umich cv-4-2 經典折積網路架構
這節課中主要討論了折積神經網路的發展歷史以及幾種經典結構是如何構建的
AlexNet
在2012年的時候,Alexnet神經網路提出,這時網路的架構比如說各個層之間要如何排列組合,使用多少折積層池化層,每個層又如何設定超引數其實沒有什麼規律,主要通過實驗與試錯:
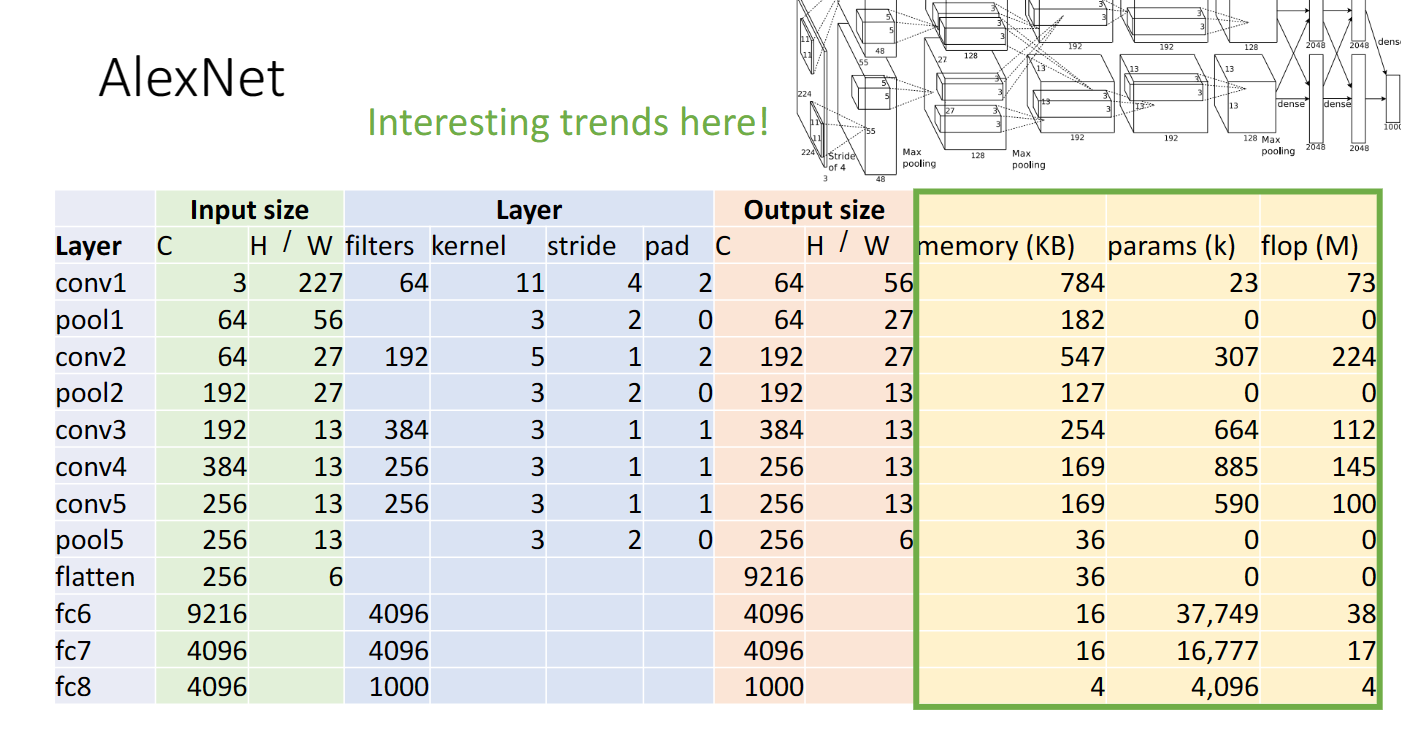
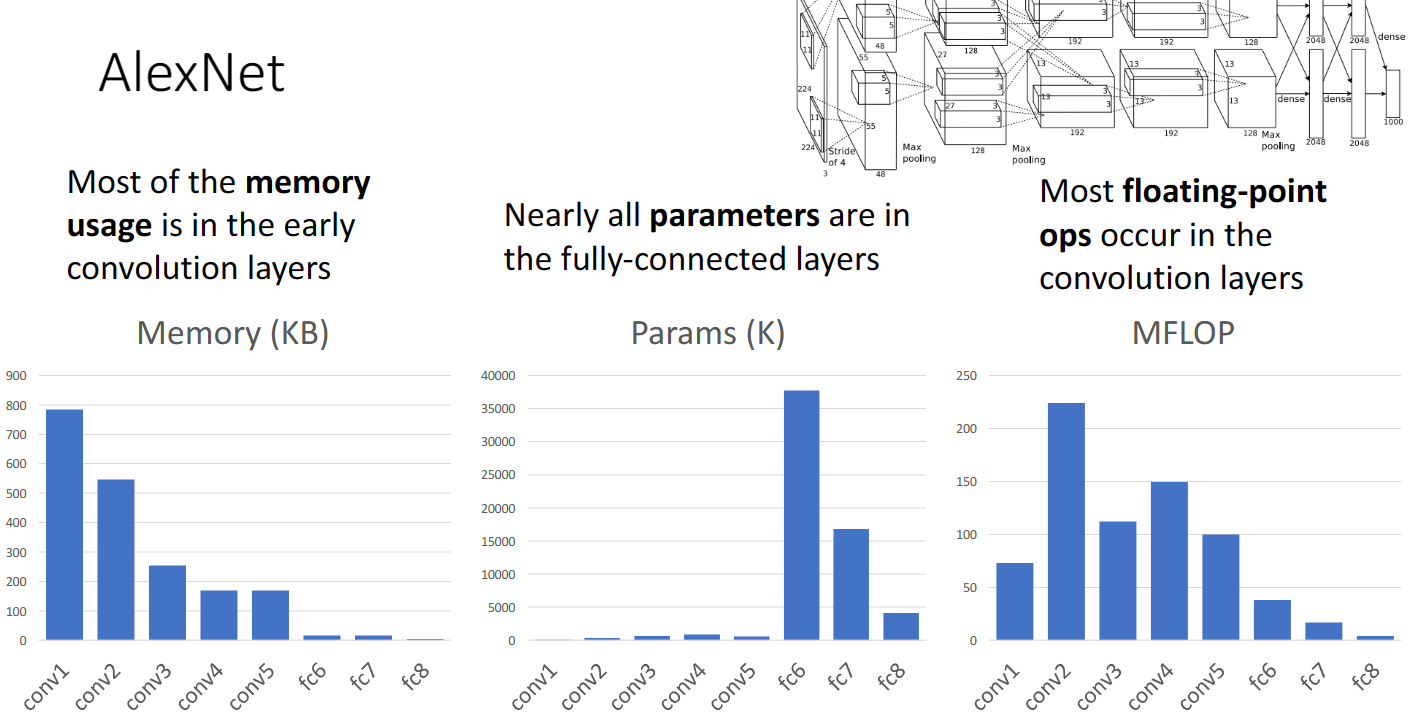
但是我們通過對內容容量,可學習引數以及浮點運算次數的計算,可以看到一些有趣的規律,絕大多數的內容容量都使用在了折積層,絕大多數的可學習的引數都在全連線層,絕大多數的浮點運算都發生在折積層
