雙陣列字典樹 (Double-array Trie) 實現原理 -- 程式碼 + 圖文,看不懂你來打我
學習HanLP時,碰到了 雙陣列字典樹(Double-Array Trie)的概念,網上找了好多貼子,花了好久才整明白,結合看過的貼文重新做個梳理。
雙陣列字典樹(Double-Array Trie,簡稱DAT或者Darts)就是這樣一種狀態轉移複雜度為常數的資料結構。雙陣列字典樹由日本人Jun-IchiAoe於1989 年提出它由base[]和check[]兩個陣列構成,又簡稱雙陣列。是一種高效的字典樹資料結構,它將字串對映為整數值,常用於字串匹配、字串檢索和詞頻統計等領域。它的原理基於兩個關鍵思想:壓縮儲存和公共字首共用。
優點:Trie 字典樹 是一種 以空間換時間 的資料結構,Trie對記憶體的消耗比較大,DAT正是為了優化該問題而提出,刻服了Tire樹浪費空間的不足。
缺點:在插入和刪除的時,往往需要對雙陣列結構進行全域性調整,靈活效能較差。如果核心詞典已經預先建立好並且有序的,並且不會新增或刪除新詞,那麼這個缺點是可以忽略的。
Trie 字典樹
由 ["清華", "清華大學", "清新", "中華", "華人"] 五個中文詞構成的 Trie 樹形
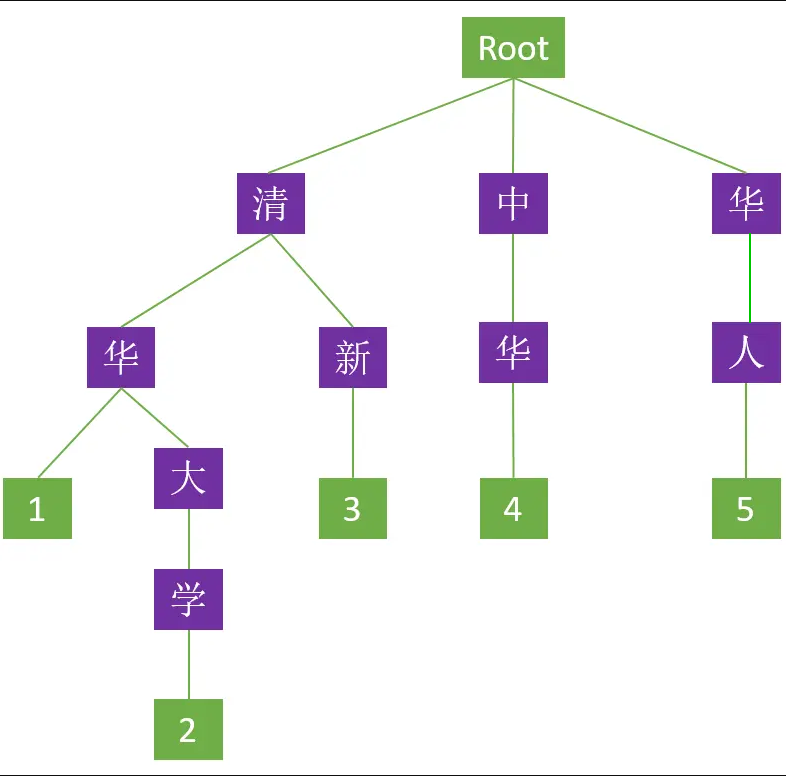
雙陣列Trie樹 構建
雙陣列 Trie,是將所有節點的狀態都記錄到一個陣列之中(Base Array),以此減少陣列的大量空置。
建議實際應用中應首先對字典排個序,減少插入帶來樹的重構,再構建所有詞的首字,然後逐一構建各個節點的子節點,這樣一旦產生衝突,可以將衝突的處理侷限在單個父節點和子節點之間,而不至於導致大範圍的節點重構。
下文中,清【新】的變化導致 清【華】的變化,只是兄弟節點的小範圍調整
字元編碼
為了方便理解,將字典中5個詞的字進行編碼,實際使用中,可直接使用 (int)char 強轉為ASCII碼,或者 Unicode 碼等
| char | 清 | 華 | 大 | 學 | 新 | 中 | 人 |
|---|---|---|---|---|---|---|---|
| code | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
計算規則
在Double Array Trie中,base 和 check 通常表示Trie樹的兩種狀態。
- base陣列:陣列的每個元素表示一個Trie節點,即一個狀態(分為空閒狀態和佔用狀態),負責記錄狀態,用於狀態轉移。
- check陣列:陣列的每個元素表示某個狀態的前驅狀態,負責檢查各個字串是否是從同一個狀態轉移而來。
當狀態 s 接受字元 c轉移到狀態 t時,雙陣列滿足:
# s 表示當前狀態的下標
# c 代表輸入字元的值 => code("清")
# t 表示轉移狀態的下標
base[s] + c = t # 表示一次狀態轉移
check[t] = s # 等於 前驅狀態(位置索引),檢驗狀態轉移是否成功,
# HanLP 書上寫的是 check[p] = base[b],不知道是不是勘誤,感覺 當前轉移基數 = 前驅轉移基數 不太保險
Base Array 計算
- 當前狀態 = base[s]
- 轉移下標 = 當前狀態 + 字元值 = base[s] + code("字元")
也就是下一個 「字元」 要寫入的位置
- 轉移基數 = 前驅節點轉移基數。
有衝突時,處理步驟如下:
- 重新計算前驅轉移基數 = 所放位置值 - 字元Code值。
- 再遍歷前驅下面的子節點,看看新的轉移基數,對其它子節點有沒有引起衝突,如果有,回到第1步再進行計算
- 前驅節點下所有的子節點,都找到可放的位置後,更新所有節點的轉移基數
Check Array 計算
- 檢驗值 = 前驅節點的 位置
清華,清的位置 2,check[5] = 2,check[5] == 2, 說明 "清華" 這個詞在構建的樹字典中
人大,人的位置 3,check[6] = 5, check[6] != 3, 說明 "人大" 這個詞不在構建的樹字典中
處理葉子節點
如果是葉子節點。將值轉為負數,這樣相比在後面加上 \0 要省節點空間
構建 Base Array、Check Array
對下列5組詞進行構建: [「清華」、「清華大學」、「清新」、「中華」、「華人」]

