Go 函數的健壯性、panic例外處理、defer 機制
Go 函數的健壯性、panic例外處理、defer 機制

一、函數健壯性的「三不要」原則
1.1 原則一:不要相信任何外部輸入的引數
函數的使用者可能是任何人,這些人在使用函數之前可能都沒有閱讀過任何手冊或檔案,他們會向函數傳入你意想不到的引數。因此,為了保證函數的健壯性,函數需要對所有輸入的引數進行合法性的檢查。一旦發現問題,立即終止函數的執行,返回預設的錯誤值。
1.2 原則二:不要忽略任何一個錯誤
在我們的函數實現中,也會呼叫標準庫或第三方包提供的函數或方法。對於這些呼叫,我們不能假定它一定會成功,我們一定要顯式地檢查這些呼叫返回的錯誤值。一旦發現錯誤,要及時終止函數執行,防止錯誤繼續傳播。
1.3 原則三:不要假定異常不會發生
這裡,我們先要確定一個認知:異常不是錯誤。錯誤是可預期的,也是經常會發生的,我們有對應的公開錯誤碼和錯誤處理預案,但異常卻是少見的、意料之外的。通常意義上的異常,指的是硬體異常、作業系統異常、語言執行時異常,還有更大可能是程式碼中潛在 bug 導致的異常,比如程式碼中出現了以 0 作為分母,或者是陣列越界存取等情況。
雖然異常發生是「小眾事件」,但是我們不能假定異常不會發生。所以,函數設計時,我們就需要根據函數的角色和使用場景,考慮是否要在函數內設定異常捕捉和恢復的環節。
二、Go 語言中的異常:panic
2.1 panic 例外處理介紹
不同程式語言表示異常(Exception)這個概念的語法都不相同。在 Go 語言中,異常這個概念由 panic 表示。
panic 指的是 Go 程式在執行時出現的一個異常情況。如果異常出現了,但沒有被捕獲並恢復,Go 程式的執行就會被終止,即便出現異常的位置不在主 Goroutine 中也會這樣。
在 Go 中,panic 主要有兩類來源,一類是來自 Go 執行時,另一類則是 Go 開發人員通過 panic 函數主動觸發的。無論是哪種,一旦 panic 被觸發,後續 Go 程式的執行過程都是一樣的,這個過程被 Go 語言稱為 panicking。
2.2 panicking 的過程
Go 官方檔案以手工呼叫 panic 函數觸發 panic 為例,對 panicking 這個過程進行了詮釋:當函數 F 呼叫 panic 函數時,函數 F 的執行將停止。不過,函數 F 中已進行求值的 deferred 函數都會得到正常執行,執行完這些 deferred 函數後,函數 F 才會把控制權返還給其呼叫者。
對於函數 F 的呼叫者而言,函數 F 之後的行為就如同呼叫者呼叫的函數是 panic 一樣,該 panicking 過程將繼續在棧上進行下去,直到當前 Goroutine 中的所有函數都返回為止,然後 Go 程式將崩潰退出。
package main
import "fmt"
func main() {
f()
fmt.Println("Returned normally from f.")
}
func f() {
defer func() {
if r := recover(); r != nil {
fmt.Println("Recovered in f", r)
}
}()
fmt.Println("Calling g.")
g(0)
fmt.Println("Returned normally from g.")
}
func g(i int) {
if i > 3 {
fmt.Println("Panicking!")
