記憶體與CPU:計算機默契互動的關鍵解析
記憶體
記憶體和CPU之間的互動是電腦架構中至關重要的一部分。它們之間的互動類似於一對不可分割的愛侶,彼此相互依賴且密不可分。沒有記憶體,CPU無法執行程式指令,這樣計算機就會變得毫無意義。同樣地,如果只有記憶體而沒有能夠執行指令的CPU,計算機也無法正常執行。
總而言之,記憶體和CPU之間的互動是計算機正常執行的基礎,它們相互依賴,共同完成計算機的各種任務。通過匯流排進行資料傳輸,以及通過快取機制提高資料的存取速度,記憶體和CPU實現了高效的共同作業,使計算機能夠快速、準確地執行各種指令和操作。
記憶體的物理結構
在掌握一個事物的理解之前,先要有所接觸,這樣才能形成印象,進而產生對其瞭解的興趣。因此,為了更好地理解記憶體以及其物理結構,我們首先需要先觀察並認識什麼是記憶體以及它的具體構成。

為了更深入地瞭解記憶體以及其物理結構,我們需要了解記憶體的組成。記憶體內部由各種積體電路(IC)電路組成,其中有幾種主要的記憶體型別。
首先是隨機記憶體(RAM),這是記憶體中最重要的一種。RAM既可以讀取資料,也可以寫入資料。然而,當機器關閉時,記憶體中的資訊會丟失。
其次是唯讀記憶體(ROM),ROM通常只用於資料的讀取,無法寫入資料。但是當機器停電時,這些資料不會丟失。
還有一種常見的記憶體是快取記憶體(Cache),它分為一級快取(L1 Cache)、二級快取(L2 Cache)和三級快取(L3 Cache)。快取記憶體位於記憶體和CPU之間,是一個讀寫速度比記憶體更快的記憶體。當CPU向記憶體寫入資料時,這些資料也會被寫入快取記憶體中。當CPU需要讀取資料時,會直接從快取記憶體中讀取。當然,如果需要的資料在快取中不存在,CPU會再去讀取記憶體中的資料。
記憶體積體電路是一個完整的結構,它內部還包括電源、地址訊號、資料訊號、控制訊號以及用於定址的IC引腳,這些都是用於資料的讀寫操作。下面是一個虛擬的IC引腳示意圖。
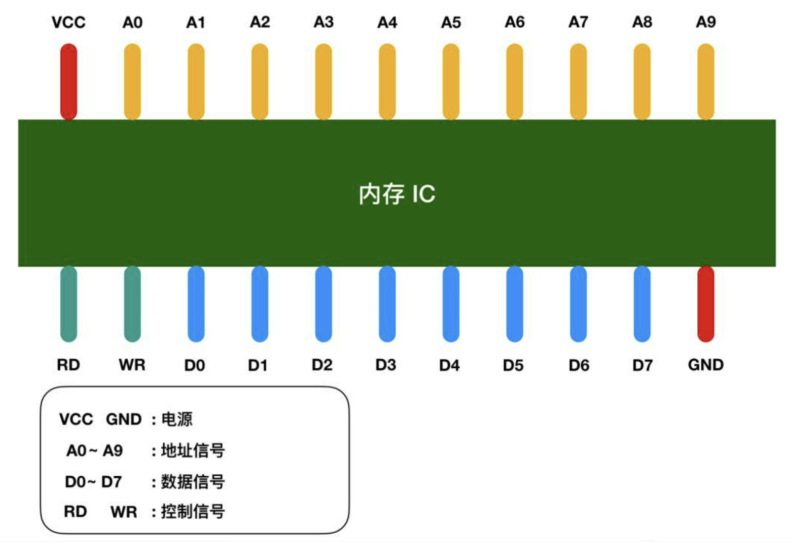
在圖中,VCC和GND代表電源,A0-A9是地址訊號引腳,D0-D7代表資料訊號,RD和WR是控制訊號。我用不同顏色對它們進行了區分。將電源連線到VCC和GND後,其他引腳可以傳遞0和1的訊號。通常情況下,+5V表示1,0V表示0。
我們都知道記憶體用於儲存資料。那麼這個記憶體IC中可以儲存多少資料呢?D0-D7代表資料訊號,也就是說,一次可以輸入輸出8位元(1位元組)的資料。A0-A9是10個地址訊號,可以指定00000 00000到11111 11111共1024個地址。每個地址存放1位元組的資料,因此我們可以得出記憶體IC的容量為1KB。
記憶體的讀寫過程
讓我們把關注點放在記憶體 IC 對資料的讀寫過程上來吧!讓我們來看一個模型,它展示了對記憶體 IC 進行資料寫入和讀取的過程。

為了詳細描述這個過程,假設我們想要向記憶體 IC 中寫入 1byte 的資料。下面是這個過程的詳細步驟:
- 首先,將 VCC 連線到 +5V 的電源,將 GND 連線到 0V 的電源。
- 使用 A0 - A9 來指定資料的儲存位置。
- 輸入資料的值到 D0 - D7 的資料訊號線。
- 將 WR(寫入)訊號置為1,表示執行寫入操作。
- 執行完上述操作後,資料將被寫入記憶體 IC。
要讀取資料,只需要執行以下步驟:
- 通過 A0 - A9 的地址訊號指定要讀取資料的儲存位置。
- 將 RD(讀取)訊號置為1,表示執行讀取操作。
圖中的 RD 和 WR 也被稱為控制訊號。當 WR 和 RD 都為 0 時,無法進行寫入和讀取操作。
記憶體的現實模型
為了更好地理解和記憶,我們可以將記憶體模型對映成現實世界中的樓房模型。想象一下,這個樓房代表記憶體,每一層樓可以儲存一個位元組的資料。樓層的編號就對應記憶體的地址。下面是一個將記憶體和樓層整合的模型圖,讓我們更好地理解記憶體的工作原理。

我們知道,程式中的資料不僅僅是數值,還有資料型別的概念。從記憶體的角度來看,每個資料型別在記憶體中佔用的空間大小可以看作是樓層數。即使在物理層面上,我們以位元組為單位來逐一讀寫記憶體資料,但在程式中,通過指定資料型別,我們可以實現以特定位元組數為單位進行讀寫。
下面是一個範例程式,演示瞭如何以特定位元組數為單位來讀寫指令位元組:
// 定義變數
char a;
short b;
long c;
// 變數賦值
a = 123;
