Amazon MSK 可靠性最佳實踐
1. Amazon MSK介紹
Kafka作為老牌的開源分散式事件流平臺,已經廣泛用於如資料整合,流處理,資料管道等各種應用中。
亞馬遜雲科技也於2019年2月推出了Apache Kafka的雲託管版本,Amazon MSK(Managed Streaming for Apache Kafka)。相較於傳統的自建式Kafka叢集,MSK有如下幾點優勢:
- 快速部署:作為完全託管的雲服務,Amazon MSK提供了原生多可用區(AZ)的Apache Kafka叢集部署模式,可以幫助客戶快速設定並部署高度可用的Apache Kafka叢集
- 降低運維複雜度:Amazon MSK會自動檢測底層伺服器,並在出現故障時進行替換。也會編排伺服器的修補程式與升級。同時還確保資料得到長久儲存和保護,方便快捷地檢視監控指標並設定警報
- 彈性擴充套件:充分利用雲服務的資源彈效能力,可以根據負載變化自動進行擴充套件
- 與其他AWS服務緊密整合:Amazon MSK 與 AWS Identity and Access Management (IAM) 和 AWS Certificate Manager 整合以實現安全性;與 AWS Glue Schema Registry 整合用於schema管理;與 Amazon Kinesis Data Analytics 和 AWS Lambda 整合用於流式傳輸處理,等等。使應用程式的開發更簡單
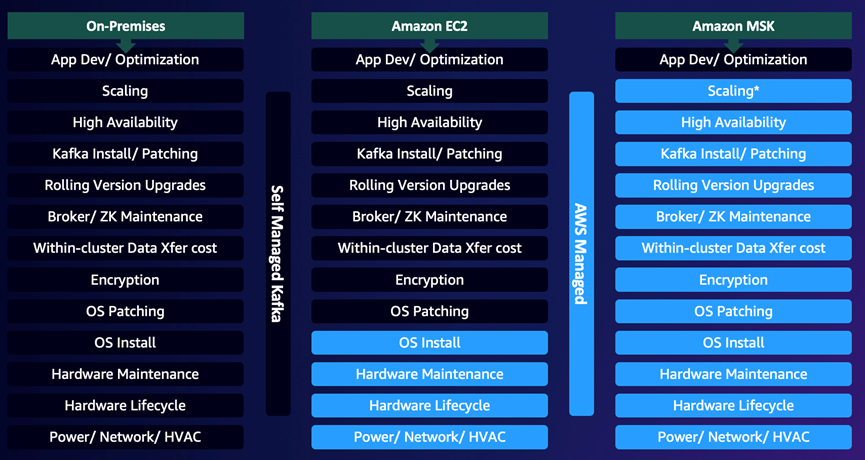
下面對比圖很清晰地描述了在本地、EC2部署Apache Kafka以及Amazon MSK的對比。使用Amazon MSK服務,可以讓使用者將更多的時間與精力關注在應用開發與執行上。
2. 構建可靠的訊息佇列平臺
Amazon MSK作為託管服務,除了上面提到的優勢外,還提供了基礎設施穩定執行的保障(例如底層的EC2,EBS卷等,分別有其對應的SLA保障)。但是,對於底層硬體,達到0%的故障率是非常難以企及的事情,我們無法忽視這部分不確定性對業務帶來的影響。所以在構建Apache Kafka的訊息佇列平臺時,仍需根據不同場景,調整Kafka相關引數,達到可靠性要求。而在我們提到可靠性時,往往表示的是整個系統的可靠性,而非單個元件的可靠性。所以在調整時,除了叢集本身的引數外,還包括使用者端的引數。
為避免歧義,我們定義在本文中提到的「可靠」的含義。其表示的是:在出現不同的系統故障時,Kafka訊息佇列系統仍能正常對外提供服務,不影響業務的正常執行且儘可能減少資料丟失的風險。
下面我們會首先介紹Kafka提供的基本保障,以及基於這幾個基本保障之上,Kafka叢集、生產者使用者端,以及消費者使用者端如何進行設定,以達到不同的保障性需求。
注意,下面文字內容較多,可以優先參考檔案第5部分的設定總結進行相關引數設定。
2.1. Kafka提供的保障
首先,我們先看看Kafka提供的4個基本保障:
- 同一partition內訊息的順序在寫入後不再變化
- 一條訊息在寫入到其partition對應的所有in-sync replicas(不一定已經flush到disk)後,此訊息才視為committed。而Producer可以設定是否接受ack以及ack級別
- 被committed訊息,只要有至少一個replica存活,則訊息不會丟失
- Consumer只能讀取到committed的訊息
在這4個基本保障中,與可靠性相關的部分主要為第2條,其中涉及到的Replication(副本)是Kafka提供可靠性保障的一個重要功能。也是Kafka實現高可用與資料高永續性的核心要素。
首先簡單地介紹Replication的功能(若希望瞭解更多細節,請參考檔案[2]):在Kafka中,每個partition可以有多個replica,其中1個為leader,其他的為in-sync replica。Leader replica負責寫入,以及消費。其他的in-sync replica只需要與leader保持同步狀態並實時複製訊息(也可以設定消費者從replica消費資料)。如果leader 不可用,則其他replica會選舉為新的leader。
下面我們圍繞此機制展開,介紹構建可靠的Kafka訊息佇列平臺時,需要考慮的相關要點。
2.2. Broker設定
在broker層面,與可靠性相關的設定主要有3個,分別為default.replication.factor,unclean.leader.election.enable以及min.insync.replicas。
Replication Factor
Replication factor控制的是訊息備份數,topic級別的設定項為 replication.factor,broker級別的設定項為 default.replication.factor。在MSK中,default.replication.factor預設為3 for 3-AZ clusters, 2 for 2-AZ clusters。