panic(fmt.Sprintf("%v", i))
}
defer fmt.Println("Defer in g", i)
fmt.Println("Printing in g", i)
g(i + 1)
}
下面,我們用一個例子來更直觀地解釋一下 panicking 這個過程:
func foo() {
println("call foo")
bar()
println("exit foo")
}
func bar() {
println("call bar")
panic("panic occurs in bar")
zoo()
println("exit bar")
}
func zoo() {
println("call zoo")
println("exit zoo")
}
func main() {
println("call main")
foo()
println("exit main")
}
上面這個例子中,從 Go 應用入口開始,函數的呼叫次序依次為 main -> foo -> bar -> zoo。在 bar 函數中,我們呼叫 panic 函數手動觸發了 panic。
我們執行這個程式的輸出結果是這樣的:
call main
call foo
call bar
panic: panic occurs in bar
根據前面對 panicking 過程的詮釋,理解一下這個例子。
這裡,程式從入口函數 main 開始依次呼叫了 foo、bar 函數,在 bar 函數中,程式碼在呼叫 zoo 函數之前呼叫了 panic 函數觸發了異常。那範例的 panicking 過程就從這開始了。bar 函數呼叫 panic 函數之後,它自身的執行就此停止了,所以我們也沒有看到程式碼繼續進入 zoo 函數執行。並且,bar 函數沒有捕捉這個 panic,這樣這個 panic 就會沿著函數呼叫棧向上走,來到了 bar 函數的呼叫者 foo 函數中。
從 foo 函數的視角來看,這就好比將它對 bar 函數的呼叫,換成了對 panic 函數的呼叫一樣。這樣一來,foo 函數的執行也被停止了。由於 foo 函數也沒有捕捉 panic,於是 panic 繼續沿著函數呼叫棧向上走,來到了 foo 函數的呼叫者 main 函數中。
同理,從 main 函數的視角來看,這就好比將它對 foo 函數的呼叫,換成了對 panic 函數的呼叫一樣。結果就是,main 函數的執行也被終止了,於是整個程式異常退出,紀錄檔"exit main"也沒有得到輸出的機會。
2.3 recover 函數介紹
recover 是Go語言中的一個內建函數,用於在發生 panic 時捕獲並處理 panic,以便程式能夠繼續執行而不會完全崩潰。以下是有關 recover 函數的介紹:
- 用途:
recover用於恢復程式的控制權,防止程式因panic而崩潰。它通常與defer一起使用,用於在發生異常情況時執行一些清理操作、記錄錯誤資訊或者嘗試恢復程式狀態。 - 工作原理:當程式進入
panic狀態時,recover可以用來停止panic的傳播。它會返回導致panic的值(通常是一個錯誤資訊),允許程式捕獲這個值並採取適當的措施。如果recover在當前函數內沒有找到可捕獲的panic,它會返回nil。 - 與
panic配合使用:通常,recover會與defer一起使用。在defer中使用recover,可以確保在函數返回之前檢查panic狀態並採取適當的措施。 - 侷限性:
recover只能用於捕獲最近一次的panic,它不能用於捕獲之前的panic。一旦recover成功捕獲了一個panic,它會重置panic狀態,因此無法繼續捕獲之前的panic。
接著,我們繼續用上面這個例子分析,在觸發 panic 的 bar 函數中,對 panic 進行捕捉並恢復,我們直接來看恢復後,整個程式的執行情況是什麼樣的。這裡,我們只列出了變更後的 bar 函數程式碼,其他函數程式碼並沒有改變,程式碼如下:
package main
import "fmt"
func foo() {
println("call foo")
bar()
println("exit foo")
}
// func bar() {
// println("call bar")
// panic("panic occurs in bar")
// zoo()
// println("exit bar")
// }
func bar() {
defer func() {
if e := recover(); e != nil {
fmt.Println("recover the panic:", e)
}
}()
println("call bar")
panic("panic occurs in bar")
zoo()
println("exit bar")
}
func zoo() {
println("call zoo")
println("exit zoo")
}
func main() {
println("call main")
foo()
println("exit main")
}
在更新版的 bar 函數中,我們在一個 defer 匿名函數中呼叫 recover 函數對 panic 進行了捕捉。recover 是 Go 內建的專門用於恢復 panic 的函數,它必須被放在一個 defer 函數中才能生效。如果 recover 捕捉到 panic,它就會返回以 panic 的具體內容為錯誤上下文資訊的錯誤值。如果沒有 panic 發生,那麼 recover 將返回 nil。而且,如果 panic 被 recover 捕捉到,panic 引發的 panicking 過程就會停止。
我們執行更新後的程式,得到如下結果:
call main
call foo
call bar
recover the panic: panic occurs in bar
exit foo
exit main
我們可以看到 main 函數終於得以「善終」。那這個過程中究竟發生了什麼呢?
