國科大卜東波演演算法設計作業
Question Number 1
You are interested in analyzing some hard-to-obtain data from two separate databases. Each database contains n numerical values, so there are 2n values total and you may assume that no two values are the same. You’d like to determine the median of this set of 2n values, which we will define here to be the nth smallest value. However, the only way you can access these values is through queries to the databases. In a single query, you can specify a value k to one of the two databases, and the chosen database will return the kth smallest value that it contains. Since queries are expensive, you would like to compute the median using as few queries as possible.
Give an algorithm that finds the median value using at most O(log n) queries.
思路
這個演演算法的思路是使用二分查詢的思想來在兩個資料庫 D 和 D2 中查詢合併後的第 n 小的值,也就是中位數。
-
首先,初始化兩個索引 p1 和 p2 分別指向兩個資料庫的中間位置,即 n / 2 處。
-
然後,通過一個迴圈,進行了從 2 到 log2(n) 的迭代。這個迴圈的目的是不斷地縮小待查詢範圍,直到找到中位數或者回圈結束。
-
在每次迭代中,首先查詢兩個資料庫中索引位置 p1 和p2 處的值,分別為m1 和 m2。
-
接下來,檢查 m1 和 m2 是否相等。如果它們相等,那麼這個值就是中位數,直接返回。
-
如果 m1大於 m2,說明中位數一定在 m1 的左側或 m2 的右側,因此需要將索引 p1 向左移動,同時將索引 p2 向右移動,以縮小待查詢範圍。
移動大小:
\[p1 = p1 - n / (2^i)\\ p2 = p2 + n / (2^i) \] -
如果 m1 小於 m2,說明中位數一定在 m1 的右側或 m2 的左側,因此需要將索引 p1 向右移動,同時將索引 p2 向左移動,以縮小待查詢範圍。
移動大小:
\[p1 = p1 + n / (2^i)\\ p2 = p2 - n / (2^i) \] -
重複上述步驟直到找到中位數或者回圈結束。
-
最後,返回 m1 和 m2 中的較小值,作為合併後的第 n 小的值,也就是中位數。
這個演演算法的核心思想是不斷地二分查詢,並根據當前的中位數候選值來決定下一步查詢的方向,以有效地找到中位數
時間複雜度分析
- 初始化 p1 和 p2 需要 O(1) 時間。
- 迴圈迭代從 2 到 log2(n) 次,其中 n 表示資料庫中的元素總數。每次迭代都會執行以下操作:
- 執行兩次查詢操作,即 Query(D1, p1) 和 Query(D2, p2),這需要 O(1) 時間。
- 進行條件判斷和更新操作,這也需要 O(1) 時間。
- 最終返回 min(m1, m2),需要 O(1) 時間。
由於每次將問題的規模減少1/2,因此有:
因此複雜度為:
虛擬碼
Algorithm FindMedian(D1, D2, n):
Input: 資料庫D1{x1,x2,...xn},資料庫D2{x1,x2,...xn}
Output: 兩個資料庫中第n小的數值
p1 = n / 2
p2 = n / 2
For i from 2 to log2(n) do
m1 = Query(D1, p1) //查詢D1中第p1小的數
m2 = Query(D2, p2) //查詢D2中第p2小的數
If m1 == m2 then
Return m1
EndIf
If m1 > m2 then
p1 = p1 - n / (2^i)
p2 = p2 + n / (2^i)
Else
p1 = p1 + n / (2^i)
p2 = p2 - n / (2^i)
EndIf
EndFor
Return min(m1, m2)
END Algorithm
證明正確性
基本情況:n = 1時:p1 和 p2 都被初始化為整數 0和,而在迴圈之前,m1 和 m2 分別查詢 D1 和 D2 中第 0 小的數。由於沒有明確規定,可以假設查詢到的值都是唯一的,因此 m1 和 m2 將分別等於 D1 和 D2 中的唯一值。由於 m1 和 m2 相等,演演算法將直接返回其中一個值,這是正確的。
歸納假設: n > 1 的情況。在這種情況下,演演算法使用二分法逐步縮小查詢範圍,直到找到中位數。
- 在迴圈的每一次迭代中,演演算法首先查詢 D1 和 D2 中的第 p1 和 p2 小的數,分別為 m1 和 m2。
- 如果 m1 等於 m2,則演演算法直接返回其中一個值,因為這個值就是中位數。
- 如果 m1 大於 m2,則說明中位數在左側。演演算法會將查詢範圍調整為左半部分,即 p1 和 p2 向左移動。
- 如果 m1 小於 m2,則說明中位數在右側。演演算法會將查詢範圍調整為右半部分,即 p1 和 p2 向右移動。
演演算法在每次迭代中都縮小了查詢範圍,直到找到中位數或者 n 等於 2 時,返回兩個候選中位數中的較小值。
綜上所述,演演算法 FindMedian(D1, D2, n) 能夠正確找到中位數,並且對於任何 n 的值都有效,即使 p1 和 p2 都為整數。
Question Number 2
Given any 10 points, p1, p2, ..., p10, on a two-dimensional Euclidean plane, please write an algorithm to find the distance between the closest pair of points.