Replication factor設定為N時,可以允許N-1 個broker丟失時還能正常提供topic的讀寫服務。所以此引數的值越高,系統的可用性、可靠性越高,故障容忍度也更高。但另一方面,我們需要的broker數(至少N個broker),磁碟量也會更多(N倍的資料儲存量),同時broker之間的流量也會增加(N-1倍的複製流量)。所以這裡在可用性與硬體設施上需要有所權衡。
另一方面,在資料冗餘方面,Kafka會確保同一個partition的各個replica分佈在不同的broker上。但僅有這點是不夠的安全的,最好還將broker分佈在不同的機架甚至不同的資料中心,達到更高的資料持久型保障。而Amazon MSK便是將broker跨多個可用區進行部署。
對於replication factor引數,常規調整準則為:
l 以3為起始(當然至少需要有3個brokers,同時也不建議一個Kafka 叢集中節點數少於3個節點)
l 如果由於replication 導致效能成為了瓶頸,則建議使用一個效能更好的broker,而不是降低RF的值
l 永遠不要在生產環境中設定RF為1
Unclean Leader 選舉
對於1個partition來說,如果其leader replica出現故障且不再可用,則會在其in-sync replicas中選舉一個新的leader replica。對於這個過程,我們稱為一個「clean」選舉,因為這個過程沒有committed資料丟失,committed資料存在於所有in-sync replica上。
與「clean」選舉相反的為「unclean」選舉,其表示的含義是:並不一定要強制從in-sync replica中選舉leader,也允許out-of-sync replica選舉成為leader。Out-of-sync replica,如字面意思,表示此replica與leader中間存在同步落後的情況(落後的原因可能包括網路延遲,broker故障等)。
為什麼需要考慮允許out-of-sync replica選舉成為leader?舉一個例子,假設一個partition有3個replica,有2個in-sync replica已經出現故障,僅有leader在正常工作。過了一會兒,leader出現故障,並很快有1個replica恢復。此時,這個replica為out-of-sync replica(因為中間有一段時間未與leader同步資料)。
若是不允許out-of-sync replica選舉成為leader,則此partition將無法繼續提供服務,除非等到leader恢復正常。若是允許out-of-sync replica選舉成為leader,則此時partition可以繼續提供服務,但是會有部分資料丟失(之前未同步的資料)。所以,這裡也涉及到可用性與資料持久型的權衡。
控制此行為的引數為unclean.leader.election.enable,在broker級別(實際一般在叢集級別設定)適用。在MSK中預設為true,也即是說允許「unclean」選舉。在使用時,需要根據實際場景,在可用性與資料永續性之間進行權衡。
最少In-Sync Replicas
從我們上面的例子可以看到,造成資料丟失的主要原因是:leader與replica之間存在同步落後,且允許選舉out-of-sync replica為leader。這裡的問題在於:in-sync replica故障後,仍可以往leader正常寫入,導致了同步落後。
在Kafka提供的保障中,訊息在寫入leader及其所有in-sync replicas後,才視為committed。但是這裡「所有in-sync replicas」僅包含in-sync replicas,並不考慮out-of-sync replica。也就是說,如果當前partition有leader以及2個out-of-sync replica,則訊息在寫入leader後,便視為committed。
如果需要保證訊息至少寫入到多個in-sync replicas後才視為committed,則可以通過引數 min.insync.replicas 進行控制(可以在broker級別或是topic級別設定)。
舉個例子,假設我們MSK使用3 broker,default.replication.facto=3,min.insync.replicas=2。則至少有2個replica為in-sync狀態時(包括leader),此topic的partition才能被生產者正常寫入。如果1個replica發生故障(例如AZ宕機,broker故障等等),topic仍能正常進行讀寫。而若是有2個replica同時發生故障時,broker會拒絕所有寫入(Producer會收到NOT_ENOUGH_REPLICAS異常),topic轉為唯讀。
