使用 DDPO 在 TRL 中微調 Stable Diffusion 模型
引言
擴散模型 (如 DALL-E 2、Stable Diffusion) 是一類文生圖模型,在生成影象 (尤其是有照片級真實感的影象) 方面取得了廣泛成功。然而,這些模型生成的影象可能並不總是符合人類偏好或人類意圖。因此出現了對齊問題,即如何確保模型的輸出與人類偏好 (如「質感」) 一致,或者與那種難以通過提示來表達的意圖一致?這裡就有強化學習的用武之地了。
在大語言模型 (LLM) 領域,強化學習 (RL) 已被證明是能讓目標模型符合人類偏好的非常有效的工具。這是 ChatGPT 等系統卓越效能背後的主要祕訣之一。更準確地說,強化學習是人類反饋強化學習 (RLHF) 的關鍵要素,它使 ChatGPT 能像人類一樣聊天。
在 Training Diffusion Models with Reinforcement Learning 一文中,Black 等人展示瞭如何利用 RL 來對擴散模型進行強化,他們通過名為去噪擴散策略優化 (Denoising Diffusion Policy Optimization,DDPO) 的方法針對模型的目標函數實施微調。
在本文中,我們討論了 DDPO 的誕生、簡要描述了其工作原理,並介紹瞭如何將 DDPO 加入 RLHF 工作流中以實現更符合人類審美的模型輸出。然後,我們切換到實戰,討論如何使用 trl 庫中新整合的 DDPOTrainer 將 DDPO 應用到模型中,並討論我們在 Stable Diffusion 上執行 DDPO 的發現。
DDPO 的優勢
DDPO 並非解決 如何使用 RL 微調擴散模型 這一問題的唯一有效答案。
在進一步深入討論之前,我們強調一下在對 RL 解決方案進行橫評時需要掌握的兩個關鍵點:
- 計算效率是關鍵。資料分佈越複雜,計算成本就越高。
- 近似法很好,但由於近似值不是真實值,因此相關的錯誤會累積。
在 DDPO 之前,獎勵加權迴歸 (Reward-Weighted Regression,RWR) 是使用強化學習微調擴散模型的主要方法。RWR 重用了擴散模型的去噪損失函數、從模型本身取樣得的訓練資料以及取決於最終生成樣本的獎勵的逐樣本損失權重。該演演算法忽略中間的去噪步驟/樣本。雖然有效,但應該注意兩件事:
- 通過對逐樣本損失進行加權來進行優化,這是一個最大似然目標,因此這是一種近似優化。
- 加權後的損失甚至不是精確的最大似然目標,而是從重新加權的變分界中得出的近似值。
所以,根本上來講,這是一個兩階近似法,其對效能和處理複雜目標的能力都有比較大的影響。
DDPO 始於此方法,但 DDPO 沒有將去噪過程視為僅關注最終樣本的單個步驟,而是將整個去噪過程構建為多步馬爾可夫決策過程 (MDP),只是在最後收到獎勵而已。這樣做的好處除了可以使用固定的取樣器之外,還為讓代理策略成為各向同性高斯分佈 (而不是任意複雜的分佈) 鋪平了道路。因此,該方法不使用最終樣本的近似似然 (即 RWR 的做法),而是使用易於計算的每個去噪步驟的確切似然 ( \(\ell(\mu, \sigma^2; x ) = -\frac{n}{2} \log(2\pi) - \frac{n}{2} \log(\sigma^2) - \frac{1}{2\sigma^2} \sum_ {i=1}^n (x_i - \mu)^2\) )。
如果你有興趣瞭解有關 DDPO 的更多詳細資訊,我們鼓勵你閱讀 原論文 及其 附帶的博文。
DDPO 演演算法簡述
