DPDK丟包那些事
本文來自部落格園,作者:T-BARBARIANS,博文嚴禁轉載,轉載必究!
一、前言
DPDK技術原理相關的文章不勝列舉,但從實戰出發,針對DPDK丟包這一類問題進行系統分析的文章還是鳳毛麟角。
剛好最近幾個月一直在做DPDK的相關效能優化,x86和arm平臺都在做。在完整經歷了發現問題、分析問題、解決問題的所有階段後,回顧過去這段時間的來龍去脈,覺得可以將其將形成一篇技術文章,並予以分享。
優化目的只有一個:DPDK零丟包!
零丟包,談何容易!在整個效能優化期間,查閱過大量資料;調整過大量引數;嘗試過多種優化手段。相關的不相關的招都使過,很多時候都是無功而返,優化過程簡直就是一個每天都想放棄的過程。
但是俗話說得好:只要功夫深,鐵棒磨成針。對任何事物的認知必然是一個由淺入深的過程,DPDK也不例外。通過持續的嘗試和總結,x86和國產化平臺最後都收到了很好的效果。
接下來就吐血奉獻過去一段時間的經歷和思考,希望可以為大家提供一些參考和相關問題的解決思路。
篇幅較長,而且資訊量有些大,完整閱讀加理解大概需要30分鐘。
二、背景與問題
與使用DPDK的大多數同行一樣,我們也是通過DPDK獲取資料面的大規模網路流量,在使用者態將流量直接傳遞給某個應用,最終體現業務價值。
願景很美好,現實很殘酷,DPDK丟包了。
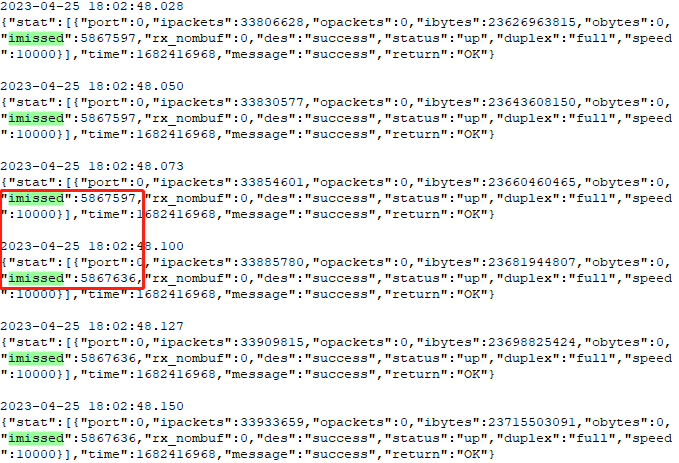
圖1
在時間點 [18:02:48.073,18:02:48.100] 之間發生了丟包,丟包個數為:5867636 - 5867597 = 39。這是在很短時間內的丟包數,情況嚴重時每秒成千上萬個包被丟棄,應用層收到的報文殘缺不全,這就沒法玩了。
··················上 篇··················
一、x86平臺優化經歷
10Gbps線速網路卡,流量也才在2Gbps---3Gbps之間,這也能丟包?
(1)ring環長度儘可能大
各大平臺搜尋一通,公開的祕籍就是:給我把ring環加大!
ring環就是大家耳熟能詳的DPDK無鎖佇列,收包ring環是DPDK收包流程裡最底層的一個佇列,直接與DMA打交道,用於儲存DMA從網路卡搬運至此的網路報文。
在我看來,加大ring環有兩個作用,一是增加儲存網路報文的容量;二是抗流量突發。
我們把ring環長度由1024幹到了16384,同時增加了DPDK佇列統計函數:rte_eth_rx_queue_count(uint16_t port_id, uint16_t queue_id),用於實時統計當前環形佇列已使用的描述符個數,即ring環裡當前駐留了有多少個未消費的封包。
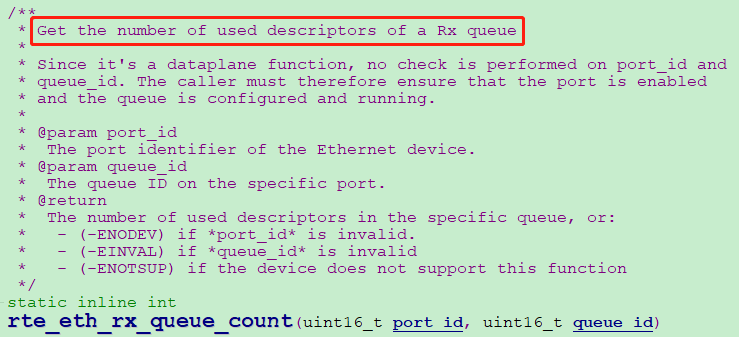
圖2
加大ring環就不丟包了嗎?把佇列統計資訊通過紀錄檔實時列印,繼續觀察。

圖3
很明顯,DPDK繼續丟包。還丟包那我就繼續加,但是DPDK收包ring環的設定是有上限的,uint16_t nb_rx_desc (The number of receive descriptors to allocate for the receive ring),表明DPDK最大可以將收包ring環設定為65535。

