【matplotlib 實戰】--漏斗圖
2023-10-23 12:01:41
漏斗圖,形如「漏斗」,用於展示資料的逐漸減少或過濾過程。
它的起始總是最大,並在各個環節依次減少,每個環節用一個梯形來表示,整體形如漏斗。
一般來說,所有梯形的高度應是一致的,這會有助人們辨別數值間的差異。
需要注意的是,漏斗圖的各個環節,有邏輯上的順序關係。
同時,漏斗圖的所有環節的流量都應該使用同一個度量。
通過漏斗圖,可以較直觀的看出流程中各部分的佔比、發現流程中的問題,進而做出決策。
1. 主要元素
漏斗圖的主要元素包括:
- 分類:漏斗圖中的不同層級或步驟。每個分類代表一個特定的過程、篩選或轉化。
- 倒梯形:表示在每個階段中的資料數量或數量的百分比。通常,隨著階段的推進,資料量會逐漸減少。
- 資料流:表示資料在不同階段之間的流動路徑。它顯示了資料從一個階段到另一個階段的轉移和過濾過程。
- 轉化率:表示在每個階段中資料的轉化率或轉化的百分比。它反映了資料在不同階段之間的損失或過濾程度。

2. 適用的場景
漏斗圖適用的分析場景包括:
- 銷售轉化分析:跟蹤銷售過程中的潛在客戶數量,並展示他們在不同階段的轉化率,從而幫助分析銷售流程中的瓶頸和改進機會。
- 市場行銷分析:展示市場活動中的潛在客戶數量,並顯示他們在不同行銷階段的轉化率,從而評估市場策略的有效性和改進方向。
- 使用者體驗分析:追蹤使用者在產品或服務使用過程中的轉化率,幫助分析使用者體驗中的瓶頸和提升點,從而優化產品或服務設計。
- 網站流量分析:展示網站存取者在不同頁面或功能模組之間的轉化率,幫助分析使用者行為和改進網站設計。
3. 不適用的場景
然而,漏斗圖並不適用於所有分析場景。以下是一些不適合使用漏斗圖的情況:
- 資料無序或重複:如果資料沒有明確的階段或無法按照特定的流程進行過濾或轉化,漏斗圖可能不適用。
- 資料缺失或不完整:如果資料在不同階段之間存在缺失或不完整,漏斗圖可能無法準確反映資料流動和轉化情況。
- 多個並行路徑:如果資料在不同階段之間存在多個並行路徑,並且無法簡單地表示為單一的線性流程,漏斗圖可能無法有效展示資料流動。
4. 分析實戰
本次用漏斗圖分析各個學歷的畢業生人數,從小學學歷到博士學歷。
4.1. 資料來源
資料來源國家統計局公開的資料,整理好的資料可從下面的地址下載:
https://databook.top/nation/A0M
使用其中的檔案:A0M0203.csv(各級各類學歷教育畢業生數)
fp = "d:/share/data/A0M0203.csv"
df = pd.read_csv(fp)
df

4.2. 資料清理
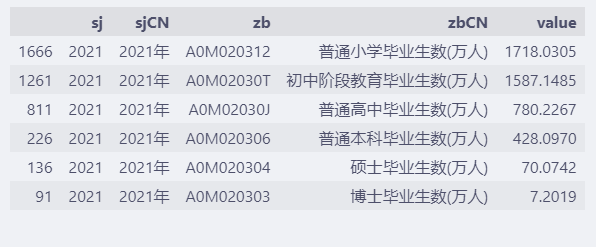
漏斗圖不需要時間序列資料,所以,只提取2021年的資料中從小學到博士的6種學歷的畢業生人數。
data = df[df["sj"] == 2021]
#A0M020312: 普通小學畢業生數(萬人)
#A0M02030T: 初中階段教育畢業生數(萬人)
#A0M02030J: 普通高中畢業生數(萬人)
#A0M020306: 普通本科畢業生數(萬人)
#A0M020304: 碩士畢業生數(萬人)
#A0M020303: 博士畢業生數(萬人)
data = data[
data["zb"].isin(
[
"A0M020312",
"A0M02030T",
"A0M02030J",
"A0M020306",
"A0M020304",
"A0M020303",
]
)
]
data = data.sort_values("value", ascending=False)
data
4.3. 分析結果視覺化
with plt.style.context("dark_background"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 1, 1])
colors = plt.cm.Set2.colors
cnt = len(data)
y = [[1 + i * 3, 3.8 + i * 3] for i in range(cnt)]
y_ticks = [2 + i * 3 for i in range(cnt)]
start_x1 = 5
start_x2 = -5
for i in range(cnt):
ax.fill_betweenx(
y=y[i],
x1=[start_x1, data.iloc[i, 4]],
x2=[start_x2, -1 * data.iloc[i, 4]],
color=colors[i],
)
start_x1 = data.iloc[i, 4]
start_x2 = -1 * data.iloc[i, 4]
ax.set_xticks([], [])
ax.set_yticks(y_ticks, data["zbCN"])
for y, value in zip(y_ticks, data["value"]):
ax.text(
10,
y,
value,
fontsize=16,
fontweight="bold",
color="white",
ha="center",
)
ax.grid(False)
ax.set_title("2021年各學歷畢業人數")

從圖中可以看出,完成9年義務教育的比例很高。
初中到高中,人數幾乎減半,而本科考研,碩士考博的人數比例更是銳減。