考慮到我們用 MDP 對去噪過程進行建模以及其他因素,求解該優化問題的首選工具是策略梯度方法。特別是近端策略優化 (PPO)。整個 DDPO 演演算法與近端策略優化 (PPO) 幾乎相同,僅對 PPO 的軌跡收集部分進行了比較大的修改。
下圖總結了整個演演算法流程:
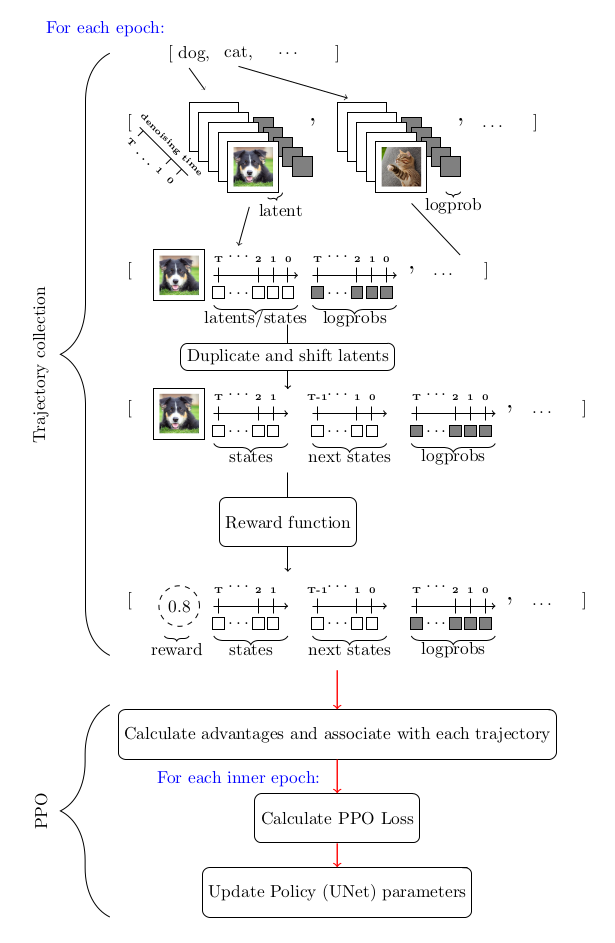
DDPO 和 RLHF: 合力增強美觀性
RLHF 的一般訓練步驟如下:
- 有監督微調「基礎」模型,以學習新資料的分佈。
- 收集偏好資料並用它訓練獎勵模型。
- 使用獎勵模型作為訊號,通過強化學習對模型進行微調。
需要指出的是,在 RLHF 中偏好資料是獲取人類反饋的主要來源。
DDPO 加進來後,整個工作流就變成了:
- 從預訓練的擴散模型開始。
- 收集偏好資料並用它訓練獎勵模型。
- 使用獎勵模型作為訊號,通過 DDPO 微調模型
請注意,DDPO 工作流把原始 RLHF 工作流中的第 3 步省略了,這是因為經驗表明 (後面你也會親眼見證) 這是不需要的。
下面我們實戰一下,訓練一個擴散模型來輸出更符合人類審美的影象,我們分以下幾步來走:
- 從預訓練的 Stable Diffusion (SD) 模型開始。
- 在 美學視覺分析 (Aesthetic Visual Analysis,AVA) 資料集上訓練一個帶有可訓迴歸頭的凍結 CLIP 模型,用於預測人們對輸入影象的平均喜愛程度。
- 使用美學預測模型作為獎勵訊號,通過 DDPO 微調 SD 模型。
記住這些步驟,下面開始幹活:
使用 DDPO 訓練 Stable Diffusion
環境設定
首先,要成功使用 DDPO 訓練模型,你至少需要一個英偉達 A100 GPU,低於此規格的 GPU 很容易遇到記憶體不足問題。
使用 pip 安裝 trl 庫
pip install trl[diffusers]
主庫安裝好後,再安裝所需的訓練過程跟蹤和影象處理相關的依賴庫。注意,安裝完 wandb 後,請務必登入以將結果儲存到個人帳戶。
pip install wandb torchvision
注意: 如果不想用 wandb ,你也可以用 pip 安裝 tensorboard 。
演練一遍
trl 庫中負責 DDPO 訓練的主要是 DDPOTrainer 和 DDPOConfig 這兩個類。有關 DDPOTrainer 和 DDPOConfig 的更多資訊,請參閱 相應檔案。 trl 程式碼庫中有一個 範例訓練指令碼。它預設使用這兩個類,並有一套預設的輸入和引數用於微調 RunwayML 中的預訓練 Stable Diffusion 模型。
此範例指令碼使用 wandb 記錄訓練紀錄檔,並使用美學獎勵模型,其權重是從公開的 Hugging Face 儲存庫讀取的 (因此資料收集和美學獎勵模型訓練均已經幫你做完了)。預設提示資料是一系列動物名。
使用者只需要一個命令列引數即可啟動指令碼。此外,使用者需要有一個 Hugging Face 使用者存取令牌,用於將微調後的模型上傳到 Hugging Face Hub。
執行以下 bash 命令啟動程式:
python stable_diffusion_tuning.py --hf_user_access_token <token>
下表列出了影響微調結果的關鍵超引數:
| 引數 | 描述 | 單 GPU 訓練推薦值(迄今為止) |
|---|---|---|
num_epochs |
訓練 epoch 數 |
200 |
train_batch_size |
訓練 batch size | 3 |
sample_batch_size |