圖4
還真設定過最大值,但是無濟於事,繼續丟包。說明在我們環境上增大ring環容量並不能解決全部問題。這時候陷入了僵局,是什麼問題導致了丟包呢?
從圖3我們可以看到一個現象,當ring環被打滿時,才出現了imissed統計值增長。DMA往ring環裡放資料,收包執行緒從ring環裡取資料,現在ring環保持高水位,這充分說明了是上層收包執行緒未及時的將ring環裡的封包取走呀!根據這個重要線索,我們重新審視了與收包相關的應用層程式碼。
(2)執行緒任務儘可能輕量
業務流程邏輯可簡化如下圖所示。
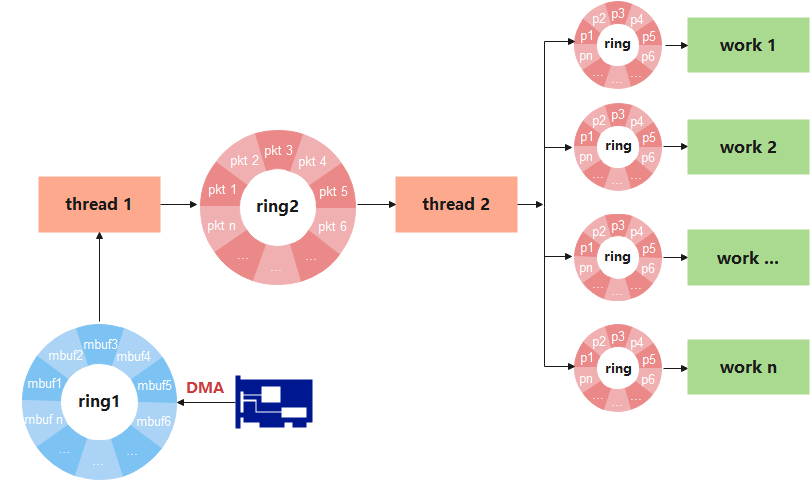
圖5
1、網路封包通過DMA拷貝到ring1;
2、thread1負責從ring1裡接收封包,同時還要做一些其它任務,例如限速、過濾、封包初始化等工作,最後將初始化後的描述符傳遞至ring2;
3、thread2從ring2裡獲取描述符,進行資料預取,協定解析(eth、ip、tcp、udp等等)等相關工作,最後通過hash演演算法將描述符雜湊到對應work執行緒的接收佇列;
4、各work執行緒從對應的ring環裡獲取描述符,進行業務處理。
流程結構很清晰,各個執行緒被安排得明明白白。但是問題恰恰出現在看似沒有問題的地方。
回到上一個問題,ring1被打滿,只能是thread1未及時消費掉ring1的資料,造成ring1可用buf越來越少,DMA無法將網路卡收到的所有網路報文拷貝至ring1裡,最終導致了DPDK丟包。
如何證明?遮蔽大法呀!
當我遮蔽掉thread1裡的限速和過濾,丟包現象明顯減少;當我遮蔽掉封包初始化流程,再也沒有出現過丟包。很明顯,問題就出在初始化流程裡,它的負荷相對於限速和過濾來說,對thread1造成了更大的影響。後來通過uftrace(有關uftrace的用法可以參考我的另一篇文章,連結:https://www.cnblogs.com/t-bar/p/16898892.html)也發現了「初始化流程」函數的消耗時間比「限速」和「流量過濾」要長,佔比更高,也提供了充分的理論支撐,且發現了相對更耗時的罪魁禍首clock_gettime()。
比較了3個時間函數,time(),clock_gettime(),rdtsc()。time和clock_gettime都可以直接獲取時間,且time效能更好,但是精度是秒級別,不適用於高精度時間計時;clock_gettime可獲取納秒級精度時間,且效能還不錯(相對gettimeofday()而言);rdtsc其實效能最好,但是獲取的是系統啟動以來的CPU時鐘週期數,還需要一定的轉換方法才能轉換為時間,對於更高的流量場景,例如20+Gbps,30+Gbps,建議使用rdtsc()。
之所以之前選擇clock_gettime一是精度高,二是效能相對較好。但是這裡的問題就在於:流量規模上來後,當「收包」,「限速」,」過濾」,「初始化」四個流程組合在一起時,任務過重,clock_gettime又是最耗時的任務,形成了木桶的最短板。
明確了問題所在,如何優化呢?
那就是任務拆分!thread1顯然無法在完成限速、過濾、初始化任務的同時,又把ring1消費在低水位。因此有必要把thread1的當前任務進行拆分,即再加一個搬磚執行緒。
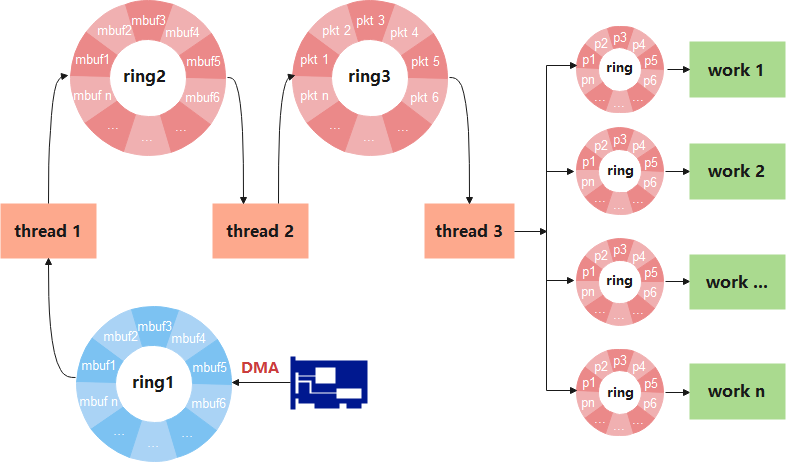
圖6
3個執行緒的分工分別為:
1、thread1只負責從ring1收包,並將封包傳遞至ring2;
2、thread2從ring2獲取封包,完成限速、過濾、初始化工作,並將報文傳遞至ring3;
3、thread3從ring3獲取資料包文,完成協定解析(eth、ip、tcp、udp等等)等相關工作,最後通過hash演演算法將各個Pacekt雜湊至對應ring佇列。
完成上述改造後,ring1再也未出現過因為thread1的不及時消費導致佇列被打滿的情況。也印證了標題,各執行緒任務儘量輕量,各司其職。
(3)mbuf的釋放有講究
摸著石頭過河往往都會遇到你永遠想不到的困難,克服這些困難需要尋找問題線索、解決問題的方法和耐力。
上面程式優化後,興奮感並沒有持續太久,DPDK居然又丟包了,這次直接懵逼了。。。
當我在圖6的thread3直接釋放packet,即切斷各work的輸入,遮蔽業務流程後,不再發生丟包,證明之前的優化至少解決了thead1來不及及時消費ring1封包的問題。
新問題又出在哪裡呢?感覺毫無頭緒,當前唯一的線索就是開啟業務後丟包,遮蔽業務後又不丟包,那大概率問題出在work上,還是看紀錄檔吧!
新丟包現象有如下圖所示資訊:

圖7
這次的丟包和前面的丟包有些不一樣:imissed發生增長的同時,伴隨著rx_nombuf的增長!
rx_nombuf是什麼指標?看看DPDK的定義:用於接收報文的mbuf分配失敗。

圖8
此時腦海裡產生了兩個想法:一是記憶體池設定過小,導致thread1收取報文時mbuf不夠;二是work執行緒數較少,業務來不及處理,mbuf產生堆積,最終導致mbuf沒有及時歸還到記憶體池。
後來的驗證真的很失望,記憶體池從100萬擴大至200萬,甚至擴大至600萬,還是丟包;work執行緒數從8個擴大至16個,還是丟包;雙管齊下,兩個引數都加大,還是丟包!新問題總是接踵而至,感覺好艱難。