分四輪構建,先處理第一層【清、中、華】,再處理第二層【華、新、華、人】,然後處理【大】,【學】
初始化root的 base 轉移基數為 1, check 的值為 -1。
base陣列初始化大小,一般為 65535 + N ,放大些,足夠容納下字元就可以了。
本文圖中紫色有9個字元,由於 root(base[0]) 的轉移基數初始賦值 = 1,第一個字的字元編碼 = 1,1+1 = 2,所以第1個字元放的位置是從 base[2] 開始,base[1] 會空在那,因此 Base Array 大小初始化為 base[0] + base[1] + 9個字元 11,如下圖:

處理字典首字
先處理字典的首字【清、中、華】,逐字處理
先不考慮葉子節點的情況下,這樣方便理解(後面會說處理邏輯),實際編碼時 base、check、葉子節點,會一併處理
【清】
當前狀態 = root 根狀態 = base[0] = 1
轉移下標 = 當前狀態 + 字元值 = base[0] + code("清") = 1 + 1 = 2 位置 2 空閒,(放入位置 2)
前驅轉移基數 = base[0] = 1 (位置 2 空閒,不需重新計算)
轉移後的前驅,也就是【清】的前驅,其實也就是上面提到的當前狀態
轉移基數 = 前驅轉移基數 = base[0] = 1
Check = 前驅的位置 = 0