(a) Using a brute-force algorithm to solve this problem, analyze the time complexity of your implemented brute-force algorithm and explain why the algorithm’s time complexity is O(n^2 ), where n is the number of points.
(b) Propose an improved algorithm to solve this problem with a time complexity better than the brute-force algorithm. Describe the algorithm’s idea and analyze its time complexity.
(a) Brute-Force
思路
暴力搜尋的思路是對每一對點計算距離,並找到最小距離的一對點。該演演算法的時間複雜度分析如下:
- 對於10個點,有10個點中的第一個點與其他9個點的距離需要計算。
- 然後,有9個點中的第二個點與其他8個點的距離需要計算。
- 以此類推,依次計算所有可能的點對的距離。
時間複雜度
總共需要計算的距離對數是 9 + 8 + 7 + ... + 1 = (10 * 9) / 2 = 45 對。即對於n個點,需要計算的距離對數為:
所以,該演演算法的時間複雜度為:
其中n是點的數量。這是因為演演算法必須對每一對點都進行距離計算,導致時間複雜度與點的數量的平方成正比。
虛擬碼
Algorithm BruteForceClosestPair(points)
Input: 一個點集 points,包含 n 個點
Output: 最近的點對 closestPair 和它們之間的距離 minDistance
minDistance = 無窮大
closestPair = 無
For i = 1 to n-1 do
For j = i+1 to n do
distance = 計算歐幾里得距離(points[i], points[j])
If distance < minDistance then
minDistance = distance
closestPair = (points[i], points[j])
EndIf
EndFor
EndFor
Return closestPair, minDistance
End Algorithm
證明正確性
要證明 BruteForceClosestPair(points) 演演算法的正確性,可以使用數學歸納法。
基本情況:,當點集中只有兩個點時,演演算法將直接計算它們之間的距離,並返回這對點及其距離作為最近點對。這是顯然正確的,因為只有兩個點可以構成最近點對。
歸納假設:接下來,假設對於任意點集大小為 k 的情況,BruteForceClosestPair(points) 演演算法都能正確找到最近點對和它們之間的距離。
現在考慮點集大小為 k+1 的情況。演演算法首先初始化 minDistance 為無窮大,並將 closestPair 設為無。然後,演演算法使用兩層巢狀迴圈遍歷所有可能的點對,並計算它們之間的距離。如果找到一個距離小於 minDistance 的點對,演演算法將更新 minDistance 和 closestPair。
在完成迴圈後,演演算法返回 closestPair 和 minDistance。這確保了演演算法總是會找到最近的點對和它們之間的距離。
由於在基本情況下和歸納步驟中都假設演演算法是正確的,所以可以得出結論,BruteForceClosestPair(points) 演演算法對於任意點集都能正確找到最近點對和它們之間的距離。因此,該演演算法是正確的。
(b) Improved algorithm
思路
當點集的規模較小(n <= 3)時,使用暴力搜尋是因為對於小規模的點集,暴力搜尋的時間複雜度相對較低,且實現簡單。對於包含很少點的情況,直接計算每一對點的距離並找到最小距離點對是一種高效的方法,因為計算的點對數量較少,效能相對較好。
