我試圖扯掉這條 SQL 的底褲。
你好呀,我是歪歪。

這次帶大家盤一個我覺得有點意思的東西,也是之前寫《一個爛分頁,踩了三個坑!》這篇文章時,遇到的一個神奇的現象,但是當時忙著做文章搞定這個主線任務,就沒有去深究這個支線任務。
現在我們一起把這個支線任務盤一下。
啥支線任務?
之前不是寫分頁嘛,分頁肯定就要說到 limit 關鍵字嘛。
然後我啪的一下扔了一個連結出來:
https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html

這個連結就是 MySQL 官方檔案,這一章節叫做「對 Limit 查詢的優化」,針對 limit 和 order by 組合的場景進行了較為詳細的說明。
連結裡面有這樣的一個範例。
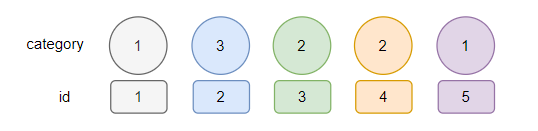
首先,針對一張叫做 ratings 的表給了一個不帶 limit 的查詢結果:
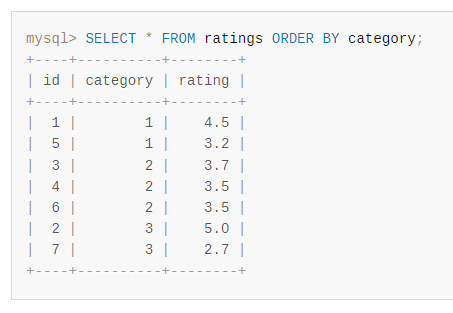
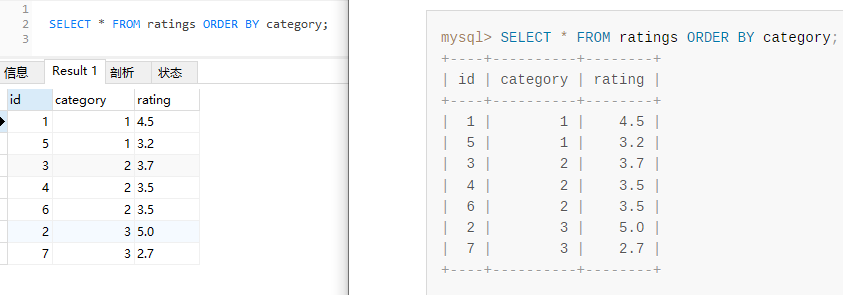
可以看到,一共有 7 條資料,確實按照 category 欄位進行了排序。
但是當我們帶著 limit 的時候,官方檔案上給出的查詢結果是這樣的:
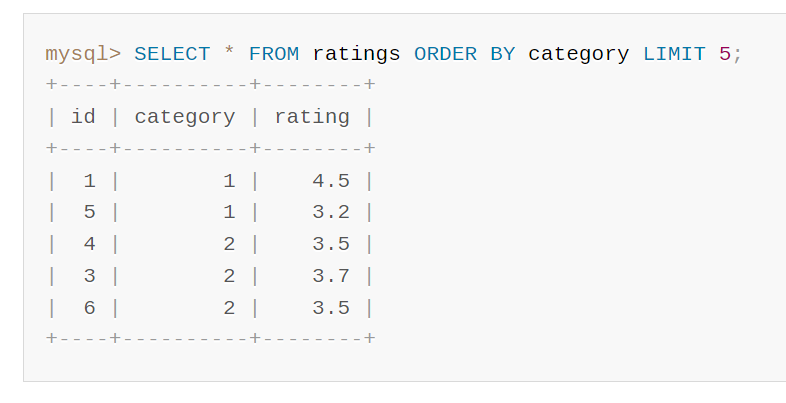
為了讓你更加直觀的看出差異,我把兩個結果給你放在一起:
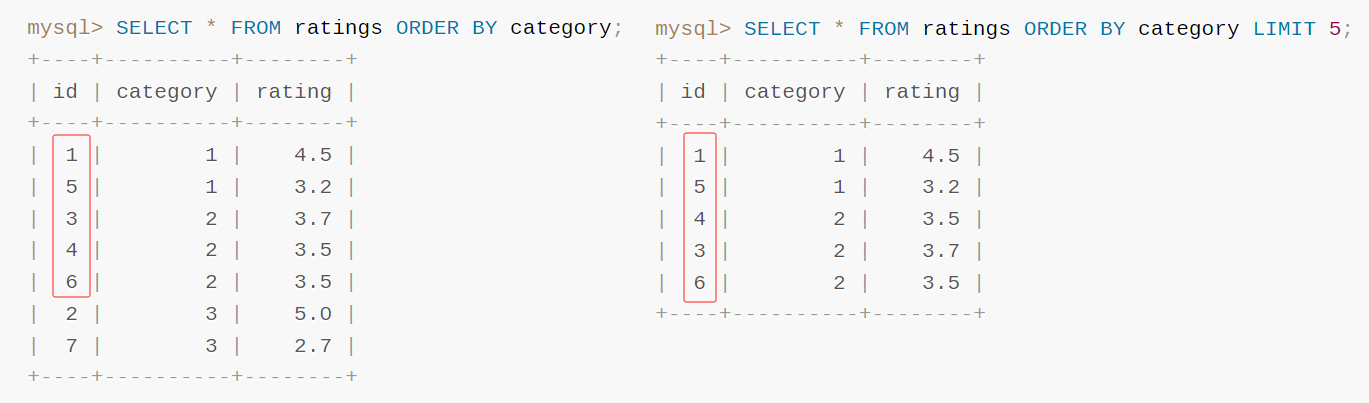
沒排序之前,前五條對應的 ID 是 1,5,3,4,6。
排序之後,前五條對應的 ID 是 1,5,4,3,6。
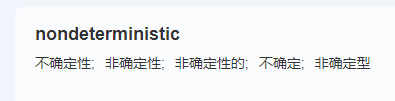
這就是官方的案例,非常直觀的體現了 order by 和 limit 一起使用時帶來的 nondeterministic。
這個單詞,我們前一篇文章中才學過,現在又可以溫習了一下了:
你知道的,歪師傅一向是比較嚴謹的,所以我也想著在本地復現一下官網的這個案例。

我原生的 MySQL 版本是 8.0.22,以下 SQL 均是基於這個版本執行的。
首先,按照官網上的欄位,先「咔」的一下整出表結構:
CREATE TABLE `ratings` (
`id` int NOT NULL AUTO_INCREMENT,
`category` int DEFAULT NULL,
`rating` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
然後「唰」的一下插入 7 條資料:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (1, 1, '4.5');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (2, 3, '5.0');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (3, 2, '3.7');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (4, 2, '3.5');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (5, 1, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (6, 2, '3.5');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (7, 3, '2.7');
接著「啪」的一聲執行一下不帶 limit 的 SQL,發現執行結果和官網一致:
SELECT * FROM ratings ORDER BY category;
然後「咻」的聲執行一下帶 limit 的 SQL:
SELECT * FROM ratings ORDER BY category LIMIT 5;
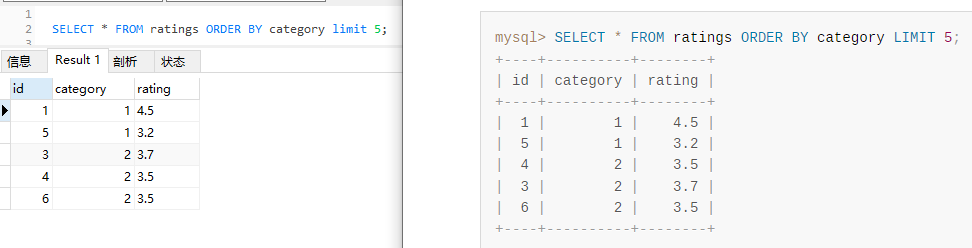
等等,執行結果不一樣了?
你把表結構拿過去,然後分別執行對應的 SQL,大概率你也會發現:怎麼和官網上的執行結果不一樣呢?