【中】
當前狀態 = root 根狀態 = base[0] = 1
轉移下標 = base[0] + code("中") = 1 + 6 = 7 位置 2 空閒,(放入位置 7)
前驅轉移基數 = base[0] = 1 (位置 7 空閒,不需重新計算)
轉移基數 = 前驅轉移基數 = 1
Check = 前驅的位置 = 0
【華】
當前狀態 = root 根狀態 = base[0] = 1
轉移下標 = base[0] + code("華") = 1 + 2 = 3 位置 2 空閒,(放入位置 3)
前驅轉移基數 = base[0] = 1 (位置 3 空閒,前驅不需重新計算)
轉移基數 = 前驅轉移基數 = 1
Check = 前驅的位置 = 0
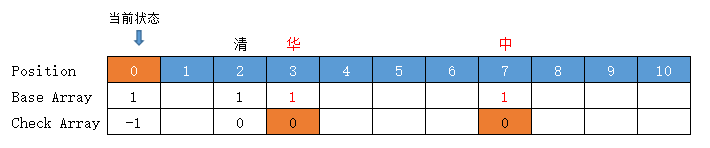
處理字典二層字
處理字典 ["清華", "清華大學", "清新", "中華", "華人"] 的第二層字【華、新、華、人】
【清華】
計算過程,要看上一張圖,下面對應的圖是計算後的結果圖
當前狀態 = "清"字狀態 =base[0] + code("清") = 2
當前在「清」字上,要計算下一個「華」
轉移下標 = base[2] + code("華") = 1 + 2 = 3 ,位置3有值,向後挪至空位4 (放入位置 4)
前驅轉移基數 = base[2] = 所放位置值 - 字元Code值 = 4 - code("華") = 4 - 2 = 2
有衝突,前驅轉移基數需要重新計算,並更新前驅轉移基數的值
轉移基數 = 前驅轉移基數 = 2
Check = 前驅的位置 = 2

【清華大學】
和前面的【清華】一致,節點位置、轉移基數無變化
【清新】
當前狀態 = 「清」字狀態 = base[0] + code("清") = 2
轉移下標 = base[2] + code("新") = 2 + 5 = 7,位置7有值,向後挪至空位8 (放入位置 8 )
前驅轉移基數 = base[2] = 所放位置值 - 字元Code值 = 8 - code("新") = 8 - 5 = 3
此時 "清" 變為3了,再看下它的子節點,清【華】,base[2] + code("華") = 3 + 2 =5
此時需要將 base[4] 上原來的華,向後挪至 base[5],否則 【清華】就斷連了
如果 base[5] 上有值,還需要繼續往後挪,然後重新計算前驅 base[2] 轉移基數
轉移基數 = 前驅轉移基數 = 3
【清華】 = base[5] = 3
【清新】 = base[8] = 3
Check = 前驅的位置 = 2
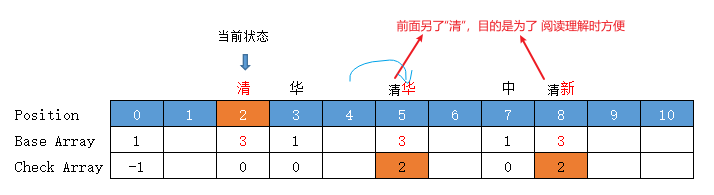
【中華】
當前狀態 = 「中」字狀態 = base[0] + code("中") =1 + 6 = 7
轉移下標 = base[7] + code("華") = 1 + 2 = 3,位置3有值,向後挪至空位4 (放入位置 4 )
前驅轉移基數 = base[7] = 所放位置值 - 字元Code值 = 4 - code("華") = 4 - 2 = 2
轉移基數 = 前驅轉移基數 = base[7] = 2
Check = 前驅的位置 = 7

【華人】
當前狀態 = "華"字狀態 = "華"字位置下標 = base[0] + code("華") = 1 + 2 = 3
轉移下標 = base[3] + code("人") = 1 + 7 = 8,位置 8 有值,向後挪至空位 9 (放入位置 9 )
前驅轉移基數 = base[3] = 所放位置值 - 字元Code值 = 9 - 7 = 2
轉移基數 = 前驅轉移基數 = base[3] = 2
Check = 前驅的位置 = 7
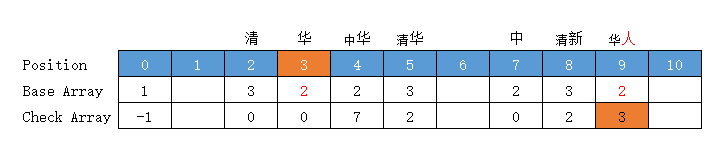
處理字典三層字
處理字典 ["清華", "清華大學", "清新", "中華", "華人"] 的第三層字【大】
【清華大學】
當前狀態 = "華"字狀態 = "華"字位置下標 = base[base[0] + code("清")] + code("華") = 3 + 2 = 5
當前狀態下標要從頭開始算,不能直接看 「華」 否則會被上面的 華人的華干擾,這也是圖片上在文字前面加上小字字首 的原因
轉移下標 = base[5] + code("大") = 3 + 3 = 6,位置 6 空閒 (放入位置 6 )
前驅轉移基數 = base[5] = 3 (位置 6 空閒,不需要重算)
轉移基數 = 前驅轉移基數 = base[5] = 3
Check = 前驅的位置 = 5