b = 123;
c = 123;
我們分別宣告了三個變數 a, b, c,並給每個變數賦值為相同的 123。這三個變數代表了記憶體中的特定區域。通過使用變數,即使不指定實體地址,我們也可以直接進行讀寫操作,因為作業系統會自動為變數分配記憶體地址。
這三個變數分別表示 1 個位元組長度的 char,2 個位元組長度的 short,和 4 個位元組長度的 long。雖然這三個變數儲存的資料都是 123,但它們在記憶體中所佔的空間大小是不同的。

在這個例子中,我們使用了低位元組序列的方式將資料儲存在記憶體中。這意味著資料的低位儲存在記憶體的低位地址,而高位則儲存在記憶體的高位地址。對於short和long型別的資料,由於123沒有超過每個型別的最大長度,所以除了佔用的記憶體空間外,其餘的記憶體空間都被分配為0。這是因為作業系統會自動為變數分配記憶體地址,並且不同的資料型別在記憶體中佔用的空間大小是不同的。
記憶體的使用
指標
加長優化語句:指標是C語言中非常重要的特性,它是一種變數,但與普通變數不同,它儲存的不是資料的值,而是記憶體的地址。通過使用指標,我們可以讀取和寫入任意記憶體地址上的資料。
在瞭解指標讀寫的過程之前,我們需要先了解如何定義一個指標。與普通變數不同,我們通常在變數名前加一個"*"號來定義一個指標。例如,我們可以使用指標定義以下變數:
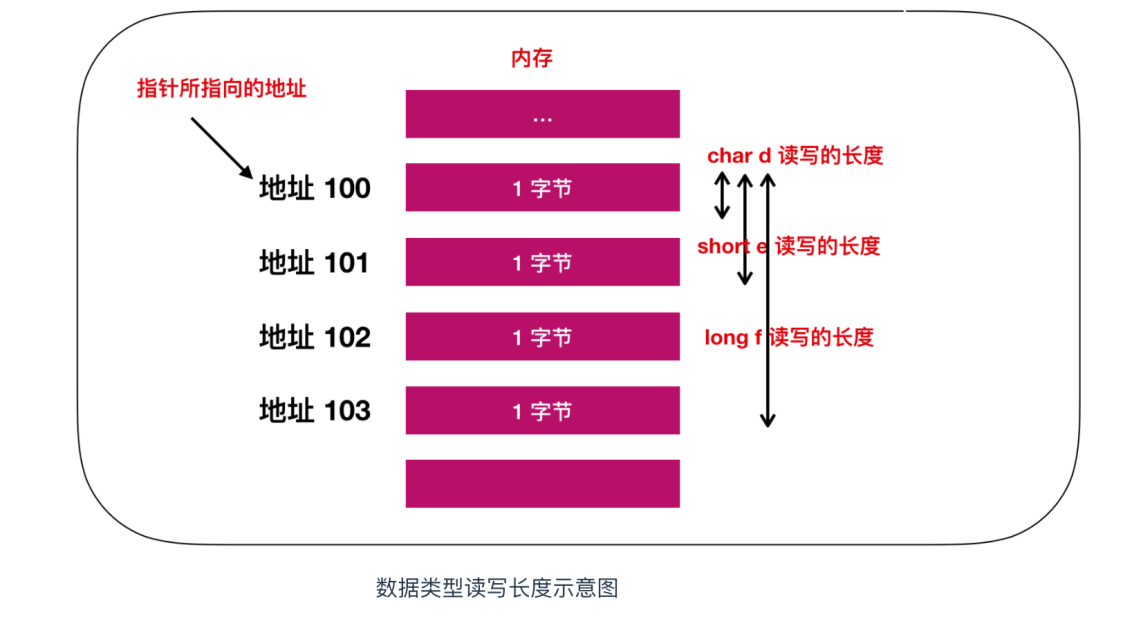
char *d; // char型別的指標 d 定義
short *e; // short型別的指標 e 定義
long *f; // long型別的指標 f 定義
加長優化語句:讓我們以32位元計算機為例來解釋為什麼變數d、e和f代表不同的位元組長度。在32位元計算機中,記憶體地址的長度是4位元組,因此指標的長度也是32位元(4位元組)。
然而,變數d、e和f表示的是從記憶體中一次讀取的位元組數。假設這些變數的值都為100,那麼使用char型別時,我們可以從記憶體中讀取或寫入1位元組的資料;使用short型別時,我們可以從記憶體中讀取或寫入2位元組的資料;而使用long型別時,我們可以從記憶體中讀取或寫入4位元組的資料。