執行一段時間後,mbuf不夠是事實,可為什麼加大了資源還是丟包呢?毫無頭緒的時候,又只有把程式碼重新搬出來再看看。
各個work執行緒,以及mbuf的釋放有如下邏輯圖所示:
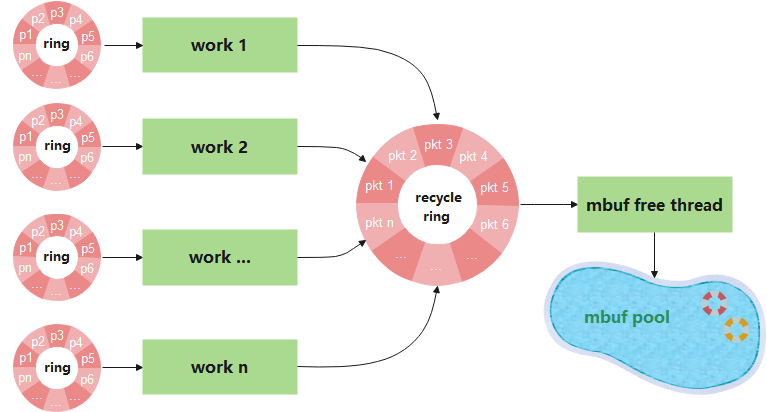
圖9
1、每一個work從對應的ring環消費packet;
2、每一個work thread處理完業務後,作為生產者將packet生產至recycle ring;
3、mbuf free thread作為消費者,從recycle ring消費元素,通過呼叫rte_pktmbuf_free實現mbuf的釋放。
從哪可以獲取一些幫助定位丟包問題的資訊呢?還是隻有通過紀錄檔,我們增加了各work執行緒對應ring環中待處理packet個數,以及mbuf回收執行緒待處理packet個數的實時統計紀錄檔。
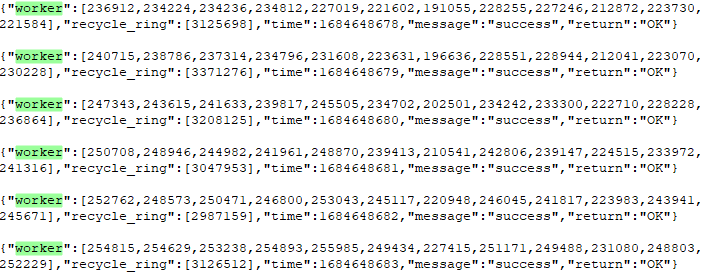
圖10
從紀錄檔可以得到兩個資訊:
1、一共12個work執行緒,每一個work執行緒的ring環中都出線了元素堆積;
2、recycle ring出現了元素堆積,且接近recycle ring的長度極限;
真實原因開始逐漸顯現,是因為mbuf free thread來不及消費導致recycle ring堆積,各work也無法及時向recycle ring生產,也導致了work各個ring環堆積!就像高速路上的汽車一樣,前方不遠處堵車,最終你也得堵車。。。
那為什麼recycle ring會堆積呢?那就是mbuf釋放太慢了,記憶體池的mbuf基本所剩無幾,最終出現了圖7描述的問題 「imissed發生增長的同時,伴隨著rx_nombuf的增長!」
問題找到了,如何優化呢?想到了兩種方案:
1、再增加一對recycle ring、mbuf釋放執行緒,使一部分work向新的recycle ring生產;
2、取消recycle ring和mbuf釋放執行緒,由各work執行緒直接呼叫rte_pktmbuf_free進行mbuf釋放。
第一種方案稍微複雜一些,並且會增加資源開銷。同時存在一個潛在的問題:多個work作為生產者,同時向同一個ring環生產資料,是會產生競爭的。雖說是所謂的無鎖佇列,但是DPDK底層還是通過CMPSET原子操作實現的,只能說是將同步帶來的開銷降到了最低。因此,如果work越多,越有可能觸碰ring環的生產極限。
第二種方案更加簡單,且減小了資源開銷。由之前的mbuf free thread統一釋放,還不如各work獨自呼叫rte_pktmbuf_free釋放,因為獨樂樂不如眾樂樂啊。
不服就幹!於是乎mbuf的釋放方案就再次演進為如下圖所示邏輯。
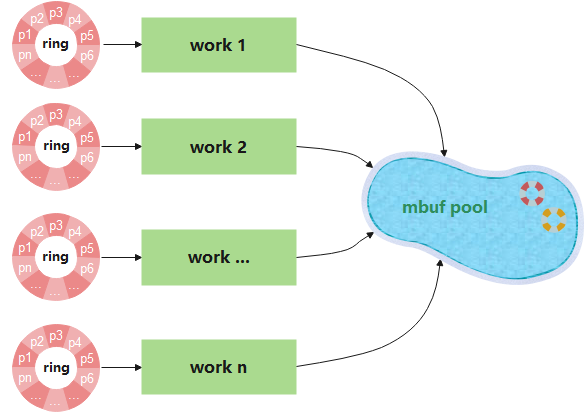
圖11
完成對應改造後繼續測試,但是還是發現work佇列有大量堆積,偶爾還是會出現丟包,並伴隨著rx_nombuf的增長。
再次陷入了僵局,感到有些心灰意冷,下班路上的淅瀝小雨迎面打在臉上,令我沮喪到了極點。回到家躺在床上也是遲遲不能入睡,思考著每一個細節和下一步的調查手段。第二天清晨醒來,自己又像被打了雞血一樣,發誓要死磕到底!這種心理狀態確實是我這段是時間的真實寫照:雄心壯志上班,垂頭喪氣下班,周而復始。
再回頭看看業務邏輯:work執行緒從對應ring環取出mbuf,最後直接呼叫rte_pktmbuf_free釋放mbuf,中間只有業務處理。懷疑業務過慢?好,遮蔽掉業務流程,且work取出packet後立即釋放packet。結果居然與業務遮蔽前一致,即還是偶發丟包!好,那就說明這裡的瓶頸不在業務流程上,可以懷疑的只有rte_pktmbuf_free了。
描述到這裡,才真正到了本小節的核心點:mbuf的釋放有講究!講究並不是指前面改造的mbuf釋放方案,而是指使用rte_pktmbuf_free時,如何避坑!
那就研究一下rte_pktmbuf_free吧。下面不得不用程式碼的形式來介紹rte_pktmbuf_free,提取了rte_pktmbuf_free內部實現的一部分關鍵函數做簡要說明。
第一步先介紹mbuf釋放時,檢查當前執行緒是否存在獨享的小記憶體池cache。
1 #define RTE_PER_LCORE(name) (per_lcore_##name)
2
3 static inline unsigned
4 rte_lcore_id(void)
5 {
6 return RTE_PER_LCORE(_lcore_id);
7 }
8
9 static __rte_always_inline struct rte_mempool_cache *
10 rte_mempool_default_cache(struct rte_mempool *mp, unsigned lcore_id)
11 {
12 if (mp->cache_size == 0)
13 return NULL;
14
15 if (lcore_id >= RTE_MAX_LCORE)
16 return NULL;
17
18 rte_mempool_trace_default_cache(mp, lcore_id,
19 &mp->local_cache[lcore_id]);
20 return &mp->local_cache[lcore_id];
21 }
22
23 static __rte_always_inline void
24 rte_mempool_put_bulk(struct rte_mempool *mp, void * const *obj_table,
25 unsigned int n)
26 {
27 struct rte_mempool_cache *cache;
28 cache = rte_mempool_default_cache(mp, rte_lcore_id());
29 rte_mempool_trace_put_bulk(mp, obj_table, n, cache);
30 rte_mempool_generic_put(mp, obj_table, n, cache);
31 }
概括起來可表述為:
1、通過rte_mempool_default_cache檢查當前執行緒是否存在獨享的小記憶體池cache;