當規模較大時,可以使用分治法來改進演演算法,該演演算法的時間複雜度更優。演演算法的思路如下:
- 將點按照橫座標從小到大排序。
- 將點集分成左右兩部分,並分別在這兩個子集上遞迴呼叫自身來找到左右兩邊的最近點對。
- 在遞迴的每一層,比較左分割區的最近點對和右分割區的最近點對,選擇其中的最小距離,得到一個候選的最近點對和最小距離。
然後考慮跨越左右兩個分割區的點對,計算它們之間的距離。如果跨越點對的距離小於已知的最小距離,則更新最小距離和最近點對。 - 最後,返回三個距離中最小的值對應的點對,以及它們之間的最小距離。這樣,就能夠找到整個點集中的最近點對。
演演算法的關鍵思想是通過遞迴將問題分解成較小的子問題,然後通過合併子問題的結果來解決原始問題。
時間複雜度
- 預處理排序步驟:首先,對點集按照橫座標排序的時間複雜度為 O(n log n),這是常見的排序演演算法(如快速排序或歸併排序)的時間複雜度。
- 遞迴部分:遞迴呼叫 ClosestPair 函數時,每次都將點集分成兩個子集,並進行遞迴呼叫。每個遞迴層級需要對一半的點集進行處理,所以總共有 O(log n) 層遞迴。在每一層遞迴中,需要進行一些常數時間的計算(如計算最近點對),因此遞迴部分的時間複雜度為 O(log n)。
- 橫跨兩個分割區的計算:在演演算法中,當滿足條件橫座標距離(leftClosestPair, rightClosestPair) < minDistance 時,才會計算跨越兩個分割區的最近點對。這個計算的時間複雜度可以看作是線性的,因為在窄頻區域內只需要考慮一些點對。這個部分的時間複雜度是 O(n)。
綜上所述,該演演算法的時間複雜度由預處理排序步驟(O(n log n))和遞迴部分(O(log n))組成,其中遞迴部分的主要計算開銷在於跨越兩個分割區的計算(O(n))。因此,總體時間複雜度為:
因此,改進演演算法的時間複雜度比暴力搜尋的演演算法要好,因為它以對數方式增長,而不是二次方式增長。
虛擬碼
Algorithm ClosestPair(points)
Input: 一個點集 points,包含 n 個點按橫座標排序
Output: 最近的點對 closestPair 和它們之間的距離 minDistance
// 也是遞迴出口
If n <= 3 then
Return BruteForceClosestPair(points)
Else
// 按照橫座標排序
SortPointsByX(points)
// 將 points 分成左右兩部分 leftPoints 和 rightPoints
leftClosestPair, leftMinDistance = ClosestPair(leftPoints) // 遞迴呼叫左分割區
rightClosestPair, rightMinDistance = ClosestPair(rightPoints) // 遞迴呼叫右分割區
minDistance = min(leftMinDistance, rightMinDistance)
IF 橫座標距離(leftClosestPair, rightClosestPair) < minDistance then
計算左右兩部分之間的最近點對 stripClosestPair 和 stripMinDistance
EndIf
IF stripMinDistance < minDistance then
Return stripClosestPair, stripMinDistance
Else
Return 最小的 minDistance 對應的 closestPair
EndIf
EndIf
End Algorithm
證明正確性
要證明該演演算法的正確性,可以使用分治法和歸納法。
基本情況:即 n <= 3 時的情況。在這種情況下,演演算法直接呼叫 BruteForceClosestPair(points) 來計算最近的點對。