在更新後的程式碼中,當 bar 函數呼叫 panic 函數觸發異常後,bar 函數的執行就會被中斷。但這一次,在程式碼執行流回到 bar 函數呼叫者之前,bar 函數中的、在 panic 之前就已經被設定成功的 derfer 函數就會被執行。這個匿名函數會呼叫 recover 把剛剛觸發的 panic 恢復,這樣,panic 還沒等沿著函數棧向上走,就被消除了。
所以,這個時候,從 foo 函數的視角來看,bar 函數與正常返回沒有什麼差別。foo 函數依舊繼續向下執行,直至 main 函數成功返回。這樣,這個程式的 panic「危機」就解除了。
面對有如此行為特點的 panic,我們應該如何應對呢?是不是在所有 Go 函數或方法中,我們都要用 defer 函數來捕捉和恢復 panic 呢?
三、如何應對 panic?
其實大可不必。一來,這樣做會徒增開發人員函數實現時的心智負擔。二來,很多函數非常簡單,根本不會出現 panic 情況,我們增加 panic 捕獲和恢復,反倒會增加函數的複雜性。同時,defer 函數也不是「免費」的,也有帶來效能開銷。
日常情況下,我們應該採取以下3點經驗。
3.1 第一點:評估程式對 panic 的忍受度
首先,我們應該知道一個事實:不同應用對異常引起的程式崩潰退出的忍受度是不一樣的。比如,一個單次執行於控制檯視窗中的命令列互動類程式(CLI),和一個常駐記憶體的後端 HTTP 伺服器程式,對異常崩潰的忍受度就是不同的。
前者即便因異常崩潰,對使用者來說也僅僅是再重新執行一次而已。但後者一旦崩潰,就很可能導致整個網站停止服務。所以,針對各種應用對 panic 忍受度的差異,我們採取的應對 panic 的策略也應該有不同。像後端 HTTP 伺服器程式這樣的任務關鍵系統,我們就需要在特定位置捕捉並恢復 panic,以保證伺服器整體的健壯度。在這方面,Go 標準庫中的 http server 就是一個典型的代表。
Go 標準庫提供的 http server 採用的是,每個使用者端連線都使用一個單獨的 Goroutine 進行處理的並行處理模型。也就是說,使用者端一旦與 http server 連線成功,http server 就會為這個連線新建立一個 Goroutine,並在這 Goroutine 中執行對應連線(conn)的 serve 方法,來處理這條連線上的使用者端請求。
前面提到了 panic 的「危害」時,我們說過,無論在哪個 Goroutine 中發生未被恢復的 panic,整個程式都將崩潰退出。所以,為了保證處理某一個使用者端連線的 Goroutine 出現 panic 時,不影響到 http server 主 Goroutine 的執行,Go 標準庫在 serve 方法中加入了對 panic 的捕捉與恢復,下面是 serve 方法的部分程式碼片段:
// $GOROOT/src/net/http/server.go
// Serve a new connection.
func (c *conn) serve(ctx context.Context) {
c.remoteAddr = c.rwc.RemoteAddr().String()
ctx = context.WithValue(ctx, LocalAddrContextKey, c.rwc.LocalAddr())
defer func() {
if err := recover(); err != nil && err != ErrAbortHandler {
const size = 64 << 10
buf := make([]byte, size)
buf = buf[:runtime.Stack(buf, false)]
c.server.logf("http: panic serving %v: %v\n%s", c.remoteAddr, err, buf)
}
if !c.hijacked() {
c.close()
c.setState(c.rwc, StateClosed, runHooks)
}
}()
... ...
}
可以看到,serve 方法在一開始處就設定了 defer 函數,並在該函數中捕捉並恢復了可能出現的 panic。這樣,即便處理某個使用者端連線的 Goroutine 出現 panic,處理其他連線 Goroutine 以及 http server 自身都不會受到影響。
這種區域性不要影響整體的例外處理策略,在很多並行程式中都有應用。並且,捕捉和恢復 panic 的位置通常都在子 Goroutine 的起始處,這樣設定可以捕捉到後面程式碼中可能出現的所有 panic,就像 serve 方法中那樣。
3.2 第二點:提示潛在 bug
有了對 panic 忍受度的評估,panic 也沒有那麼「恐怖」,而且,我們甚至可以藉助 panic 來幫助我們快速找到潛在 bug。
Go 語言標準庫中並沒有提供斷言之類的輔助函數,但我們可以使用 panic,部分模擬斷言對潛在 bug 的提示功能。比如,下面就是標準庫 encoding/json包使用 panic 指示潛在 bug 的一個例子:
// $GOROOT/src/encoding/json/decode.go
... ...
