兩臺實體機器4個虛擬機器器節點的Hadoop叢集搭建(Ubuntu版)
安裝Ubuntu
Linux元資訊
- 兩臺機器,每臺機器兩臺Ubuntu
- Ubuntu版本:ubuntu-22.04.3-desktop-amd64.iso
- 處理器數量2,每個處理器的核心數量2,總處理器核心數量4
- 單個虛擬機器器記憶體8192MB(8G),最大磁碟大小30G
參考連結
-
清華大學開源軟體映象站
-
虛擬機器器(VMware)安裝Linux(Ubuntu)安裝教學
具體步驟
-
把下載好的iso檔案儲存到一個位置
-
開始在VMware安裝Ubuntu
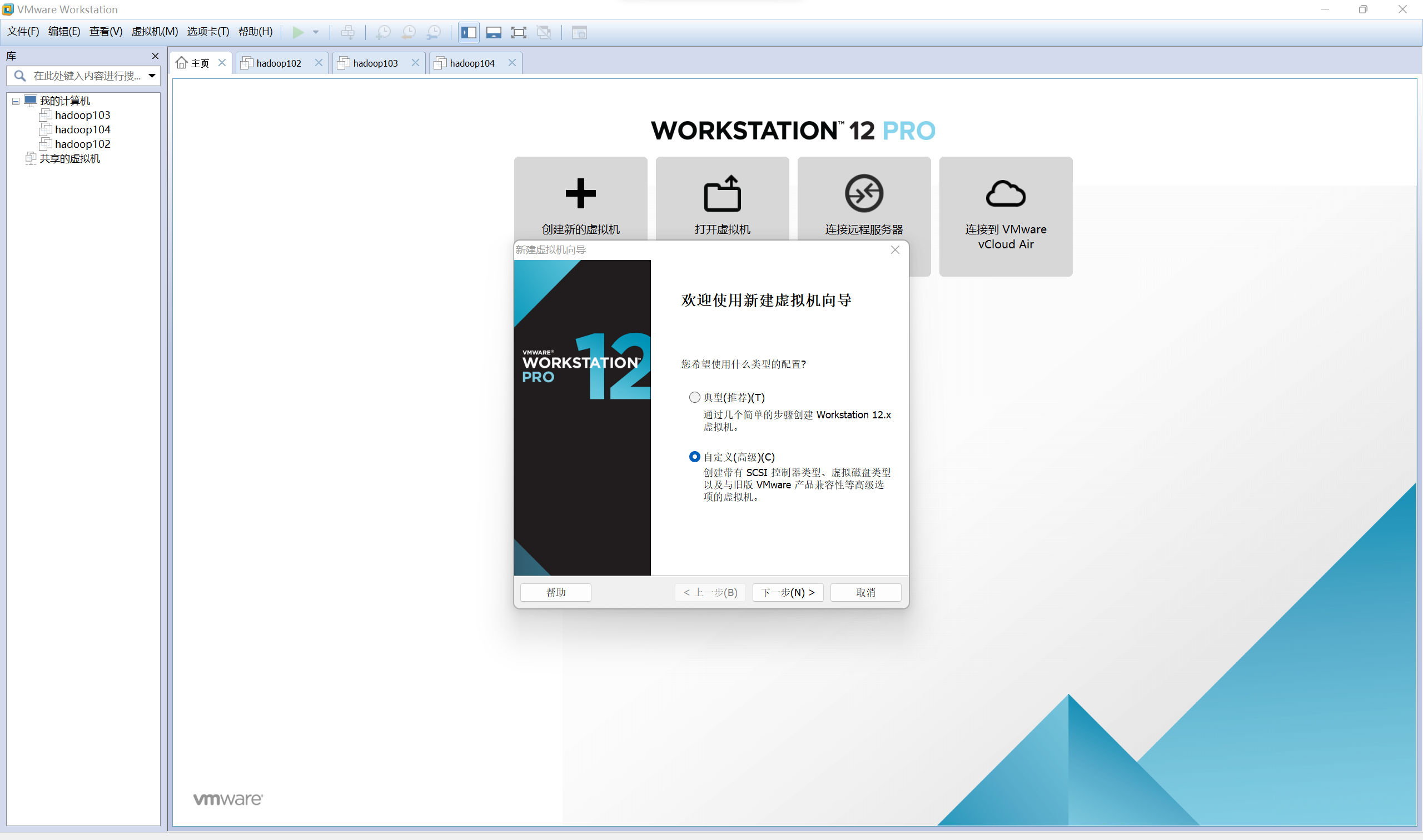
-
選擇網路型別(圖片錯了,應該是「橋接網路」,詳見「設定虛擬機器器網路」)
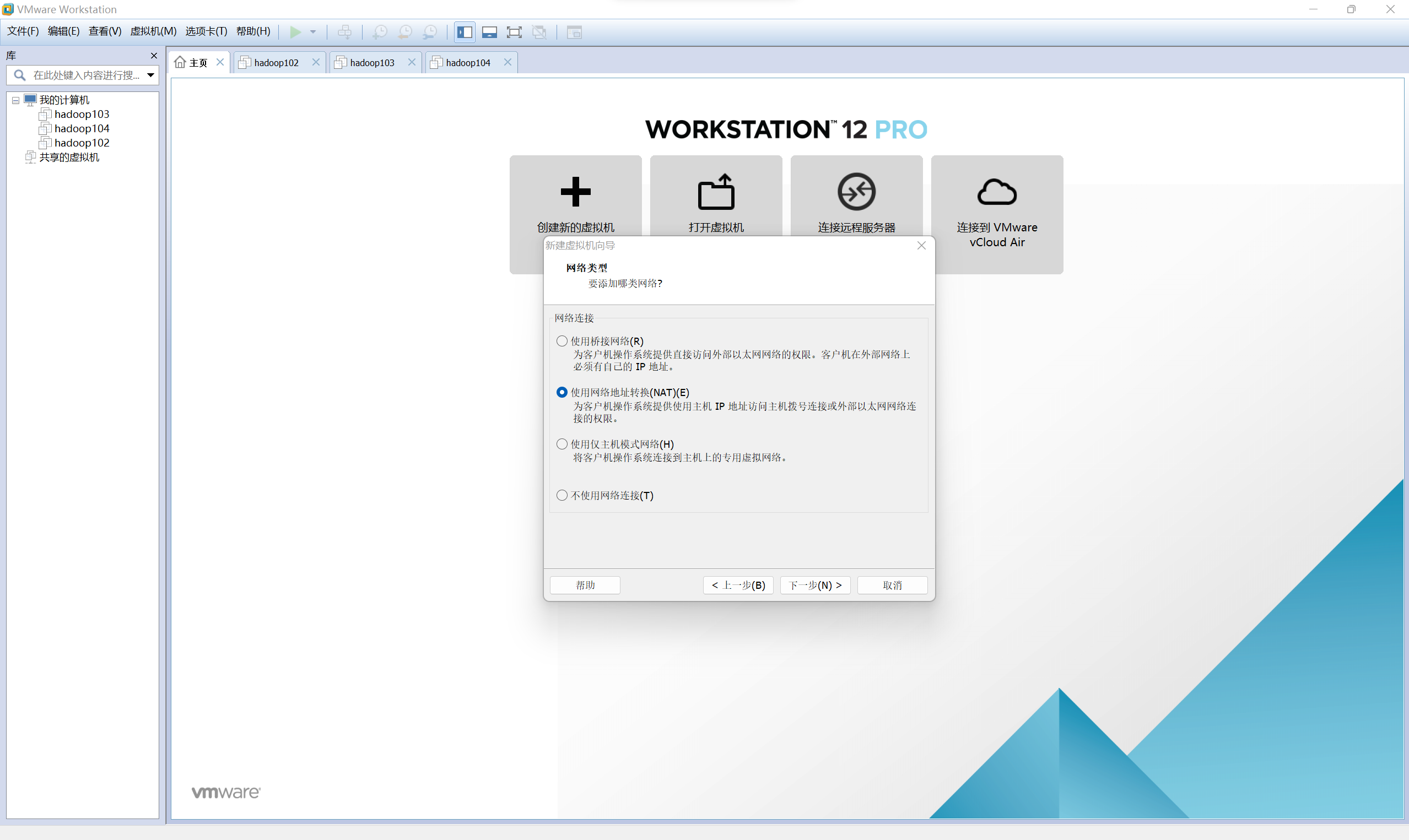
-
指定磁碟容量
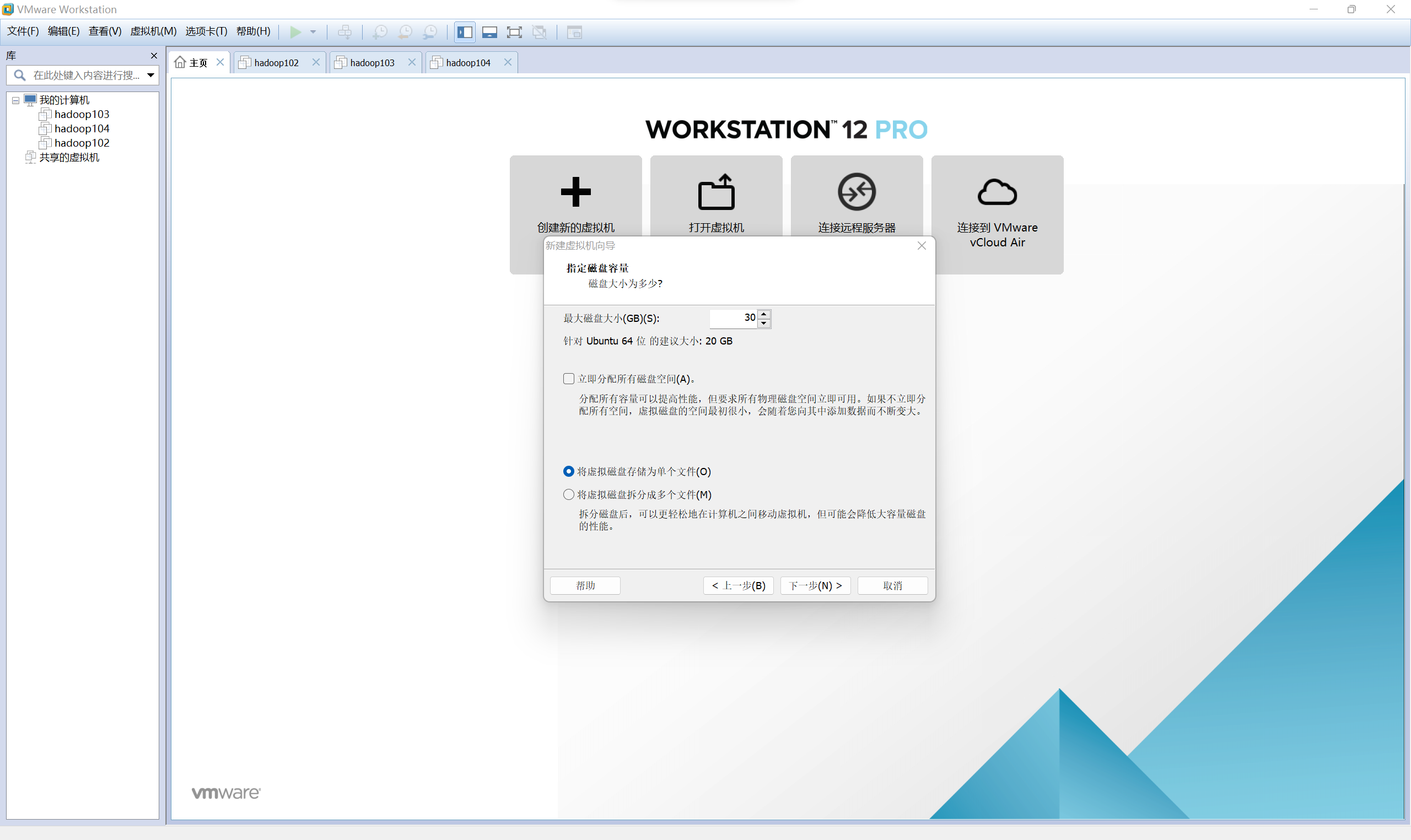
-
設定映象檔案

-
開始安裝Ubuntu
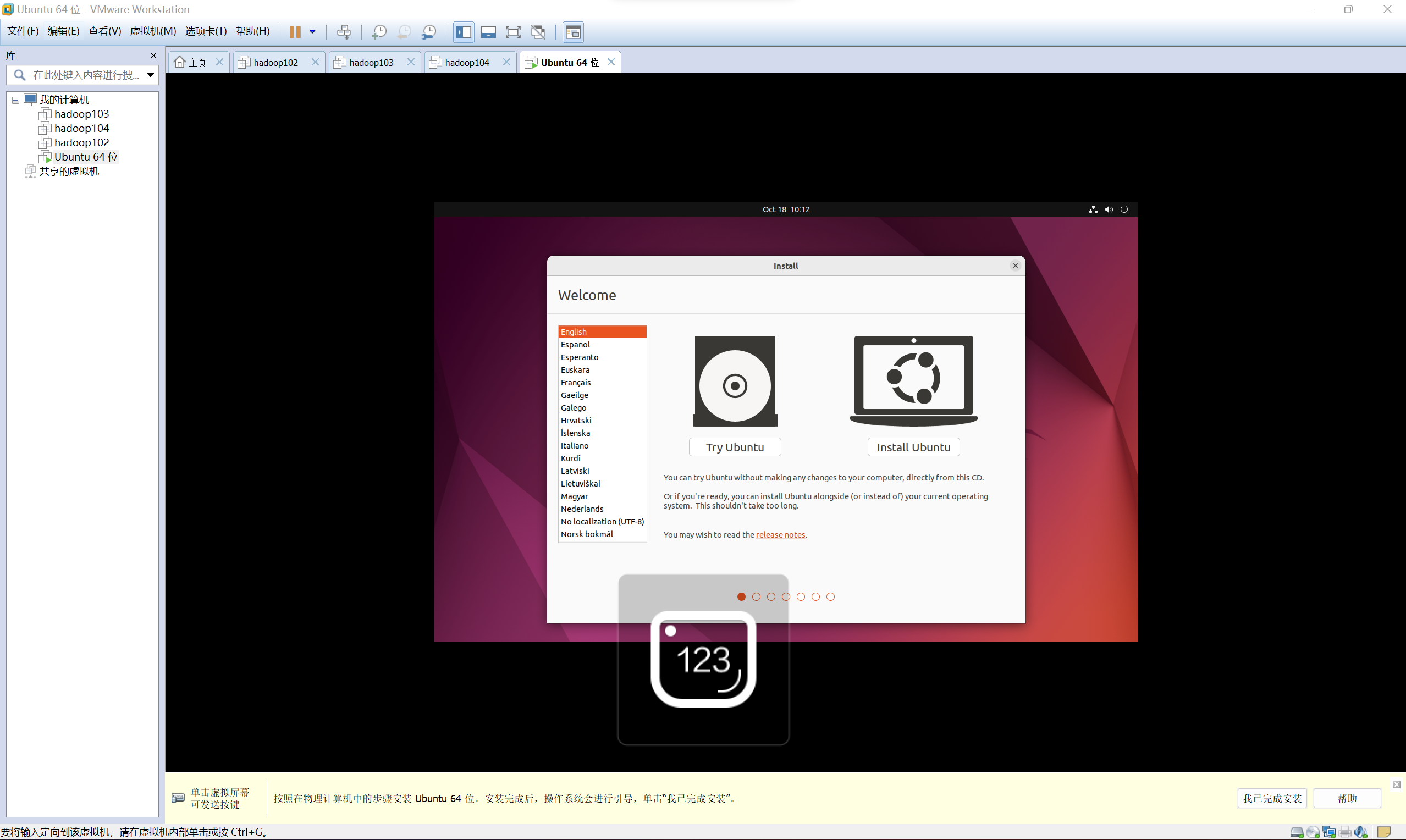
設定虛擬機器器網路
設定橋接模式
-
檢視宿主機WLAN硬體設定資訊
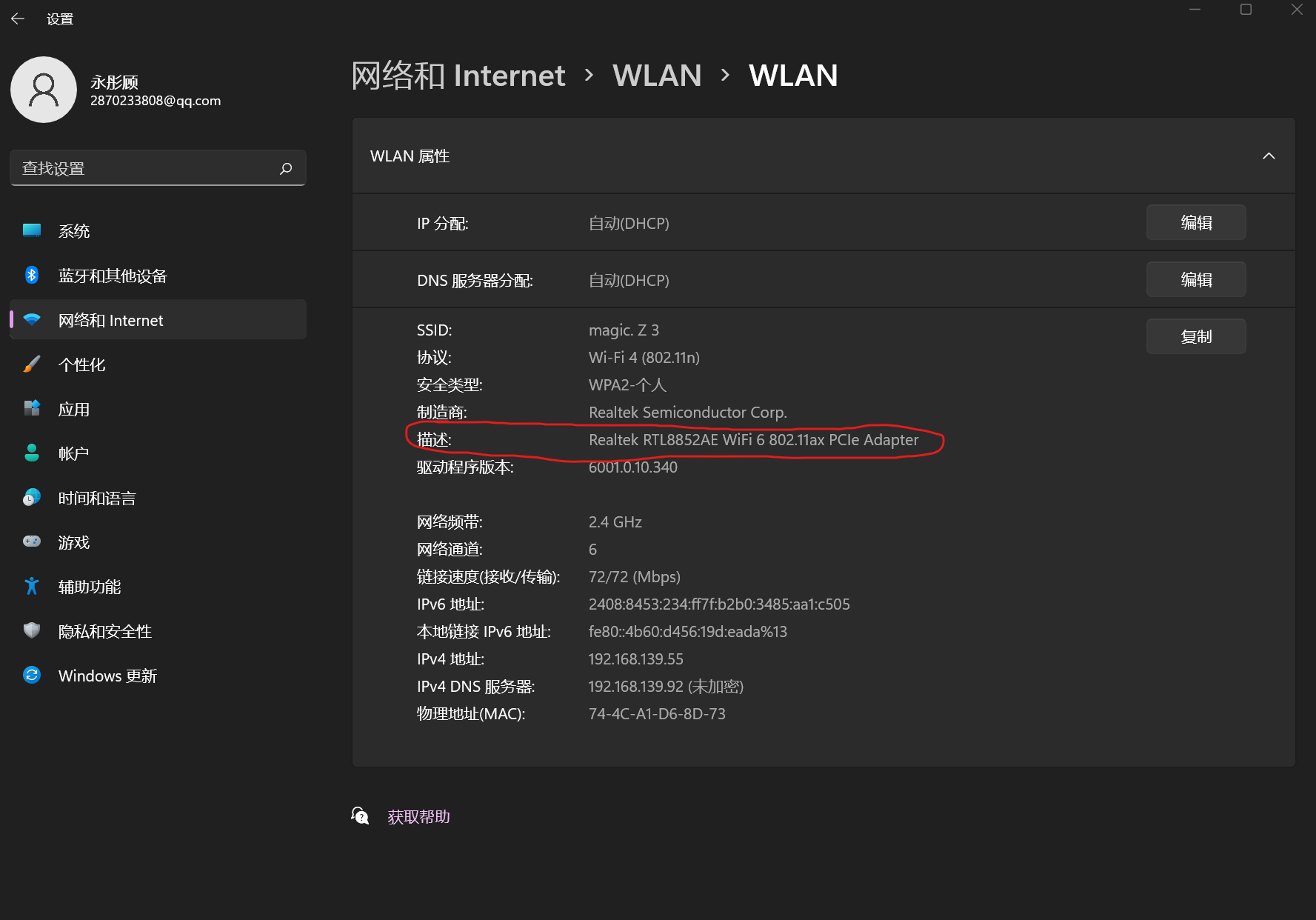
-
開啟VMware中的虛擬網路編輯器,根據宿主機WLAN硬體設定如下資訊

設定虛擬機器器靜態IP
防止每次開機隨機IP,導致無法連線到其他虛擬機器器
-