歸納假設:假設 BruteForceClosestPair(points) 是正確的,因為它會考慮所有可能的點對並返回最近的點對及其距離。因此,在基本情況下,演演算法是正確的。
接下來,考慮遞迴情況,即 n > 3 的情況。在這種情況下,演演算法將點集分成左右兩部分 leftPoints 和 rightPoints,然後遞迴地呼叫 ClosestPair(leftPoints) 和 ClosestPair(rightPoints) 來計算左右兩個分割區的最近點對和最小距離。
假設在遞迴呼叫中,ClosestPair(leftPoints) 和 ClosestPair(rightPoints) 都返回了正確的結果。現在需要證明合併這些結果時,演演算法仍然能夠得到正確的結果。
演演算法比較了左右兩個分割區的最小距離 minDistance,然後計算了 stripClosestPair 和 stripMinDistance,它們是分佈在左右兩個分割區之間的點對的最近距離。演演算法會選擇其中較小的一個,並將其作為 minDistance。
然後,演演算法比較了 stripMinDistance 與 minDistance,如果 stripMinDistance 更小,那麼演演算法返回 stripClosestPair 和 stripMinDistance,否則返回 minDistance 對應的最近點對。這確保了演演算法在任何情況下都返回正確的結果。
綜上所述,演演算法在基本情況下和遞迴情況下都假設是正確的,然後通過合併左右兩個分割區的結果,選擇最小距離的點對,確保了演演算法在任何情況下都返回正確的結果。因此,演演算法是正確的。
Question Number 3
Given an integer n, where 100 < n < 10000, please design an efficient algorithm to calculate 3^n , with a time complexity not exceeding O(n).
(a) Implement a naive calculation method to compute 3^n and analyze the time complexity of the naive calculation method.
(b) Propose an improved algorithm to calculate 3^n with a time complexity not exceeding O(n). Describe the algorithm’s concept and analyze its time complexity
(a)Native method
思路
- 初始化一個變數 result 為 1,用於儲存計算的結果。
- 使用一個迴圈,迴圈 n 次,每次將 result 與 3 相乘,並將結果賦值給 result。
- 迴圈結束後,result 中儲存的就是 3^n 的計算結果。
時間複雜度
使用一個迴圈進行 n 次乘法操作來計算 3^n。每次乘法操作需要常數時間,因此迴圈中的操作的時間複雜度為 O(1)。
迴圈執行了 n 次,所以總的時間複雜度為 :
程式碼
由於該程式碼較容易實現,因此直接寫出了具體java程式碼:
public static int calculatePower(int n) {
int result = 1;
for (int i = 0; i < n; i++) {
result *= 3;
}
return result;
}
證明正確性
基本情況:,當 n 等於 0 時,方法返回 1。這是顯然正確的,因為任何數的 0 次方都等於 1。
歸納假設:假設對於任意非負整數 k,calculatePower(k) 方法都能正確計算 3 的 k 次方。即,calculatePower(k) 返回的結果等於 3 的 k 次方。
現在考慮 n = k + 1 的情況。根據方法的實現,calculatePower(n) 的計算過程如下:
int result = 1;
for (int i = 0; i < n; i++) {
result *= 3;
}
