基於開源模型搭建實時臉部辨識系統(四):人臉質量
續臉部辨識實戰之基於開源模型搭建實時臉部辨識系統(三):人臉關鍵點、對齊模型概覽與模型選型_CodingInCV的部落格-CSDN部落格
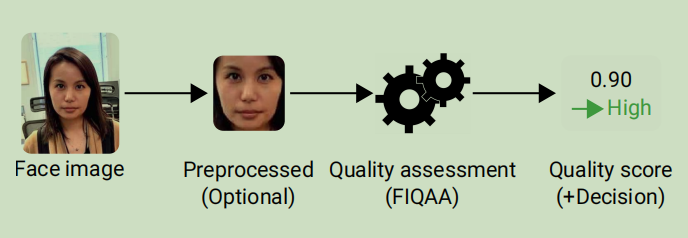
不論對於靜態的臉部辨識還是動態的臉部辨識,我們都會面臨一個問題,就是輸入的人臉影象的質量可能會很差,比如人臉角度很大,人臉很模糊,人臉亮度很亮或很暗。這些質量低的影象不僅造成識別失敗,還可能引起誤識別。因此,對輸入臉部辨識進行一定的質量過濾是很必要的。這個領域的英文為Face Image Quality Assessment。
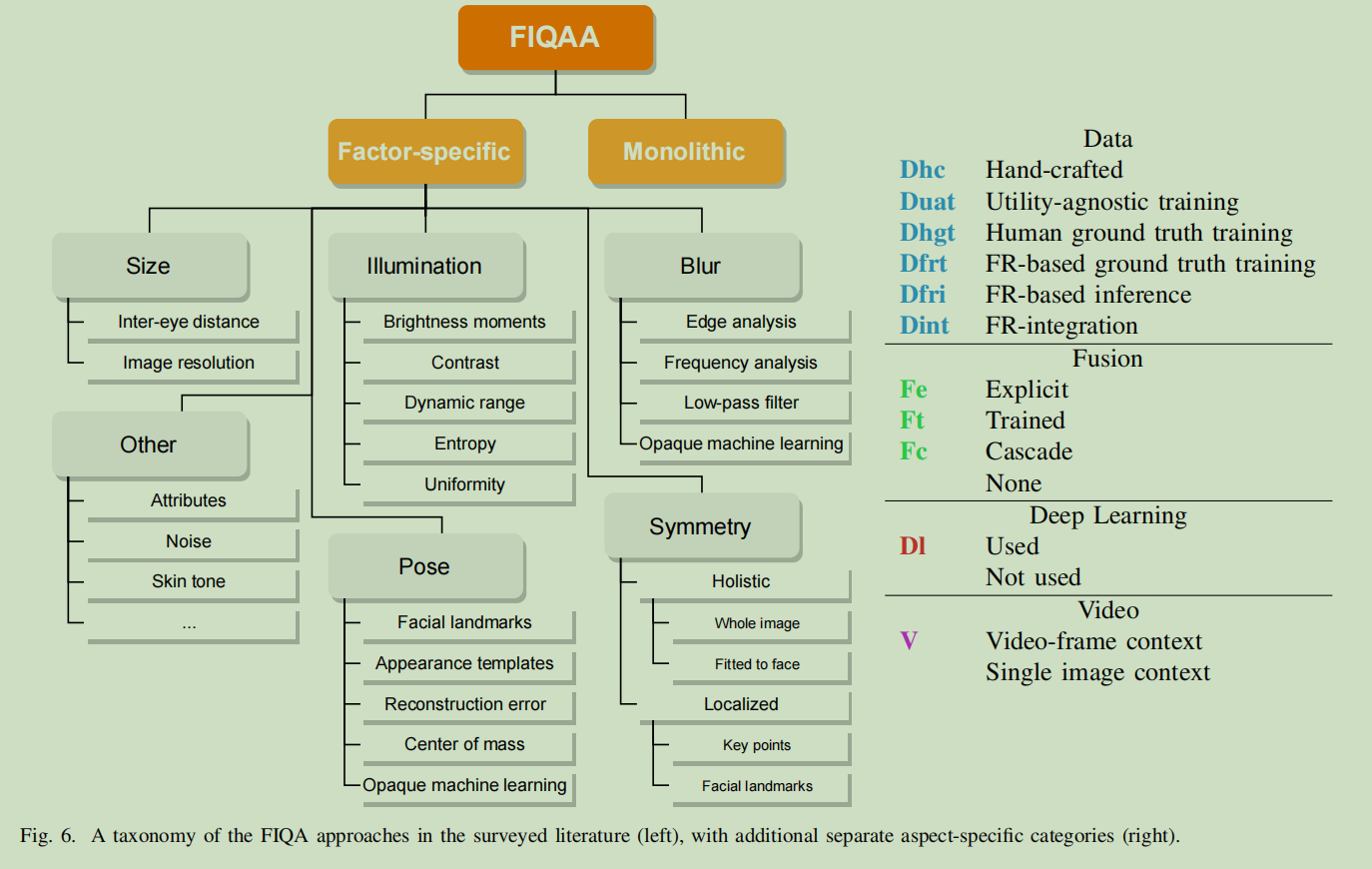
傳統方法
傳統的方法一般是將影象質量領域(Image Quality Assessment)的方法應用到人臉影象上,比如使用邊緣檢測來評測模糊、統計平均畫素值來評測亮度。這些方法沒有特別考慮人臉影象的特點,效果一般。
深度學習方法
普通深度學習方法
這類方法將人臉影象質量作為一個普通的深度學習問題,通過人工或預設演演算法對資料打標,然後設計一個網路,迴歸質量分數。這個方法的學習目標主要還是人眼感知上的質量,因為標籤來源於人工打標,而並不是對於識別效果更好的質量。
這類方法的主要難題在於資料標籤難獲得,網路結構上只是簡單的迴歸網路。
面向臉部辨識的人臉質量評估
人臉質量的篩選目標是提高臉部辨識的效果,因此越來越多的方法開始將人臉質量和臉部辨識任務結合起來,結合的方式主要有2種:
一種是直接訓一個特徵能夠用來衡量人臉質量的模型,代表是MagFace, 基本思想是用特徵的模長來表徵人臉質量。個人覺得這種方式實用起來存在一個問題就是要獲得人臉質量就得進行人臉特徵提取,開銷太大。
另一種方式是通過臉部辨識模型的特徵關係來生成質量標籤,代表方法:
SER-FIQ: 同一個人臉多次推理(開啟dropout),統計多次推理特徵的距離,對於質量好的圖片,特徵平均距離小,反之越大
SDD-FIQ: 統計計算人臉與同一ID和不同ID人臉的距離
FaceQnet, PCNet等
方法選擇
理論上,面向臉部辨識的人臉質量評估效果更好,不過這些方法與識別模型存在較大的耦合關係,根據筆者在私有資料上的實際測試,訓練比較困難,開源出來的預訓練模型也較大。KaenChan/lightqnet: Deployment of the Lightweight Face Image Quality Assessment (github.com) 這個比較輕量,但實測對於人臉區域比較敏感,沒有區分度。
綜合速度要求,選擇 KS‐FQA: Keyframe selection based on face quality assessment for efficient face recognition in video - Bahroun - 2021 - IET Image Processing - Wiley Online Library
這個方法考慮了人臉角度、亮度、大小、模糊。速度較快,也有一定區分度,不過也還是有些缺陷,對於大側臉的過濾效果一般。
import numpy as np
import cv2
class FaceQualityOverall:
def __init__(self, **kwargs) -> None:
pass
def pose_score(self, face_box: np.ndarray, landmarks: np.ndarray):
center_x, center_y = (face_box[0] + face_box[2]) / 2, (face_box[1] + face_box[3]) / 2
nose_x, nose_y = landmarks[2][0], landmarks[2][1]
distance = np.sqrt((center_x - nose_x) ** 2 + (center_y - nose_y) ** 2)
face_size = np.sqrt((face_box[2] - face_box[0]) ** 2 + (face_box[3] - face_box[1]) ** 2)
pose_score = max(0, 1 - distance / face_size)
return pose_score
def sharpness_and_brightness_score(self, image: np.ndarray, face_box: np.ndarray):
box = face_box[:]
box = box.astype(np.int32)
face_image = image[box[1] : box[3], box[0] : box[2], :]
face_image_gray = cv2.cvtColor(face_image, cv2.COLOR_BGR2GRAY)