切換root使用者(第一次切換root使用者需要設定root密碼)
sudo passwd -
開啟01-network-manager-all.yaml檔案(網路卡組態檔)
vim /etc/netplan/01-network-manager-all.yaml -
刪除原內容,複製貼上如下資訊(根據實際情況更改)
# Let NetworkManager manage all devices on this system network: ethernets: ens33: dhcp4: false addresses: [192.168.139.101/24] routes: - to: default via: 192.168.139.92 nameservers: addresses: [8.8.8.8] version: 2 -
在宿主機的cmd中執行ipconfig命令檢視網路資訊,如下圖所示:
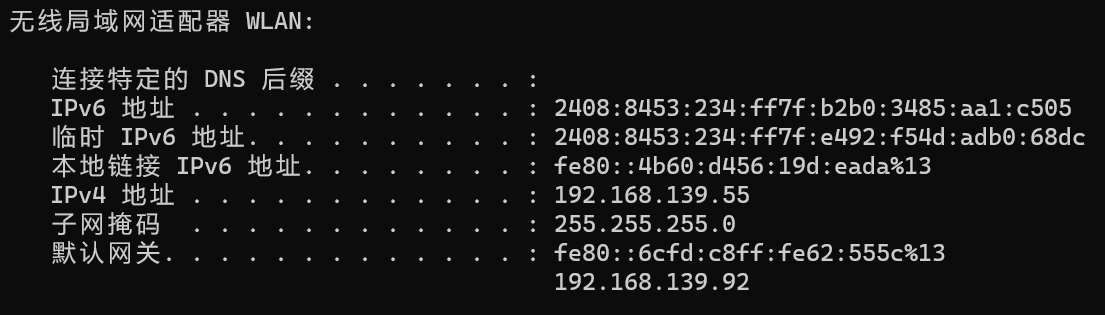
-
根據第四步更改第三步的部分資訊
- via:宿主機的預設閘道器
- addresses:前三位和宿主機預設閘道器保持一致,後一位自己隨便設定(但要避免和已有ip重複)
安裝Hadoop
Hadoop元資訊
-
統一使用者名稱:hjm,密碼:000000
-
四臺虛擬機器器分別為gyt1,gyt2,hjm1,hjm2
-
四臺虛擬機器器用橋接模式,連線一臺手機的熱點,虛擬機器器ip如下:
hjm1:192.168.139.101
hjm2:192.168.139.102