在迴圈中,result 初始值為 1,並且在每次迭代中都乘以 3。因此,迴圈結束後的 result 的值等於 3 的 n 次方。
根據歸納假設,calculatePower(k) 返回的結果等於 3 的 k 次方。而在 n = k + 1 的情況下,方法返回的結果等於 3 的 n 次方。因此,方法對於任意非負整數 n 都能正確計算 3 的 n 次方。
綜上所述,calculatePower 方法是正確的,它能夠正確計算 3 的任意非負整數次方。
(b)Improved algorithm
思路
在native method中,不斷重複計算了之前已經計算過的數值,例如求310,當算出35時,就無需計算
改進的演演算法可以使用遞迴和動態規劃的思想,以降低時間複雜度。其主要思路如下:
-
如果 n 是偶數,可以將問題分解為計算
\[3^{\left(\frac{n}{2}\right)} * 3^{\left(\frac{n}{2}\right)} \]這可以通過計算 3^(n/2) 一次,然後平方得到結果。
-
如果 n 是奇數,可以將問題分解為計算
\[3^{\left(\frac{n-1}{2}\right)} * 3^{\left(\frac{n-1}{2}\right)} * 3 \]這可以通過計算 3^((n-1)/2) 一次,然後平方得到結果,再乘以 3。
-
為了降低計算的複雜度,可以使用動態規劃的方法,將已經計算過的 3^k 儲存起來,以便後續使用。
時間複雜度
-
對於每個不同的 n值,只計算一次,並將結果儲存在 dp[] 陣列中。這一步的時間複雜度是 O(n)。
-
在遞迴部分,將問題分解為子問題,並計算這些子問題。
假設 n 的二進位制表示有 k 位(即 n 是 2 的 k 次方),那麼最多會有 k 層遞迴。每一層遞迴的計算都涉及到常數次的乘法和除法操作,因此每一層遞迴的時間複雜度是 O(1)。 -
綜合考慮所有層次的遞迴,總的時間複雜度是 O(k)。由於 n是 2 的 k次方,因此 k與 log(n) 成正比。
因此,這個演演算法的時間複雜度為:
程式碼
由於該程式碼較容易實現,因此直接寫出了具體java程式碼:
public class CalculatePowerOfThree {
private static int[] dp; // 用於儲存已計算的 3^k 值
public static int calculatePower(int n) {
dp = new int[n + 1]; // 初始化 dp 陣列,用於儲存計算結果
return calculatePowerRecursive(n);
}
private static int calculatePowerRecursive(int n) {
if (n == 0) {
return 1; // 3^0 = 1,遞迴出口
}
if (dp[n] != 0) {
return dp[n]; // 如果已經計算過,直接返回結果
}
int result;
if (n % 2 == 0) {
int halfPower = calculatePowerRecursive(n / 2);
result = halfPower * halfPower;
} else {
int halfPower = calculatePowerRecursive((n - 1) / 2);
result = halfPower * halfPower * 3;
}
dp[n] = result; // 將計算結果儲存到 dp 陣列中
return result;
}
}
證明正確性
為了證明該演演算法的正確性,可以使用數學歸納法。
基本情況:即 n=0 時演演算法的正確性。在這種情況下,calculatePowerRecursive(0) 應該返回 1,這是因為 3^0 等於 1。因此,基本情況成立。
歸納假設:假設對於任意 k,當 n=k 時演演算法的結果是正確的,即 calculatePowerRecursive(k) 返回的結果是 3^k。需要證明當 n=k+1 時演演算法仍然正確。