2、如果mp->local_cache[lcore_id]為NULL,則cache為空,表明當前執行緒不存在這麼一個小記憶體池cache;否則cache是一個有效地址,即當前執行緒存在這麼一個小記憶體池cache。注意rte_lcore_id(),後面會重點分析。
第二步,介紹mbuf釋放時的兩種不同邏輯。
1 static __rte_always_inline void 2 rte_mempool_do_generic_put(struct rte_mempool *mp, void * const *obj_table, 3 unsigned int n, struct rte_mempool_cache *cache) 4 { 5 void **cache_objs; 6 7 /* No cache provided */ 8 if (unlikely(cache == NULL)) 9 goto driver_enqueue; 10 11 /* increment stat now, adding in mempool always success */ 12 RTE_MEMPOOL_CACHE_STAT_ADD(cache, put_bulk, 1); 13 RTE_MEMPOOL_CACHE_STAT_ADD(cache, put_objs, n); 14 15 /* The request itself is too big for the cache */ 16 if (unlikely(n > cache->flushthresh)) 17 goto driver_enqueue_stats_incremented; 18 19 /* 20 * The cache follows the following algorithm: 21 * 1. If the objects cannot be added to the cache without crossing 22 * the flush threshold, flush the cache to the backend. 23 * 2. Add the objects to the cache. 24 */ 25 26 if (cache->len + n <= cache->flushthresh) { 27 cache_objs = &cache->objs[cache->len]; 28 cache->len += n; 29 } else { 30 cache_objs = &cache->objs[0]; 31 rte_mempool_ops_enqueue_bulk(mp, cache_objs, cache->len); 32 cache->len = n; 33 } 34 35 /* Add the objects to the cache. */ 36 rte_memcpy(cache_objs, obj_table, sizeof(void *) * n); 37 38 return; 39 40 driver_enqueue: 41 42 /* increment stat now, adding in mempool always success */ 43 RTE_MEMPOOL_STAT_ADD(mp, put_bulk, 1); 44 RTE_MEMPOOL_STAT_ADD(mp, put_objs, n); 45 46 driver_enqueue_stats_incremented: 47 48 /* push objects to the backend */ 49 rte_mempool_ops_enqueue_bulk(mp, obj_table, n); 50 }
概括起來可表述為:
1、當cache為NULL,直接通過末尾的rte_mempool_ops_enqueue_bulk釋放。注意,是每次只釋放一個mbuf;
2、若cache不為NULL。當釋放的個數小於閾值flushthresh時,將釋放的mbuf拷貝至當前執行緒小記憶體池cache,並立即返回(不做真正的釋放);當本次釋放的mbuf個數與cache池之和即將超過flushthresh時,先一次性批次釋放小cache記憶體池的所有mbuf,再將本次待釋放的mbuf拷貝至cache池,再次立即返回。
DPDK為什麼設計執行緒獨享的小記憶體池cache?我想應該是為了更高效的釋放mbuf。
好比我們去ATM機上取錢,假設總共取一萬元。第一種是每次先插卡、輸入密碼、輸入100、取出100、再拔卡,完成一次操作,反覆執行1萬次;第二種是先插卡、輸入密碼、輸入10000、聽一會錢翻滾的聲音,取出1萬元、最後拔卡。毋庸置疑,第二種方式的效率實在是高效太多,存錢也是一樣的道理。我不禁想到,我不會就是用的第一種方式(每次只還一個mbuf)歸還mbuf吧,難道當前每個執行緒的獨享cache池未生效?此時,上面提到的rte_lcore_id()又重新成為了重要線索!
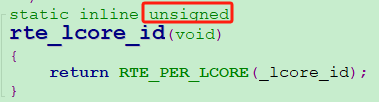
1、通過rte_lcore_id()可以得到什麼?
返回的是一個unsigned值,最終用於獲得當前執行緒的cache偏移地址。這個unsigned變數的值,是變數 per_lcore__lcore_id 的值
2、per_lcore__lcore_id變數如何定義的?
是通過 RTE_PER_LCORE 宏定義的。per_lcore_##name,' ## ' 操作符用於將引數name與字串 per_lcore_ 連線起來,形成新的識別符號。由於傳遞的是_lcore_id,因此有最終定義變數 per_lcore__lcore_id。但是什麼時候定義的,還要繼續看文章接下來的描述。

3、per_lcore__lcore_id變數在什麼時候定義的,是什麼時候初始化的?每個執行緒的獨享cache池又是何時初始化的?怎麼才能正確使用cache池?
為了弄清楚這三個問題,又追了一遍DPDK原始碼,而且稍微有些複雜,讓我娓娓道來吧。
(a) per_lcore__lcore_id在DPDK為每一個邏輯核建立worker執行緒時定義並初始化的
1、DPDK初始化呼叫rte_eal_init過程中,會為當前裝置的所有邏輯核建立一個worker執行緒。語句RTE_LCORE_FOREACH_WORKER是一個迴圈,RTE_MAX_LCORE為當前裝置的邏輯核個數,有多少個邏輯核,就建立多少個worker執行緒。