我們再回看在「Unclean Leader選舉」中的例子。在設定了min.insync.replicas=2後,若是有2個replica出現故障,則無法再進行寫入,繼而避免了後續更高的同步落後,資料永續性會更高。不過此時並非表示一定不會有資料丟失。舉一個非常極端的例子,假設leader與1個in-sync replica A正常工作,另一個replica B出現故障,此時topic仍能對外提供服務。過了一會兒,replica B 恢復(此時為out-of-sync replica),但是馬上leader與replica A 故障。若是unclean.leader.election.enable為true,則replica B 選舉為leader。此時雖然producer無法繼續寫入,但是replica B 與原leader之間未同步的資料會丟失。
在MSK中,min.insync.replicas引數預設為2 for 3-AZ clusters, 1 for 2-AZ clusters。更高的值可以提供更高的資料永續性,但是會犧牲一定的可用性。
2.2. Producer設定
系統可靠性強調的是整體的可靠性,即使我們在broker端下足功夫調整設定,使其達到儘可能高的可靠性。但如果producer端傳送訊息的機制不夠可靠,則整個系統仍有丟失資料的風險。
在Producer部分,實現可靠的Producer主要需要考慮2點:
- 根據可靠性需求,設定合理的acks引數值
- 妥善處理Producer異常
acks有3種模式,分別為:
l acks=0:producer在成功傳送一條訊息出去後,不需要broker端的response確認,即可認為寫入成功。 如果訊息傳送到broker 端時,broker下線或是發生了故障,則Producer端無法感知,且這部分資料會丟失。這種模式下,由於不需要broker的確認,所以寫入延遲較低。但是並非代表端到端延遲也低,因為只有訊息從leader同步到所有in-sync replica後,consumer才能讀取到這條訊息
l acks=1:producer在成功傳送一條訊息出去後,需要等待leader成功後寫入並返回ack後,才認為寫入成功。但是如果leader在尚未將訊息同步到in-sync replica前發生故障,則仍會丟失此訊息
l acks=all:producer在成功傳送一條訊息出去後,需要等待leader及其所有的in-sync replicas 成功寫入後,返回ack,才認為寫入成功。此引數必須與前面介紹的min.insync.replicas一起使用(控制最小所需寫入的in-sync replica數量)。此引數是最安全的選項,能夠確保訊息完全寫入到多個replica。不過顯而易見,也會引入更高的延遲
除了acks的設定外,Producer端還需要注意的一個點是異常的處理。為了防止一些瞬時的錯誤(例如NotEnoughReplicasException)影響整個應用,一般我們需要處理一些異常,以避免資料丟失。
Kafka裡的異常分兩種:
l 可重試異常(例如leader不可用):對這類異常Producer會自動進行重試。為了避免Producer端耗盡重試次數而導致資料丟失,建議設定Producer的重試次數為Integer.MAX_VALUE,並設定delivery.timeout.ms為最長的等待時間。讓Producer可以在遇到此類異常時不斷重試,直到寫入成功
l 不可重試異常(例如設定引數不對,訊息大小問題等):對這類問題,一般屬於使用者端問題,Producer也不會自動進行重試。從系統穩定性考量,開發人員需要根據業務場景,妥善處理這類異常,防止應用退出
最後,重試會帶來的一個風險是訊息的重複。重試可以保證訊息傳遞的語意為at-least-once,而非exactly-once。啟用enable.idempotence=true的設定可以使得Producer引入額外的資訊到record中,並以次讓Brokers可以過濾掉由於重試引入的重複訊息。
2.3. Idempotent Producer
首先,什麼叫做冪等(Idempotent)?其表示的是:對於一個操作,如果執行多次的結果和執行一次的結果都是完全一樣的,這樣的操作叫做冪等操作。
前面提到,在Kafka producer中,在通過重試做到訊息傳遞的at least once語意後,同一條訊息可能會多次傳輸,也就最終會導致可能的下游重複事件。
一個常見的情況是:producer傳送一條訊息到leader,leader在接收到後,將訊息成功的複製到了replica,但是在leader向producer傳送確認ack時,leader所在的broker宕機,導致沒有正常將ack傳送回producer。此時從producer的角度,它是沒有收到確認訊息的,所以會嘗試重發訊息。這條訊息會到達一個新的leader,它本身已經包含了上一條傳送的訊息,所以這種情況下就導致了訊息的重複。
在某些情況下,重複訊息不會對下游帶來影響(例如下游是put到nosql資料庫),但在部分情況下會導致下游資料重複(例如下游是append到資料庫)。
Kafka的idempotent producer(冪等生產者)功能可以解決這種問題,其方法是自動檢測並解決這類重複訊息。
2.3.1. 如何解決冪等問題
在啟用Kafka冪等生產者的功能後,每條訊息會帶上一個唯一的標識id,稱為PID(producer id),以及一個序列號。這個PID與序列號 加上 topic與partition資訊,可以唯一標識一條訊息。
Broker會用這個唯一標識訊息的資訊來跟蹤最近5條(由引數max.inflight.requests來控制,預設值為5)傳送到每個partition的訊息。當broker收到一條之前已經收到過的訊息時,會拒絕這條訊息並返回producer一條提示報錯資訊。在producer端,這個資訊會加入到record-error-rate的指標中。在broker端,這個報錯會歸類於ErrorsPerSec的指標,屬於RequestMetrics型別。
2.3.2. 冪等producer的作用範圍
Idempotent producer僅用於防止由於producer retry機制導致的訊息重複。例如由於producer沒收到ack,或者由於網路,broker問題導致的訊息沒有傳送成功,從而producer自動嘗試,並由此導致的可能的訊息重複問題。但如果是應用層的重試,例如應用端發現訊息未傳送成功,把失敗的訊息放入重試佇列,然後再次呼叫send()方法傳送訊息。這類重試的訊息會有新的唯一標識資訊,不在idempotent producer處理的範圍內。
2.3.3. 如何配idempotent producer
在producer端加上設定enable.idempotence=true即可。在開啟這個功能後,會有如下變化:
- 由於要從broker取producer ID,所以producer會在啟動時額外呼叫一個API
- 每個傳送的record batch會包含producer ID以及第1條訊息的sequence ID(batch中第1條之後的訊息的sequence ID是由第1條訊息的sequence ID 加上一個delta增量得來)。這些新的欄位會增加每個record batch 額外96bits(producer ID是long型別,sequence時integer型別)。
- Broker會驗證每個producer發過來的訊息中sequence number,並判斷是否為重複訊息
- Partition內的訊息順序仍能保持
2.4. Consumer設定
Consumer在消費Kafka資料時,主要需要確保的一點便是: 不漏消費訊息。保障此行為的機制便是offset commit。
Consumer 在消費了目標topic的訊息後,可以自動(按固定時間間隔)或手動的方式完成offset commit。Committed offset會記錄在Kafka的__consumer_offsets topic內(由group.id的值進行hash並寫入不同partition),下次消費會按照上次offset的位置繼續消費。
與offset commit相關的有4個重要的設定:
- group.id:用於標識消費組
- auto.offset.reset:如果當前消費組對目標topic沒有committed offset時(例如Consumer第一次消費),Consumer使用的offset位置(可設定為earliest或latest,預設為latest)
- enable.auto.commit:是否定期自動commit offset
- auto.commit.interval.ms:若是啟用了自動commit offset,指定自動commit的時間間隔,預設為5s。一般來說,間隔更短,Consumer的資源開銷會更大。但是在Consumer停止並重新啟動後,處理的重複資料更少。
可以看到,在使用自動commit offset機制時,訊息傳遞語意為at-most-once。會引入重複資料消費以及資料可能丟失的問題。例如,假設Consumer在拉取了Kafka的訊息後,需要寫入下游資料庫。在寫入資料庫時發生異常,導致一直未能寫入成功並最終失敗。由於自動commit offset的機制,Consumer仍會自動將已消費訊息的offset commit到Kafka端。若是這部分異常未能正常處理,則未能寫入下游的資料便會丟失。
所以,在複雜場景下,需要更高的端到端一致性以及準確性時,建議手動做commit offset。因為自動commit offset的機制無法保證訊息已被下游正確處理。
在執行手動commit offset時,常規考慮要點為:
- 在訊息被下游完全處理後,再手動commit offset
- Commit offset是一個較為耗費資源的操作。更頻繁的commit可以減少Consumer停止並重啟後重復消費資料的概率,但是會帶來更高的負載。此處需要對吞吐與可能的重複資料之間進行權衡。