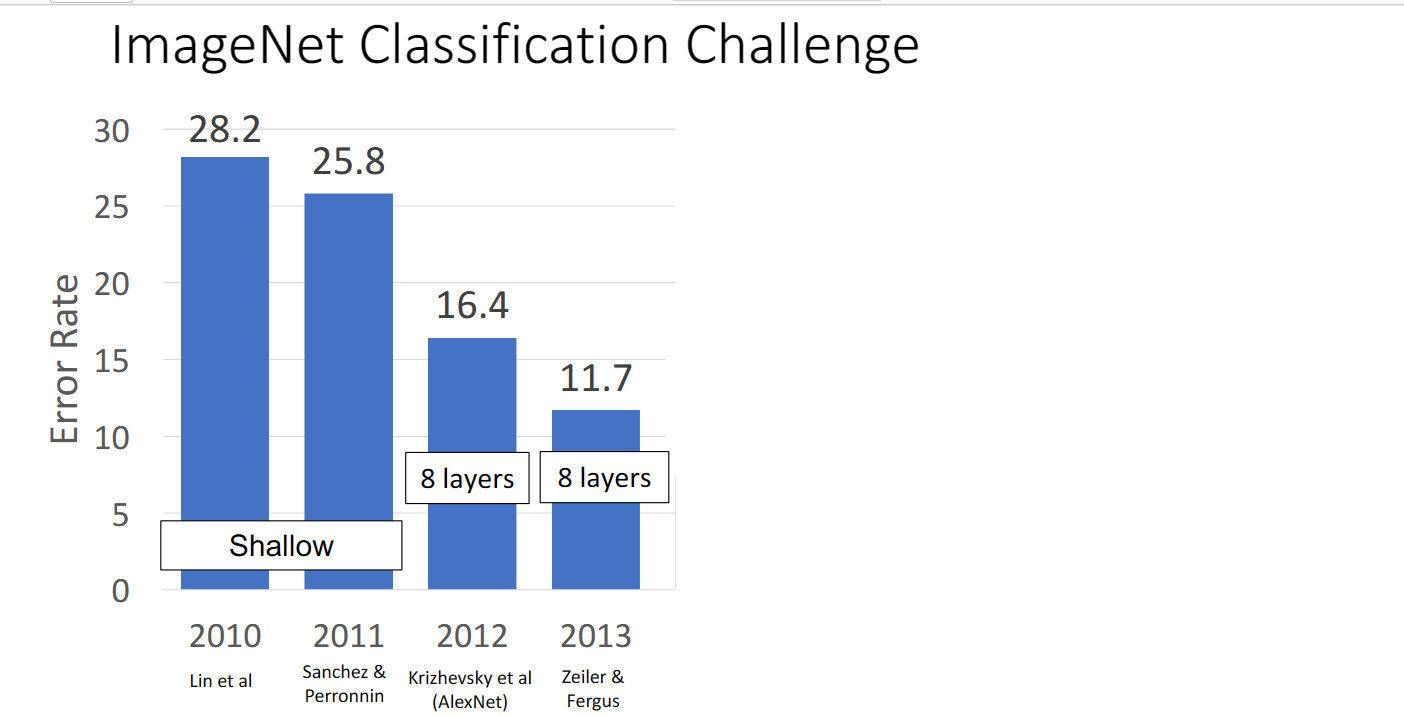
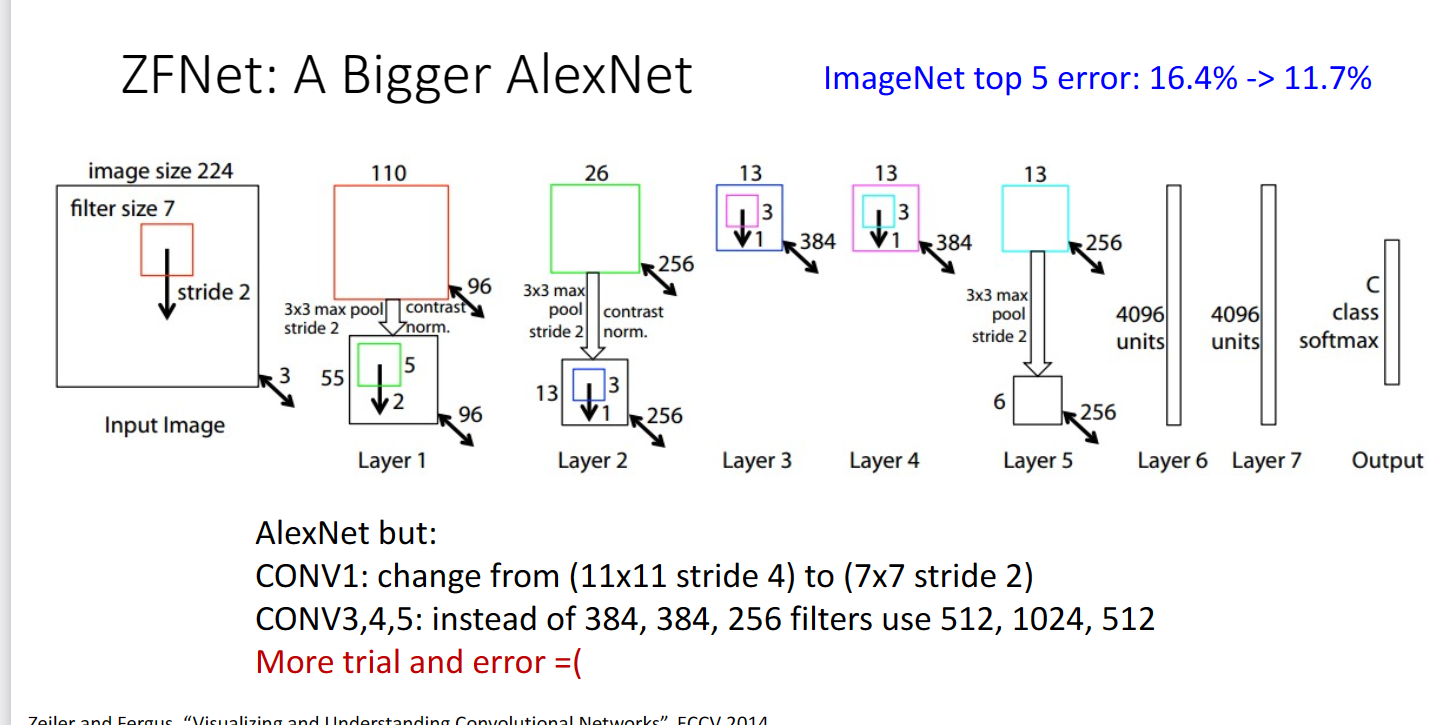
在2013年又提出了ZFNet,其實只是一個更大的AlexNet:
VGG
在2014年提出了VGG網路,VGG網路引入了有規律的設計。建立了更深層的網路,我們可以看到折積層與池化層的超引數都是固定的,並且每次池化之後都會讓折積層通道數加倍,這樣可以保證折積層每次進行的運算數量一致
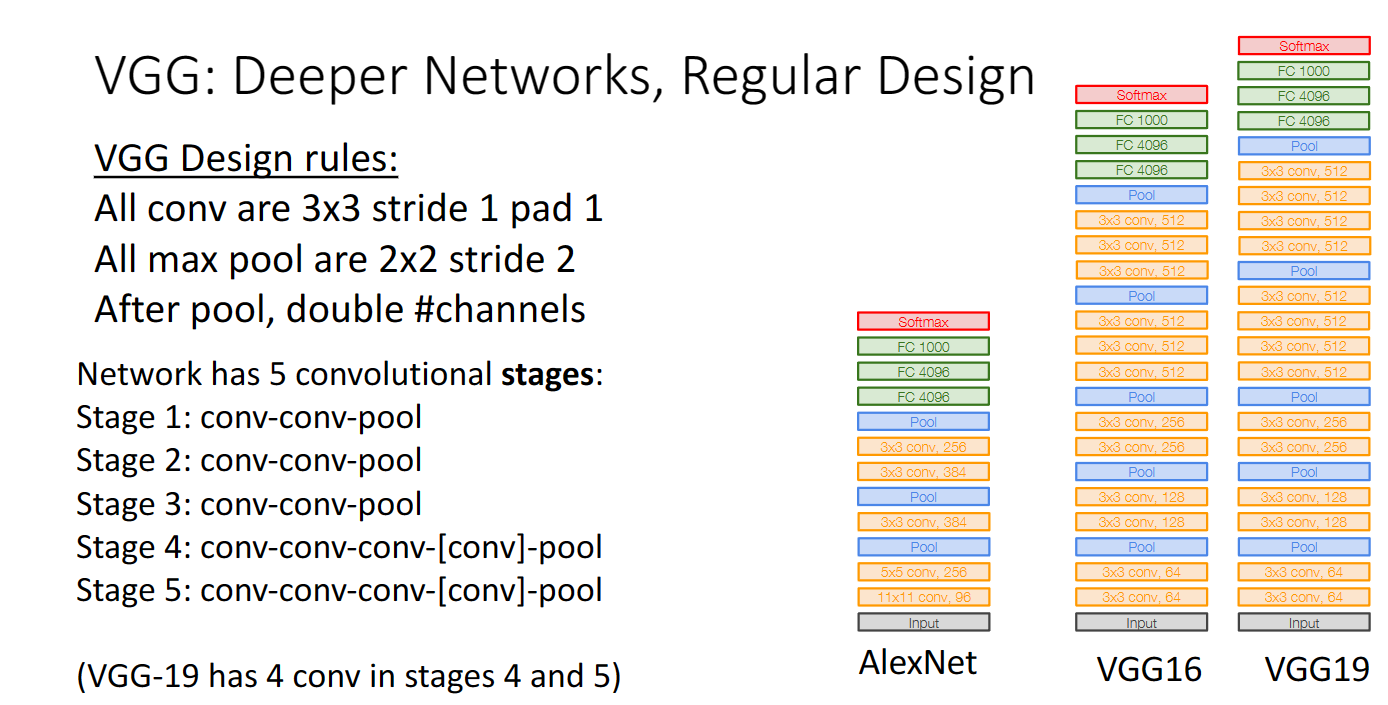
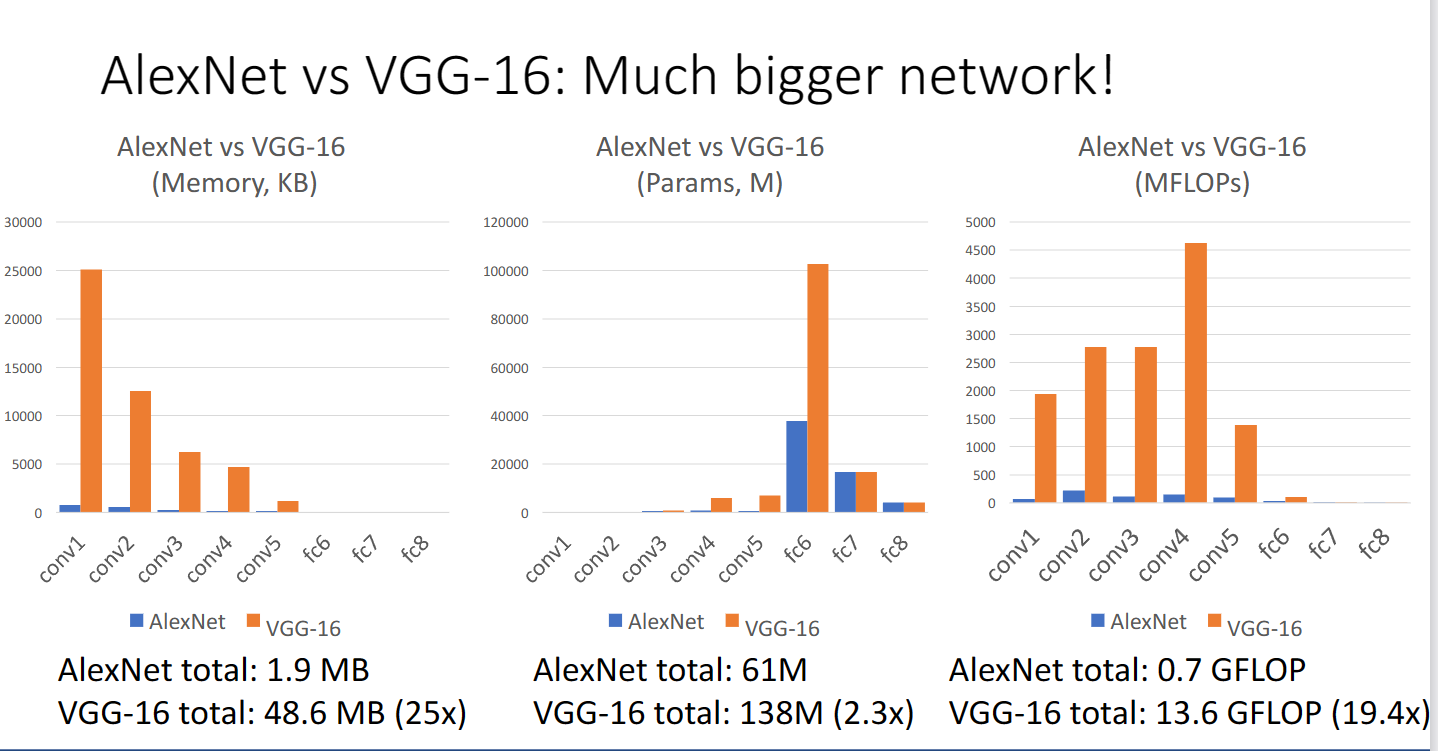
從下圖也可以看出,VGG要比Alexnet複雜許多:
GoogleNet