2、接下來,在每一次的迴圈過程中,呼叫pthread_create,使用回撥函數eal_worker_thread_loop建立每個邏輯核的worker執行緒

3、eal_worker_thread_loop封裝了eal_thread_loop,到此我們終於看到了__rte_thread_init,即per_lcore__lcore_id變數定義並初始化的函數
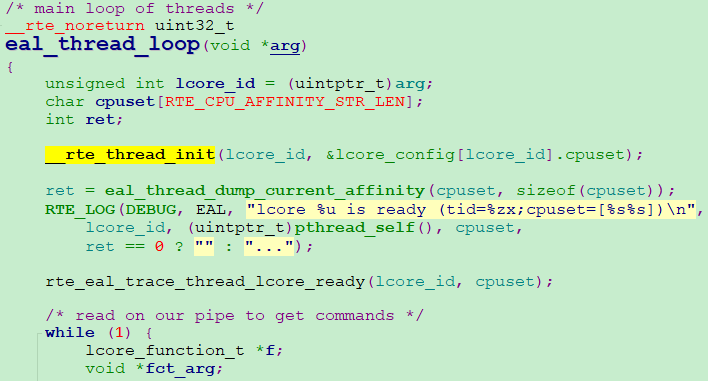
4、RTE_PER_LCORE(_lcore_id) 定義變數per_lcore__lcore_id,整個語句RTE_PER_LCORE(_lcore_id) = lcore_id 完成對per_lcore__lcore_id變數賦值,賦值為當前邏輯核的 id 值,通過lcore_id傳參 !
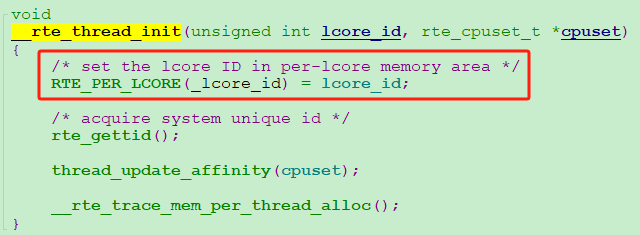
(b) 每個執行緒獨享的cache池何時初始化的?
答案就是在dpdk建立公共大記憶體池時完成的,通過rte_pktmbuf_pool_create最終呼叫rte_mempool_create_empty實現。你看,建立記憶體池的函數裡還為每一個邏輯核建立了一個獨享cache池,locore_id就是每個邏輯核的id!這樣,每個獨立的小cache池就和每個worker執行緒對應起來了。

(c) 怎麼才能正確使用cache池?
兄弟們,走過路過,千萬不能錯過。祕籍終於來啦!
那就是:需要釋放mbuf的執行緒,也就是會呼叫rte_pktmbuf_free方法的執行緒,必須通過rte_eal_remote_launch來建立!

rte_eal_remote_launch的引數 f 就是使用者指定的業務回撥函數,arg 是 f 的執行引數,worker_id是你希望業務函數 f 所執行的邏輯核id,因為通過正確的worker_id才能和對應的worker執行緒實現通訊!
rte_eal_remote_launch最後通過eal_thread_wake_worker向對應邏輯核的worker執行緒管道傳送一個message,通知worker執行指定函數 f。
最後,對應worker的回撥函數eal_thread_loop通過while,迴圈等待rte_eal_remote_launch傳送的message,收到訊息後,便開始執行你傳遞的業務回撥函數 f 。
函數 f 裡呼叫rte_pktmbuf_free時,通過rte_lcore_id()可以獲取到本worker執行緒定義並初始化過的per_lcore__lcore_id變數,因此最終成功找到本執行緒的獨享cache池地址!
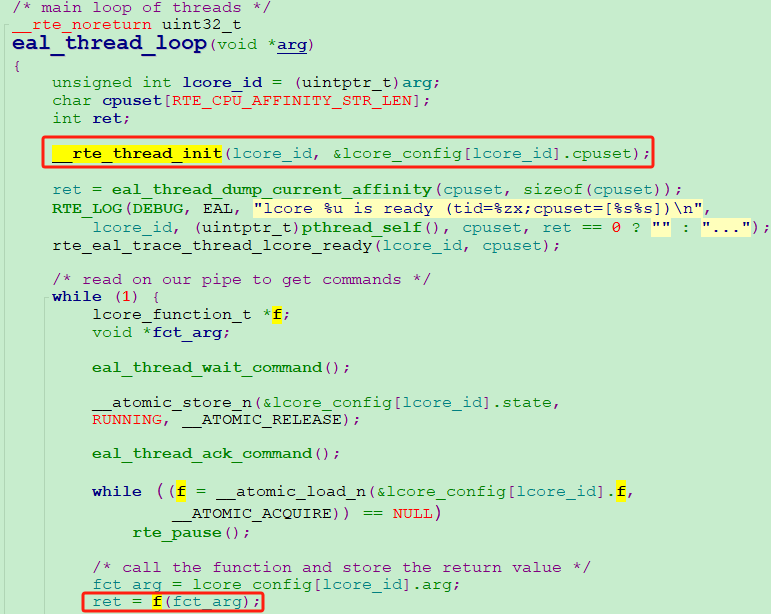
最後一個問題!為什麼我的執行緒專屬cache池未生效?
到這裡,終於可以明確回答了,我們的業務執行緒都是自己呼叫的pthread_create來建立的業務執行緒,建立過程中也未呼叫__rte_thread_init初始化per_lcore__lcore_id變數(雖然我們業務執行緒也是綁核、獨佔該執行緒),導致各執行緒呼叫rte_pktmbuf_free釋放mbuf時,變數per_lcore__lcore_id都是未定義的!返回的是一個不正確的值,導致cache為NULL,因為找不到這麼一個執行緒專享cache池,所以最終所有執行緒的mbuf都是逐個釋放的!後來改為rte_eal_remote_launch才最終解決問題!
使用pthread_create來直接建立的業務執行緒,再呼叫__rte_thread_init初始化per_lcore__lcore_id變數,在釋放mbuf時講道理也能正確獲取到執行緒cache池,不過沒有求證過。
到這裡,本小節終於講完了。整理這些資訊感覺挺累的,做程式設計師是真的不容易!
二、x86平臺優化總結
回頭看x86的優化過程,好比是從頭到尾的疏通了一條下水道。
執行緒任務儘可能輕量--解決了引水,保證水都能進來;mbuf的釋放有講究--既疏通了內部水道,也實現了引水的完整排放。自從水道暢通,10Gbps,20Gbps,40Gbps吞吐都不在話下啦!
除了綁核、執行緒獨佔、記憶體池巨頁分配、CPU performance模式設定等基本的效能優化手段,DPDK的實際效能表現還是和你的業務程式碼框架和實現有很大關係。零件都是好零件,就看自己如何搭,希望大家少踩點坑吧!
看到這,請先喝口水,休息一會吧!接下來的內容也很精彩。
··················下 篇··················
一、arm平臺調查優化經歷
接下來我們看點不一樣的:丟包跟你沒關係!瓦特?

