這個面試官真煩,問完合併又問拆分。
你好呀,我是歪歪。
這次來盤個小夥伴分享給我的一個面試題,他說面試的過程中面試官的問了一個比較開放的問題:
請談談你對於請求合併和分治的看法。
他覺得自己沒有答的特別好,主要是沒找到合適的角度來答題,跑來問我怎麼看。
我能怎麼看?
我也不知道面試官想問啥角度啊。但是這種開放題,只要回答的不太離譜,應該都能混得過去。
比如,如果你回答一個:我認為合併和分治,這二者之間是辯證的關係,得用辯證的眼光看問題,它們是你中有我,我中有你~
那涼了,拿著簡歷回家吧。

我也想了一下,如果讓我來回答這個問題,我就用這篇文章來回答一下。
有廣義上的實際應用場景,也有狹義上的原始碼體現對應的思想。
讓面試官自己挑吧。

鋪墊一下
首先回答之前肯定不能幹聊,所以我們鋪墊一下,先帶入一個場景:熱點賬戶。
什麼是熱點賬戶呢?
在第三方支付系統或者銀行這類交易機構中,每產生一筆轉入或者轉出的交易,就需要對交易涉及的賬戶進行記賬操作。
記賬粗略的來說涉及到兩個部分。
交易系統記錄這一筆交易的資訊。 賬戶系統需要增加或減少對應的賬戶餘額。
如果對於某個賬戶操作非常的頻繁,那麼當我們對賬戶餘額進行操作的時候,肯定就會涉及到並行處理的問題。
並行了怎麼辦?
我們可以對賬戶進行加鎖處理嘛。但是這樣一來,這個賬戶就涉及到頻繁的加鎖解鎖操作。
雖然這樣我們可以保證資料不出問題,但是隨之帶來的問題是隨著並行的提高,賬戶系統效能下降。
極少數的賬戶在短時間內出現了極大量的餘額更新請求,這類賬戶就是熱點賬戶,就是效能瓶頸點。
熱點賬戶是業界的一個非常常見的問題。
而且根據熱點賬戶的特性,也可以分為不同的型別。
如果餘額的變動是在頻繁的增加,比如頭部主播帶貨,只要一喊 321,上連結,那訂單就排山倒海的來了,錢就一筆筆的打到賬戶裡面去了。這種賬戶,就是非常多的人在給這個賬戶打款,頻率非常高,賬戶餘額一直在增加。
這種賬戶叫做「加餘額頻繁的熱點賬戶」。
如果餘額的變動是在頻繁的減少,比如常見的某流量平臺廣告位曝光,這種屬於扣費場景。
商家先充值一筆錢到平臺上,然後平臺給商家一頓咔咔曝光,接著賬戶上的錢就像是流水一樣嘩啦啦啦的就沒了。
這種預充值,然後再扣減頻繁的賬戶,這種賬戶叫做「減餘額頻繁的熱點賬戶」。
還有一種,是加餘額,減餘額都很頻繁的賬戶。
你細細的嗦一下,什麼賬戶一邊加一遍減呢,怎麼感覺像是個二手販子在左手倒右手呢?
這種賬戶一般不能細琢磨,琢磨多了,就有點灰色地帶了,點到為止。

先說請求合併
針對「加餘額頻繁的熱點賬戶」我們就可以採取請求合併的思路。
假設有個歪師傅是個正經的帶貨主播,在直播間穿著女裝賣女裝,我只要喊「321,上連結」姐妹們就開始衝了。

隨著歪師傅生意越來越好,有的姐妹們就反饋下單越來越慢。
後來一分析,哦,原來是更新賬戶餘額那個地方是個效能瓶頸,大量的單子都在這裡排著隊,等著更新餘額。
怎麼辦呢?
針對這種情況,我們就可以把多筆調整賬務餘額的請求合併成一筆處理。
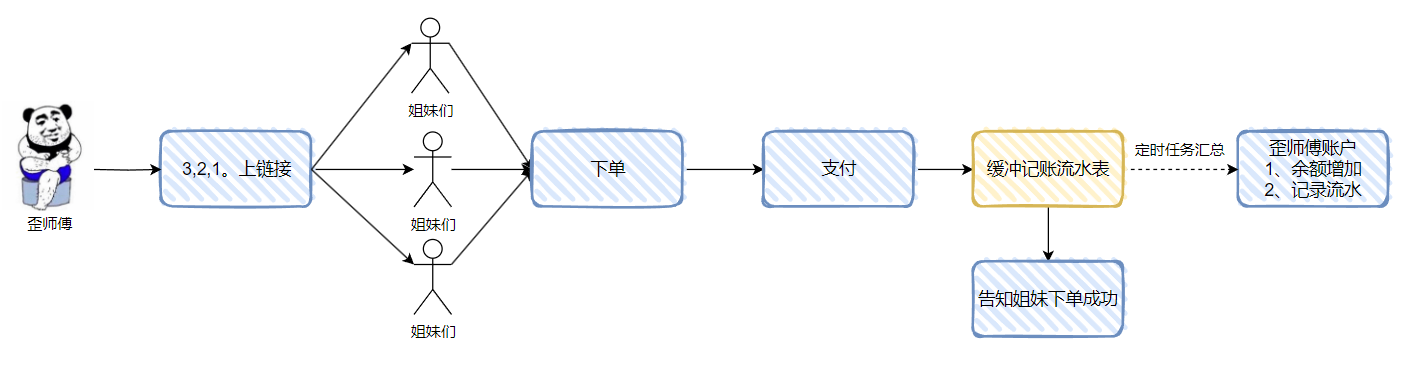
當記錄進入緩衝流水記錄表之後,我就可以告知姐妹下單成功了,雖然錢還沒有真的到我的賬戶中來,但是你放心,有定時任務保證,錢一會就到賬。
所以當姐妹們下單之後,我們只是先記錄資料,並不去實際動賬戶。等著定時任務去觸發記賬,進行多筆合併一筆的操作。
比如下面的這個示意圖:

對於歪師傅來說,實際有 6 個姐妹的支付記錄,但是隻有一次餘額調整。
而我拿著這一次餘額調整的賬戶流水,也是可以追溯到這 6 筆交易記錄的詳情。
這樣的好處是吞吐量上來了,使用者體驗也好了。但是帶來的弊端是餘額並不是一個準確的值。
假設我們的定時任務是一小時彙總一次,那麼歪師傅在後端看到的交易金額可能是一小時之前的資料。
但是歪師傅覺得沒關係,總比姐妹們下不了單強。

如果我們把緩衝流水記錄表看作是一個佇列。那麼這個方案抽象出來就是佇列加上定時任務。
所以,請求合併的關鍵點也是佇列加上定時任務。
除了我上面的例子外,比如還有 redis 裡面的 mget,資料庫裡面的批次插入,這玩意不就是一個請求合併的真實場景嗎?
比如 redis 把多個 get 合併起來,然後呼叫 mget。多次請求合併成一次請求,節約的是網路傳輸時間。
還有真實的案例是轉賬的場景,有的轉賬渠道是按次收費的,那麼作為第三方公司,我們就可以把使用者的請求先放到表裡記錄著,等一小時之後,一起彙總發起,假設這一小時內發生了 10 次轉賬,那麼 10 次收費就變成了 1 次收費,雖然讓客戶等的稍微久了點,但還是在可以接受的範圍內,這操作節約的就是真金白銀了。
請求合併,說穿了,就這麼一點事兒,一點也不復雜。
那麼如果我在請求合併的前面,加上「高並行」這三個字...