gyt1:192.168.139.103
gyt2:192.168.139.104
-
叢集部署規劃
hjm1 hjm2 gyt1 gyt2 HDFS NameNode、DataNode DataNode SecondaryNameNode、DataNode DataNode YARN NodeManager NodeManager NodeManager ResourceManager、NodeManager
設定使用者sudo許可權
設定以後,每次使用sudo,無需輸入密碼
-
用sudo許可權開啟sudoers檔案
sudo vim /etc/sudoers -
增加修改sudoers檔案,在%sudo下面新加一行(這裡以hjm使用者為例)
# Allow members of group sudo to execute any command %sudo ALL=(ALL:ALL) ALL hjm ALL=(ALL) NOPASSWD: ALL
建立目錄並更改許可權
-
建立module和software資料夾
sudo mkdir /opt/module sudo mkdir /opt/software -
修改 module、software 資料夾的所有者和所屬組均為hjm使用者
sudo chown hjm:hjm /opt/module sudo chown hjm:hjm /opt/software
Ubuntu檢視、安裝和開啟ssh服務
-
檢視ssh服務的開啟狀態,如果開啟,則可以跳過這一部分
ps -e|grep ssh -
安裝ssh服務
sudo apt-get install openssh-server -
啟動ssh服務
sudo /etc/init.d/ssh start
注意:
當你用ssh軟體(這裡預設是Xhell 7)連線時,不要用root使用者連,ssh預設 不能用root直接連,除非修改組態檔
安裝JDK
-
用xftp工具將jdk匯入到opt目錄下面的software資料夾下面
-
解壓jdk到opt/module目錄下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ -
設定jdk環境變數
(1)新建/etc/profile.d/my_env.sh 檔案
sudo vim /etc/profile.d/my_env.sh(2)新增以下內容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin(3)儲存後退出,source 一下/etc/profile 檔案,讓新的環境變數 PATH 生效
source /etc/profile(4)測試jdk是否安裝成功
java -version
安裝Hadoop
-
用xftp工具將hadoop匯入到opt目錄下面的software資料夾下面
-
解壓hadoop到opt/module目錄下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ -
設定hadoop環境變數
(1)開啟/etc/profile.d/my_env.sh 檔案