考慮 n=k+1 的情況,根據演演算法的遞迴步驟,如果 n是奇數,演演算法會計算 calculatePowerRecursive((n-1)/2) 並將其平方,再乘以 3。根據的歸納假設,calculatePowerRecursive((n-1)/2) 正確地返回了 3^((k+1-1)/2) = 3^k,所以平方後得到 3^(k+1)。然後再乘以 3,得到 3^(k+1+1) = 3^(k+2),這正是期望的結果。
同樣,如果 n 是偶數,演演算法會計算 calculatePowerRecursive(n/2) 並將其平方,得到 3^k。這也是期望的結果。
綜上所述,使用數學歸納法證明了對於任意 n,演演算法 calculatePowerRecursive(n) 返回的結果是 3^n,因此證明了該演演算法的正確性。
Question Number 4
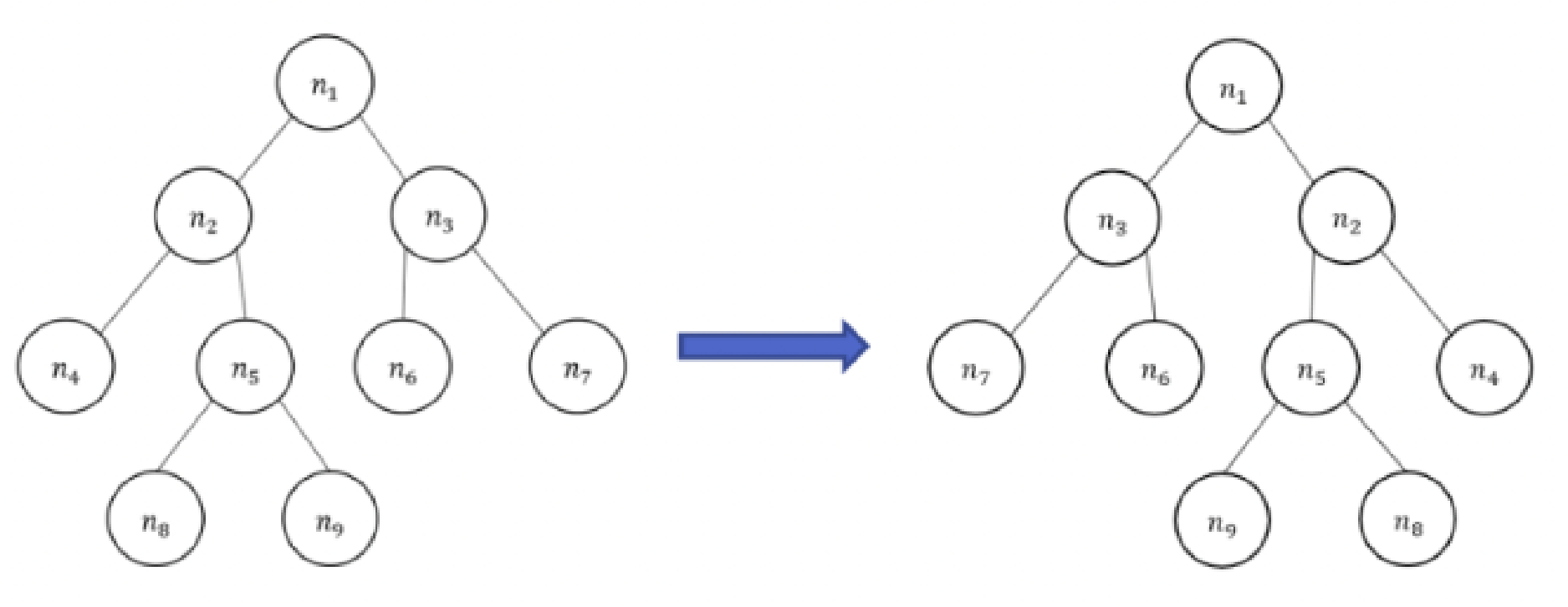
Given a binary tree T, please give an O(n) algorithm to invert binary tree. For example below, inverting the left binary tree, we get the right binary tree.
思路
- 如果輸入的二元樹根節點 root 為空,表示已經到達葉節點或空樹,直接返回 null,作為遞迴的出口。
- 否則,遞迴處理左子樹和右子樹。首先遞迴呼叫 invertTree 函數來翻轉左子樹,並將返回值賦給 root.left,這一步會一直遞迴到左子樹的葉節點,然後開始回溯,逐級翻轉左子樹節點的左右子節點。
- 同樣地,遞迴呼叫 invertTree 函數來翻轉右子樹,並將返回值賦給 root.right,也是逐級遞迴和回溯。
- 最後,交換 root 節點的左右子節點,完成翻轉操作。
- 返回根節點 root,表示整棵樹已經完成翻轉。
這個遞迴過程會從根節點開始,遞迴處理每個子樹的左右子節點,直到葉節點,然後逐級回溯完成翻轉操作。
時間複雜度
- 根據遞迴的出口條件,如果輸入的根節點 root 為空,返回 null,這一步的時間複雜度是 O(1),因為只是一次條件判斷和返回操作。
- 對左子樹的遞迴呼叫 invertTree(root.left) 和對右子樹的遞迴呼叫 invertTree(root.right),每次遞迴都是對子樹進行操作,而且只進行了一次遞迴。因此,每次遞迴的時間複雜度是 O(1)。
- 交換 root 節點的左右子節點的操作,包括將左子節點賦給右子節點,右子節點賦給左子節點,以及將臨時節點的值賦給其中一個子節點。這些操作都是常數時間複雜度的操作,因此時間複雜度是 O(1)。
總結起來,整個演演算法的時間複雜度是 O(n),因為在每個節點上都進行了一次遞迴操作,而遞迴的次數等於二元樹中的節點數 n。因此,時間複雜度是線性的,與二元樹的規模成正比。
程式碼
程式碼的實現較為簡單,因此直接寫出了java的具體實現
public TreeNode invertTree(TreeNode root) {
if (root==null) return null;//遞迴出口
root.left=invertTree(root.left);//一直遞迴左子樹到葉節點,然後回溯,並用節點保持當前節點
root.right=invertTree(root.right);//一直遞迴右子樹到葉節點,然後回溯,並用節點保持當前節點
TreeNode temp=root.left;//交換左右節點
root.left=root.right;
root.right=temp;
return root;//返回當前要交換的節點
}
證明正確性
- 如果一棵二元樹為空樹,那麼它的映象也是空樹,所以基本情況下是正確的。
- 對於任意一個非空的二元樹,可以遞迴地交換它的左右子樹,並且對左子樹和右子樹分別進行相同的操作。這個過程可以保持樹的結構不變,只是交換了每個節點的左右子節點。因此,如果對左子樹和右子樹都正確地進行了翻轉,那麼整個樹也就正確地完成了翻轉。