為什麼執行結果不一樣了呢?
這就是我當時遇到的支線任務。
大力出奇跡
當我遇到這個問題的時候,其實我非常自信。
我自信的知道,肯定是我錯了,官方檔案不可能有問題,只是它在展示這個案例的時候,隱去了一些資訊而已。
巧了,我也恰好知道怎麼去觸發 order by 和 limit 組合在一起時的「資料紊亂」的情況:當 order by 的欄位重複率特別高的時候,帶著 limit 查詢,就會出現官網中的現象。
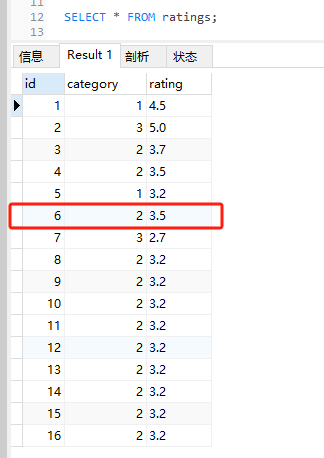
我直接先插入了 20 條這樣的資料:
(實際上我第一次執行的時候,插入了 100 條這樣的資料,所以,這一小結的名字叫做:大力出奇跡。)
這樣在表中就有大量的 category 為 2 的資料。
同樣的 SQL,執行結果就變成了這樣:
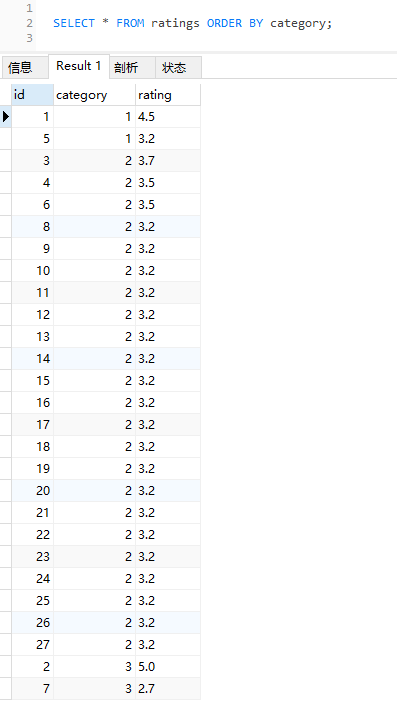
可以看到前五條資料的 ID 還是 1,5,3,4,6。
但是,當我執行這個 SQL 的時候,情況就不一樣了:
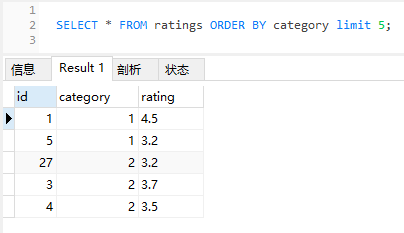
確實出現了官網中類似的情況,ID 為 27 的資料突然衝到了前面。
好,現在算是一定程度上覆現了官網上的案例。
你知道當我復現這個案例之後,隨之而來的另一個問題是什麼嗎?
那就是如果我開始的不插入 20 條 category 為 2 的資料,只是插入 10 條呢,或者是 5 條呢?
就是有沒有一個臨界值的存在,讓兩個 SQL 執行結果不一樣呢?
你猜怎麼著?
我以二分查詢大法為抓手,為執行結果賦能,沉澱出了一套尋找臨界值的打發,最終通過精準下鑽,找到了臨界值,就是 ID 為 16 的這條資料。

你先把這一批資料插入到表中:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (8, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (9, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (10, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (11, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (12, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (13, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (14, 2, '3.2');
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (15, 2, '3.2');
然後分別執行這兩個 SQL,執行結果是符合預期的:
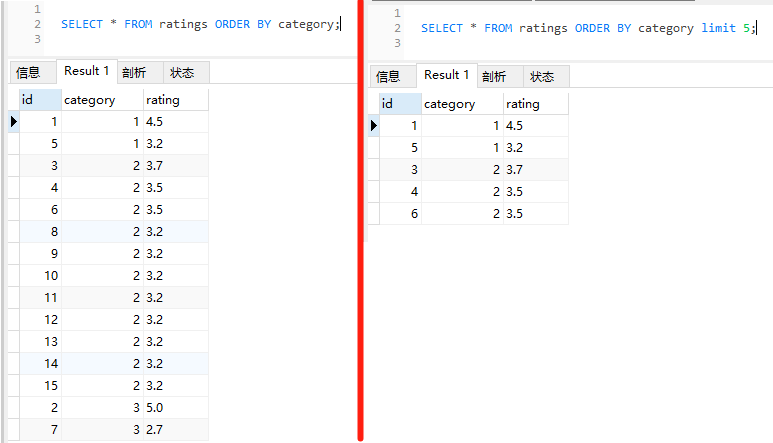
但是,一旦再插入這樣的一條資料:
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (16, 2, '3.2');
情況就不一樣了:
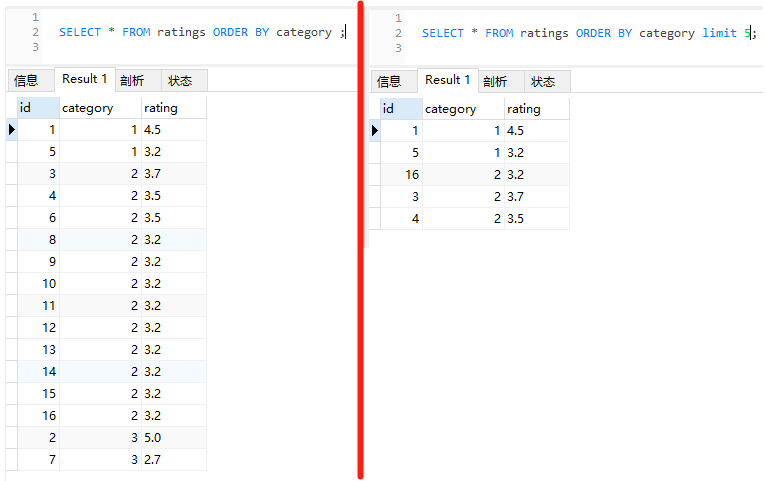
limit 語句查詢出來的 id 就是 1,5,16,3,4 了。
16 就冒出來了。
很好,越來越有意思了。

為什麼當表裡面有 15 條資料的執行結果和 16 條資料時不一樣呢?
我也不知道,所以我試圖從執行計劃中尋找答案。
但是,這兩種情況對應的執行計劃一模一樣:

為什麼會這樣呢?
因為官網上還有這樣一句話:

使用 EXPLAIN 不會區分優化器是否在記憶體中執行檔案排序。
但是在優化器的 optimizer trace 的輸出中的 filesort_priority_queue_optimization 欄位,可以看到記憶體中檔案排序的相關情況。
所以,這個時候得掏出另外一個武器了:optimizer_trace。
使用 optimizer_trace 可以跟蹤 SQL 語句的解析優化執行的全過程。
這兩張情況的執行結果不一樣,那麼它們的 optimizer_trace 結果也必然是不一樣的。
於是我分別在 15 條資料和 16 條資料的情況下執行了這樣的語句:
SET optimizer_trace='enabled=on';
SELECT * from ratings order by category limit 5;
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`;
SET optimizer_trace='enabled=off';