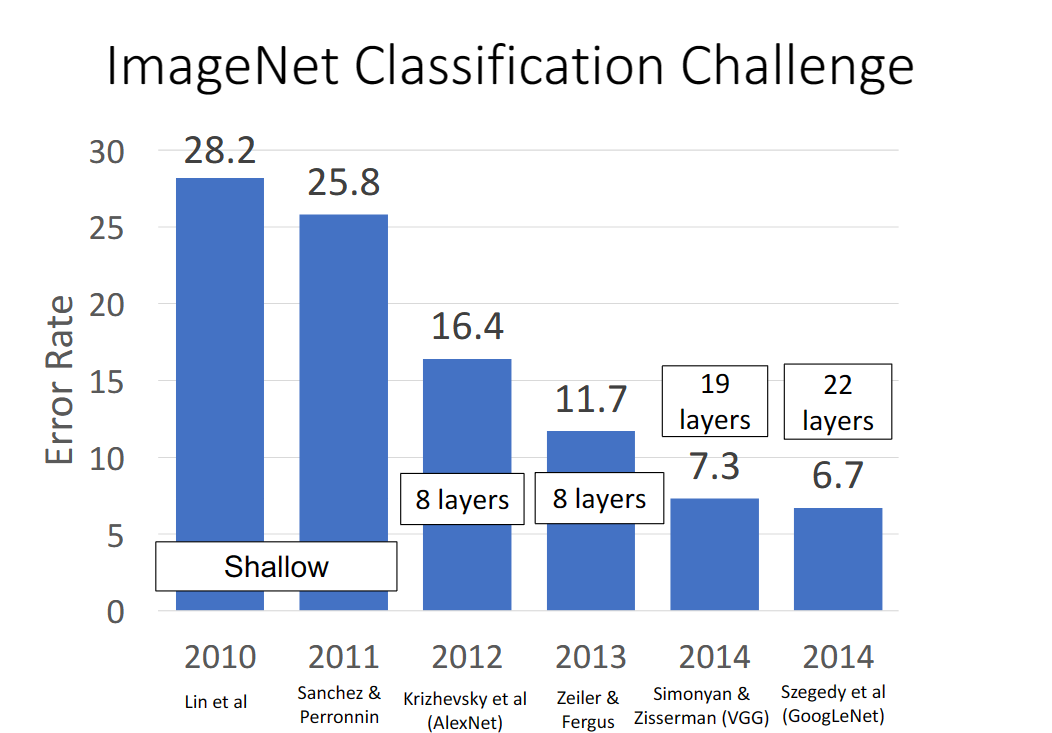
但是同樣在2014年提出的Googlenet網路中,不再強調更大更深的神經網路,因為谷歌想要在更低要求的裝置下,去追求效率,這意味著減少記憶體容量的使用,可學習引數的數目以及浮點運算的次數
為了實現上面的目標,googlenet做出了很多的努力
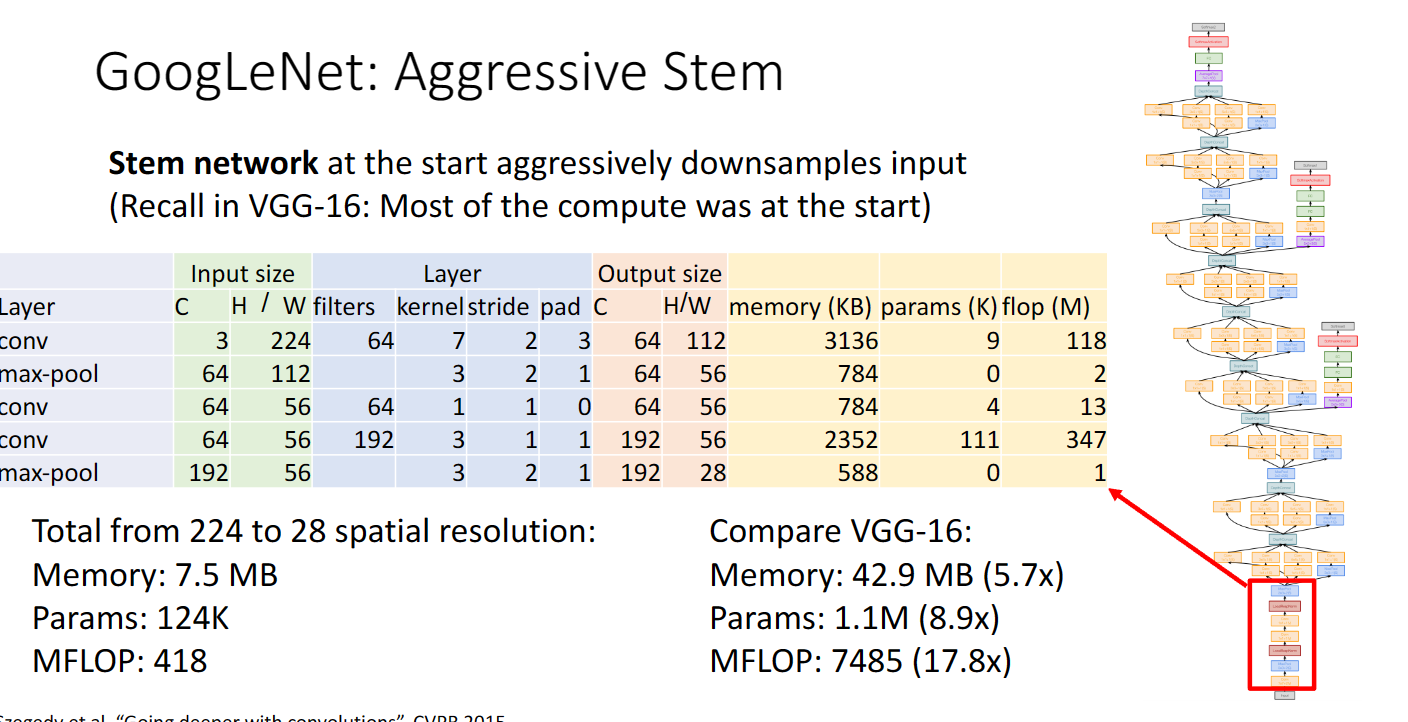
首先,在網路最開始,Googlenet採用了非常激進地下取樣,使用了步長與折積核都比較大的折積層以及池化層,我們可以看到是直接從224維度降到了28,同時記憶體,引數,浮點運算也大幅下降:
其次,Googlenet在網路的中間部分,多次採用了叫Inception Module的結構,我們可以看到它是採用了多個平行分支,在多個尺寸上進行折積再聚合,那麼我們怎麼理解這樣設計呢,可以參考這篇博文:https://zhuanlan.zhihu.com/p/32702031
簡單來說,其實就相當於把傳統折積方式得到的稀疏矩陣,使用不同尺度的折積,我們可以得到密集矩陣,把相關性強的特徵聚集在一起,篩除了冗餘資訊:
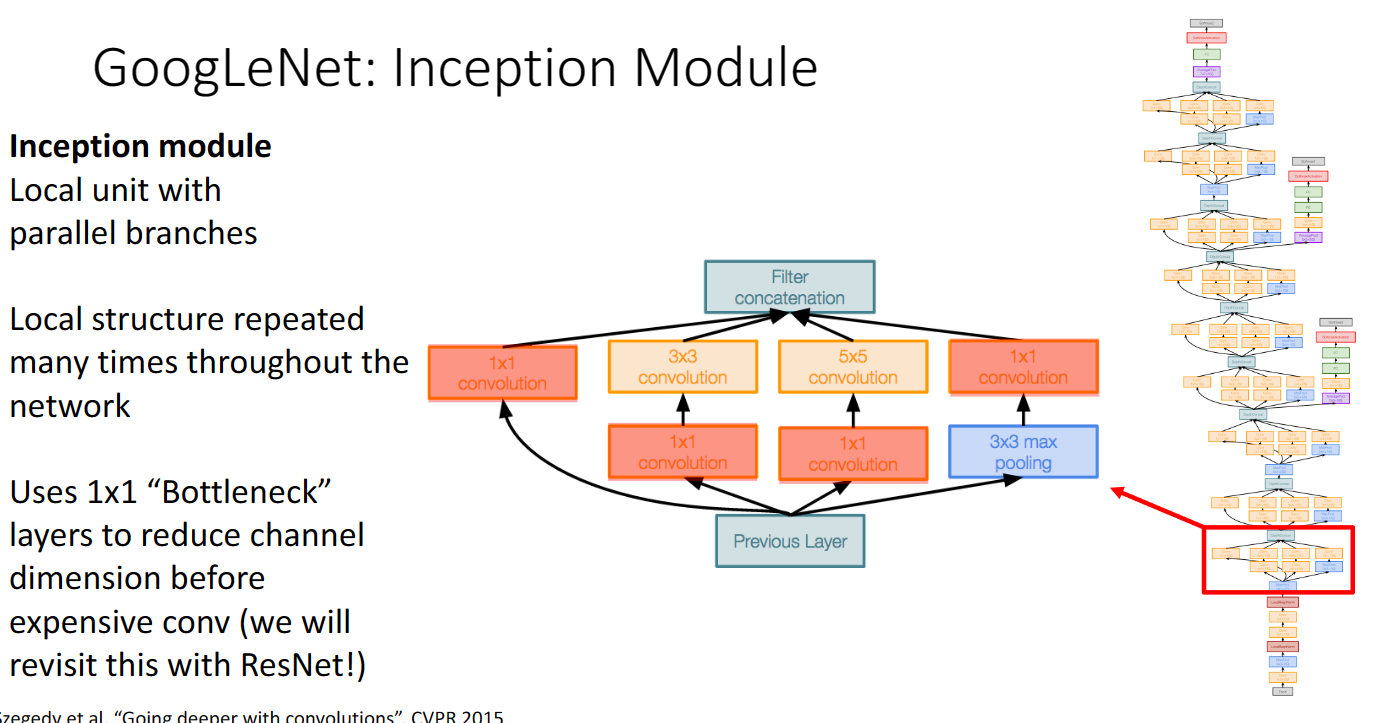
然後,在神經網路的最後,不使用很大的全連線層,而是使用一個平均池化層以及一個全連線層來輸出各分類分數得分,這樣可以大大減少引數,記憶體以及浮點運算次數:
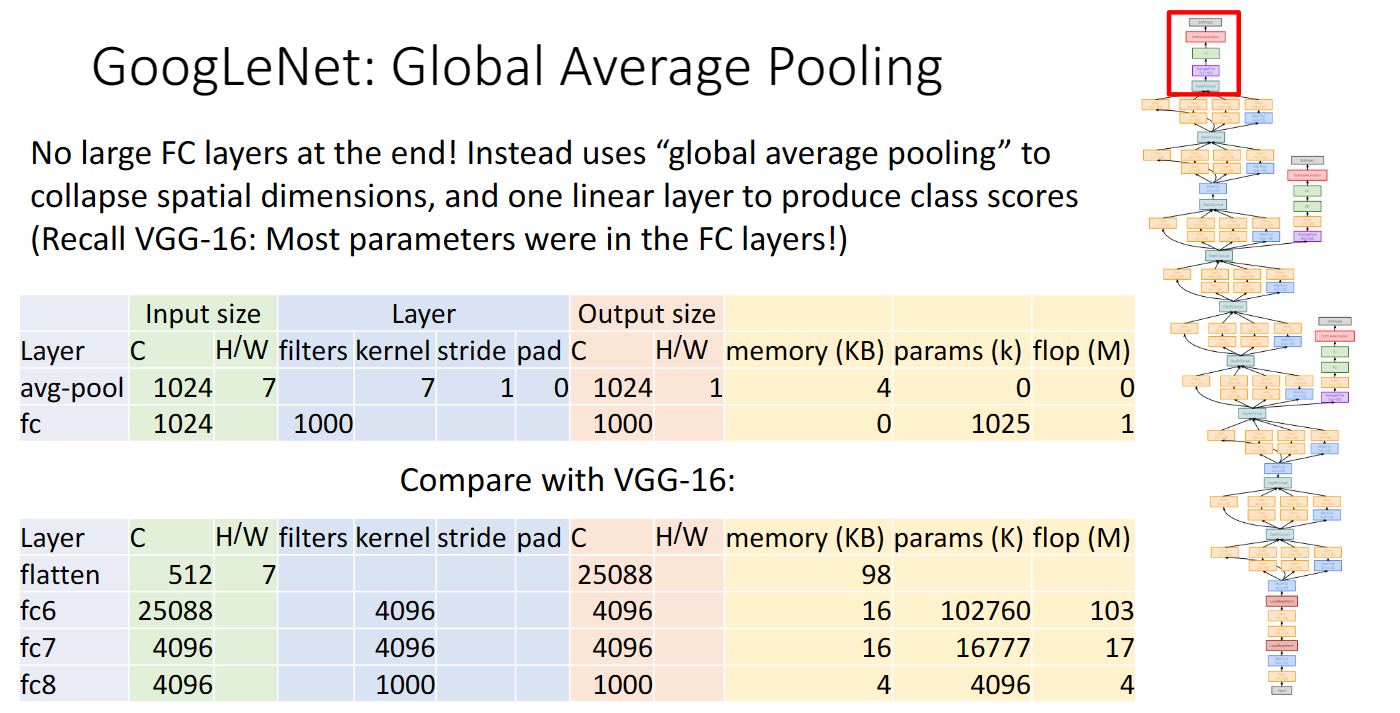