相信我XDM:是軟體觸碰了硬體效能瓶頸。
將x86平臺無比絲滑的業務搬到了arm平臺,結果慘不忍睹。arm國產化平臺我們嘗試過「XX」的兩款伺服器級別CPU,結合我們的業務,資料不僅丟得多,而且丟得非常的莫名其妙。
(1)丟包現象
先看看發生了什麼。

圖12
首先是丟包,其次是丟包現象與上前文圖3有些區別,圖3是:丟包時伴隨佇列que滿。
而此時是:發生丟包時,佇列que並沒有滿,且距離佇列滿還非常遙遠(佇列已經設定得非常大,32768個描述符空位)。檢視其它統計:各worker執行緒的待處理mbuf很少,沒有堆積;也沒有出現rx_nombuf,即記憶體池足夠大,不存在記憶體申請失敗。
這就完全不知道從哪開始著手調查了,最難理解的就是:只使用DPDK進行收包(相當於遮蔽了所有業務流程),然後立即釋放mbuf,還是會發生丟包,並且其它所有指標居然都是正常的。
這到底是撞了什麼鬼?竟然還有如此怪異的現象發生,丟包到底丟在哪裡了,實話實說,我是真的不知道!
(2)丟包點追蹤
到了說不清,道不明的階段,混沌了。但是老闆不認啊,拿錢辦事,你得說個一二三。說不知道就是請出門左轉見HR,打工人的卑微。
沒辦法,繼續看起了原始碼。思考,分析了一段時間,結合理論,陸陸續續才開始產生了一些新的思路和想法。
1、imissed的定義是什麼?

Total of Rx packets dropped by the HW。指統計的是被hardware所丟棄包的總和,即硬體丟棄的packet之和。什麼硬體?不清楚。
because there are no available buffer (i.e. Rx queues are full)。因為Rx queues沒有可用buffer,例如:Rx queues接收佇列滿。注意這裡只提到了「接收佇列滿」這一種情況,這種描述符合上文圖3的現象:丟包時伴隨佇列滿。但是並不符合圖12的丟包情形:丟包時佇列未滿。
2、從物理層到最終的應用層,封包是如何流轉的?
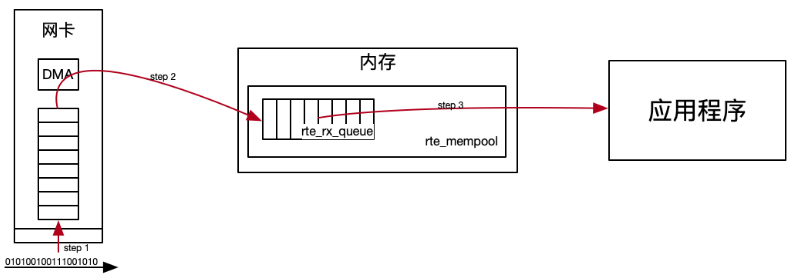
a、網路卡收到封包;
b、由DMA將封包拷貝到記憶體中的ring buffer,即DPDK的收包佇列Rx queue;
c、應用程式通過輪詢的方式將封包取走,供業務使用。
3、猜測是網路卡丟包
結合圖3和圖12的兩種丟包現象分析:
圖3:DPDK的Rx queue已經被收上來的封包填滿,無可用buffer,因此DMA也無法將封包拷貝到Rx queue的地址空間,所以imissed同步增長。
圖12:Rx queue統計值未滿,很空,imissed卻偶爾增長,偶發丟包。
這裡假設imissed是基於DPDK Rx queue的統計。那第一種和第二種丟包就會自相矛盾,因為第二種丟包現象發生時,queue根本沒有滿,那麼不可能出現imissed統計增長。因此「imissed是基於DPDK Rx queue的統計」這種假設是不成立的。
DPDK對queue的統計不可靠?不可能的事情。
4、為什麼判斷是網路卡丟包?
我們使用的是82599 10Gigabit 網路卡,且測試流量在6Gbps±,按道理是能覆蓋的。
回憶一下前面描述的imissed定義,指的是被硬體所丟棄包的總和。再看看DPDK原始碼imissed的統計相關程式碼:
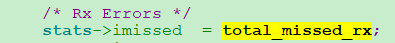
total_missed_rx的統計來源於8個 IXGBE_MPC 暫存器。
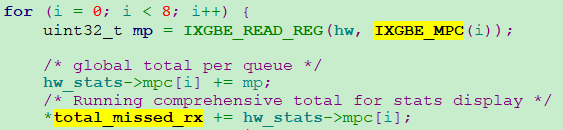
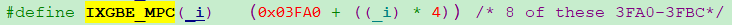
統計最終從IXGBE_MPC暫存器完成讀取,IXGBE_MPC暫存器是ixgbe網路卡的暫存器嗎?又下載一份82599 ixgbe網路卡手冊繼續追,總共1000+頁,感到崩潰。
只有搜關鍵字了,「IXGBE_MPC」,「MPC」,「0x03FA0」,還真找著了。ixgbe網路卡里叫RXMPC暫存器,也是總共有8個,和DPDK原始碼裡的暫存器地址對上了。
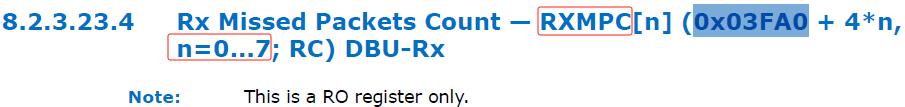
再找找RXMPC暫存器的相關資訊。

手冊上說,當Rx packet buffer發生overflows時,會丟包!
Missed packet interrupt is activated for each received packet that overflows the Rx packet buffer (overrun)。即當 Rx packet buffer 溢位時,接收的每一個包都會產生一個丟包中斷事件,並且記錄在「EICR」暫存器的第17bit。
另外,每一個丟包都會被計數增加至暫存器 RXMPC[n] 中。明白了,DPDK的imissed統計數值讀取的是網路卡的RXMPC計數暫存器!
和DPDK原始碼關於imissed的定義:統計的是被hardware所丟棄包的總和。這個hardware指的就是網路卡,這裡與DPDK原始碼又對上啦!
那 Rx packet buffer 是哪裡的buffer,是指的DPDK的Rx queue,還是網路卡自身的Rx packet buffer?
看到這裡越來越興奮了,再找一下Rx packet buffer是什麼。