//當一些本不該發生的事情導致我們結束處理時,phasePanicMsg將被用作panic訊息
//它可以指示JSON解碼器中的bug,或者
//在解碼器執行時還有其他程式碼正在修改資料切片。
const phasePanicMsg = "JSON decoder out of sync - data changing underfoot?"
func (d *decodeState) init(data []byte) *decodeState {
d.data = data
d.off = 0
d.savedError = nil
if d.errorContext != nil {
d.errorContext.Struct = nil
// Reuse the allocated space for the FieldStack slice.
d.errorContext.FieldStack = d.errorContext.FieldStack[:0]
}
return d
}
func (d *decodeState) valueQuoted() interface{} {
switch d.opcode {
default:
panic(phasePanicMsg)
case scanBeginArray, scanBeginObject:
d.skip()
d.scanNext()
case scanBeginLiteral:
v := d.literalInterface()
switch v.(type) {
case nil, string:
return v
}
}
return unquotedValue{}
}
我們看到,在 valueQuoted 這個方法中,如果程式執行流進入了 default 分支,那這個方法就會引發 panic,這個 panic 會提示開發人員:這裡很可能是一個 bug。
同樣,在 json 包的 encode.go 中也有使用 panic 做潛在 bug 提示的例子:
// $GOROOT/src/encoding/json/encode.go
func (w *reflectWithString) resolve() error {
... ...
switch w.k.Kind() {
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
w.ks = strconv.FormatInt(w.k.Int(), 10)
return nil
case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
w.ks = strconv.FormatUint(w.k.Uint(), 10)
return nil
}
panic("unexpected map key type")
}
這段程式碼中,resolve 方法的最後一行程式碼就相當於一個「程式碼邏輯不會走到這裡」的斷言。一旦觸發「斷言」,這很可能就是一個潛在 bug。
我們也看到,去掉這行程式碼並不會對 resolve 方法的邏輯造成任何影響,但真正出現問題時,開發人員就缺少了「斷言」潛在 bug 提醒的輔助支援了。在 Go 標準庫中,大多數 panic 的使用都是充當類似斷言的作用的。
3.3 第三點:不要混淆異常與錯誤
在日常編碼中,一些 Go 語言初學者,尤其是一些有過Python,Java等語言程式設計經驗的程式設計師,會因為習慣了 Python 那種基於try-except 的錯誤處理思維,而將 Go panic 當成Python 的「checked exception」去用,這顯然是混淆了 Go 中的異常與錯誤,這是 Go 錯誤處理的一種反模式。
檢視Python 標準類庫,我們可以看到一些 Java 已預定義好的 checked exception 類,比較常見的有ValueError、TypeError等等。看到這裡,這些 checked exception 都是預定義好的、代表特定場景下的錯誤狀態。
那 Python 的 checked exception 和 Go 中的 panic 有啥差別呢?
Python 的 checked exception 用於一些可預見的、常會發生的錯誤場景,比如,針對 checked exception 的所謂「例外處理」,就是針對這些場景的「錯誤處理預案」。也可以說對 checked exception 的使用、捕獲、自定義等行為都是「有意而為之」的。