最後,由於神經網路層數過深,梯度傳播效果不佳,可以選擇在其它層數採用和最後結構一樣的結構,提取輸出分類分數,但是這裡是batch normalization還沒有提出的時候,之後我們就不需要這樣做

ResidualNetwork
在batch normalization提出之後,我們可以很輕鬆地訓練深層的網路使其收斂,導致神經網路的層數迅速增加,但是又出現的新的問題,發現深層神經網路反而不如淺層神經網路訓練效果好,甚至出現了欠擬合的情況。
後來就有人(何大神)想出了殘差網路,核心原理可以參見這篇:https://medium.com/@hupinwei/深度學習-resnet之殘差學習-f3ac36701b2f
大概是說過深的神經網路會導致出現退化的情況,有一種辦法就是我們直接堆疊一層和上一層一樣的結果(Identify mapping 恆等對映),更好的辦法是這樣做:
「讓我們先建立以下的概念:
輸入是x
學到的特徵是H(x)
我們定義一個新的名詞,叫做殘差 Residual
Residual = H(x) - x
殘差的概念很直覺吧? 就是學到的特徵和原本的輸入的差異。
既然是Residual = H(x) - x,Residual 也是X的函數,所以也寫作F(x), 那F(x) = H(x) - x
原本學習是這樣的。 x → H(x)
已經知道 F(x) = H(x) - x
所以學習也可以這樣寫:x → F(x) + x
因為H(x) = F(x) + x
用文字來說明的話,
輸入→特徵
變成:輸入→ 輸入 + 殘差
這樣有什麼好處嗎?