首先不論是在請求合併的前面加上多麼狂拽炫酷吊炸天的形容詞,說的多麼的天花亂墜,它也還是一個請求合併。
那麼佇列和定時任務的這個基礎結構肯定是不會變的。
高並行的情況下,就是請求量非常的大嘛,那我們把定時任務的頻率調高一點不就行了?
以前 100ms 內就會過來 50 筆請求,我每收到一筆就是立即處理了。
現在我們把請求先放到佇列裡面快取著,然後每 100ms 就執行一次定時任務。
100ms 到了之後,就會有定時任務把這 100ms 內的所有請求取走,統一處理。
同時,我們還可以控制佇列的長度,比如只要 50ms 佇列的長度就達到了 50,這個時候我也進行合併處理。不需要等待到 100ms 之後。
其實寫到這裡,高並行的請求合併的答案已經出來了。
關鍵點就三個:
一是需要藉助佇列加定時任務實現。 二是控制定時任務的執行時間. 三是控制緩衝佇列的任務長度。
方案都想到了,把程式碼寫出來豈不是很容易的事情。而且對於這種面試的場景圖,一般都是討論技術方案,而不太會去討論具體的程式碼。
當討論到具體的程式碼的時候,要麼是對你的方案存疑,想具體的探討一下落地的可行性。要麼就是你答對了,他要準備從程式碼的交易開始衍生另外的面試題了。
總之,大部分情況下,不會在你給了一個面試官覺得錯誤的方案之後,他還和你討論程式碼細節。你們都不在一個頻道了,趕緊換題吧,還聊啥啊。
實在要往程式碼實現上聊,那麼大概率他是在等著你說出一個框架:Hystrix。
其實這題,你要是知道 Hystrix,很容易就能給出一個比較完美的回答。
因為 Hystrix 就有請求合併的功能。
通過一個實際的例子,給大家演示一下。
假設我們有一個學生資訊查詢介面,呼叫頻率非常的高。對於這個介面我們需要做請求合併處理。
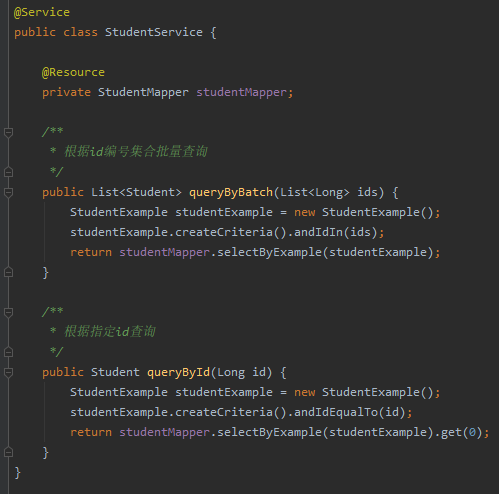
做請求合併,我們至少對應著兩個介面,一個是接收單個請求的介面,一個處理把單個請求彙總之後的請求介面。
所以我們需要先提供兩個 service:
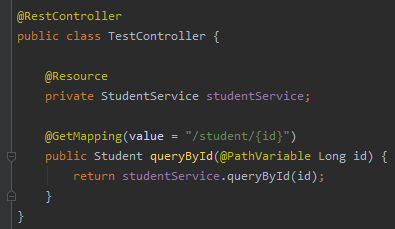
其中根據指定 id 查詢的介面,對應的 Controller 是這樣的:
服務啟動起來後,我們用執行緒池結合 CountDownLatch 模擬 20 個並行請求:
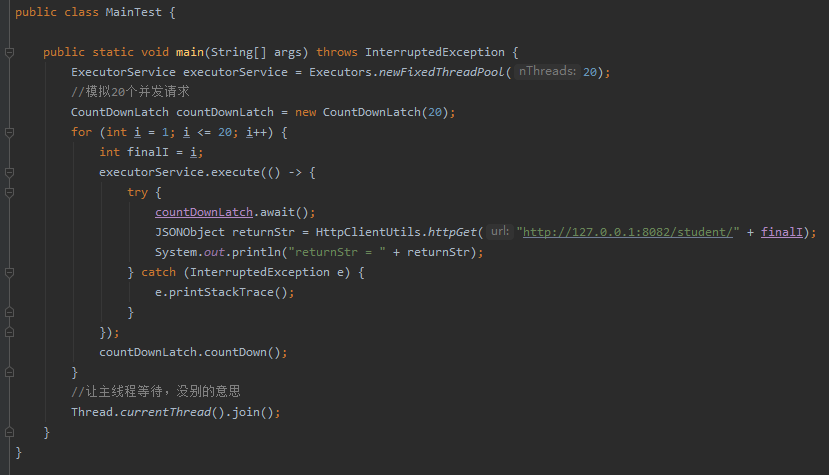
從控制檯可以看到,瞬間接受到了 20 個請求,執行了 20 次查詢 sql:
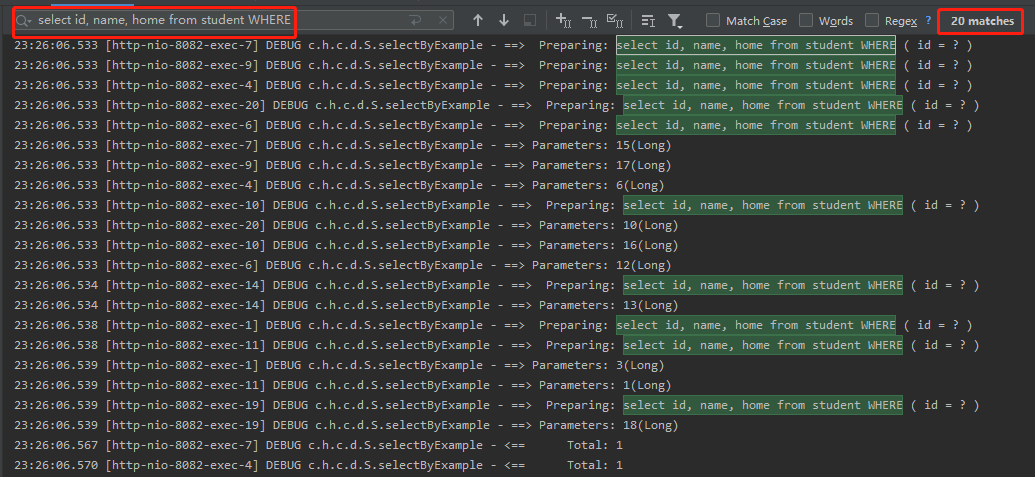
很明顯,這個時候我們就可以做請求合併。每收到 10 次請求,合併為一次處理,結合 Hystrix 程式碼就是這樣的,為了程式碼的簡潔性,我採用的是註解方式:
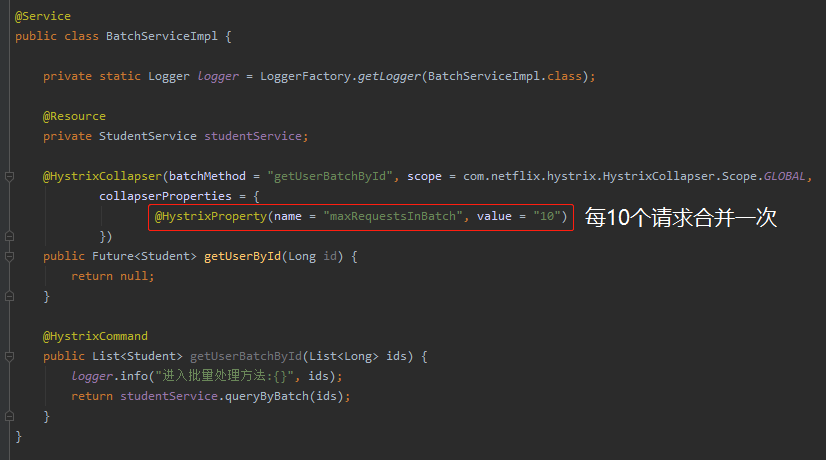
在上面的圖片中,有兩個方法,一個是 getUserId,直接返回的是null,因為這個方法體不重要,根本就不會執行。
在 @HystrixCollapser 裡面可以看到有一個 batchMethod 的屬性,其值是 getUserBatchById。
也就是說這個方法對應的批次處理方法就是 getUserBatchById。當我們請求 getUserById 方法的時候,Hystrix 會通過一定的邏輯,幫我們轉發到 getUserBatchById 上。
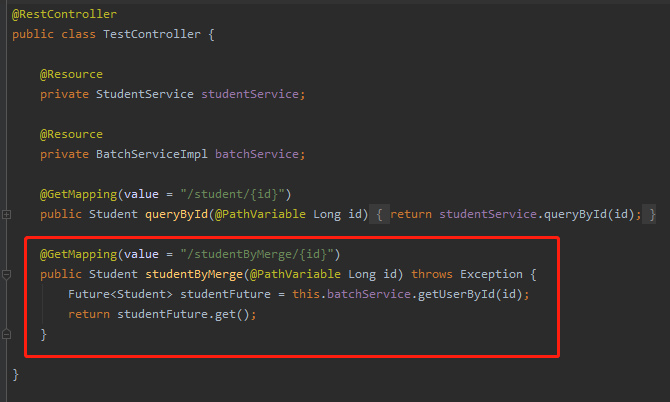
所以我們呼叫的還是 getUserById 方法:
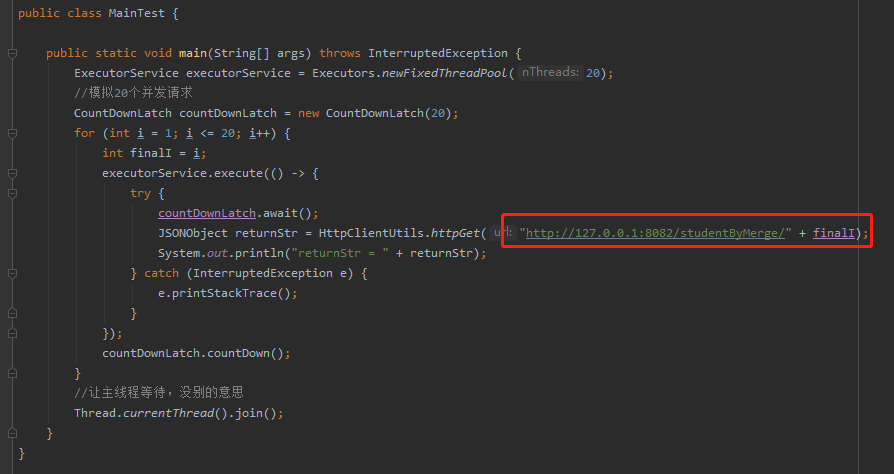
同樣,我們用執行緒池結合 CountDownLatch 模擬 20 個並行請求,只是變換了請求地址:
呼叫之後,神奇的事情就出現了,我們看看紀錄檔:

同樣是接受到了 20 個請求,但是每 10 個一批,只執行了兩個sql語句。
從 20 個 sql 到 2 個 sql,這就是請求合併的威力。請求合併的處理速度甚至比單個處理還快,這也是效能的提升。
那假設我們只有 5 個請求過來,不滿足 10 個這個條件呢?
別忘了,我們還有定時任務呢。
在 Hystrix 中,定時任務預設是每 10ms 執行一次:
同時我們可以看到,如果不設定 maxRequestsInBatch,那麼預設是 Integer.MAX_VALUE。
也就是說,在 Hystrix 中做請求合併,它更加側重的是時間方面。
功能演示,其實就這麼簡單,程式碼量也不多,有興趣的朋友可以直接搭個 Demo 跑跑看。看看 Hystrix 的原始碼。
我這裡只是給大家指幾個關鍵點吧。
第一個肯定是我們需要找到方法入口。
你想,我們的 getUserById 方法的方法體裡面直接是 return null,也就是說這個方法體是什麼根本就不重要,因為不會去執行方法體中的程式碼。它只需要攔截到方法入參,並快取起來,然後轉發到批次方法中去即可。
然後方法體上面有一個 @HystrixCollapser 註解。
那麼其對應的實現方式你能想到什麼?
肯定是 AOP 了嘛。
所以,我們拿著這個註解的全路徑,進行搜尋,啪的一下,很快啊,就能找到方法的入口:
com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect#methodsAnnotatedWithHystrixCommand
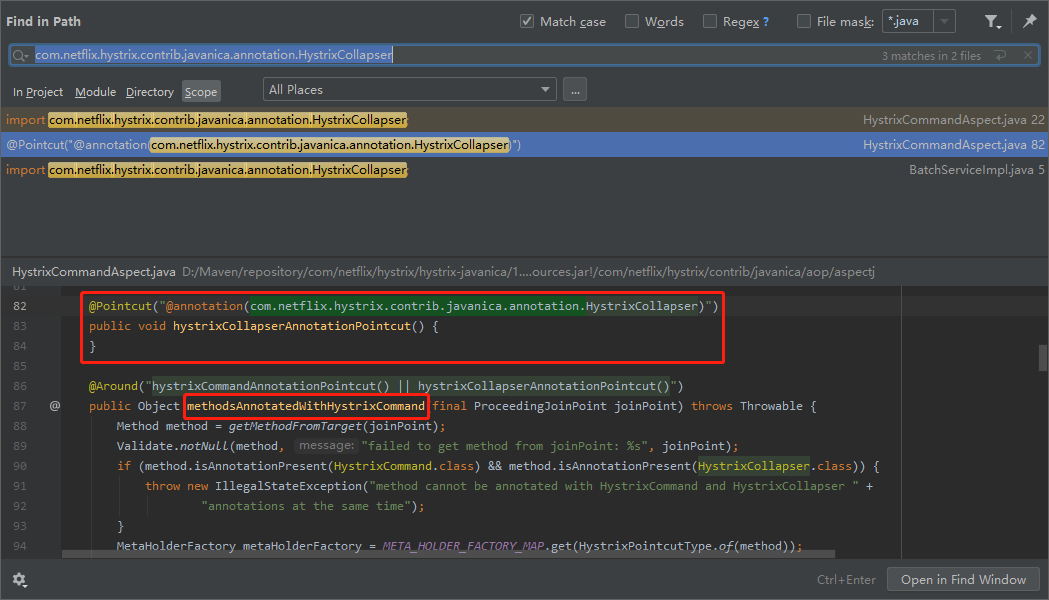
在入口處打上斷點,就可以開始偵錯了:
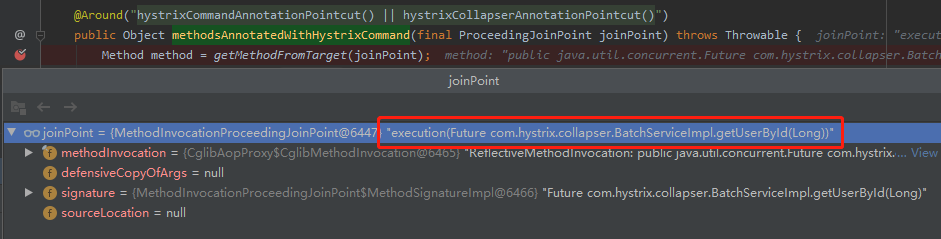
第二個我們看看定時任務是在哪兒進行註冊的。
這個就很好找了。我們已經知道預設引數是 10ms 了,只需要順著鏈路看一下,哪裡的程式碼呼叫了其對應的 get 方法即可:
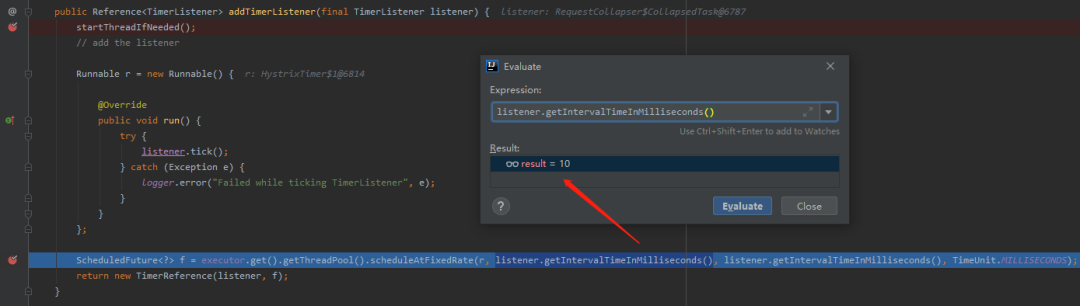
同時,我們可以看到,其定時功能是基於 scheduleAtFixedRate 實現的。
第三個我們看看是怎麼控制超過指定數量後,就不等待定時任務執行,而是直接發起彙總操作的:

可以看到,在com.netflix.hystrix.collapser.RequestBatch#offer方法中,當 argumentMap 的 size 大於我們指定的 maxBatchSize 的時候返回了 null。
如果,返回為 null ,那麼說明已經不能接受請求了,需要立即處理,程式碼裡面的註釋也說的很清楚了:
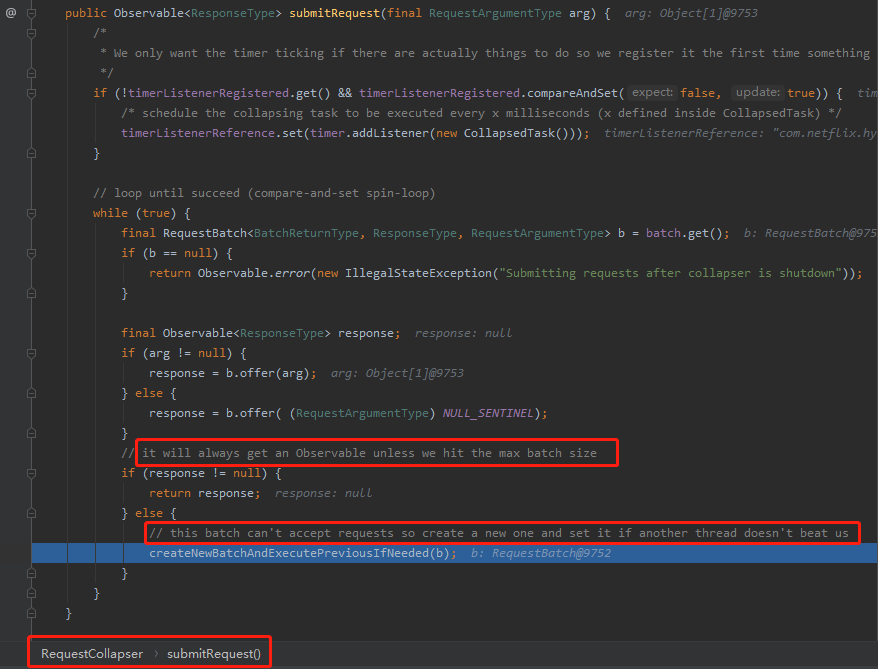
以上就是三個關鍵的地方,Hystrix 的原始碼讀起來,需要下點功夫,大家自己研究的時候需要做好心理準備。
最後再貼一個官方的請求合併工作流程圖:
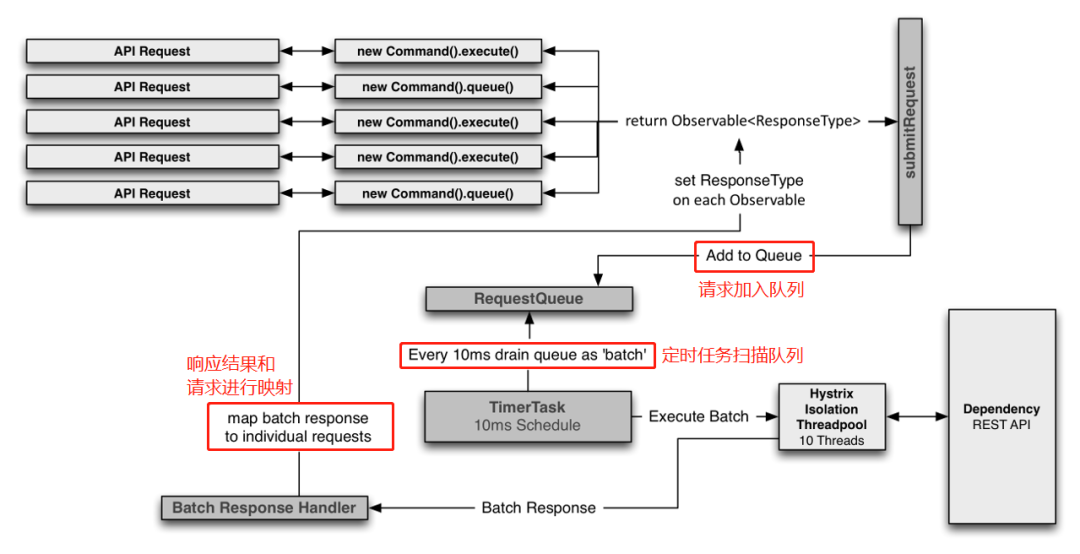
再說請求分治
還是回到最開始我們提出的熱點賬戶問題中的「減餘額頻繁的熱點賬戶」。
請求分治和請求合併,就是針對「熱點賬戶」這同一個問題的完全不同方向的兩個回答。
分治,它的思想是拆分。
再說拆分之前,我們先聊一個更熟悉的東西:AtomicLong。
AtomicLong,這玩意是可以實現原子性的增減操作,但是當競爭非常大的時候,被操作的「值」就是一個熱點資料,所有執行緒都要去對其進行爭搶,導致並行修改時衝突很大。
那麼 AtomicLong 是靠什麼解決這個衝突的呢?
看一下它的 getAndAdd 方法:
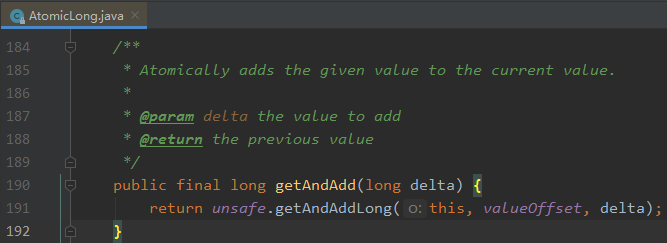
可以看到這裡面還是有一個 do-while 的迴圈:
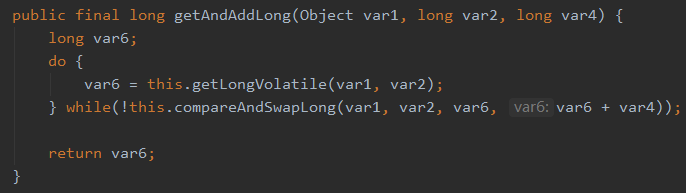
裡面呼叫了 compareAndSwapLong 方法。
do-while,就是自旋。
compareAndSwapLong,就是 CAS。
所以 AtomicLong 靠的是自旋 CAS 來解決競爭大的時候的這個衝突。
你看這個場景,是不是和我們開篇提到的熱點賬戶有點類似?
熱點賬戶,在並行大的時候我們可以對賬戶進行加鎖操作,讓其他請求進行排隊。
而它這裡用的是 CAS,一種樂觀鎖的機制。
但是也還是要排隊,不夠優雅。
什麼是優雅的?
LongAdder 是優雅的。
有點小夥伴就有點疑問了:歪師傅,不是要講熱點賬戶嗎,怎麼扯到 LongAdder 上了呢?
閉嘴,往下看就行了。