手冊說是一個可程式化的記憶體接收空間,大小為512KB。再看看詳細介紹。
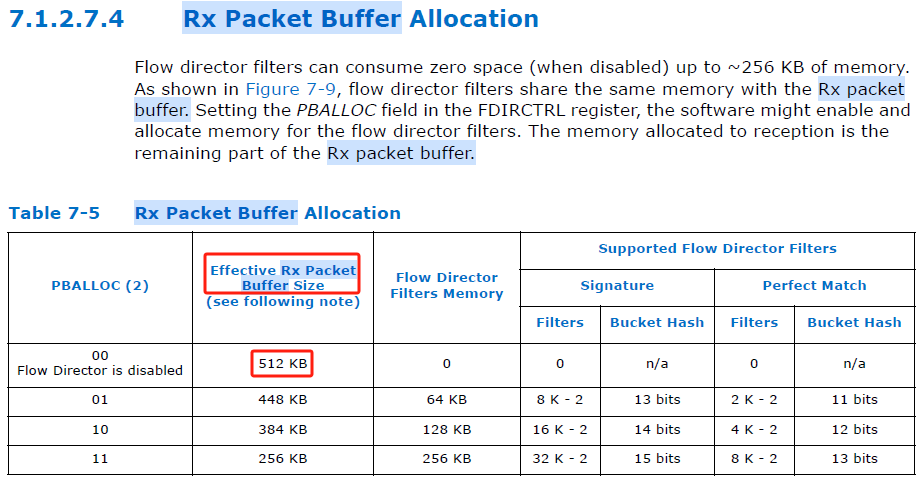
Rx packet buffer也指的是82599網路卡自身的包儲存緩衝區!總共有512KB。且網路卡支援流控,當關閉流控時,所有的512KB會全部用於資料接收。
再找找手冊上有沒有與封包接收的相關介紹。

看到這裡我已經高興壞了。因為手冊已經說得很清楚了,網路卡收到封包後會先將封包儲存至網路卡的receive data FIFO(即512KB的Rx packet buffer),然後再通過DMA將封包投遞至指定的本主機的接收佇列裡。receive queue,才是指的DPDK的Rx queue!
上面所有的關鍵資訊總結起來就是:
a、82599網路卡有一個封包接收的FIFO佇列緩衝區,最大為512KB;
b、當512KB的Rx packet buffer發生overflow時,網路卡會丟包;
c、網路卡發生丟包時,將丟包計數到 RXMPC暫存器,同時會產生丟包中斷事件,且事件資訊記錄在網路卡EICR暫存器的第17 bit。
(3)網路卡丟包證明
接下來就是該證實上面的猜測了。記得證實猜測的前一個晚上很興奮,一直沒睡好,總想著第二天趕緊去把它坐實了!
我們在ixgbe imissed的統計函數ixgbe_dev_stats_get,模擬讀取imissed的統計值,增加讀取EICR暫存器變數的邏輯,最終通過紀錄檔實時列印EICR暫存器值。
一起來見證精彩時刻:

圖13
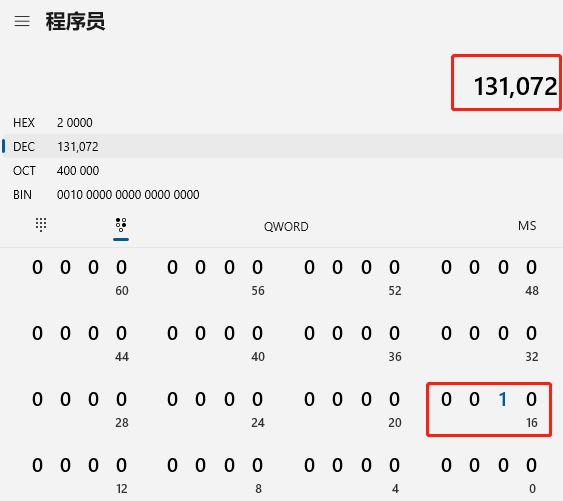
圖13可總結為:
1、當第一次發生imissed時,EICR暫存器的十進位制值為131072,que未滿;
2、第二次、第三次發生imissed時,EICR也為131072,que也未滿;
3、其它時刻,未發生丟包,EICR值均為0。
紀錄檔裡的「131072」代表了什麼?就是EICR暫存器第17bit被置1時的十進位制值。真相大白,真的是網路卡發生了丟包啊!
興奮之情,實在是無以言表!我居然也體會到了:提出猜想,並驗證猜想的快樂!
到這裡我們就可以把網路卡imissed丟包歸類為兩種情況了:
1、DPDK的環形接收佇列Rx queue溢位時,會發生imissed;
很明顯,DPDK的Rx queue溢位,代表上層來不及收包,Rx queue無多餘空閒空間,那DMA也無法將網路卡佇列的封包及時拷貝至Rx queue,最終導致網路卡的 FIFO 佇列溢位,出現丟包。這種情形是大家最常見的!
2、DPDK的環形接收佇列Rx queue空閒,而網路卡的FIFO佇列Rx packet buffer獨自溢位時,也會發生imissed。
這種情況是不多見的,但是我們arm平臺剛好碰到了這種情況!
兩種丟包情形,其實本質都是因為網路卡的緩衝區溢位導致,一個是間接導致,一個是直接導致。這個結論在這之前是不是沒見過?哈哈。我搜遍了內外網反正是沒看見過。
(4)網路卡緩衝區為什麼會獨自溢位?
回答這個問題前,我們先來看看網路資料是如何達到記憶體的。
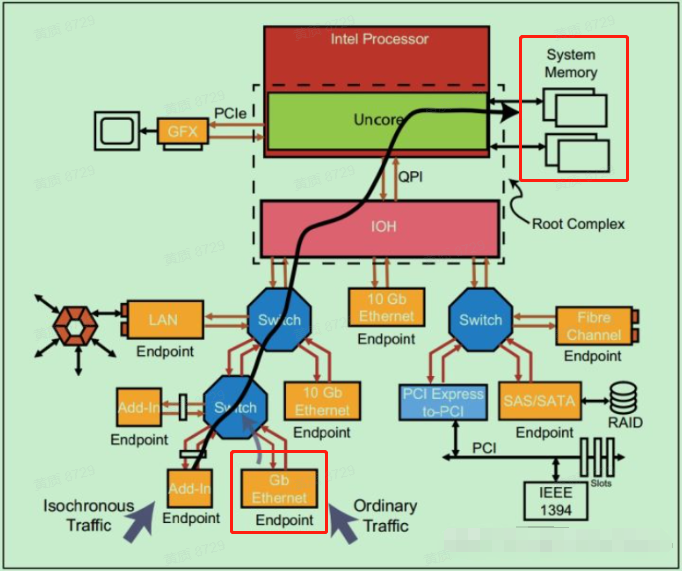
簡單描述為:
1、網路封包到達網路卡;
2、DMA將封包從網路卡經由PCIE通道傳遞至與CPU直連的記憶體中。
那在硬體上至少有3個地方可能存在效能瓶頸,一個是PCIE通道頻寬;第二個是記憶體頻率;第三個是CPU。
PCIE,協商出來的頻寬是4GB/s,10Gbps收包,即使加上業務I/O速率,遠遠低於這個值,因此應該不存在效能瓶頸。
記憶體頻率,我們x86也是使用一樣的記憶體條,按理也不存在效能瓶頸。
那就只剩CPU了,為何懷疑CPU存在效能瓶頸呢?我們再看一個圖。
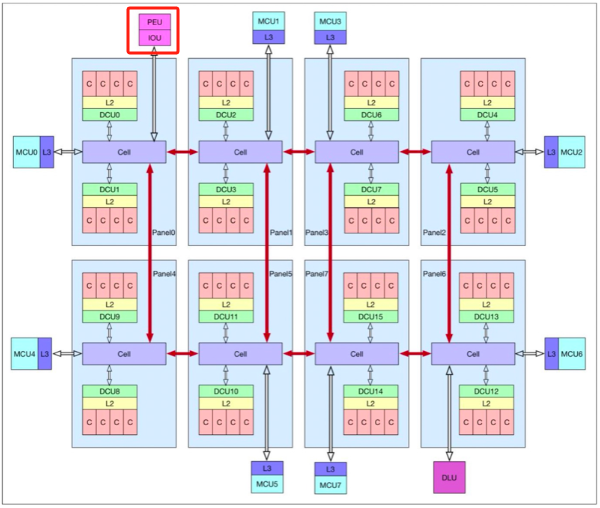
如果有同行以前看到過這個圖,其實就知道arm平臺的這款晶片名字了。
從官方給的CPU結構圖看,PEU(可以理解為是PCIE與CPU的介面)與numa0直接相連,且只與numa0相連。我個人理解:這種架構比較容易觸碰效能瓶頸,因為整個CPU的所有I/O資料,包括網路I/O、磁碟I/O都必須經過numa0,numa0表現的頻寬就會成為整個CPU的效能瓶頸。而且其它numa的I/O資料只能通過numa0的QPI匯流排傳遞和轉發。
因此,懷疑是網路卡單獨溢位的原因是:I/O增大時,資料規模達到numa0的資料頻寬,多種資料形成競爭關係,導致DMA不足以及時的將網路卡緩衝區資料傳遞至記憶體,最終導致網路卡緩衝區溢位丟包。
不過這裡我只是猜測,也沒有辦法去證實了。如果有這方面的專家,還望不吝賜教。
再看看intel某款晶片的CPU架構圖:
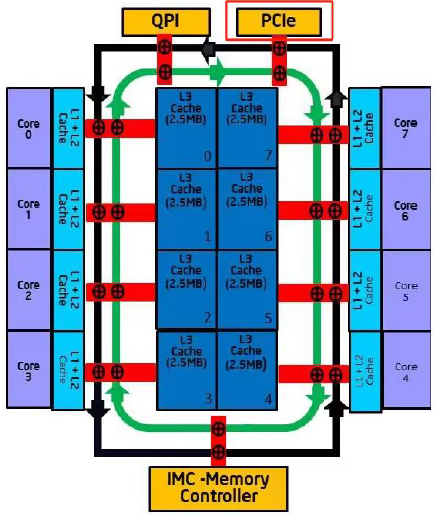
PCIE匯流排不與任何核心直接相連,節點相連,且各numa或者core獲取 I/O 資料不需要任何其它numa或者core來中轉,可以極大的提高匯流排頻寬。
(5)還有效能優化空間嗎?
arm平臺碰到的丟包問題完全超出了業務開發人員的能力範疇。不過還好分析出了丟包點和丟包原因,俗稱甩鍋。
但是任何東西,包括人,有時候榨一榨就還能得到點什麼,懂的都懂。
繼續做了以下幾點優化:
1、DPDK收包相關執行緒工作在同一個numa上;
2、DPDK記憶體池分配在收包執行緒所在的numa節點上;
3、儘可能的加大記憶體池規模。
你還別說,又提升了2個Gbps,應該是DPDK減小資源競爭獲得的收益。不過至此以後真的再也沒有任何提升手段了。
哦,差點忘了,arm平臺的DPDK還有一個坑,也是無意中發現的:收包函數rte_eth_rx_burst的第四個引數nb_pkts,一定要是2的指數冪,即2 ^ 10 = 1024,2 ^ 14 = 16384,2 ^ 15 = 32768這種形式。如果指定任意2的非指數冪整數,DPDK會將向量化收包(neon,arm平臺的SIMD技術)替換為非向量化收包函數,極大的降低收包效能。例如將ixgbe_recv_pkts_vec替換為ixgbe_recv_pkts_bulk_alloc。
二、arm平臺優化總結
arm平臺碰到了很罕見的丟包現象,通過查閱原始碼和網路卡手冊,最終定位到是網路卡自身發生了丟包,跟DPDK沒有太大關係。如果非要說有關係,那就是DPDK佔用的資料通道頻寬擠壓了DMA的資料傳遞。
另外一個大的收穫就是確定了imissed一定是基於網路卡的統計。發生imissed時,一種是我們常見的間接原因導致imissed(上層不能及時收包,導致DPDK ring滿,然後導致DMA無法投遞至ring環,最終網路卡緩衝區溢位);另一種就是我們在arm平臺碰到的直接原因導致的imissed(資源競爭直接導致DMA無法及時將封包投遞至DPDK ring環,導致網路卡緩衝區溢位,且DPDK ring環非常空閒)。
最後通過減小DPDK資源競爭的方法(一是減少垮numa記憶體存取,二是DPDK加速獲取報文接收的mbuf。我理解可以減少資料在多種資源下的傳輸吧),提升了一丟丟效能。
好了,前前後後寫了一個月,本次就分享到這裡吧!謝謝閱讀!
技術是不斷實踐積累的,在此分享出來與大家一起共勉!
如果文章對你有些許幫助,還請各位技術愛好者登入點贊呀,非常感謝!
本文來自部落格園,作者:T-BARBARIANS,博文嚴禁轉載,轉載必究!