如果今天我們多一層,什麼都沒有學到。那殘差就是0
那多這一層,想想我們上面介紹過的,當殘差=0的時候,輸入→ 輸入,這一層就叫做恆等對映,因此,多這一層如果沒學到新的特徵,也不會讓模型退化。實際上當然不會剛好等於0, 而是可以增加很多層,而每一層都可以學到一些新的更複雜的特徵。」
這就是殘差網路中基本的殘差塊的設計思路:
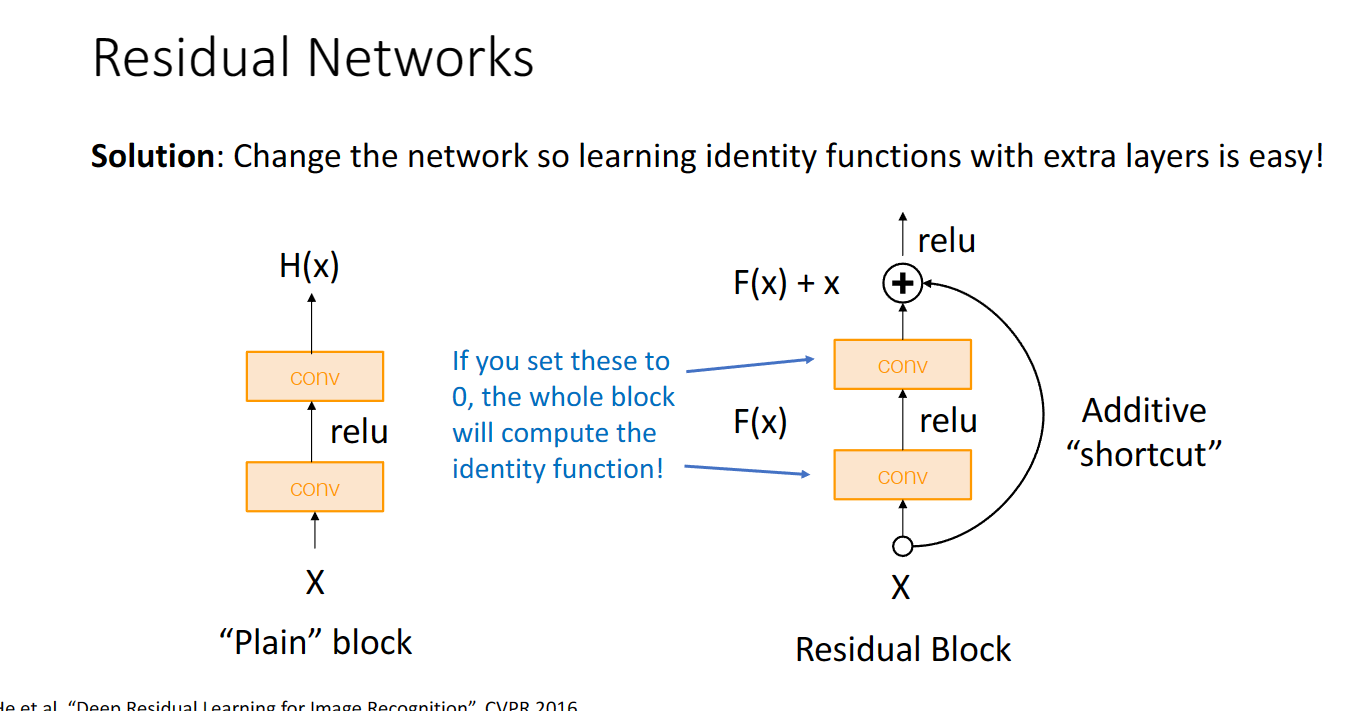
我們把上圖的shortcut加入折積層,再結合之前VGG的中間結構設計,googlenet的首尾設計,剛開始激進地下取樣,最後採用平均池化層與一個線性層輸出結構,就得到了殘差網路的設計:
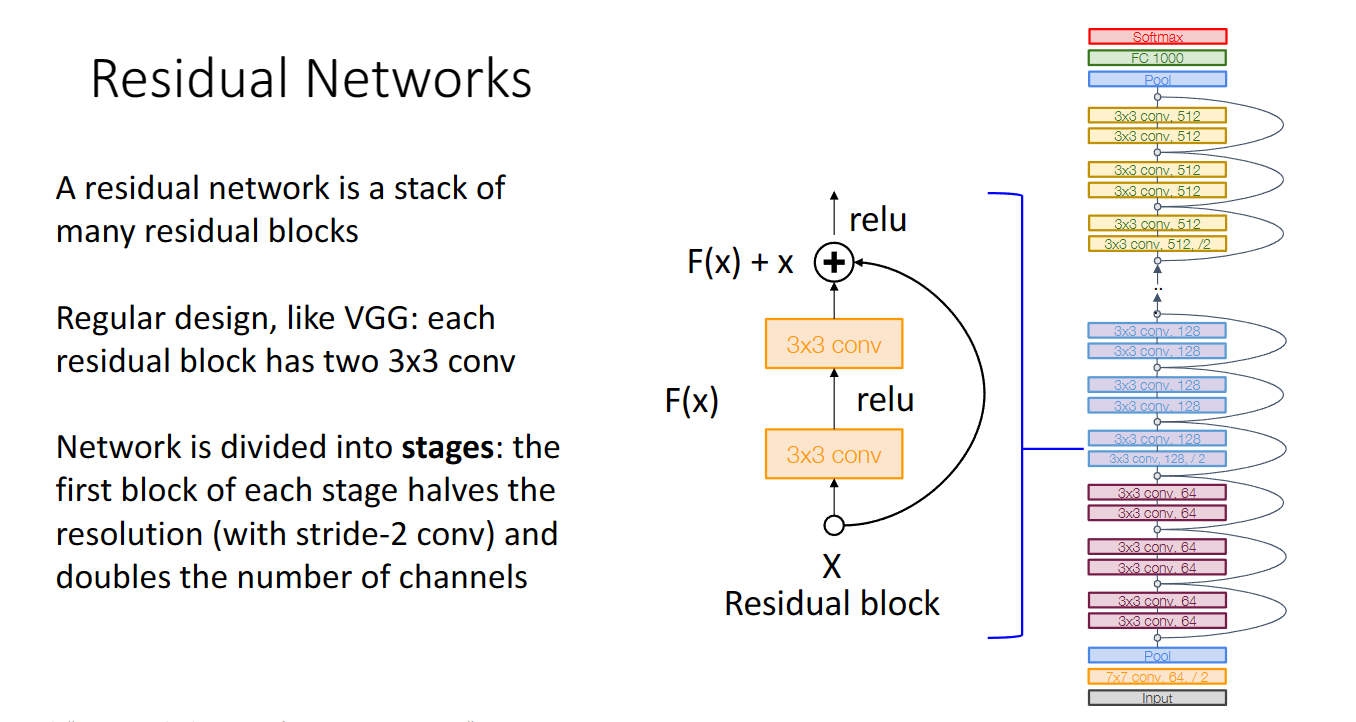

更進一步地,我們可以優化殘差塊的設計,使計算量更小:

我們可以總體看看不同折積網路的複雜度比較:
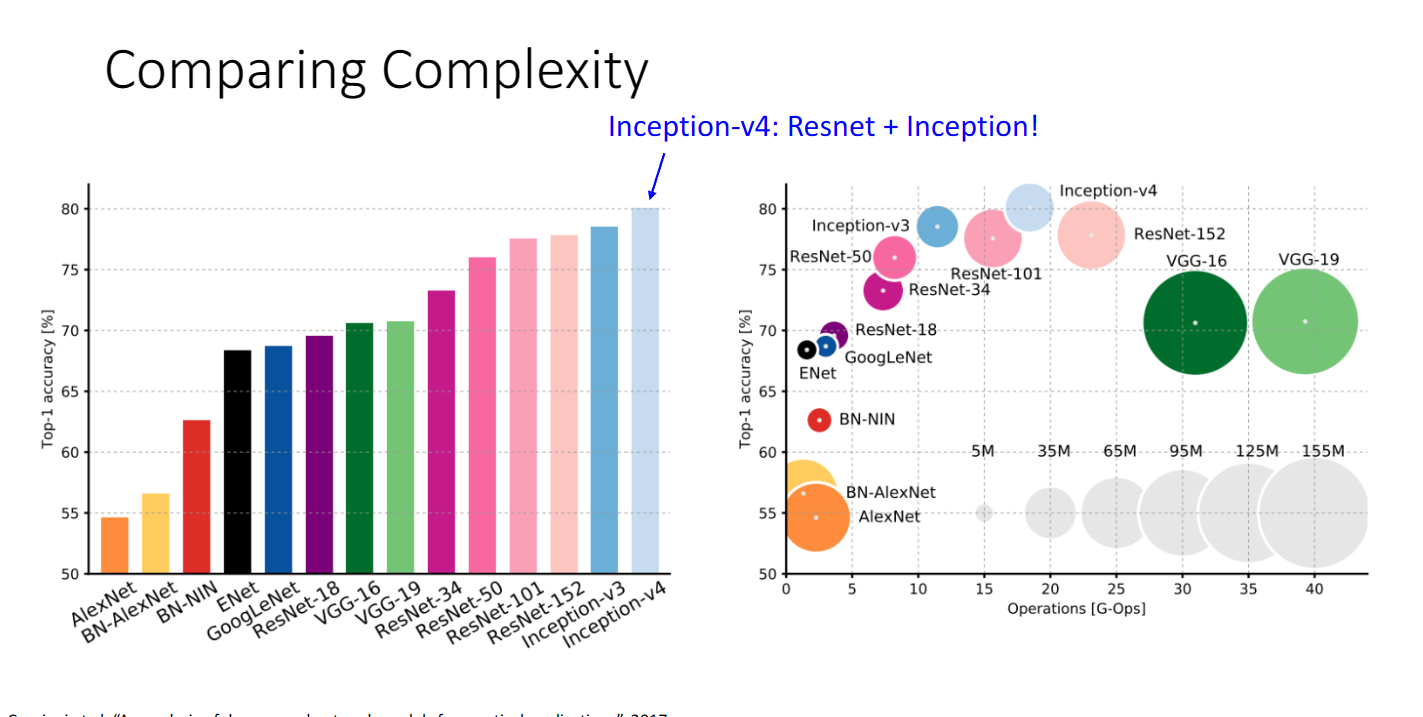
最後提及一些其它更加高效的設計,並沒有詳細地講,我也不是很懂,這裡就再放一張總結圖以及小哥的溫馨提示:

