關於Halcon中variation_model模型的快速解讀。
十一期間在家用期間研讀了下Halcon的variation_model模型,基本上全系復現了他的所有技術要求和細節,這裡做個記錄。
其實這個模型的所有原理都不是很複雜的,而且Halcon中的幫助檔案也講的很是清楚,所以通過猜測、測試、編碼基本能搞清楚是怎麼回事。
關於這個模型,Halcon裡有如下十來個函數:
create_variation_model、prepare_variation_model, train_variation_model、compare_variation_model、prepare_direct_variation_model、clear_variation_model, clear_train_data_variation_model, compare_ext_variation_model, get_thresh_images_variation_model, get_variation_model、 clear_train_data_variation_model, write_variation_model 。
看起來涉及到了蠻多的東西的。
那麼一般的工作流程是:create_variation_model ---> train_variation_model ---> prepare_variation_model ---> compare_variation_model ---> clear_variation_mode。
即: 建立模型,然後訓練模型,接著就是準備模型,這個時候就可以使用了,那麼可以開始做輸入比較了,比較完事了,清楚模型。
所謂的variation_model的模型呢,其實是從一系列已經確認是OK的樣圖中,訓練出2幅結果圖,即上限圖和下限圖,也可以認為是訓練出影象公差帶,當要進行比較的時候,就看輸入的影象的每個畫素是否位於這個公差帶之類,如果是,則這個點是合格的,不是,則這個畫素點就是不合格的區域。
那麼在Halcon中,把這個工作就分解為了上面這一大堆函數。我們稍微來對每個函數做個解析。
一、create_variation_model 建立模型。
這個運算元有如下幾個引數:
create_variation_model( : : Width, Height, Type, Mode : ModelID)
這裡主要是注意Type和Mode兩個引數。
其中Type可以取'byte', 'int2', 'uint2' 這三種型別,我這裡的解讀是這個運算元支援我們常用的8位元灰度影象 和 16位元的Raw影象, 16位元因為有signed short和unsigned short,所有這裡也有int2 和uint2兩種型別。
Mode引數有3個選擇,: 'standard', 'robust', 'direct',這也是這個運算元的靈魂所在,具體的做法後續再說,在建立時只是儲存了他們的值,並沒有做什麼。
那麼建立的工作要做的一個事情就是分配記憶體,Halcon裡的幫助文章是這樣描述的:
A variation model created with create_variation_model requires 12*Width*Height bytes of memory for Mode = 'standard' and Mode = 'robust' for Type = 'byte'. For Type = 'uint2' and Type = 'int2', 14*Width*Height are required. For Mode = 'direct' and after the training data has been cleared with clear_train_data_variation_model, 2*Width*Height bytes are required for Type = 'byte' and 4*Width*Height for the other image types.
為什麼是這樣的記憶體,我們後續再說,接著看下一個函數。
二、train_variation_model 訓練模型
這個運算元是這個功能的最有特色的地方,他用於計算出variation_model 模型中的 ideal image和 variation image,即理想影象和方差影象。
當Mode選擇 'standard', 'robust'時,此運算元有效,當Mode為'direct'無效。
Mode為 'standard'時,訓練採用求多幅平均值的方式獲取理想影象以及對應的方差影象,Mode為 'robust'時,採用,求多幅影象的中間值的方式獲取理想影象以及對應的方差影象。
注意,這裡的求均值和方差是針對同一座標位置,不同影象而言的,而不是針對單一影象領域而言,這個概念一定不能能錯了,比如訓練5副影象,他們某一行的對應位置資料分別為:
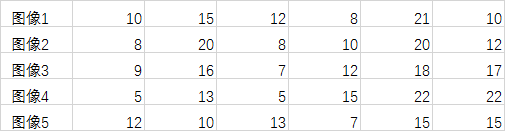
當選擇模式為 'standard',訓練結果的 ideal image 值應該是(實際還需要四捨五入求整):

當選擇模式為 'robust',訓練結果的 ideal image 值應該是:

當選擇'standard'模式,我們可以在找到一副OK影象的時候,單獨把這幅影象的資料訓練到variation_model模型,而如果使用'robust'方式,則必須一次性把所有的OK影象新增到訓練模型中,無法動態的新增物件,但是,由於'robust'模式採用的是中值的方式,因此,其抗噪音效果要好很多。
為什麼'standard'模式可以隨時新增,而'robust'只能一次性新增,其實這個也很簡單,前一次求平均值的資訊如果臨時儲存了,那麼在新的OK圖需要新增時,可以直接利用前一次的有關資訊進行溝通,而如果是採用求中值的方式,前面的排序資訊一是難以儲存(資料量大),二是即使儲存了,對本次排序的作用也不大。
這個時候我們停來下分析下前面Halcon檔案裡的提出的variation_model模型的記憶體佔用大小,假如我們的Type是byte型別,使用'standard'模式,那麼Ideal Image佔用一份Width*Height位元組記憶體,variation image必須是浮點型別的,佔用 4 * Width*Height位元組記憶體,另外,我們能隨時新增新的OK的影象,應該還需要一個臨時的int 型別的資料儲存累加值(雖然Ideal Image儲存了平均值,但是他是已經進行了取捨了, 精度不夠),這需要額外的4 * Width*Height位元組記憶體,後面我們提到variation_model還需要有2個width * height自己大小的記憶體用來儲存上限和下限的影象資料,因此這裡就有大概 1 + 4 + 4 + 2 = 11 * width * height的記憶體了,還差一個,呵呵,不知道幹啥的了。
選擇'robust'模式時, ideal image好說,就是取中間值,但是對於variation image,並不是普通的方差影象,在halcon中時這樣描述的:The corresponding variation image is computed as a suitably scaled median absolute deviation of the training images and the median image at the respective image positions,實際上,他這裡是計算的絕對中位差,即計算下面這個數的中間值了。
MAD=median(∣X−median(X)∣)
這個還需要舉例說明嗎????
對於使用‘standard’模式的計算優化,也是有很多技巧的,不過這個應該很多人能掌握吧。但是如果是'robust'模式,直接寫求中值的方法大家應該都會,但是因為這是個小規模大批次的排序和求中值的過程,其實是非常耗時的,比如W = 1000, H=1000,如果訓練20副影象,那麼就是1000*1000 = 100萬個20個數位的排序,而且還涉及到到一個非常嚴重的cache miss問題。 即這20個數位的讀取每次都是跨越很大的記憶體地址差異的。
如何提高這個排序的過程,我覺得在這裡指令集是有最大的優勢的,他有兩個好處,一是一次性處理多個位元組,比如SSE處理16個位元組,這樣我也就可以一次性載入16個位元組,整體而言就少了很多次cache miss,第二,如果我需要利用指令集,則我需要儘量的避免條件判斷,因此,很多稍微顯得高階一點的排序都不太合適,我需要找到那種固定迴圈次數的最為有效,比如氣泡排序,他就是固定的迴圈次數。
對於N個影象的逐畫素排序求中值,一個簡單的C程式碼如下所示:

純C程式碼的話,這個的效率絕對不是最高的,有很多優秀的排序演演算法都可以比這個快很多。但是他是最簡單,也是最簡潔的,最適合進行SIMD優化的。 看到中間的X迴圈了嗎,那就是他主要的計算量所在,這個迴圈用指令集優化是不是很簡單。
有人說這個迴圈就是個典型的判斷分支語句啊,你剛剛說要避免分支,這明顯不就是個矛盾嗎,那麼我如果把這個迴圈這樣寫呢:

他們結果是不是一樣,還有分支嗎,好了,到這一步,後面的SIMD指令應該不需要我說怎麼寫了吧,_mm_min_epu8 + _mm_max_epu8。
至於median absolute deviation的中值的計算,除了需要計算MAD值之外,其他有任何區別嗎? MAD不恰好也可以用byte型別來記錄嗎,應該懂了吧。
三、prepare_variation_model 準備模型
這個運算元的有如下幾個引數:
prepare_variation_model( : : ModelID, AbsThreshold, VarThreshold : )
這個運算元實際上是根據前面的訓練結果結合輸入的 AbsThreshold和VarThreshold引數確定最終的上限和下限影象,即確認公差帶。
Halcon內部的計算公式為:

i(x,y)是前面得到的Ideal Image, v(x,y)為variation image, au/al/bu/bl即為運算元的輸入引數。這個沒有啥好說的,具體可以看Halcon的幫助檔案。
四、 compare_variation_model 比較模型
運算元原型為: compare_variation_model(Image : Region : ModelID : )
經過前面的一些列操作,我們的準備工作就完成了,現在可以用來進行檢測了,檢測的依據如下式:

即在公差帶內的影象為合格部分,否則為不合格部分。
五、其他運算元
clear_variation_model -- 刪除模型資料,這個沒啥好說的
prepare_direct_variation_model -- 直接準備模型資料,這個在Mode設定為direct時有效,他無需經過訓練,直接設定上下限資料,一般不使用
clear_train_data_variation_model -- 清除訓練資料,當我們訓練完成後,那個Ideal Image 、variation image、臨時資料等等都是沒有用的了,都可以釋放掉,只需要保留上下限的資料了。
還有幾個運算元沒有必要說了吧。
總的來說,這是個比較簡單的運算元,實際應用中可能還需要結合模版匹配等等定位元運算,然後在對映影象等,當然也有特殊場合可以直接使用的。
我這裡做了一個DEMO,有興趣的朋友可以試用一下: https://files.cnblogs.com/files/Imageshop/Variation_Model.rar?t=1697790804&download=true