然後取出 optimizer_trace 結果中的 TRACE 資料,左邊是 15 條資料的情況,右邊是 16 條資料的情況:
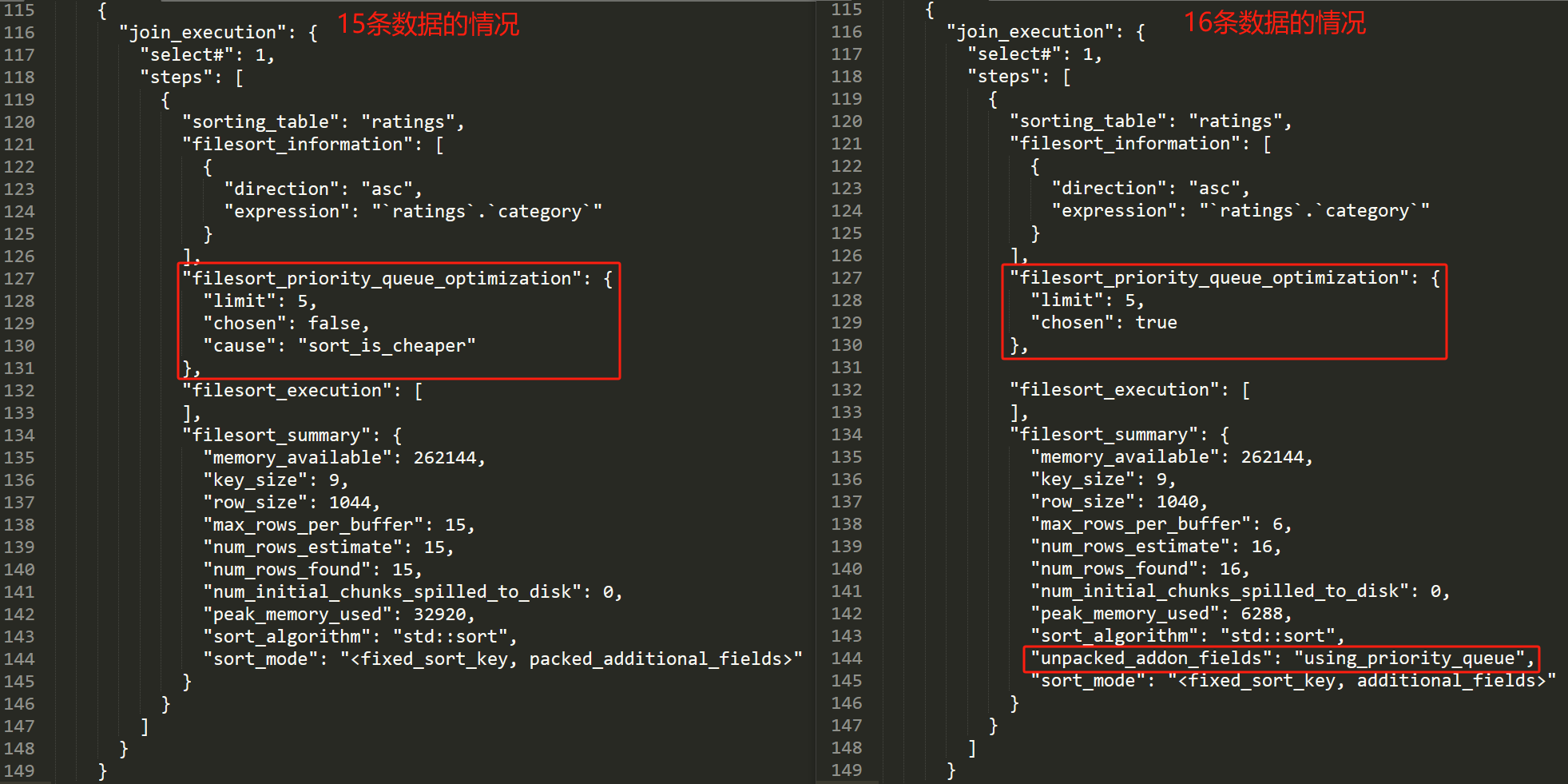
主要關注我框起來的部分,也就是前面提到的 filesort_priority_queue_optimization 欄位。
這個欄位主要是表明這個 SQL 是否使用優先順序佇列的方式進行排序。
在只有 15 條資料的情況下,它的 chosen 是 false,即不使用優先順序佇列。
"filesort_priority_queue_optimization": {
"limit": 5,
"chosen": false,
"cause": "sort_is_cheaper"
},
同時它也給了不使用的原因:sort_is_cheaper。
它認為直接進行排序的成本更低。
而我們也知道,大部分正常情況下 MySQL 就兩種排序方式。如果 sort_buffer_size 夠用,那麼就在記憶體中使用快速排序完成排序。
如果 sort_buffer_size 不夠用,那就藉助臨時檔案進行歸併排序。
但是你要注意,我前面說的是「大部分正常情況下」。
當我們程式中這種案例,order by + limit 的情況,MySQL 就掏出了優先順序佇列。
這個邏輯其實很簡單嘛,limit 語句,不就是找 TOP N 嗎?
那你說說,提到 TOP N 你是不是就能立馬聯想到優先順序佇列,想到堆排序?
翻出八股文一看:哦,原來堆排序不是穩定的排序演演算法。
那麼不穩定會帶來什麼問題呢?
我們先按下不表,插個眼在這裡,等會兒回收。

