為.NET開啟新大門:OpenVINO.NET開源專案全新發布
為.NET開啟新大門:OpenVINO.NET開源專案全新發布
在AI的應用越來越廣泛的今天,優化深度學習模型並進行推理部署已經成為了一門必要的技術。Intel開發的OpenVINO工具包(Open Visual Inference and Neural network Optimization)就是這樣一款強大的工具。作為一個開源的工具包,OpenVINO為開發者提供了強大的深度學習模型優化和推理功能,支援跨不同的Intel硬體平臺進行部署,包括CPU, 整合GPU, Intel Movidius VPU, 和FPGAs。該工具包的初衷就是實現一處編碼後,能在任何地方部署的機器學習推理的解決方案。
然而在與深度學習模型推理打交道的過程中,我逐漸發現原本我基於百度飛槳paddlepaddle開發過的PaddleSharp專案在CPU推理OCR效能方面,同樣的模型,OpenVINO的效能更勝一籌。於是我開始關注OpenVINO,發現它的C API對於.NET世界來說並沒有一個合適且高質量的封裝。市面上的一部分封裝可能只是為了滿足特定專案的需求,功能不夠完善;有些雖然功能完善但命名規範可能不符合.NET社群規範;有些在錯誤處理和效能方面存在問題,或者無法做到跨平臺,這與OpenVINO的跨平臺性矛盾。.NET世界亟需一個更高質量的OpenVINO封裝,而我感覺我有能力去努努力。因此,我在今年的節前立下了flag——國慶期間大幹一票,開始了OpenVINO.NET的開源之旅。
如何使用
NuGet包簡介
使用OpenVINO.NET,最簡單的方法不是克隆我的Github庫(但歡迎star),而是使用我釋出的NuGet包,一般它需要配合OpenCVSharp4一起使用,因此你通常可以安裝下面4個NuGet:
- Sdcb.OpenVINO
- Sdcb.OpenVINO.runtime.win-x64
- OpenCvSharp4
- OpenCvSharp4.runtime.win
和OpenCvSharp4一樣,我釋出的包也包含.NET PInvoke包和平臺動態連結庫包,如上Sdcb.OpenVINO為.NET PInvoke包,Sdcb.OpenVINO.runtime.win-x64為相容Windows平臺的動態連結庫包,裡面包含了一些dll。
如果是基於Linux,我專門釋出了一個映象用於減輕部署壓力:sdflysha/openvino-base,這個映象基於.NET 7 SDK的Ubuntu 22.04版本,包含了OpenCvSharp 4.8的執行時和所有OpenVINO的執行時依賴,要使用這個映象,需將.NET專案第一行的FROM mcr.microsoft.com/dotnet/runtime改為FROM sdflysha/openvino-base,使用時當然也需要安裝ubuntu 22.04平臺的動態連結庫包:Sdcb.OpenVINO.runtime.ubuntu.22.04-x64。
實際上我釋出了8種不同平臺的NuGet包,這是所有我此專案新發布的NuGet包列表:
| 包名 | 版本號 | 簡介 |
|---|---|---|
| Sdcb.OpenVINO |  |
.NET PInvoke |
| Sdcb.OpenVINO.runtime.centos.7-x64 |  |
CentOS 7 x64 |
| Sdcb.OpenVINO.runtime.debian.9-arm |  |
Debian 9 ARM |
| Sdcb.OpenVINO.runtime.debian.9-arm64 |  |
Debian 9 ARM64 |
| Sdcb.OpenVINO.runtime.rhel.8-x64 |  |
RHEL 8 x64 |
| Sdcb.OpenVINO.runtime.ubuntu.18.04-x64 |  |
Ubuntu 18.04 x64 |
| Sdcb.OpenVINO.runtime.ubuntu.20.04-x64 |  |
Ubuntu 20.04 x64 |
| Sdcb.OpenVINO.runtime.ubuntu.22.04-x64 |  |
Ubuntu 22.04 x64 |
| Sdcb.OpenVINO.runtime.win-x64 |  |
Windows x64 |
有興趣的朋友一定會想,釋出並維護這麼多包做起來一定很麻煩。其實還好,感謝我此前PaddleSharp專案的經驗(那個專案也維護了一螢幕的包),我基於官網的filetree.json做了一些解析,它可以一鍵自動下載並生成上面這些NuGet包,有興趣的朋友可以看看我Github中Sdcb.OpenVINO.NuGetBuilder這個專案瞭解我是如何解析並自動建立NuGet包的。