基於以上,可以使用數學歸納法來證明演演算法的正確性:
基本情況: 當輸入的二元樹為空樹時,演演算法直接返回空樹,這是正確的。
歸納假設:假設對於任意一棵高度為 h 的二元樹,演演算法能夠正確地翻轉。
現在考慮一棵高度為 h+1 的二元樹。這棵樹可以看作是一個根節點和兩棵子樹的組合,其中左子樹和右子樹的高度都是 h。根據歸納假設,知道左子樹和右子樹都可以正確地翻轉。那麼只需要將根節點的左右子節點交換,就可以得到整棵高度為 h+1 的二元樹的翻轉。
通過數學歸納法,證明了對於任意一棵二元樹,該演演算法能夠正確地完成翻轉。
Question Number 5
There are N rooms in a prison, one for each prisoner, and there are M religions, and each prisoner will follow one of them. If the prisoners in the adjacent room are of the same religion, escape may occur. Please give an O(n) algorithm to find out how many states escape can occur. For example, there are 3 rooms and 2 kinds of religions, then 6 different states escape will occur.
思路
因為只有相鄰的信仰不相同才不能越獄,所以如果第一個房間有m種選擇,
第二個房間保證與第一個房間不同即可,有m-1種選擇
第三個房間保證與第二個房間不同即可,有m-1種選擇
以此類推,所以得出公式,不可越獄方案數:
進入房間的總方案數為:
因此,可越獄的方案數為總方案數-不可越獄方案數:
但是傳統的求冪方法計算量過大,因此可以使用快速冪演演算法來計算 M 的 N 次方和 (M-1) 的 N 次方,然後相減即可。
快速冪演演算法
快速冪演演算法的基本思想是將指數n表示為2進位制形式,然後利用二進位制形式中的位數來降低計算的複雜度。下面是該演演算法的基本步驟:
- 將指數n表示為2進位制形式,例如,n = 13可以表示為二進位制數1101。
- 從左到右遍歷二進位制表示的每一位,對於每一位i(從最高位到最低位),執行以下操作:
- 如果當前位是1,就將底數a自乘a。這相當於將底數累乘多次。
- 然後將底數a自乘自己(即a *= a),這相當於將底數平方。
- 繼續遍歷下一位,重複第2步,直到遍歷完所有位。
- 當遍歷完所有位時,底數a的值就等於指數n的冪,即a^n。
時間複雜度
這個演演算法的時間複雜度主要由兩部分組成:
- 計算 M 的 N 次方:這部分的時間複雜度由 fastExponentiation 函數決定。在 fastExponentiation 函數中,使用了迭代的方式計算冪運算,每次迭代將指數 exponent 除以 2,因此迭代次數最多為 log₂(N),其中 N 表示指數。每次迭代中,進行一次乘法操作,因此總的時間複雜度為 O(log₂(N))。
- 計算 (M-1) 的 N 次方:同樣,這部分的時間複雜度也由 fastExponentiation 函數決定。因為在此計算的是 (M-1) 的 N 次方,所以在 fastExponentiation 函數中的指數仍然為 N。因此,這部分的時間複雜度也是 O(log₂(N))。
綜上所述,演演算法的總時間複雜度是 O(log₂(N)),其中 N 表示宗教信仰的種類數量。
程式碼
public class PrisonEscapeStates {
public static int countEscapeStates(int N, int M) {
if (N <= 0 || M <= 0) {
return 0;
}
// 計算總方案數
int totalStates = fastExponentiation(M, N);
// 計算不可越獄的方案數,使用快速冪