sudo vim /etc/profile.d/my_env.sh(2)在 my_env.sh 檔案末尾新增如下內容
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin(3)儲存後退出,source 一下/etc/profile 檔案,讓新的環境變數 PATH 生效
source /etc/profile(4)測試hadoop是否安裝成功
hadoop version
修改組態檔
cd到$HADOOP_HOME/etc/hadoop目錄
core-site.xml
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hjm1:8020</value>
</property>
<!-- 指定 hadoop 資料的儲存目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 設定 HDFS 網頁登入使用的靜態使用者為 hjm -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hjm</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- nn web 端存取地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hjm1:9870</value>
</property>
<!-- 2nn web 端存取地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>gyt1:9868</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>gyt2</value>
</property>
<!-- 環境變數的繼承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程式執行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
workers
hjm1
hjm2
gyt1
gyt2
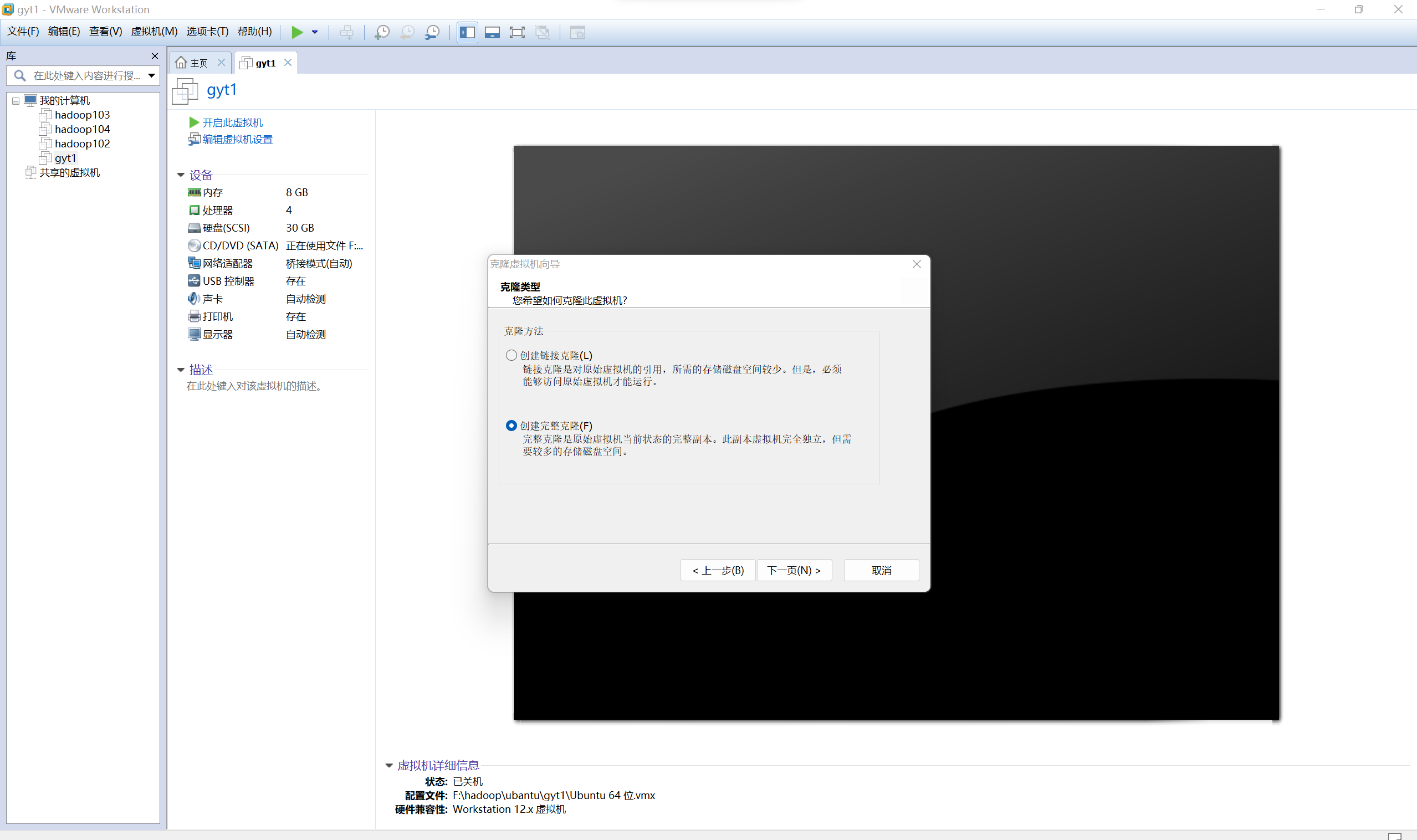
克隆虛擬機器器
-
在hjm1和gyt1的兩臺宿主機上分別克隆出hjm2和gyt2
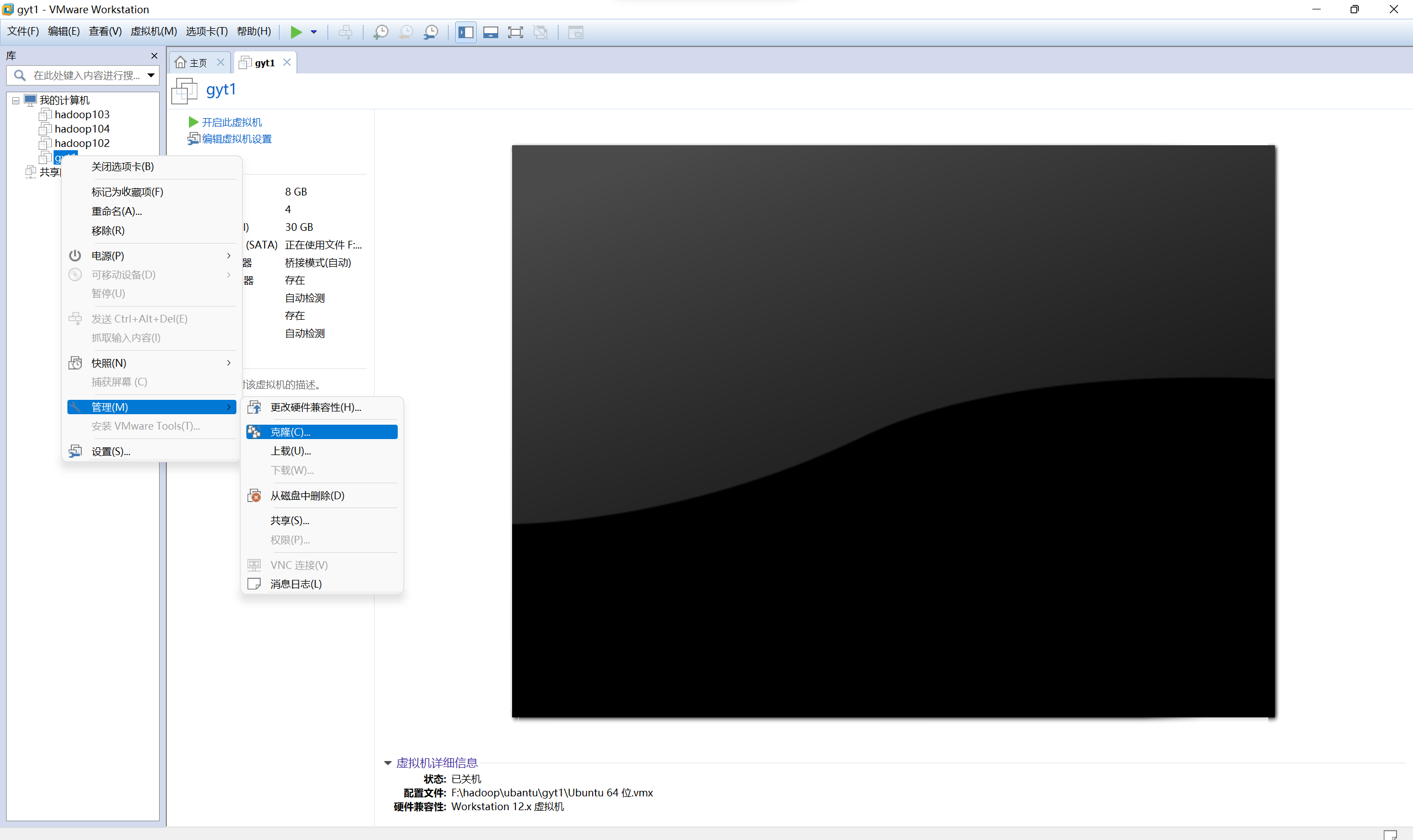
-
按照「設定虛擬機器器網路-設定虛擬機器器靜態IP」的方式,設定hjm2的ip為192.168.139.102,gyt2的ip為192.168.139.104
-
改每臺虛擬機器器的ubuntu對映檔案,這裡以gyt2為例
127.0.0.1 localhost # 127.0.1.1 gyt2 記得刪除這一行 192.168.139.101 hjm1 192.168.139.102 hjm2 192.168.139.103 gyt1 192.168.139.104 gyt2 -
修改四臺虛擬機器器的主機名分別為hjm1,hjm2,gyty1,gyt2