# blur the face image with a 5x5 guassian kernel
blur_face_image = cv2.GaussianBlur(face_image_gray, (5, 5), sigmaX=1, sigmaY=1)
# calculate the sharpness score
sharpness_score = np.sum(np.abs(face_image_gray - blur_face_image)) / np.prod(face_image_gray.shape)
sharpness_score = sharpness_score / 255.0
sharpness_score = min(1, sharpness_score * 2)
brightness_score = np.mean(face_image_gray)
# normalize the brightness score
if brightness_score < 20 or brightness_score > 230:
brightness_score = 0
else:
brightness_score = 1 - abs(brightness_score - 127.5) / 127.5
return sharpness_score, brightness_score
def resolution_score(self, face_box: np.ndarray):
face_width = face_box[2] - face_box[0]
face_height = face_box[3] - face_box[1]
resolution_score = min(1, min(face_width, face_height) / 224)
if face_height/face_width > 2.5:
resolution_score = 0
if min(face_width, face_height) < 48:
resolution_score = 0
return resolution_score
def run(self, image: np.ndarray, face_box: np.ndarray, landmarks: np.ndarray):
pose_score = self.pose_score(face_box, landmarks)
if pose_score < 0.3:
return 0
sharpness_score, brightness_score = self.sharpness_and_brightness_score(image, face_box)
if sharpness_score<0.1:
return 0
resolution_score = self.resolution_score(face_box)
if resolution_score < 48/224:
return 0
output = np.array([pose_score, sharpness_score, brightness_score, resolution_score])
weight = np.array([0.3, 0.4, 0.1, 0.2])
return np.sum(output * weight)
if __name__ == "__main__":
from face_recognition_modules.face_alignment.face_landmarks import FaceLandmarks
from face_recognition_modules.face_detection.yolov8_face import Yolov8Face
import cv2
yolo8face = Yolov8Face(model_path="models/yolov8-lite-t.onnx", device="gpu")
landmarks_det = FaceLandmarks(model_path="models/student_128.onnx", device="gpu")
image = cv2.imread("test_images/1.jpg")
if image is None:
raise Exception("read image failed")
face_box, _ = yolo8face.run(image)
landmarks = landmarks_det.run(image, face_box[0])
face_quality = FaceQualityOverall()
quality = face_quality.run(image, face_box[0], landmarks)
print(quality)
結語
這篇我們簡要介紹了一下人臉質量評估,不過筆者在這方面涉獵也不深,只是做個簡單的總結,需要深入做還是有不少工作。

專案原始碼
本文來自部落格園,作者:CoderInCV,轉載請註明原文連結:https://www.cnblogs.com/haoliuhust/p/17770881.html