如果它非要和 Go 中的某種語法對應來看,它對應的也是 Go 的錯誤處理,也就是基於 error 值比較模型的錯誤處理。所以,Python 中對 checked exception 處理的本質是錯誤處理,雖然它的名字用了帶有「異常」的字樣。
而 Go 中的 panic 呢,更接近於 Python 的 RuntimeException,而不是 checked exception 。我們前面提到過 Python 的 checked exception 是必須要被上層程式碼處理的,也就是要麼捕獲處理,要麼重新拋給更上層。但是在 Go 中,我們通常會匯入大量第三方包,而對於這些第三方包 API 中是否會引發 panic ,我們是不知道的。
因此上層程式碼,也就是 API 呼叫者根本不會去逐一瞭解 API 是否會引發panic,也沒有義務去處理引發的 panic。一旦你在編寫的 API 中,像 checked exception 那樣使用 panic 作為正常錯誤處理的手段,把引發的 panic 當作錯誤,那麼你就會給你的 API 使用者帶去大麻煩!因此,在 Go 中,作為 API 函數的作者,你一定不要將 panic 當作錯誤返回給 API 呼叫者。
四、defer 函數
在Go語言中,defer 是一種用於延遲執行函數或方法呼叫的機制。它通常用於執行清理操作、資源釋放、紀錄檔記錄等,以確保在函數返回之前進行這些操作。下面是有關 defer 函數的介紹和如何使用它來簡化函數實現的內容:
4.1 defer 函數介紹
- 延遲執行:
defer允許將一個函數或方法呼叫推遲到當前函數返回之前執行,無論是正常返回還是由於panic引起的異常返回。 - 執行順序:多個
defer語句按照後進先出(LIFO)的順序執行,即最後一個註冊的defer最先執行,倒數第二個註冊的defer在其後執行,以此類推。 - 常見用途:
defer常用於資源管理,例如檔案關閉、互斥鎖的釋放、資料庫連線的關閉等,也用於執行一些必要的清理工作或紀錄檔記錄。 - 不僅限於函數呼叫:
defer不僅可以用於函數呼叫,還可以用於方法呼叫,匿名函數的執行等。
4.2 使用 defer 簡化函數實現
對函數設計來說,如何實現簡潔的目標是一個大話題。你可以從通用的設計原則去談,比如函數要遵守單一職責,職責單一的函數肯定要比擔負多種職責的函數更簡單。你也可以從函數實現的規模去談,比如函數體的規模要小,儘量控制在 80 行程式碼之內等。
Go 中提供了defer可以幫助我們簡化 Go 函數的設計和實現。我們用一個具體的例子來理解一下。日常開發中,我們經常會編寫一些類似下面範例中的虛擬碼:
func doSomething() error {
var mu sync.Mutex
mu.Lock()
r1, err := OpenResource1()
if err != nil {
mu.Unlock()
return err
}
r2, err := OpenResource2()
if err != nil {
r1.Close()
mu.Unlock()
return err
}
r3, err := OpenResource3()
if err != nil {
r2.Close()
r1.Close()
mu.Unlock()
return err
}
// 使用r1,r2, r3
err = doWithResources()
if err != nil {
r3.Close()
r2.Close()
r1.Close()
mu.Unlock()
return err
}
r3.Close()
r2.Close()
r1.Close()
mu.Unlock()
return nil
}
我們看到,這類程式碼的特點就是在函數中會申請一些資源,並在函數退出前釋放或關閉這些資源,比如這裡的互斥鎖 mu 以及資源 r1~r3 就是這樣。
函數的實現需要確保,無論函數的執行流是按預期順利進行,還是出現錯誤,這些資源在函數退出時都要被及時、正確地釋放。為此,我們需要尤為關注函數中的錯誤處理,在錯誤處理時不能遺漏對資源的釋放。
但這樣的要求,就導致我們在進行資源釋放,尤其是有多個資源需要釋放的時候,比如上面範例那樣,會大大增加開發人員的心智負擔。同時當待釋放的資源個數較多時,整個程式碼邏輯就會變得十分複雜,程式可讀性、健壯性也會隨之下降。但即便如此,如果函數實現中的某段程式碼邏輯丟擲 panic,傳統的錯誤處理機制依然沒有辦法捕獲它並嘗試從 panic 恢復。
Go 語言引入 defer 的初衷,就是解決這些問題。那麼,defer 具體是怎麼解決這些問題的呢?或者說,defer 具體的運作機制是怎樣的呢?