首先,我們先看一下官網上的介紹:

上面的截圖一共兩段話,是對 LongAdder 的簡介,我給大家翻譯並解讀一下。

首先第一段:當有多執行緒競爭的情況下,有個叫做變數集合(set of variables)的東西會動態的增加,以減少競爭。
sum 方法返回的是某個時刻的這些變數的總和。
所以,我們知道了它的返回值,不論是 sum 方法還是 longValue 方法,都是那個時刻的,不是一個準確的值。
意思就是你拿到這個值的那一刻,這個值其實已經變了。
這點是非常重要的,為什麼會是這樣呢?
我們對比一下 AtomicLong 和 LongAdder 的自增方法就可以知道了:
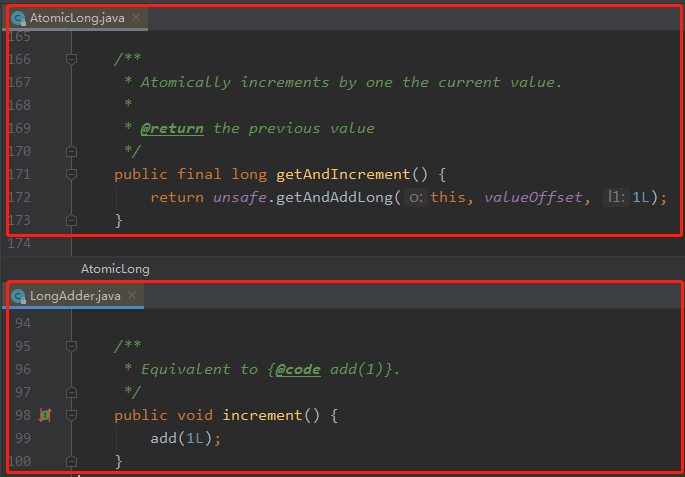
AtomicLong 的自增是有返回值的,就是一個這次呼叫之後的準確的值,這是一個原子性的操作。
LongAdder 的自增是沒有返回值的,你要獲取當前值的時候,只能呼叫 sum 方法。
你想這個操作:先自增,再獲取值,這就不是原子操作了。
所以,當多執行緒並行呼叫的時候,sum 方法返回的值必定不是一個準確的值。除非你加鎖。
該方法上的說明也是這樣的:

至於為什麼不能返回一個準確的值,這就是和它的設計相關了,這點放在後面去說。

然後第二段:當在多執行緒的情況下對一個共用資料進行更新(寫)操作,比如實現一些統計資訊類的需求,LongAdder 的表現比它的老大哥 AtomicLong 表現的更好。在並行不高的時候,兩個類都差不多。但是高並行時 LongAdder 的吞吐量明顯高一點,它也佔用更多的空間。這是一種空間換時間的思想。
這段話其實是接著第一段話在進行描述的。
因為它在多執行緒並行情況下,沒有一個準確的返回值,所以當你需要根據返回值去搞事情的時候,你就要仔細思考思考,這個返回值你是要精準的,還是大概的統計類的資料就行。
比如說,如果你是用來做序號生成器,所以你需要一個準確的返回值,那麼還是用 AtomicLong 更加合適。
如果你是用來做計數器,這種寫多讀少的場景。比如介面存取次數的統計類需求,不需要時時刻刻的返回一個準確的值,那就上 LongAdder 吧。
總之,AtomicLong 是可以保證每次都有準確值,而 LongAdder 是可以保證最終資料是準確的。高並行的場景下 LongAdder 的寫效能比 AtomicLong 高。
接下來探討三個問題:
LongAdder 是怎麼解決多執行緒操作熱點 value 導致並行修改衝突很大這個問題的? 為什麼高並行場景下 LongAdder 的 sum 方法不能返回一個準確的值? 為什麼高並行場景下 LongAdder 的寫效能比 AtomicLong 高?
先帶你上個圖片,看不懂沒有關係,先有個大概的印象:
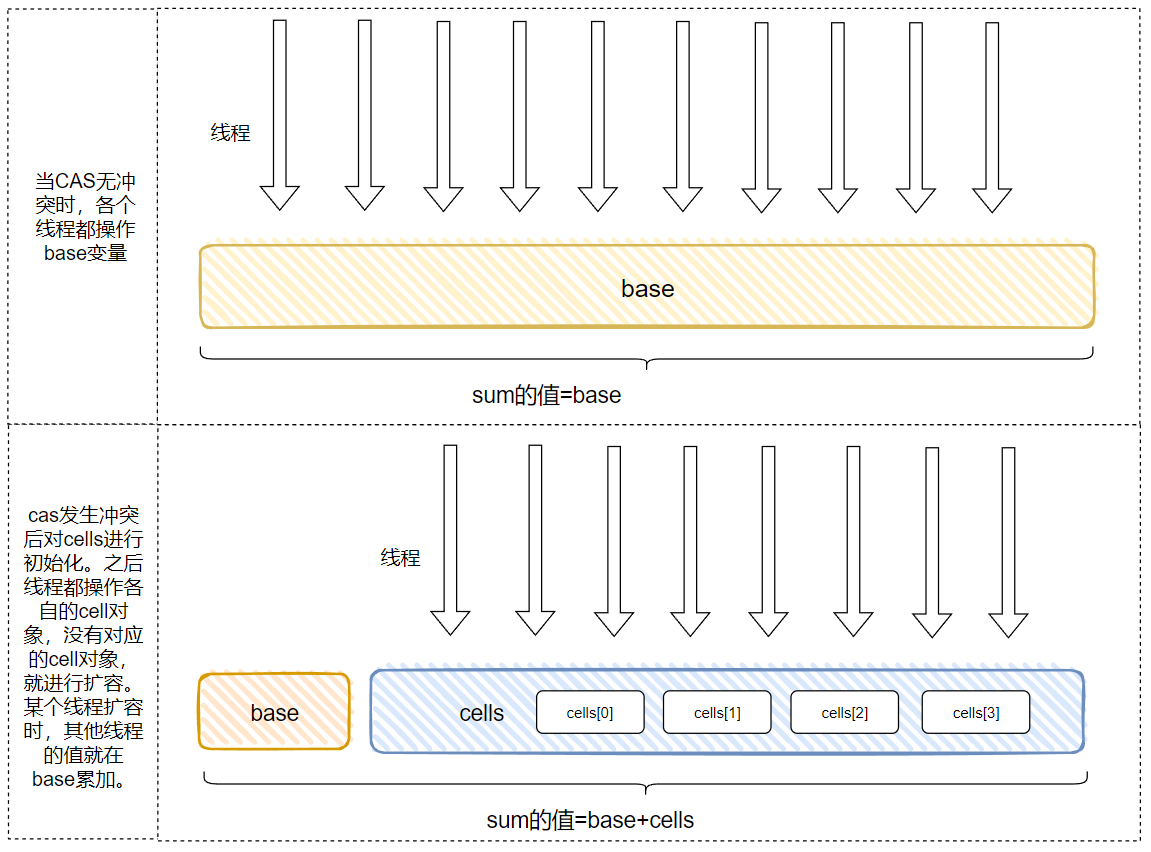
接下來我們就去探索原始碼,原始碼之下無祕密。
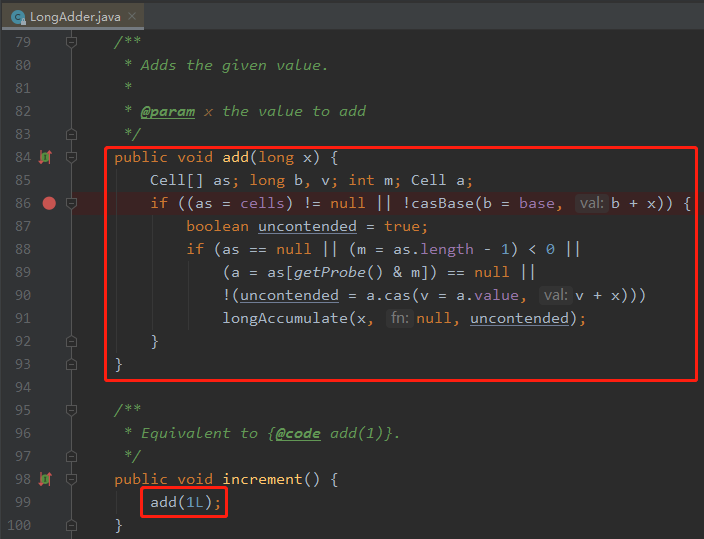
從原始碼我們可以看到 add 方法是關鍵:
裡面有 cells 、base 這樣的變數,所以在解釋 add 方法之前,我們先看一下 這幾個成員變數。
這幾個變數是 Striped64 裡面的。
LongAdder 是 Striped64 的子類:

其中的四個變數如下:
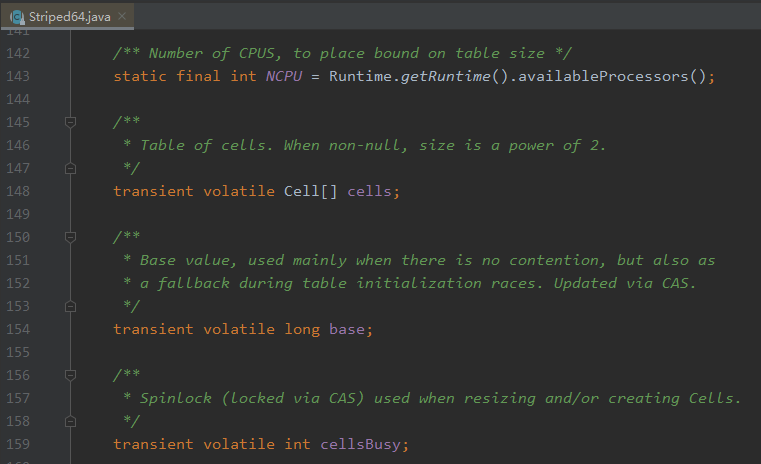
NCPU:cpu 的個數,用來決定 cells 陣列的大小。 cells:一個陣列,當不為 null 的時候大小是 2 的次冪。裡面放的是 cell 物件。 base : 基數值,當沒有競爭的時候直接把值累加到 base 裡面。還有一個作用就是在 cells 初始化時,由於 cells 只能初始化一次,所以其他競爭初始化操作失敗執行緒會把值累加到 base 裡面。 cellsBusy:當 cells 在擴容或者初始化的時候的鎖標識。
之前,檔案裡面說的 set of variables 就是這裡的 cells。