int nonEscapeStates = fastExponentiation(M - 1, N - 1);
// 可越獄的方案數等於總方案數減去不可越獄的方案數
int escapeStates = totalStates - M*nonEscapeStates;
return escapeStates;
}
// 快速冪演演算法
private static int fastExponentiation(int base, int exponent) {
int result = 1;
while (exponent > 0) {
if (exponent % 2 == 1) {
result *= base;
}
base *= base;
exponent >>= 1;
}
return result;
}
public static void main(String[] args) {
int N = 3; // 3個房間
int M = 2; // 2種宗教信仰
int escapeStates = countEscapeStates(N, M);
System.out.println("可越獄方案的數量為: " + escapeStates);
}
}
驗證正確性
首先,來分析 fastExponentiation 函數的正確性,通過數學歸納法證明。
假設 fastExponentiation(base, exponent) 正確計算 base 的 exponent 次方。現在考慮 fastExponentiation(base, exponent+1),即計算 base 的 (exponent+1) 次方。根據快速冪演演算法的步驟,可以將 (exponent+1) 表示為二進位制形式,例如 exponent+1 = b_k * 2^k + b_(k-1) * 2^(k-1) + ... + b_1 * 2 + b_0,其中 b_k, b_(k-1), ..., b_0 是二進位制位。
根據步驟 2,當 b_0 為 1 時,將 base 乘以 result。根據步驟 3,將 base 自乘一次。因此,如果可以證明 fastExponentiation(base, exponent) 正確計算 base 的 exponent 次方,那麼 fastExponentiation(base, exponent+1) 也會正確計算 base 的 (exponent+1) 次方。
已經證明了 fastExponentiation 函數的正確性。接下來,來證明 countEscapeStates 函數的正確性。
countEscapeStates 函數中,首先計算總方案數 totalStates,然後計算不可越獄的方案數 nonEscapeStates,最後通過總方案數減去不可越獄的方案數得到可越獄的方案數 escapeStates。這個過程與數學歸納法中的歸納步驟非常相似。
基礎情況:當 N 為 1 時,即只有一個房間,不管有多少種宗教信仰,都沒有相鄰的房間,不可越獄的方案數為 0,而總方案數為 M。因此,計算結果是正確的。
歸納假設:假設對於任意 N,countEscapeStates 函數都能正確計算可越獄的方案數。現在考慮 N+1 的情況。可以將 N+1 個房間分成兩部分,前 N 個房間和第 N+1 個房間。根據歸納假設,前 N 個房間的可越獄方案數是正確的。對於第 N+1 個房間,它可以選擇任意一種宗教信仰,因此有 M 種選擇。不可越獄的方案數等於前 N 個房間的不可越獄方案數乘以 M-1(因為第 N+1 個房間的宗教信仰不能與相鄰房間相同),即 nonEscapeStates = (M-1) * nonEscapeStates_N,其中 nonEscapeStates_N 是前 N 個房間的不可越獄方案數。
因此,總方案數 totalStates 是正確的,不可越獄的方案數 nonEscapeStates 也是正確的,從而可越獄的方案數 escapeStates 也是正確的。
綜上所述,通過數學歸納法證明了 countEscapeStates 函數的正確性。