- Consumers重試。例如上面介紹的Consumer消費資料並向下遊資料庫寫資料的例子,Consumer可能會遇到處理一個批次訊息時,部分訊息寫入下游資料庫失敗。此時Consumer端要做好重試的機制,例如將失敗的訊息進行快取,並進行重試。在重試時,對消費Kafka訊息的行為有2種處理方式:
a) 使用Consumer pause() 方法,確保polls不再返回新資料,優先將當前批次資料完全處理(一致性優先考量)
b) 將失敗的訊息寫入到另一個重試topic,並使用另一個消費組來處理失敗的訊息。當前Consumer可以繼續正常消費並處理(吞吐優先考量)
可以看到,手動執行commit offset的機制保證的訊息傳遞語意為at-least-cone語意。也就是說,訊息至少會被消費一次,但是仍可能會帶來可能的資料重複消費的問題。例如在處理一個批次訊息時Consumer發生異常退出,但是部分訊息已經寫入了下游。重啟Consumer後,仍會從這個批次的offset起始位置消費,並再次處理同一批資料(包含上次已經寫入下游的部分資料)。
針對這種at-least-once語意場景,常規的處理方式是:保證下游是冪等的(idempotent)。也就是說,重複資料在寫入下游時,重複訊息不會對下游應用的準確性產生影響。例如下游寫入ElasticSearch時,使用_id欄位唯一識別一條訊息,重複資料寫入時也是覆蓋同一個檔案。
2.4.1. 流處理引擎offset管理
最後,值得提到的一點是,在流處理引擎如Spark Structured Streaming以及Flink裡,offset commit的行為有所不同。
在Spark Structured Streaming中,(即使指定了group.id的設定)Kafka Source也不會commit offset到Kafka的,而是使用其checkpoint機制進行管理並做故障恢復。每次在執行checkpoint時,會將當前消費的offset記錄在其checkpoint檔案內。
若是有需求監控消費組的lag,則需要手動做commit offset到Kafka的操作。其中開源社群提供了一個方法可以直接參考[4]。
在Flink中,如果未啟用checkpoint,則使用的自動commit offset的方式,將offset定期提交到Kafka(仍通過enable.auto.commit與auto.commit.interval.ms進行設定)。
在啟用checkpoint後,同樣通過checkpoint機制進行管理並做故障恢復。在checkpoint完成後(offset已寫入checkpoint檔案),再將offset commit到Kafka。但是在故障恢復時,僅使用checkpoint內的offset。Kafka端的offset僅用於做消費lag監控。
3. 監控
對於平臺的穩定執行,監控是必不可少的。關鍵指標監控與報警機制可以讓我們及時地發現平臺的問題,並以自動或手動的方式介入,避免對系統穩定造成進一步的影響。
對於AWS MSK,官方提供了2種檢視監控指標的方式:CloudWatch與Prometheus。具體介紹可以參考檔案[5]。
在監控指標方面,提供了不同級別的指標,包括4種級別,分別為:DEFAULT,PER_BROKER,PER_TOPIC_PER_BROKER, PER_TOPIC_PER_PARTITION。除了DEFAULT級別外,開啟另外3個級別需要額外收費。所有可監控CloudWatch指標可以參考檔案[6]。
常用叢集負載與穩定性監控指標包括:
l ActiveControllerCount:應永遠為1
l Broker的CPU User與CPU System:兩者之和應低於60%
l Broker的KafkaDataLogsDiskUsed:使用率應低於85%
l HeapMemoryAfterGC:應持續保持在60%以下
l 消費者的Consumer Lag:消費是否能跟上
4. 驗證
下面我們使用此設定驗證Kafka的高可用。
首先建立一個3-AZ的MSK叢集。
使用kakfa cli建立1個topic,為:
l ha-topic:RF=3,min.insync.replicas=2
# 建立ha-topic ./kafka-topics.sh --bootstrap-server b-1.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-2.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-3.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092 --config min.insync.replicas=2 --partitions 6 --replication-factor 3 --topic ha-topic --create
建立safe-producer.config 組態檔:
retries=2147483647 delivery.timeout.ms=604800000 acks=all
使用kafka-verifiable-consumer消費訊息:
./kafka-verifiable-consumer.sh --bootstrap-server b-1.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-2.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-3.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092 --topic ha-topic --max-messages 10000 --verbose --reset-policy latest --group-id ha-consumer1
使用kafka-verifiable-producer生產訊息:
./kafka-verifiable-producer.sh --bootstrap-server b-1.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-2.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092,b-3.msk-tokyo.ytekjr.c4.kafka.ap-northeast-1.amazonaws.com:9092 --topic ha-topic --max-messages 100000 --throughput 100 --producer.config safe-producer.config
然後捲動重啟broker。每次重啟1個broker,並在重啟完畢後再重啟第2個broker(在本次測試環境中,重啟一個broker約4分鐘左右):
aws kafka reboot-broker --cluster-arn arn:aws:kafka:ap-northeast-1:113343415039:cluster/msk-tokyo/cff9d27e-6809-47c5-9f7a-a63f689ad026-4 --broker-ids 2 --profile global
可以看到在1個broker重啟時,

在此過程中,Consumer未遇到任何報錯。Producer遇到了以下報錯:
{"timestamp":1675758285482,"name":"producer_send_success","key":null,"value":"1340","offset":209259,"topic":"ha-topic","partition":2}
WARN [Producer clientId=producer-1] Got error produce response with correlation id 1342 on topic-partition ha-topic-0, retrying (2147483646 attempts left). Error: NOT_LEADER_OR_FOLLOWER (org.apache.kafka.clients.producer.internals.Sender)
Received invalid metadata error in produce request on partition ha-topic-0 due to org.apache.kafka.common.errors.NotLeaderOrFollowerException: For requests intended only for the leader, this error indicates that the broker is not the current leader. For requests intended for any replica, this error indicates that the broker is not a replica of the topic partition.. Going to request metadata update now (org.apache.kafka.clients.producer.internals.Sender)
{"timestamp":1675758285692,"name":"producer_send_success","key":null,"value":"1342","offset":209260,"topic":"ha-topic","partition":2}