defer 是 Go 語言提供的一種延遲呼叫機制,defer 的運作離不開函數。怎麼理解呢?這句話至少有以下兩點含義:
- 在 Go 中,只有在函數(和方法)內部才能使用 defer;
- defer 關鍵字後面只能接函數(或方法),這些函數被稱為 deferred 函數。defer 將它們註冊到其所在 Goroutine 中,用於存放 deferred 函數的棧資料結構中,這些 deferred 函數將在執行 defer 的函數退出前,按後進先出(LIFO)的順序被程式排程執行(如下圖所示)。
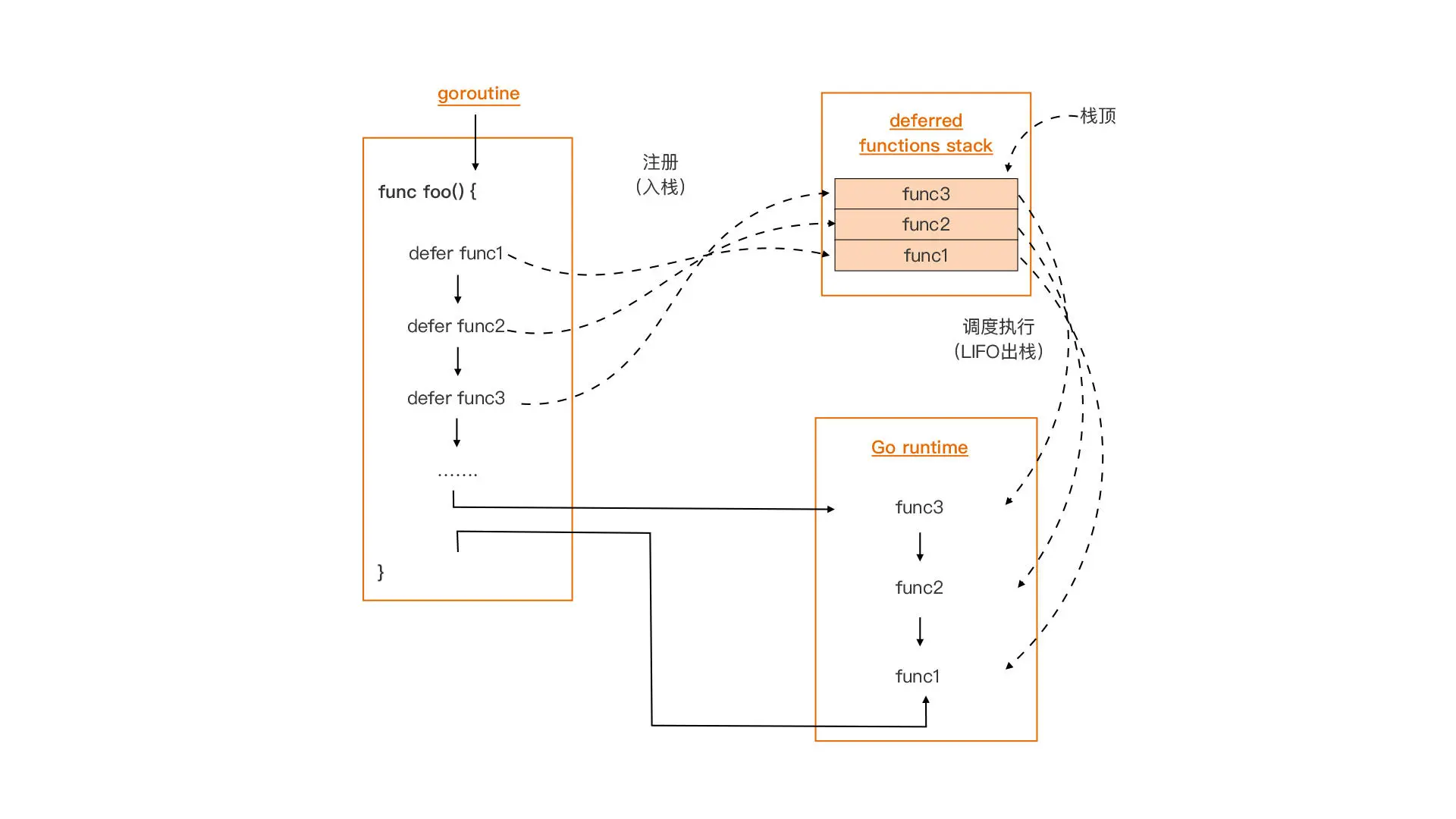
而且,無論是執行到函數體尾部返回,還是在某個錯誤處理分支顯式 return,又或是出現 panic,已經儲存到 deferred 函數棧中的函數,都會被排程執行。所以說,deferred 函數是一個可以在任何情況下為函數進行收尾工作的好「夥伴」。
我們回到剛才的那個例子,如果我們把收尾工作挪到 deferred 函數中,那麼程式碼將變成如下這個樣子:
func doSomething() error {
var mu sync.Mutex
mu.Lock()
defer mu.Unlock()
r1, err := OpenResource1()
if err != nil {
return err
}
defer r1.Close()
r2, err := OpenResource2()
if err != nil {
return err
}
defer r2.Close()
r3, err := OpenResource3()
if err != nil {
return err
}
defer r3.Close()
// 使用r1,r2, r3
return doWithResources()
}
我們看到,使用 defer 後對函數實現邏輯的簡化是顯而易見的。而且,這裡資源釋放函數的 defer 註冊動作,緊鄰著資源申請成功的動作,這樣成對出現的慣例就極大降低了遺漏資源釋放的可能性,我們開發人員也不用再小心翼翼地在每個錯誤處理分支中檢查是否遺漏了某個資源的釋放動作。同時,程式碼的簡化也意味程式碼可讀性的提高,以及程式碼健壯度的增強。
五、defer 使用的幾個注意事項
大多數 Gopher 都喜歡 defer,因為它不僅可以用來捕捉和恢復 panic,還能讓函數變得更簡潔和健壯。但「工欲善其事,必先利其器「,一旦你要用 defer,有幾個關於 defer 使用的注意事項是你一定要提前瞭解清楚的,可以避免掉進一些不必要的「坑」。
5.1 第一點:明確哪些函數可以作為 deferred 函數
這裡,你要清楚,對於自定義的函數或方法,defer 可以給與無條件的支援,但是對於有返回值的自定義函數或方法,返回值會在 deferred 函數被排程執行的時候被自動丟棄。
而且,Go 語言中除了自定義函數 / 方法,還有 Go 語言內建的 / 預定義的函數,這裡我給出了 Go 語言內建函數的完全列表:
Functions:
append cap close complex copy delete imag len
make new panic print println real recover
那麼,Go 語言中的內建函數是否都能作為 deferred 函數呢?我們看下面的範例:
// defer1.go
func bar() (int, int) {
return 1, 2
}
func foo() {
var c chan int
var sl []int
var m = make(map[string]int, 10)
m["item1"] = 1
m["item2"] = 2
var a = complex(1.0, -1.4)
var sl1 []int
defer bar()
defer append(sl, 11)
defer cap(sl)
defer close(c)
defer complex(2, -2)
defer copy(sl1, sl)
defer delete(m, "item2")
defer imag(a)
defer len(sl)