繼續回到 15 條資料和 16 條資料的情況,當時我找到這個臨界值之後,我就在想:為什麼臨界值在這個地方呢?
一定是有原因的,我想知道答案。
答案在哪裡?
我先在網上搜了一圈,發現可能是我衝浪的姿勢不對,一直沒找到能說服我的答案。
直到我有一天我乾飯的時候,腦海裡面突然蹦出了一句話:朋友,原始碼之下無祕密。
於是我桌子一掀,就起來了。
找原始碼
找原始碼這步,歪師傅就遭老罪了。
因為 MySQL 這玩意主要是用 C++ 寫的:
雖然我經常也在說語言是相通的,但是我也確實很久沒寫 C++ 了。
一路坎坎坷坷終於找到了這個地方:
https://github.com/mysql/mysql-server/blob/trunk/sql/filesort.cc
這個裡面有前面出現過的 sort_is_cheaper:
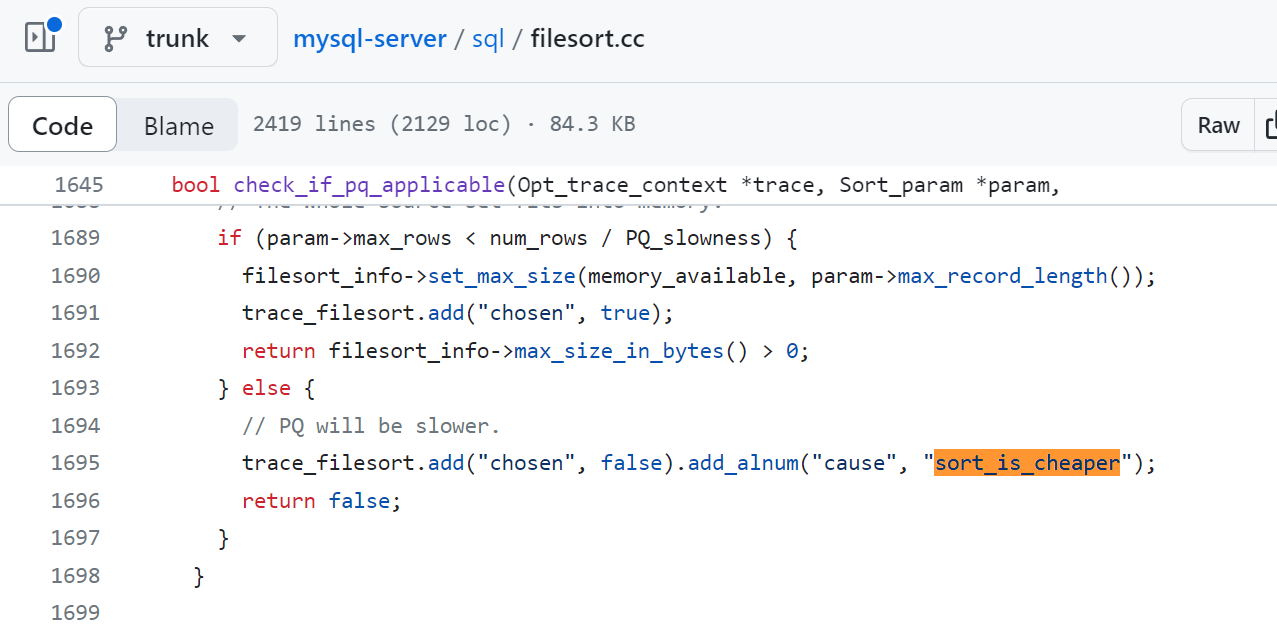
找到這裡,就算是找到突破口了,就開始無限的接近真相了。
在 filesort.cc 這個檔案裡面,有一個方法叫做 check_if_pq_applicable:
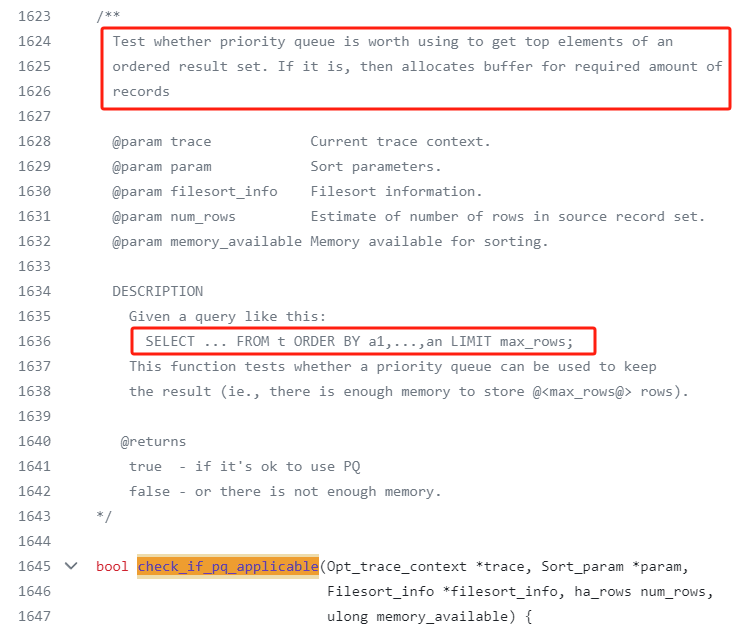
先關注一下這個方法上的描述:
Test whether priority queue is worth using to get top elements of an ordered result set.
翻譯過來大概是說,看看是否值得使用優先順序佇列去獲取有序結果級中的 Top 元素。
也就是這個方法主要就是評判「是否值得」這件事的。
如果值得呢?
If it is, then allocates buffer for required amount of records
如果值得,就為所需數量的記錄分配對應的快取區。
同時在描述部分還給出了一個對應的 SQL:
SELECT ... FROM t ORDER BY a1,...,an LIMIT max_rows;
這 SQL 樣例不就是對應我們前面研究的 SQL 嗎。
所以這裡面一定能解決我的問題:
為什麼臨界值在 16 條資料這個地方呢?
瞟一眼原始碼,可以發現它大概是分為了 6 大坨判斷:
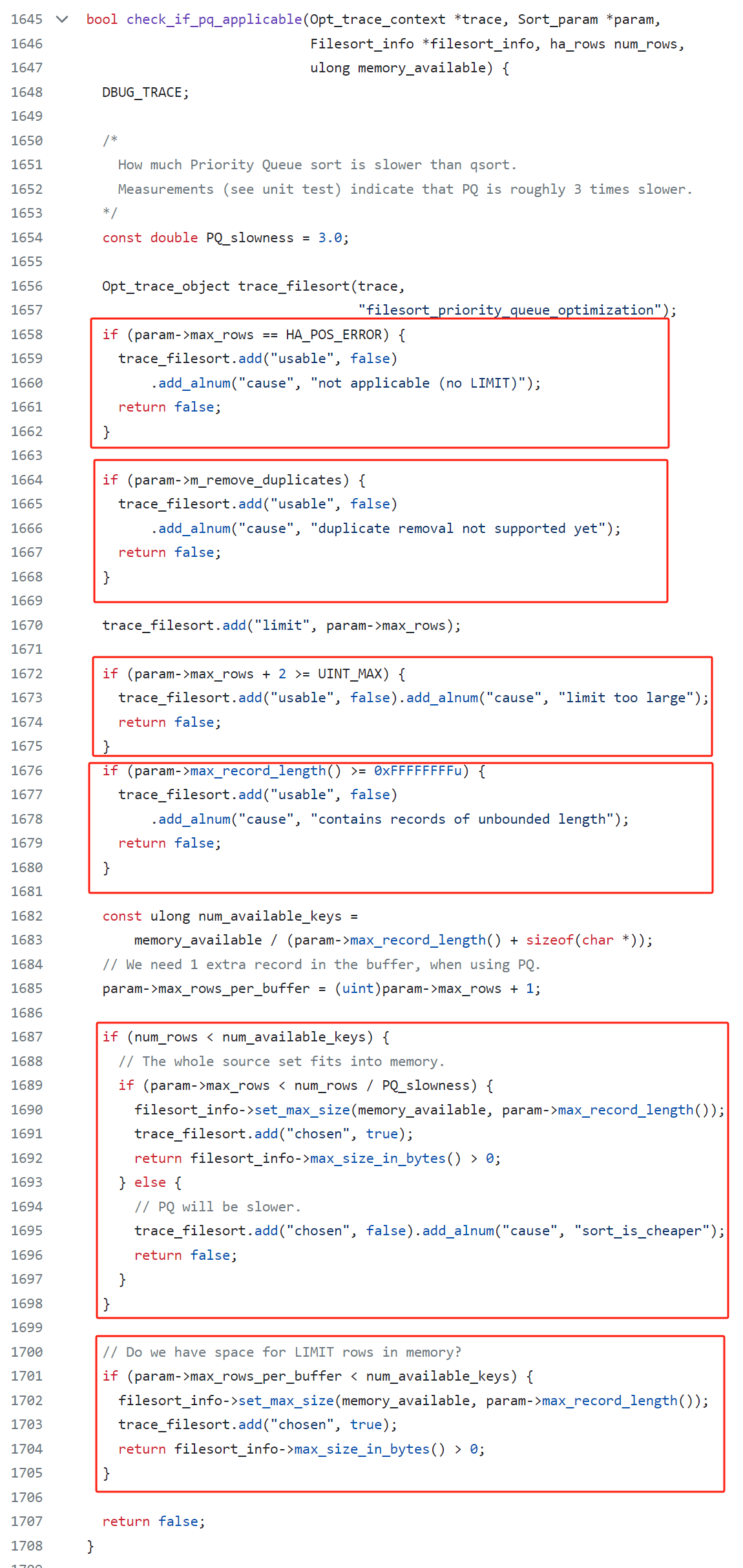
首先第一坨:

很明顯,判斷了 SQL 中是否有 limit 關鍵詞。
如果 limit 都沒有,那肯定不能用優先順序佇列了。
這一點,我們也可以通過 optimizer_trace 中的結果來驗證:
這個 SQL 對應的結果是這樣的:
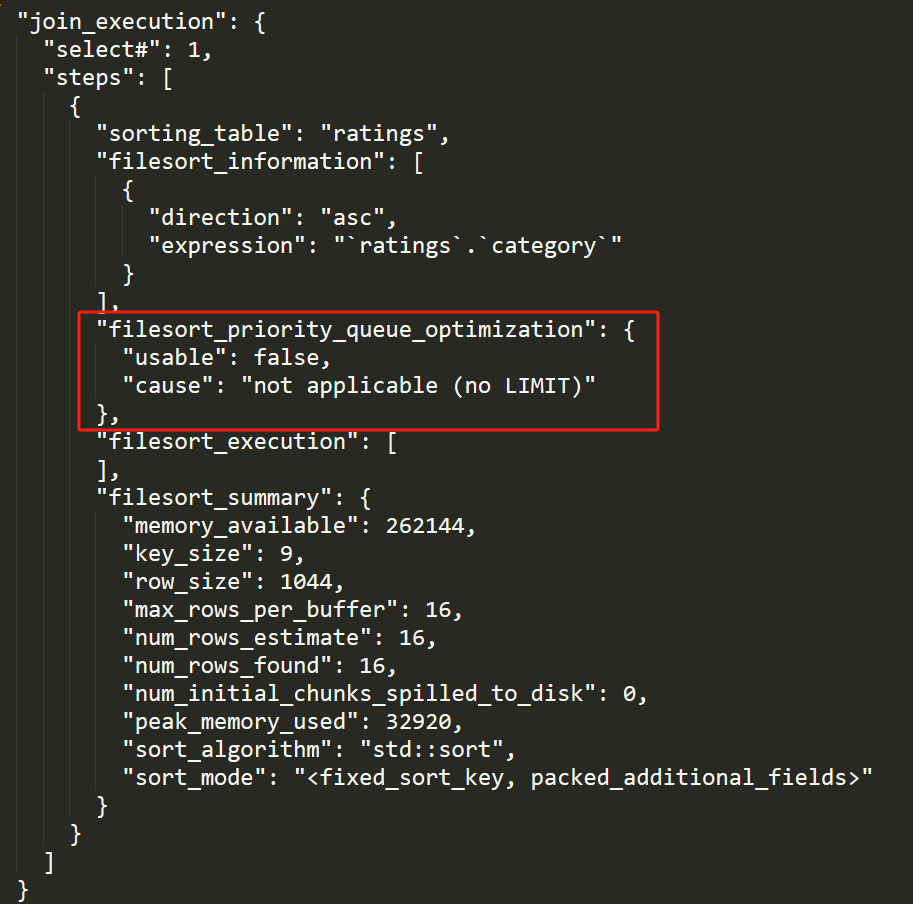
這不就和原始碼中的 「not applicable (no LIMIT)」 呼應上了嗎?
然後看第二坨 if 判斷:

如果 SQL 裡面有去重的操作,則不支援。
第三坨和第四坨:

分別是說,limit 的值需要小於 UINT_MAX - 2,以及記錄的最大長度需要小於 0xFFFFFFFF,不能太長。
UINT_MAX - 2 指的是 priority queue 的最大容量。
然後我們先看最後一坨 if 判斷:

也很好理解,要看看針對 limit 這部分的資料,記憶體夠不夠,放不放的下。放得下才能使用優先順序佇列。
主要看這坨:
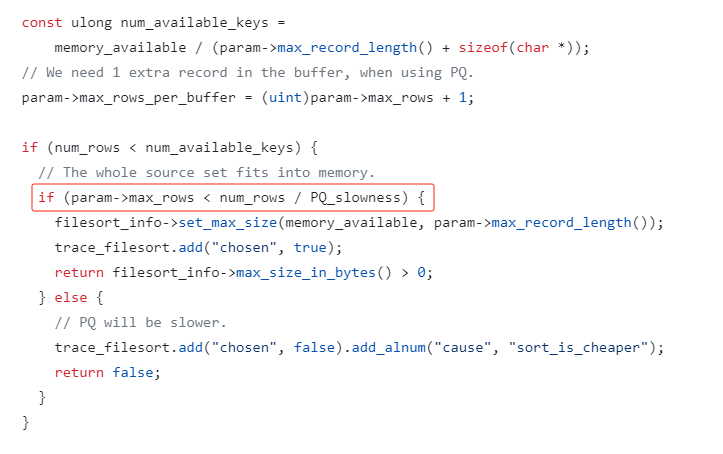
看這個判斷條件:
if (param->max_rows < num_rows / PQ_slowness)
如果滿足,就使用優先順序佇列。
如果不滿足,就 「sort_is_cheaper」。
其中 max_rows 就是 limit 的條數,num_rows 就是資料庫裡面符合條件的總條數。
PQ_slowness 是什麼玩意?
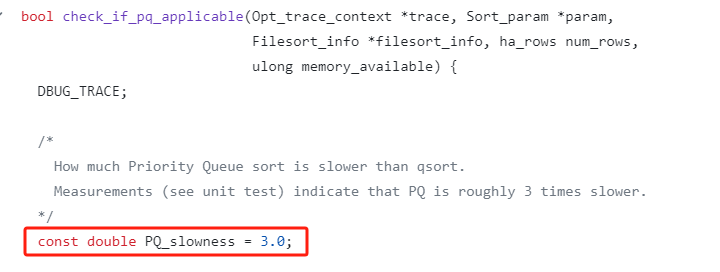
PQ_slowness 是一個常數,值為 3。
從這個值的描述上看,MySQL 官方認為快速排序的速度是堆排序的 3 倍,這個值也不是拍腦袋拍出來,是通過測試跑出來。
知道了每個欄位的含義,那麼這個表示式什麼時候為 true 就很清晰了。
if (param->max_rows < num_rows / PQ_slowness)
已知,PQ_slowness=3,max_rows=5。
那麼當 num_rows <=15 時,表示式為 false。num_rows>16 時,表示式為 true。
為 true ,則使用優先順序佇列進行排序。
臨界值就是這樣來的。
所以,那句話是怎麼說的來著?
原始碼之下,無祕密。

再回首
前面盤完了 optimizer_trace 中的 filesort_priority_queue_optimization 欄位。
接著再回首,看看結果檔案中的這個 sort_mode 玩意。
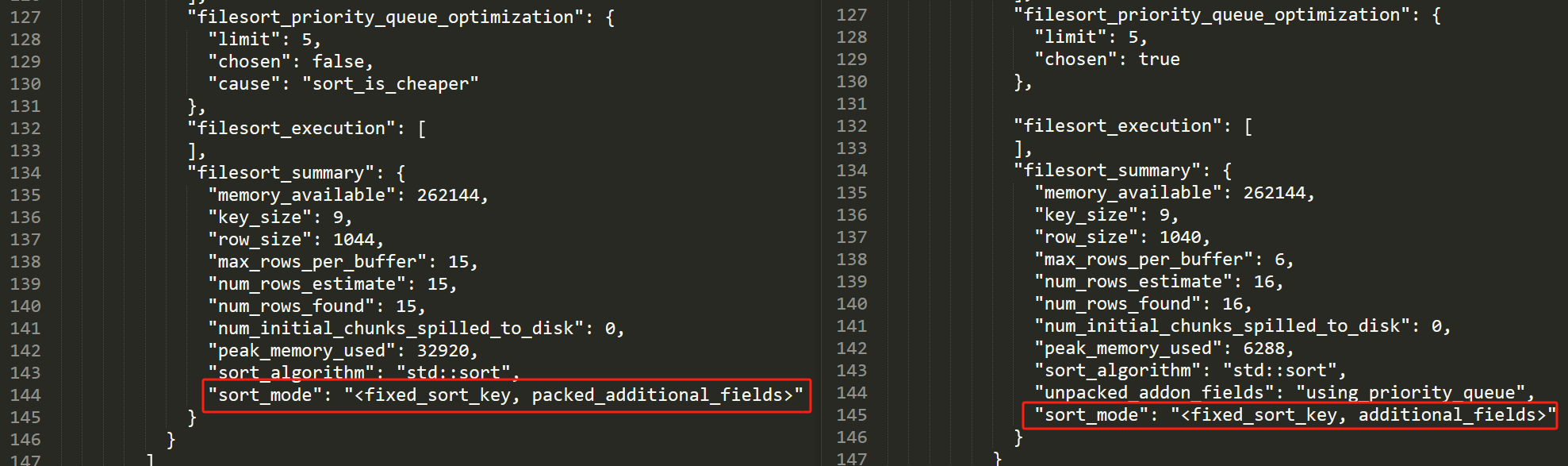
關於 sort_mode 官網上也有專門的介紹:
https://dev.mysql.com/doc/refman/8.0/en/order-by-optimization.html

sort_mode 一共有三種模式。
第一種,<sort_key, rowid> 模式。
This indicates that sort buffer tuples are pairs that contain the sort key value and row ID of the original table row. Tuples are sorted by sort key value and the row ID is used to read the row from the table.
這種模式的工作邏輯就是把需要排序的欄位按照 order by 在 sort buff 裡面排好序。
sort buff 裡面放的是排序欄位和這個欄位對應的 ID。排序欄位和 ID 是以鍵值對的形式存在的。
如果 sort buff 不夠放,那就讓臨時檔案幫幫忙。
反正最後把所有資料都過一遍,完成排序任務。接著再拿著 ID 進行回表操作,取出完整的資料,寫進結果檔案。
第二種,<sort_key, additional_fields> 模式:
This indicates that sort buffer tuples contain the sort key value and columns referenced by the query. Tuples are sorted by sort key value and column values are read directly from the tuple.
這種模式和回表不一樣,就是直接一梭子把整個使用者需要查詢的欄位放在存入 sort buffer 中。
當然,還是會先按照排序的欄位 order by ,在 sort buff 裡面排好序。
這樣全部資料讀取完畢之後,就不需要回表了,可以直接往結果檔案裡面寫。
其實我理解,第一種和第二種就是是否回表的區別。第二種模式應該是第一種模式的迭代優化。
因為不管怎麼樣,用第一種模式都能完成排序並獲取資料任務。
至於怎麼決策使用哪種方案,MySQL 內部肯定也是有一套自己的邏輯。
第三種模式是 <sort_key, packed_additional_fields>:
Like the previous variant, but the additional columns are packed tightly together instead of using a fixed-length encoding.
這種模式是第二種模式的優化。描述中說用 packed tightly together 代替了 fixed-length encoding。
啥意思呢?
比如我們的表結構中 rating 欄位的型別是 varchar(255):
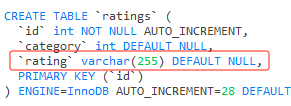
如果我只是在裡面儲存一個 why,那麼它的實際長度應該是 「why」 這 3 個字元的記憶體空間,加 2 個位元組的欄位長度,而不是真正的 255 這麼長。
這就是 「packed tightly together」,欄位緊密的排列在一起,不浪費空間。
sort buffer 就這麼點大,肯定不能太浪費了。
我之前確實不知道這個東西,所以趁這次查漏補缺了一下,屬於又拿捏了一個小細節。