{"timestamp":1675758285798,"name":"producer_send_success","key":null,"value":"1341","offset":210908,"topic":"ha-topic","partition":0}
從報錯前後的資訊來看,資料 1340,1341,1342均寫入了Kafka。並且可以在Consumer端列印的紀錄檔找到:
{"timestamp":1675758285482,"name":"record_data","key":null,"value":"1340","topic":"ha-topic","partition":2,"offset":209259}
{"timestamp":1675758285801,"name":"record_data","key":null,"value":"1341","topic":"ha-topic","partition":0,"offset":210908}
{"timestamp":1675758285815,"name":"record_data","key":null,"value":"1343","topic":"ha-topic","partition":1,"offset":207770}
{"timestamp":1675758285886,"name":"record_data","key":null,"value":"1344","topic":"ha-topic","partition":3,"offset":207459}
{"timestamp":1675758285890,"name":"record_data","key":null,"value":"1342","topic":"ha-topic","partition":2,"offset":209260}
且可以看到在partition級別,仍保持了有序。
5. 設定總結
根據以上介紹,總結在使用AWS MSK時,構建可靠高可用的MSK叢集的設定為:
1. MSK多AZ
- 使用3-AZ叢集
2. Broker/叢集端設定
- default.replication.factor設定至少為3(MSK為3-AZ時,預設為3)
- min.insync.replicas設定為RF-1。例如在RF為3時,minISR設定為2
3. Producer端設定
- acks=all
- 對於可重試異常,設定無限次重試:retries=MAX_INT
- 設定delivery.timeout.ms為最長的等待時間
- 在連線串裡填寫所有broker地址
- (可選)基於是否需要處理由於重試導致的重複資料,設定enable.idempotence
4. Consumer端設定
- 使用主動commit offset的機制,在資料被下游正常處理後再commit offset到kafka
由於MSK會自動做底層硬體的維護以及軟體的修補程式、升級等工作。其工作方式是做捲動升級,也就是說,在執行過程中會每次下線一臺broker,以捲動的方式進行維護。上述設定可以實現在這些場景下(包括替換broker)MSK的高可用,同時儘可能避免資料的丟失。
參考檔案
[1] MSK特點介紹:https://aws.amazon.com/cn/msk/features/
[2] Kafka資料複製: https://developer.confluent.io/learn-kafka/architecture/data-replication/
[3] MSK預設設定:https://docs.aws.amazon.com/msk/latest/developerguide/msk-default-configuration.html
[4] Spark Structured Streaming commit offset: https://github.com/HeartSaVioR/spark-sql-kafka-offset-committer
[5] Monitoring an Amazon MSK cluster: https://docs.aws.amazon.com/msk/latest/developerguide/monitoring.html
[6] Amazon MSK metrics for monitoring with CloudWatch:https://docs.aws.amazon.com/msk/latest/developerguide/metrics-details.html
[7] Kafka The Definitive Guide:https://learning.oreilly.com/library/view/kafka-the-definitive/9781491936153/
[8] MSK Best Practice:https://docs.aws.amazon.com/msk/latest/developerguide/bestpractices.html