處理字典四層字
處理字典 ["清華", "清華大學", "清新", "中華", "華人"] 的第三層字【學】
【清華大學】
當前狀態 = "大"字狀態 = "大"字位置下標 = 6
轉移下標 = base[6] + code("學") = 3 + 4 = 7,位置 7 有值,向後挪至空位 10 (放入位置 10 )
前驅轉移基數 = base[6] = 所放位置值 - 字元Code值 = 10 - 6 = 6
轉移基數 = 前驅轉移基數 = base[6] = 6
Check = 前驅的位置 = 6
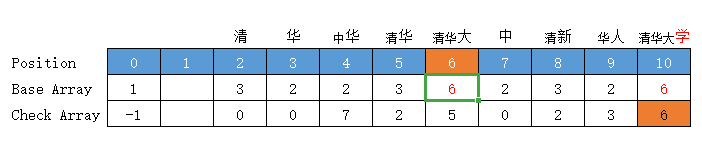
葉子節點處理
將每個詞的詞尾設定為轉移基數的負數(只有詞尾為負值),這樣能夠節省構建時間,不過進行轉移時要將狀態轉移函數改為|base[b]|+code(字元)
//葉子節點轉移基數標識為父節點轉移基數的相反數,比起 \0 少加了節點,計算時加上絕對值
base[s]= (base[s] * -1);
處理後的效果圖如下

核心程式碼
public void build(List<String> list) {
init();
String[] dir = list.toArray(new String[0]);
// 詞的深度 -- 先處理首字
int depth = 1;
//迴圈處理字典列表,每層處理一次,直到所有的字典都處理完
while (!list.isEmpty()) {
// 根據相同字首分組,存放每一次的字,key = 深度
Map<Integer, List<Node>> map = new HashMap<>();
for (int i = 0; i < list.size();) {
String word = list.get(i);
String pre = word.substring(0, depth - 1); //取前驅字
String k = word.substring(depth - 1, depth); //取當前要處理的字
Node n = new Node();
n.code = getCode(k);
n.s = depth == 1 ? 0 : indexOf(pre);
n.label = k;
if (depth == word.length()) {
list.remove(i); // 如果深度 = 字典長度,表示沒有下一層,這時候從列表中移除
} else {
i++;
}
List<Node> siblings = map.getOrDefault(n.s, new ArrayList<>());
if(siblings.contains(n)){
continue;
}
siblings.add(n);
map.put(n.s, siblings);
}
//字典 第N層的字 組裝好後,開始處理
map.forEach((s, siblings) -> {
int offset = 0;
for (int i = 0; i < siblings.size(); i++) {
Node node = siblings.get(i);
int c = node.code;
int t = base[s] + offset + c;
System.out.printf(" "+ node.label);
// 發現在節點已有值則偏移+1
if (check[t] != -1) {
offset++; //往後挪一位,重新計算時看看下一位有沒有值,如果有值繼續算
i = -1; //字元沒地方放,倒回去,整個這一層的節點都需要,重新計算,新變了,導致清轉移基數變了,這時候要重新計算清華的華,看華往後挪一個是不是可以,如果不可以繼續調整
System.out.printf(" " + t + " 有值換 ");
}
else {
System.out.println(" "+ t);
}
}
base[s] = base[s] + offset; // offset 往後挪了1位,滿足了 清【新】、清【華】,重新構建建樹
//轉移基數計算完成後,構建 base、check陣列
for (Node node : siblings) {
int c = node.code;
int t = base[s] + c;
// 給上父結點
check[t] = s;
// 當前狀態的轉移基數 = 上一個節點的轉移基數
base[t] = base[s];
}
});
depth++;
}
// 發現位元組點,置為負數
for (String aDir : dir) {
int s = indexOf(aDir);
base[s] = -1 * base[s];
}
}
完整程式碼
參考:
小白詳解 Trie 樹 -- 圖中數值有些錯誤
雙陣列字典樹(DATrie)詳解及實現 -- 它是按每個詞去處理的,程式碼有些問題,有衝突沒有重構樹
本文來自部落格園,作者:VipSoft 轉載請註明原文連結:https://www.cnblogs.com/vipsoft/p/17774393.html