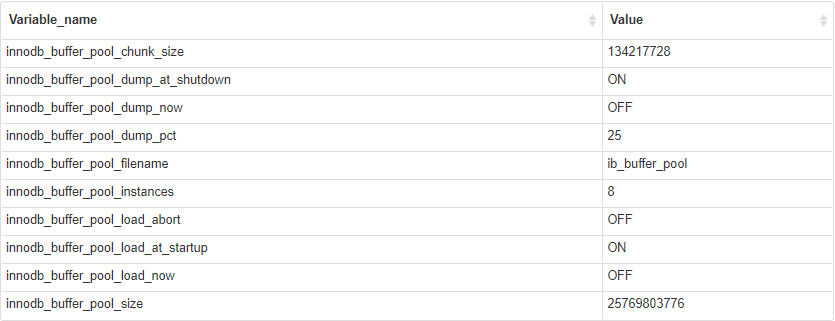
innodb_buffer_pool_chunk_size:指定了 InnoDB 緩衝池記憶體的分配單位大小,預設值為 128MB,表示以 128MB 為單位進行記憶體分配
innodb_buffer_pool_instances:這個引數指定了 InnoDB 緩衝池被劃分為多少個範例,每個範例獨立管理一部分緩衝池記憶體,可以提高並行讀取的效能,建議設定為 CPU 核心數
innodb_buffer_pool_size:指定了 InnoDB 緩衝池的大小,即用於快取資料和索引的記憶體池大小,預設單位是位元組,適當調整此引數可以提高讀取效能,過大或過小都可能導致效能下降