defer make([]int, 10)
defer new(*int)
defer panic(1)
defer print("hello, defer\n")
defer println("hello, defer")
defer real(a)
defer recover()
}
func main() {
foo()
}
執行這個範例程式碼,我們可以得到:
$go run defer1.go
# command-line-arguments
./defer1.go:17:2: defer discards result of append(sl, 11)
./defer1.go:18:2: defer discards result of cap(sl)
./defer1.go:20:2: defer discards result of complex(2, -2)
./defer1.go:23:2: defer discards result of imag(a)
./defer1.go:24:2: defer discards result of len(sl)
./defer1.go:25:2: defer discards result of make([]int, 10)
./defer1.go:26:2: defer discards result of new(*int)
./defer1.go:30:2: defer discards result of real(a)
我們看到,Go 編譯器居然給出一組錯誤提示!
從這組錯誤提示中我們可以看到,append、cap、len、make、new、imag 等內建函數都是不能直接作為 deferred 函數的,而 close、copy、delete、print、recover 等內建函數則可以直接被 defer 設定為 deferred 函數。
不過,對於那些不能直接作為 deferred 函數的內建函數,我們可以使用一個包裹它的匿名函數來間接滿足要求,以 append 為例是這樣的:
defer func() {
_ = append(sl, 11)
}()
5.2 第二點:注意 defer 關鍵字後面表示式的求值時機
這裡,一定要牢記一點:defer 關鍵字後面的表示式,是在將 deferred 函數註冊到 deferred 函數棧的時候進行求值的。
我們同樣用一個典型的例子來說明一下 defer 後表示式的求值時機:
func foo1() {
for i := 0; i <= 3; i++ {
defer fmt.Println(i)
}
}
func foo2() {
for i := 0; i <= 3; i++ {
defer func(n int) {
fmt.Println(n)
}(i)
}
}
func foo3() {
for i := 0; i <= 3; i++ {
defer func() {
fmt.Println(i)
}()
}
}
func main() {
fmt.Println("foo1 result:")
foo1()
fmt.Println("\nfoo2 result:")
foo2()
fmt.Println("\nfoo3 result:")
foo3()
}
這裡,我們一個個分析 foo1、foo2 和 foo3 中 defer 後的表示式的求值時機。
首先是 foo1。foo1 中 defer 後面直接用的是 fmt.Println 函數,每當 defer 將 fmt.Println 註冊到 deferred 函數棧的時候,都會對 Println 後面的引數進行求值。根據上述程式碼邏輯,依次壓入 deferred 函數棧的函數是:
fmt.Println(0)
fmt.Println(1)
fmt.Println(2)
fmt.Println(3)
因此,當 foo1 返回後,deferred 函數被排程執行時,上述壓入棧的 deferred 函數將以 LIFO 次序出棧執行,這時的輸出的結果為:
3
2
1
0