下面是一個完整的型別位元組表,它展示了不同資料型別在記憶體中所佔用的位元組數:
| 型別 | 32位元 | 64位元 |
|---|---|---|
| char | 1 | 1 |
| short | 2 | 2 |
| int | 4 | 4 |
| float | 4 | 4 |
| double | 8 | 8 |
| long | 4 | 8 |
當涉及到指標和記憶體操作時,我們可以用圖來更直觀地描述資料的讀寫過程。
陣列是記憶體的實現
陣列是一種資料結構,它指的是多個相同資料型別的元素在記憶體中連續排列的形式。每個陣列元素都可以通過索引來區分,索引即為元素的編號。通過索引,我們可以對陣列中指定位置的元素進行讀取和修改操作。
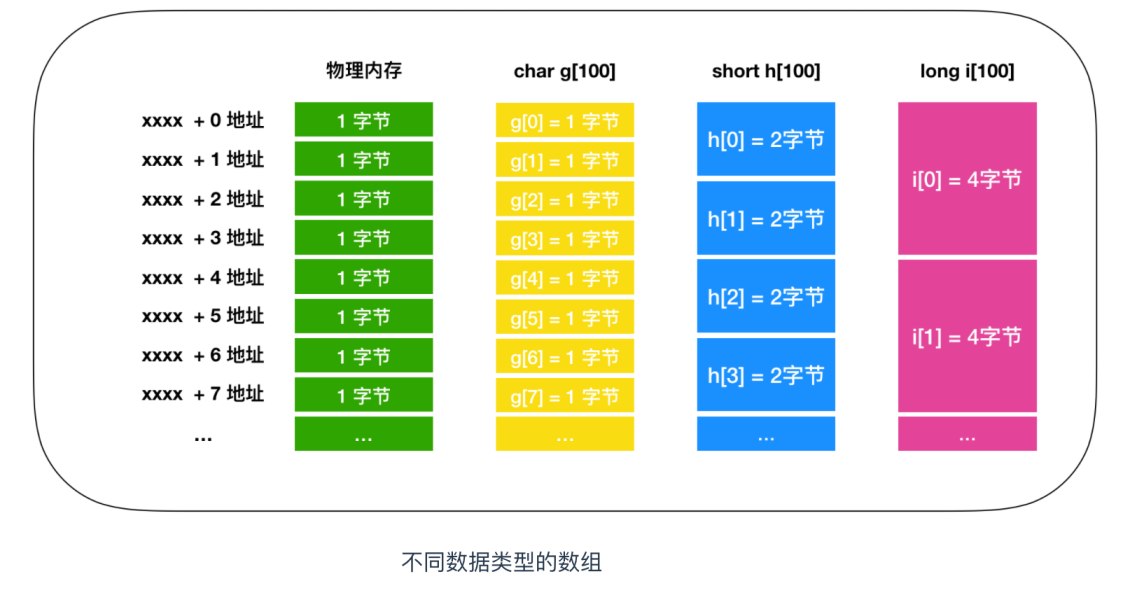
首先,讓我們瞭解一下陣列的定義方式。我們可以使用 char、short、long 等資料型別定義陣列,並使用[value]來表示陣列的長度,如下所示:
char g[100];
short h[100];
long i[100];
陣列的資料型別決定了一次可以讀寫的記憶體大小。以 char、short、long 為例,它們分別佔用 1、2、4 個位元組的記憶體空間。
陣列在記憶體中的實現與記憶體的物理結構完全一致。特別是在讀寫單個位元組時,無論位元組數是多少,都需要逐個位元組進行讀取或寫入。下面是記憶體讀寫的過程。
陣列是我們學習的第一個資料結構,我們都知道陣列的檢索效率非常高。至於為什麼陣列的檢索效率如此快,這超出了本文的討論範圍。
總結
本文介紹了記憶體和CPU之間的互動以及記憶體的物理結構。記憶體和CPU的互動是計算機正常執行的基礎,它們相互依賴,共同完成計算機的各種任務。記憶體由各種積體電路(IC)組成,包括RAM、ROM和Cache等記憶體型別。記憶體的讀寫過程包括指定地址、輸入輸出資料和控制訊號等步驟。記憶體可以用樓房模型來理解,每層樓對應一個位元組的資料。指標是C語言中重要的特性,可以讀取和寫入任意記憶體地址上的資料。陣列是一種資料結構,通過索引可以對記憶體中連續排列的元素進行讀取和修改。總的來說,記憶體在計算機中起到了儲存和處理資料的重要作用。