堆排序
既然都提到堆排序了,那我們就按照堆排序的邏輯盤一盤資料庫裡面的資料。
目前資料庫裡面全部的資料是這樣的:
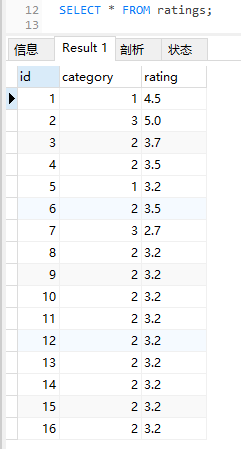
因為是 limit 5,所以先把前五條拿出來:
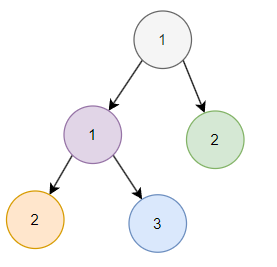
我們先按照 category 構建小頂堆,只是用不同的顏色來表示不同的 ID。
那麼前五條資料構建出來的小頂堆是這樣的:
接著,下一條資料是 id 為 6,category 為 2 的資料:
把這條資料放到小頂堆之後變成了這樣:

再下一條資料為 id 為 7,category 為 3 的資料。
由於 3 大於 2,所以不滿足放入小頂堆的條件。
再下一條資料為 id 為 8,category 為 2 的資料,所以會把小頂堆變成這樣:
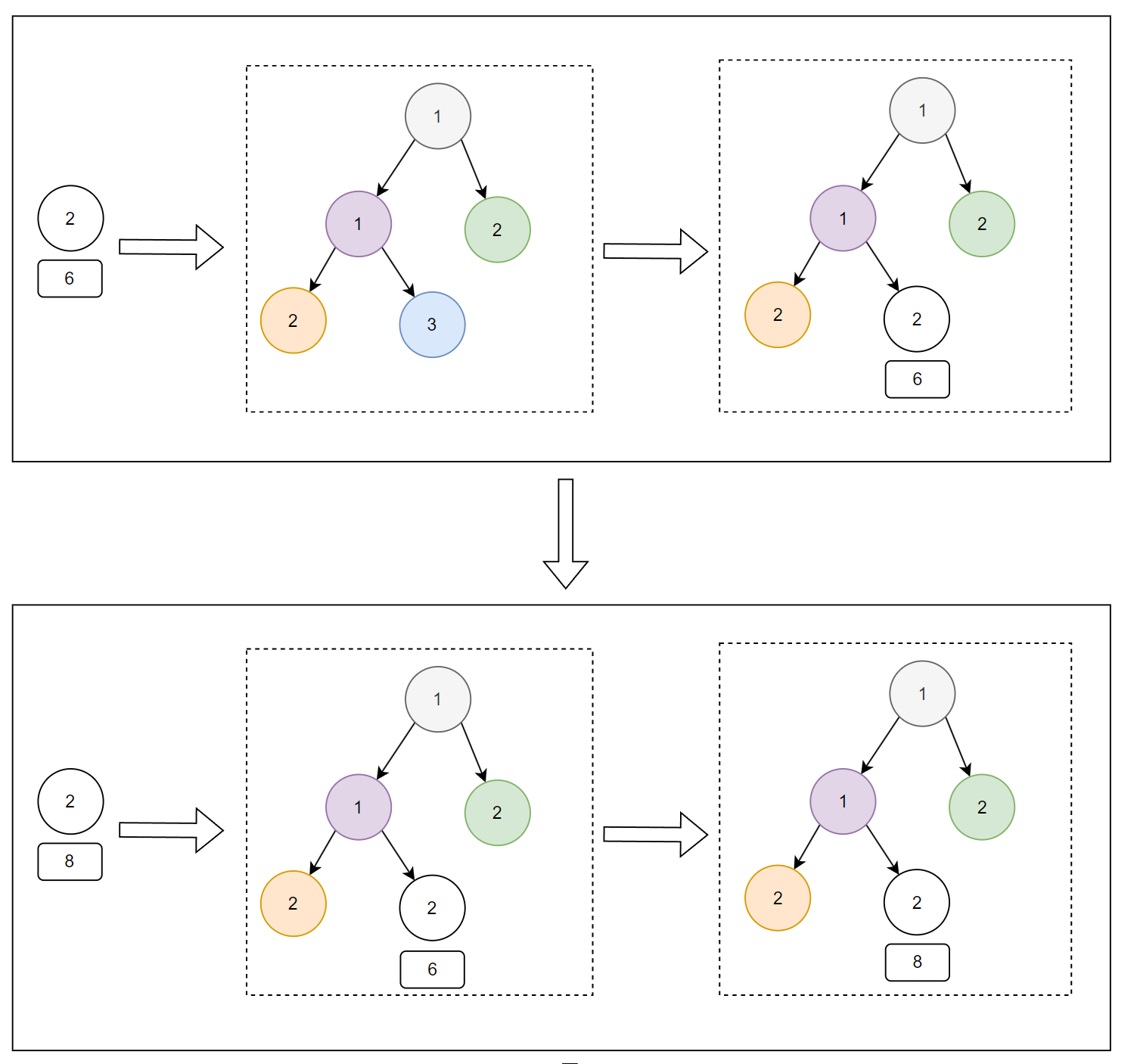 再來 id 為 9,category 為 2 的資料,小頂堆會變成這樣:
再來 id 為 9,category 為 2 的資料,小頂堆會變成這樣:
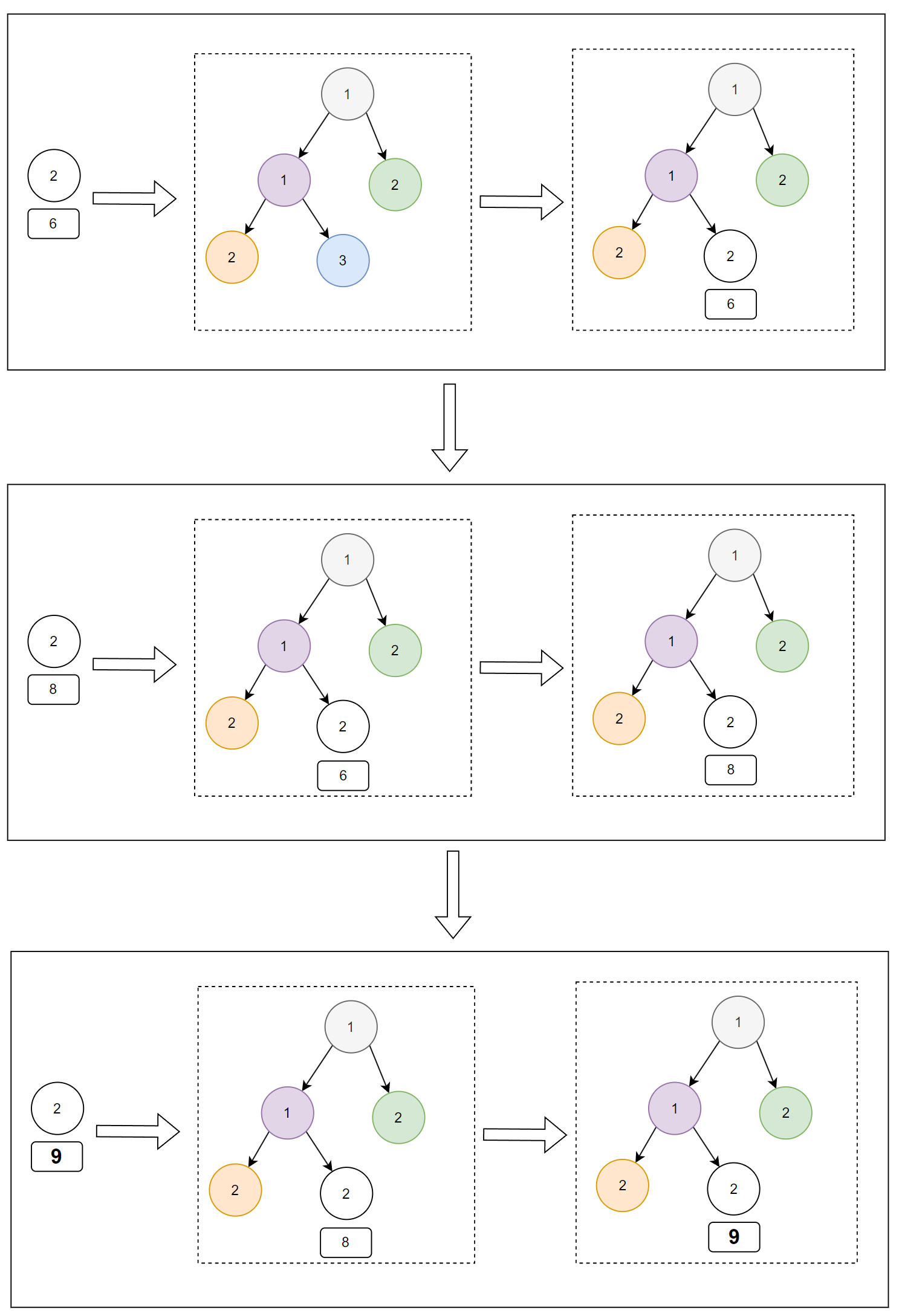
以此類推,最後一條處理完成之後,小頂堆裡面的資料是這樣的:
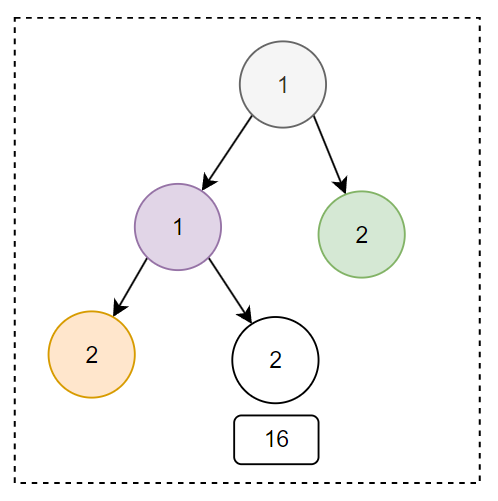
然後,我們將上述小頂堆,進行出堆操作。
翻開八股文一看,哦,原來出堆無外乎就三個動作:
堆頂元素出堆 最後一個元素放入堆頂 調整堆
所以第一個出堆的節點是這樣:
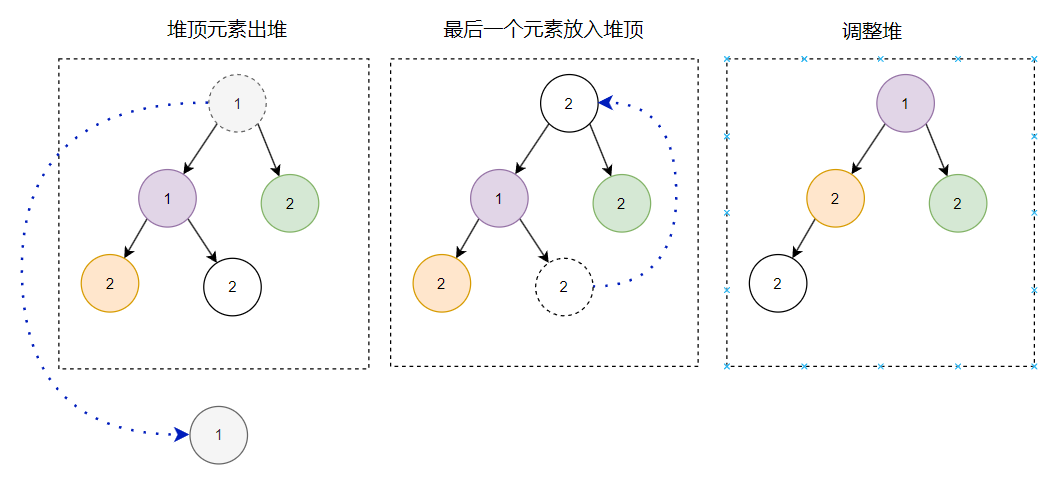
第二個出堆的節點是這樣的:
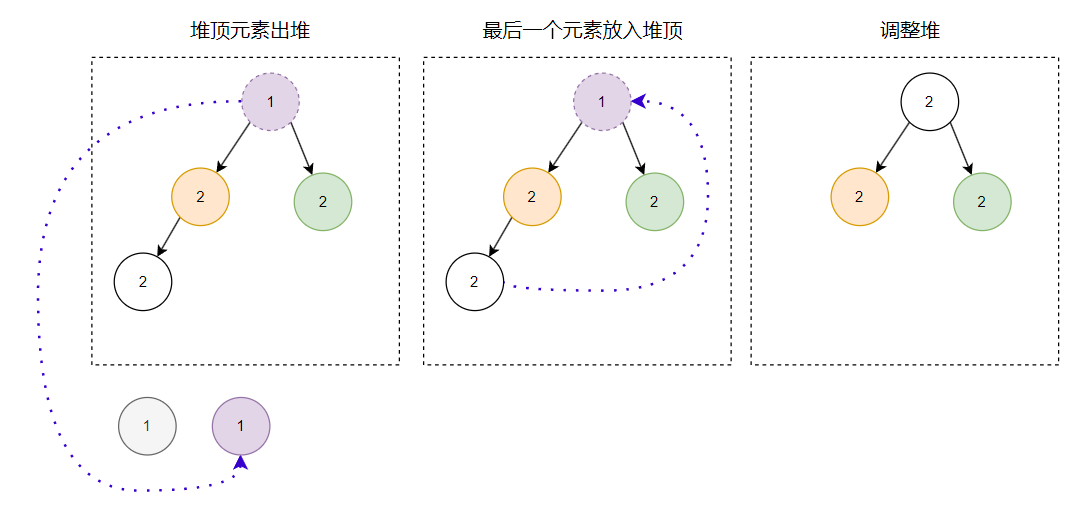
第三個出堆的節點是這樣的:
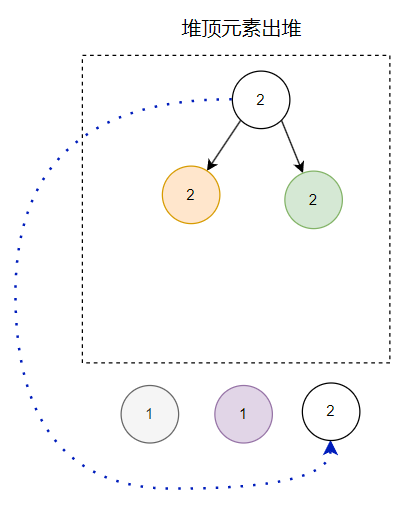
那麼最終的出堆順序就是這樣的:

接下來,別忘了,我們的顏色是有含義的,代表的是 ID,我們在看看最開始的五條資料:
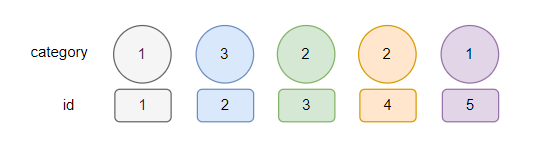
所以,我們按照顏色把出堆順序補上 ID:
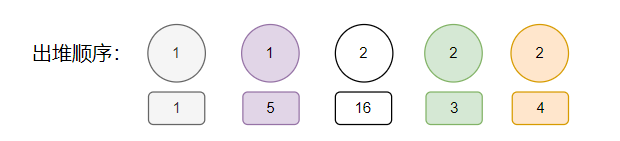
1,5,16,3,4。
朋友們,這串數位是否有點眼熟?
是否在午夜夢迴的時候夢到過一段?
再給你看一個神奇的東西:
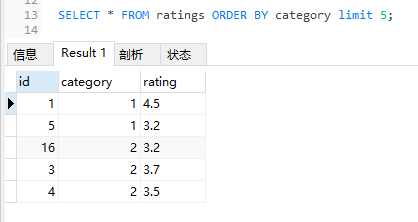
你看看這個 limit 5 取出來的 id 是什麼?
1,5,16,3,4。

這玩意就這樣呼應上了,掌聲可以響起來了,今晚高低得用這串數位搞個彩票。
然後,再提醒一下,我們都知道堆排序是一個不穩定的排序演演算法。
它的不穩定體現在哪裡?
翻開八股文一看,哦,原來是「位置變了」。
就拿我們的這個例子來說,排序之前,3 和 4 這兩條資料在 16 之前:
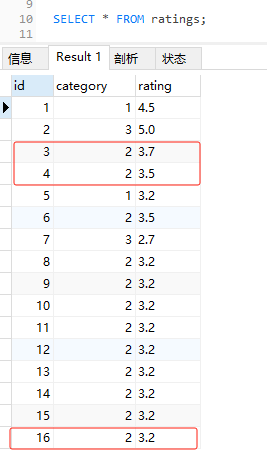
排完序之後,16 這條資料跑到 3 前面去了。
雖然他們對應的 category 值都是 2,但是相對位置發生了變化,這就是不穩定的表現。
好了,現在我再問你一個問題,當我再插入一條資料
INSERT INTO `ratings`(`id`, `category`, `rating`) VALUES (17, 2, '3.2');
你說取前五條,執行結果是什麼?
肯定是 1,5,17,3,4。
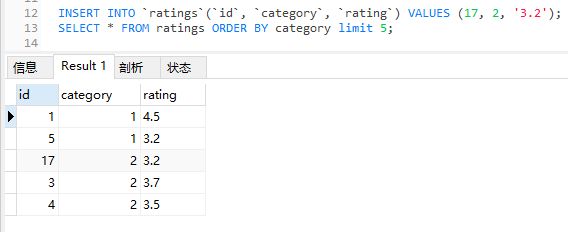
哪怕我插入個 10000,執行結果我也猜得出來,肯定是 1,5,10000,3,4。

但是你說,我要是再插入個 10w 條 category=2 的資料呢?
這玩意我就沒實驗了,但是我猜,可能不會啟用優先順序佇列,也就是不會走這一套邏輯。
為什麼,你問為什麼?
要不你再想想使用優先順序佇列的那幾坨 if 判斷?
最後說一句
好了,寫到這裡文章也就進入尾聲了,到了我拿手的上價值環節了。
你現在回過頭想想,其實這篇文章真的沒有教會你什麼特別有價值的東西。如果讓我來總結這篇文章,我只會取走文章開頭的這個連結:
https://dev.mysql.com/doc/refman/8.0/en/limit-optimization.html
這是官方檔案,當你開啟這個連結之後,我不相信你不會被側邊欄中的 Optimization 這個單詞給吸引住,然後仔細一看,這一章節下有這麼多的 xxx Optimization,我不信你沒有點開看一眼的慾望:
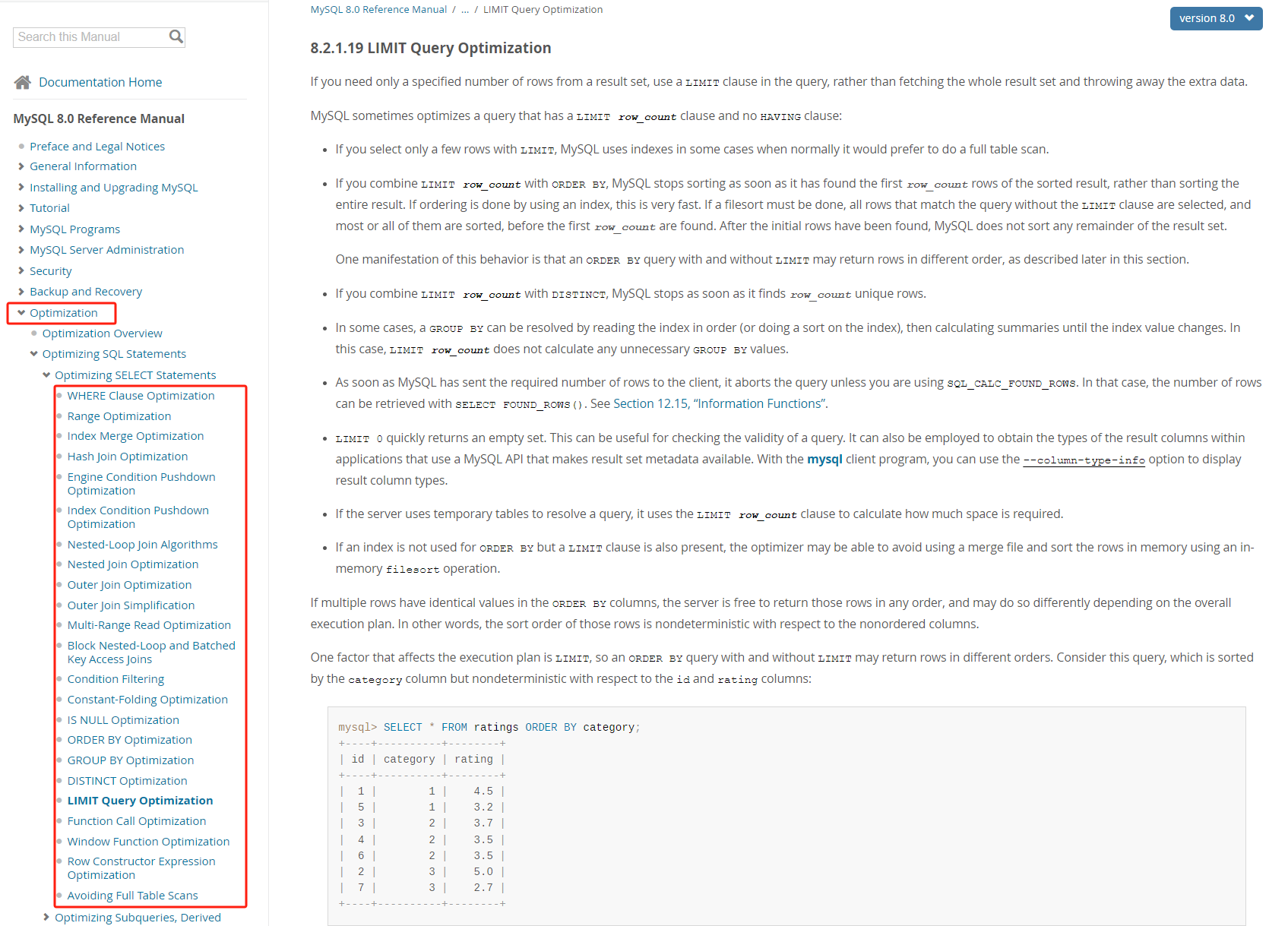
如果你沒有這一眼慾望,你抵抗的一定不是技術,因為如果你抵抗技術,你根本就不會開啟這個連結。
如果你沒有這一眼慾望,說明你抵抗的是純英文。但是我的朋友,要克服好嗎。一點點啃,這才是一手資料的地方,而我不過是一個拙劣的倒賣一手資料的二手販子而已。
你在看的過程中,除了英文的問題外,肯定有很多其他的問題。這個時候你帶著問題去搜尋答案,收穫將會是巨大的。
這就是我們常常說的:從官方檔案開始學。
我這篇文章的起點,就是官方檔案,然後從檔案發散,我看了很多其他的文章。
如果有一天你看官方檔案的時候,看到 limit ptimization 這一章節的時候,有看不懂的地方,然後帶著問題在網上搜到了我這篇文章。
朋友,這就很爽了。
這是你的收穫,是我的榮幸。
好了,上完價值,打完收工。