取樣 batch size | 6 |
gradient_accumulation_steps |
梯度累積步數 | 1 |
sample_num_steps |
取樣步數 | 50 |
sample_num_batches_per_epoch |
每個 epoch 的取樣 batch 數 |
4 |
per_prompt_stat_tracking |
是否跟蹤每個提示的統計資訊。如果為 False,將使用整個 batch 的平均值和標準差來計算優勢,而不是對每個提示進行跟蹤 |
True |
per_prompt_stat_tracking_buffer_size |
用於跟蹤每個提示的統計資料的緩衝區大小 | 32 |
mixed_precision |
混合精度訓練 | True |
train_learning_rate |
學習率 | 3e-4 |
這個指令碼僅僅是一個起點。你可以隨意調整超引數,甚至徹底修改指令碼以適應不同的目標函數。例如,可以整合一個測量 JPEG 壓縮度的函數或 使用多模態模型評估視覺文字對齊度的函數 等。
經驗與教訓
- 儘管訓練提示很少,但其結果似乎已經足夠泛化。對於美學獎勵函數而言,該方法已經得到了徹底的驗證。
- 嘗試通過增加訓練提示數以及改變提示來進一步泛化美學獎勵函數,似乎反而會減慢收斂速度,但對模型的泛化能力收效甚微。
- 雖然推薦使用久經考驗 LoRA,但非 LoRA 也值得考慮,一個經驗證據就是,非 LoRA 似乎確實比 LoRA 能產生相對更復雜的影象。但同時,非 LoRA 訓練的收斂穩定性不太好,對超參選擇的要求也高很多。
- 對於非 LoRA 的超參建議是: 將學習率設低點,經驗值是大約
1e-5,同時將mixed_ precision設定為None。
結果
以下是提示 bear 、 heaven 和 dune 微調前 (左) 、後 (右) 的輸出 (每行都是一個提示的輸出):
| 微調前 | 微調後 |
|---|---|
 |
 |
 |
 |
 |
 |
限制
- 目前
trl的DDPOTrainer僅限於微調原始 SD 模型; - 在我們的實驗中,主要關注的是效果較好的 LoRA。我們也做了一些全模型訓練的實驗,其生成的質量會更好,但超參尋優更具挑戰性。
總結
像 Stable Diffusion 這樣的擴散模型,當使用 DDPO 進行微調時,可以顯著提高影象的主觀質感或其對應的指標,只要其可以表示成一個目標函數的形式。
DDPO 的計算效率及其不依賴近似優化的能力,在擴散模型微調方面遠超之前的方法,因而成為微調擴散模型 (如 Stable Diffusion) 的有力候選。
trl 庫的 DDPOTrainer 實現了 DDPO 以微調 SD 模型。
我們的實驗表明 DDPO 對很多提示具有相當好的泛化能力,儘管進一步增加提示數以增強泛化似乎效果不大。為非 LoRA 微調找到正確超參的難度比較大,這也是我們得到的重要經驗之一。
DDPO 是一種很有前途的技術,可以將擴散模型與任何獎勵函數結合起來,我們希望通過其在 TRL 中的釋出,社群可以更容易地使用它!
致謝
感謝 Chunte Lee 提供本博文的縮圖。
英文原文: https://hf.co/blog/trl-ddpo
原文作者: Luke Meyers,Sayak Paul,Kashif Rasul,Leandro von Werra
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態資料上的應用及大規模模型的訓練推理。
審校/排版: zhongdongy (阿東)