sudo vim /etc/hostname -
重啟虛擬機器器
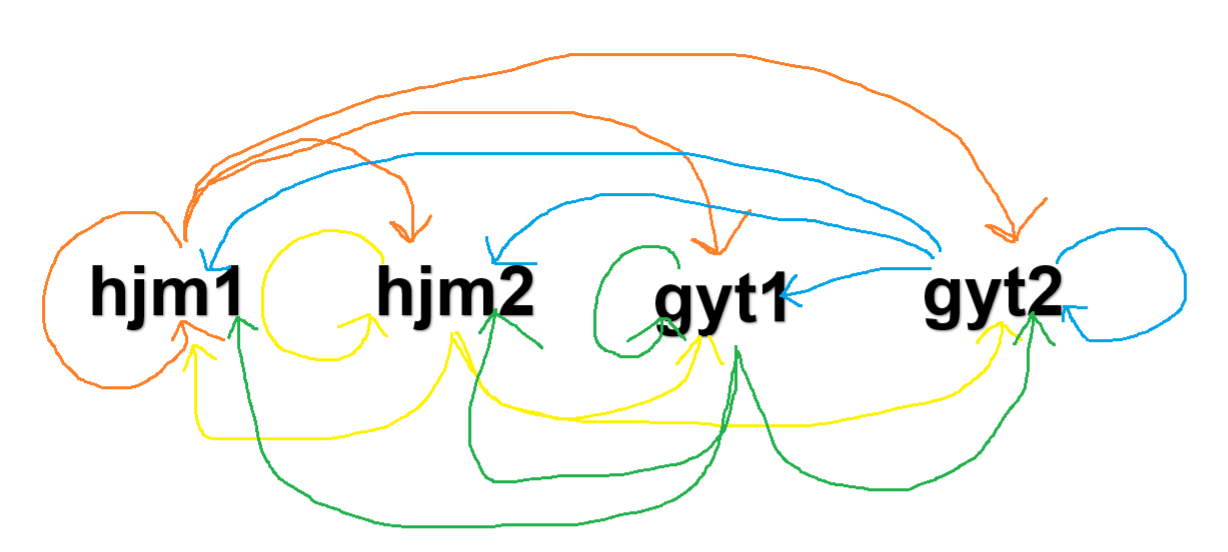
ssh免密登入
- 分別要設定16種免密登入,如下圖所示
-
切換hjm使用者,cd到~/.ssh,生成公鑰和私鑰
ssh-keygen -t rsa -
將公鑰複製到目的機上,這裡以hjm1舉例
ssh-copy-id hjm1
xsync叢集分發指令碼
-
在/home/hjm/bin目錄下建立xsync檔案
-
在該檔案中編寫如下程式碼
#!/bin/bash #1. 判斷引數個數 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍歷叢集所有機器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍歷所有目錄,挨個傳送 for file in $@ do #4. 判斷檔案是否存在 if [ -e $file ] then #5. 獲取父目錄 pdir=$(cd -P $(dirname $file); pwd) #6. 獲取當前檔案的名稱 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done -
修改指令碼xsync具有執行許可權
chmod +x xsync -
測試指令碼
xsync /home/atguigu/bin -
將指令碼複製到/bin中,以便全域性呼叫