好了,我們再回到 add 方法裡面:
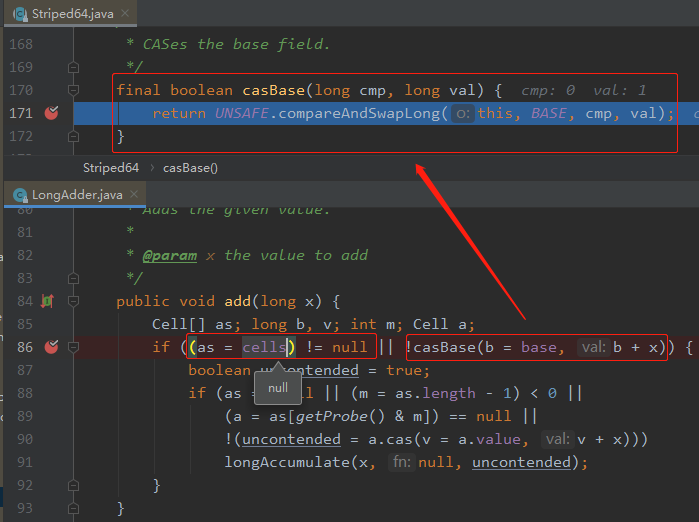
cells 沒有被初始化過,說明是第一次呼叫或者競爭不大,導致 CAS 操作每次都是成功的。
casBase 方法就是進行 CAS 操作。
當由於競爭激烈導致 casBase 方法返回了 false 後,進入 if 分支判斷。
這個 if 分子判斷有 4 個條件,做了 3 種情況的判斷
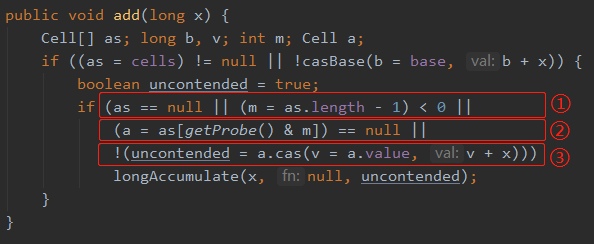
標號為 ① 的地方是再次判斷 cells 陣列是否為 null 或者 size 為 0 。as 就是 cells 陣列。 標號為 ② 的地方是判斷當前執行緒對 cells 陣列大小取模後的值,在 cells 陣列裡面是否能取到 cell 物件。 標號為 ③ 的地方是對取到的 cell 物件進行 CAS 操作是否能成功。
這三個操作的含義為:當 cells 陣列裡面有東西,並且通過 getProbe() & m算出來的值,在 cells 陣列裡面能取到東西(cell)時,就再次對取到的 cell 物件進行 CAS 操作。
如果不滿足上面的條件,則進入 longAccumulate 函數。
這個方法主要是對 cells 陣列進行操作,你想一個陣列它可以有三個狀態:未初始化、初始化中、已初始化,所以下面就是對這三種狀態的分別處理:

標號為 ① 的地方是 cells 已經初始化過了,那麼這個裡面可以進行在 cell 裡面累加的操作,或者擴容的操作。 標號為 ② 的地方是 cells 沒有初始化,也還沒有被加鎖,那就對 cellsBusy 標識進行 CAS 操作,嘗試加鎖。加鎖成功了就可以在這裡面進行一些初始化的事情。 標號為 ③ 的地方是 cells 正在進行初始化,這個時候就在 base 基數上進行 CAS 的累加操作。
上面三步是在一個死迴圈裡面的。
所以如果 cells 還沒有進行初始化,由於有鎖的標誌位,所以就算並行非常大的時候一定只有一個執行緒去做初始化 cells 的操作,然後對 cells 進行初始化或者擴容的時候,其他執行緒的值就在 base 上進行累加操作。
上面就是 sum 方法的工作過程。
感受到了嗎,其實這就是一個分段操作的思想,不知道你有沒有想到 ConcurrentHashMap,也不奇怪,畢竟這兩個東西都是 Doug Lea 寫的。
總的來說,就是當沒有衝突的時候 LongAdder 表現的和 AtomicLong 一樣。當有衝突的時候,才是 LongAdder 表現的時候,然後我們再回去看這個圖,就能明白怎麼回事了:
好了,現在我們回到前面提出的三個問題:
LongAdder 是怎麼解決多執行緒操作熱點 value 導致並行修改衝突很大這個問題的? 為什麼高並行場景下 LongAdder 的 sum 方法不能返回一個準確的值? 為什麼高並行場景下 LongAdder 的寫效能比 AtomicLong 高?
它們其實是一個問題。
因為 LongAdder 把熱點 value 拆分了,放到了各個 cell 裡面去操作。這樣就相當於把衝突分散到了 cell 裡面。所以解決了並行修改衝突很大這個問題。
當發生衝突時 sum= base+cells。高並行的情況下當你獲取 sum 的時候,cells 極有可能正在被其他的執行緒改變。一個在高並行場景下實時變化的值,你要它怎麼給你個準確值?
當然,你也可以通過加鎖操作拿到當前的一個準確值,但是這種場景你還用啥 LongAdder,是 AtomicLong 不香了嗎?
為什麼高並行場景下 LongAdder 的寫效能比 AtomicLong 高?
你發動你的小腦殼想一想,朋友。
AtomicLong 不管有沒有衝突,它寫的都是一個共用的 value,有衝突的時候它就在自旋。
LongAdder 沒有衝突的時候表現的和 AtomicLong 一樣,有衝突的時候就把衝突分散到各個 cell 裡面了,衝突分散了,寫的當然更快了。
我強調一次:有衝突的時候就把衝突分散到各個 cell 裡面了,衝突分散了,寫的當然更快了。
你注意這句話裡面的「各個 cell」。
這是什麼?
這個東西本質上就是 sum 值的一部分。
如果用熱點賬戶去套的話,那麼「各個 cell」就是熱點賬戶下的影子賬戶。
熱點賬戶說到底還是一個單點問題,那麼對於單點問題,我們用微服務的思想去解決的話是什麼方案?
就是拆分。
假設這個熱點賬戶上有 100w,我設立 10 個影子賬戶,每個賬戶 10w ,那麼是不是我們的流量就分散了?
從一個賬戶變成了 10 個賬戶,壓力也就進行了分攤。
但是同時帶來的問題也很明顯。
比如,獲取賬戶餘額的時候需要把所有的影子賬戶進行彙總操作。但是每個影子賬戶上的餘額是時刻在變化的,所以我們不能保證餘額是一個實時準確的值。
但是相比於下單的量來說,大部分商戶並不關心「賬上的實時餘額」這個點。
他只關心上日餘額是準確的,每日對賬都能對上就行了。
這就是分治。
其實我淺顯的覺得分散式、高並行都是基於分治,或者拆分思想的。
本文的 LongAdder 就不說了。
微服務化、分庫分表、讀寫分離......這些東西都是在分治,在拆分,把集中的壓力分散開來。
這就算是我對於「請求合併和分治」的理解、
好了,到這裡本文就算是結束了。
針對"熱點賬戶"這同一個問題,細化了問題方向,定義了加餘額頻繁和減餘額頻繁的兩種熱點賬戶,然後給出了兩個完全不同方向的回答。
這個時候,我就可以把文章開頭的那句話拿出來說了:
綜上,我認為合併和分治,這二者之間是辯證的關係,得用辯證的眼光看問題,它們是你中有我,我中有你~