然後我們再看 foo2。foo2 中 defer 後面接的是一個帶有一個引數的匿名函數。每當 defer 將匿名函數註冊到 deferred 函數棧的時候,都會對該匿名函數的引數進行求值。根據上述程式碼邏輯,依次壓入 deferred 函數棧的函數是:
func(0)
func(1)
func(2)
func(3)
因此,當 foo2 返回後,deferred 函數被排程執行時,上述壓入棧的 deferred 函數將以 LIFO 次序出棧執行,因此輸出的結果為:
3
2
1
0
最後我們來看 foo3。foo3 中 defer 後面接的是一個不帶引數的匿名函數。根據上述程式碼邏輯,依次壓入 deferred 函數棧的函數是:
func()
func()
func()
func()
所以,當 foo3 返回後,deferred 函數被排程執行時,上述壓入棧的 deferred 函數將以 LIFO 次序出棧執行。匿名函數會以閉包的方式存取外圍函數的變數 i,並通過 Println 輸出 i 的值,此時 i 的值為 4,因此 foo3 的輸出結果為:
4
4
4
4
通過這些例子,我們可以看到,無論以何種形式將函數註冊到 defer 中,deferred 函數的引數值都是在註冊的時候進行求值的。
5.3 第三點:知曉 defer 帶來的效能損耗
通過前面的分析,我們可以看到,defer 讓我們進行資源釋放(如檔案描述符、鎖)的過程變得優雅很多,也不易出錯。但在效能敏感的應用中,defer 帶來的效能負擔也是我們必須要知曉和權衡的問題。
這裡,我們用一個效能基準測試(Benchmark),直觀地看看 defer 究竟會帶來多少效能損耗。基於 Go 工具鏈,我們可以很方便地為 Go 原始碼寫一個效能基準測試,只需將程式碼放在以「_test.go」為字尾的原始檔中,然後利用 testing 包提供的「框架」就可以了,我們看下面程式碼:
// defer_test.go
package main
import "testing"
func sum(max int) int {
total := 0
for i := 0; i < max; i++ {
total += i
}
return total
}
func fooWithDefer() {
defer func() {
sum(10)
}()
}
func fooWithoutDefer() {
sum(10)
}
func BenchmarkFooWithDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
fooWithDefer()
}
}
func BenchmarkFooWithoutDefer(b *testing.B) {
for i := 0; i < b.N; i++ {
fooWithoutDefer()
}
}
這個基準測試包含了兩個測試用例,分別是 BenchmarkFooWithDefer 和 BenchmarkFooWithoutDefer。前者測量的是帶有 defer 的函數執行的效能,後者測量的是不帶有 defer 的函數的執行的效能。
在 Go 1.13 前的版本中,defer 帶來的開銷還是很大的。我們先用 Go 1.12.7 版本來執行一下上述基準測試,我們會得到如下結果:
$go test -bench . defer_test.go
goos: darwin
goarch: amd64
BenchmarkFooWithDefer-8 30000000 42.6 ns/op
BenchmarkFooWithoutDefer-8 300000000 5.44 ns/op
PASS
ok command-line-arguments 3.511s
從這個基準測試結果中,我們可以清晰地看到:使用 defer 的函數的執行時間是沒有使用 defer 函數的 8 倍左右。
如果我們要用好 defer,前提就是要了解 defer 的運作機制,這裡你要把握住兩點:
- 函數返回前,deferred 函數是按照後入先出(LIFO)的順序執行的;
- defer 關鍵字是在註冊函數時對函數的引數進行求值的。
最後,在最新 Go 版本 Go1.17 中,使用 defer 帶來的開銷幾乎可以忽略不計了,你可以放心使用。