sudo cp xsync /bin/ -
在使用者端電腦(預設windows)設定對映
(1)windows + R
(2)輸入drivers,回車
(3)進入etc資料夾
(4)編輯hosts檔案
192.168.139.101 hjm1 192.168.139.102 hjm2 192.168.139.103 gyt1 192.168.139.104 gyt2
測試hadoop
-
格式化NameNode
如果叢集是第一次啟動,需要在 hadoop102 節點格式化 NameNode(注意:格式化 NameNode,會產生新的叢集 id,導致 NameNode 和 DataNode 的叢集 id 不一致,叢集找不到已往資料。如果叢集在執行過程中報錯,需要重新格式化 NameNode 的話,一定要先停止 namenode 和 datanode 程序,並且要刪除所有機器的 data 和 logs 目錄,然後再進行格式化。)
hdfs namenode -format -
在hjm1上啟動hdfs
sbin/start-dfs.sh -
在gyt2上啟動yarn
sbin/start-yarn.sh -
Web 端檢視 HDFS 的 NameNode
-
Web 端檢視 YARN 的 ResourceManager
-
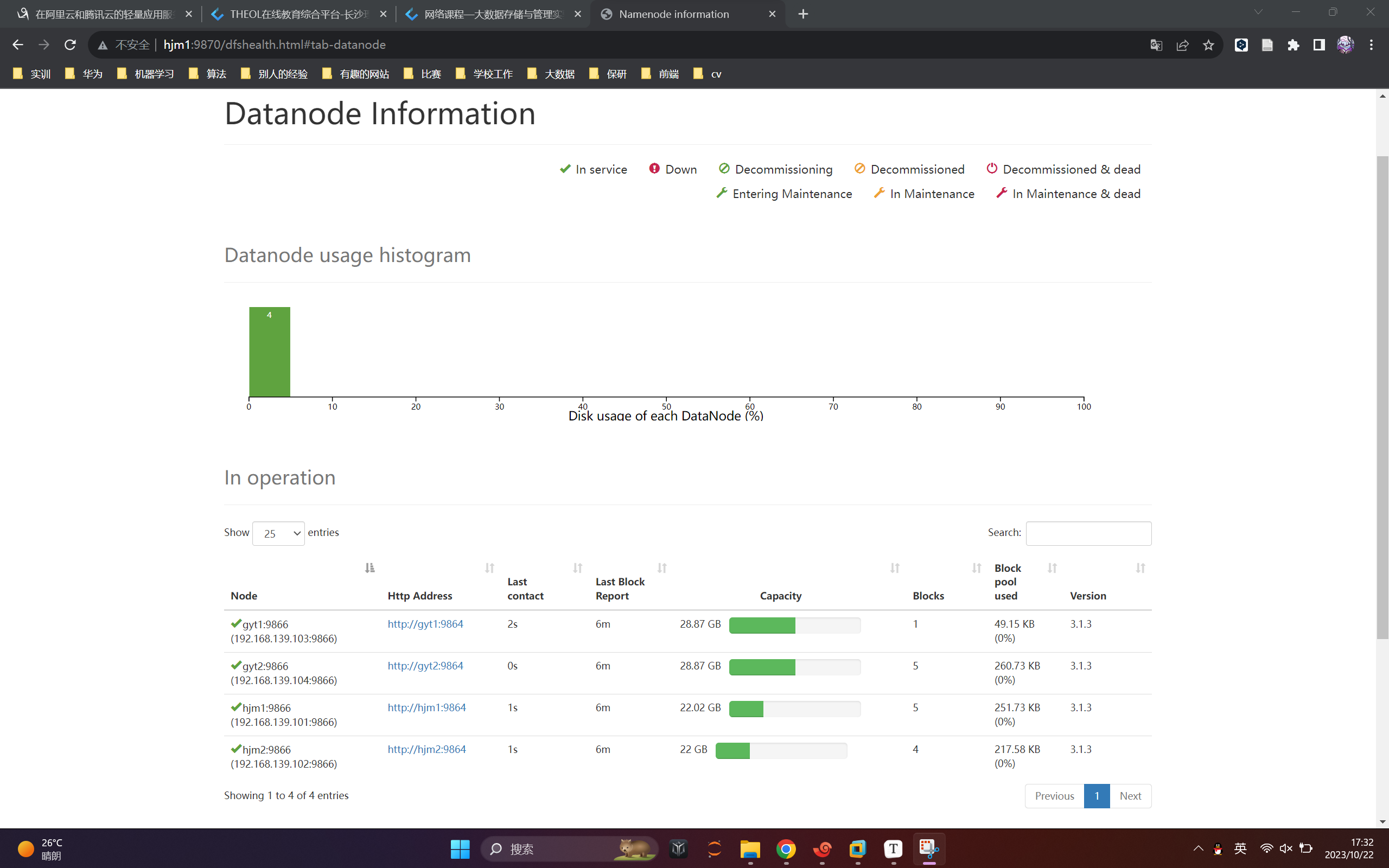
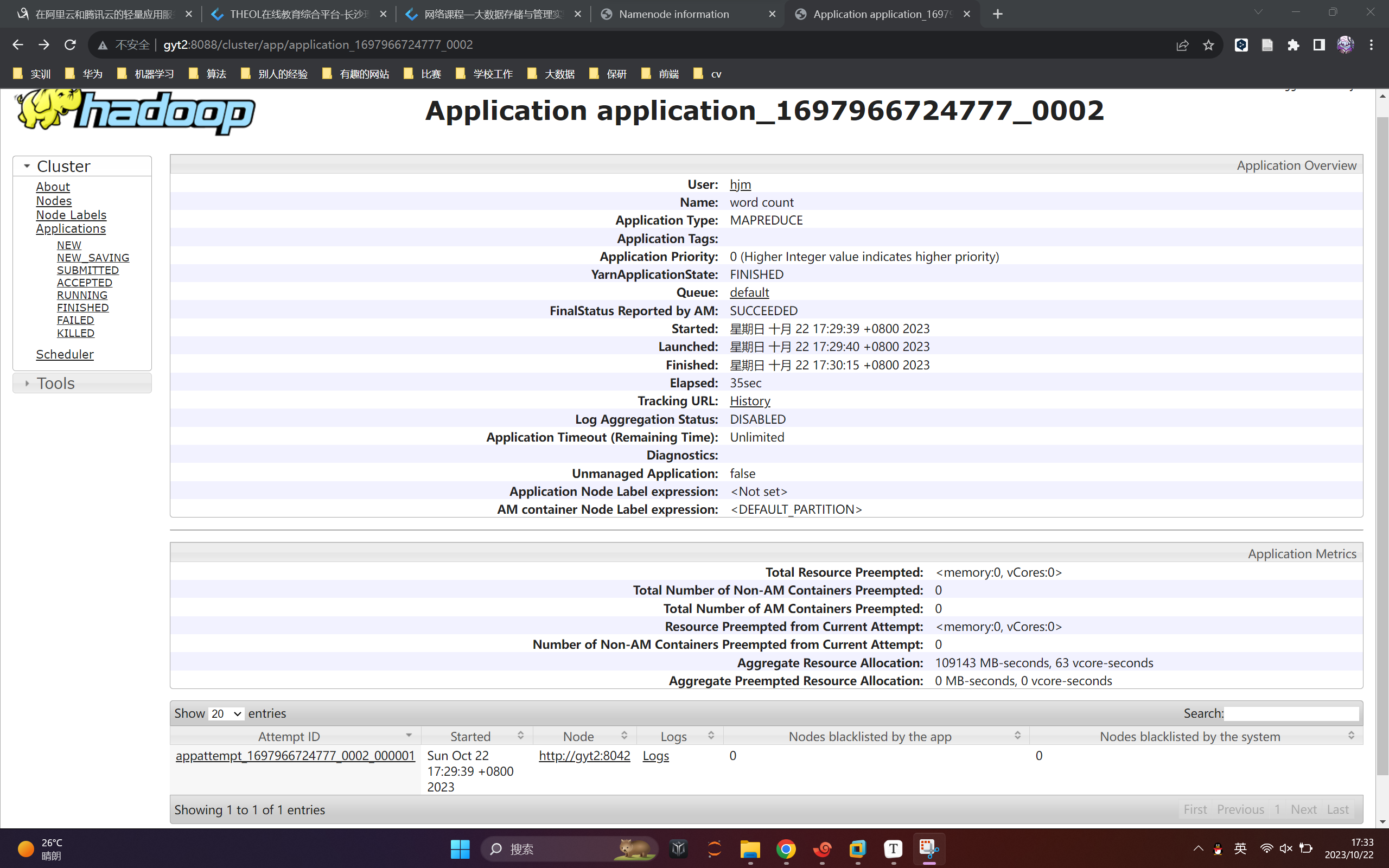
測試結果
(1)datanode
(2)Yarn
(3)WordCount