API設計
和我此前做過的PaddleSharp, Sdcb.LibRaw, Sdcb.Arithmetic, Sdcb.FFmpeg等開源專案相似,我這個專案也秉持下面這些原則:
- 完全支援低階C API,也就是說如果你更享受原汁原味的C API的感覺——或者像我一樣不想失去對低層的掌控,使用OpenVINO.NET可以滿足這一期望;
- 同時也為所有的低階API提供了便利好用的高層API;
- 高層API符合
C#的命名規範,完全利用了C#的優秀特性,做好了異常錯誤處理; - 高層API使用了
C#世界有利於效能優化的特性,如ReadOnlySpan<T>,比如恰當使用值型別; - 所有的高層API都提供了完善了XML註釋,並經過了詳盡的單元測試;
- 此外我還控制了我攜帶的「私貨」——沒必要做成公有的API一律做成
internal或private,且不汙染常用型別的擴充套件方法
目前這個專案已經基本穩定,基於這些API,我測試發現它和C/C++推理效能幾乎並無差異,PaddleOCR推理時,效能可以比PaddleSharp專案快得多,且得益於C#的優秀語言特性,使用起來會非常的省心。
設計FAQ:
- Q: 為何
OpenVINO.NET沒有直接參照OpenCvSharp4?- A: 我個人很喜歡
OpenCvSharp4,開源協定很友好,但一來OpenCvSharp4官方支援的平臺不夠多,且有些人可能更喜歡Emgu.CV或ImageSharp,儘量不做綁架為好
- A: 我個人很喜歡
- Q: C API有158個函數介面、26個介面體,也寫了詳盡的
XML註釋,是怎麼在短時間內高質量地做到的?- A: 我是自動生成的,我使用了CppSharp專案,CppSharp將C API的標頭檔案內容轉換為抽象語法樹(AST),然後我將這些AST轉換為XML註釋詳盡的
C#程式碼。其實我已經不是第一次將CppSharp應用到開源專案中,有興趣的朋友可以看我Github Sdcb.OpenVINO.AutoGen這個專案瞭解實現的細節。
- A: 我是自動生成的,我使用了CppSharp專案,CppSharp將C API的標頭檔案內容轉換為抽象語法樹(AST),然後我將這些AST轉換為XML註釋詳盡的
為想了解如何使用的朋友,我還寫了基於yolov8的檢測和分類的推理範例,OpenVINO官方的人臉檢測範例以及我為它原生設計和遷移的PaddleOCR專案。另外我還想暢談一下專案的設計思路和未來的發展方向。
4個範例
人臉檢測 - 基於OpenVINO官網提供的face-detection-0200模型
我這個範例中使用的是OpenVINO官網提供的face-detection-0200模型,官網提供了介紹頁面:https://docs.openvino.ai/2023.1/omz_models_model_face_detection_0200.html。
詳盡的範例程式碼可以從我建立的mini-openvino-facedetection這個Github倉庫找到,執行時,它會將攝像頭中定位人臉位置並框出來,效果圖如下:

如圖,臉部辨識效果正常,上面也標註了每幀推理耗時(約2.14ms)。
我使用的是AMD R7 5800X進行的CPU推理,其實程式碼也支援Intel的GPU。將DeviceOptions的第一個引數從"CPU"(預設值)改為"GPU"即可,但我只有整合顯示卡,測試發現雖然能正常工作,且CPU使用率降低了且GPU使用率上升了,但GPU推理時間比CPU還更慢。
物體識別 - 基於yolov8模型的物體分類
在上一個例子中,我們已經看到了如何使用OpenVINO.NET進行人臉檢測。接下來,我們再來看一下如何使用物體識別模型進行物體分類。
這個範例使用的是yolov8官網下載的YOLOv8n模型,這個模型支援80種物體的檢測。下載後格式為.pt檔案,表示pytorch模型,需使用yolo export model=yolov8n.pt format=openvino命令(yolo通過pip安裝ultralytics包得到)將其匯出為openvino格式的模型,openvino模型包含一個xml和一個bin檔案。
詳盡的範例程式碼可以從我建立的另一個倉庫:sdcb-openvino-yolov8-det中找到,倉庫我我已經將模型轉換好了。執行時,程式碼會讀取攝像頭的每一幀,並將檢測到的物體位置框出來,效果圖如下:
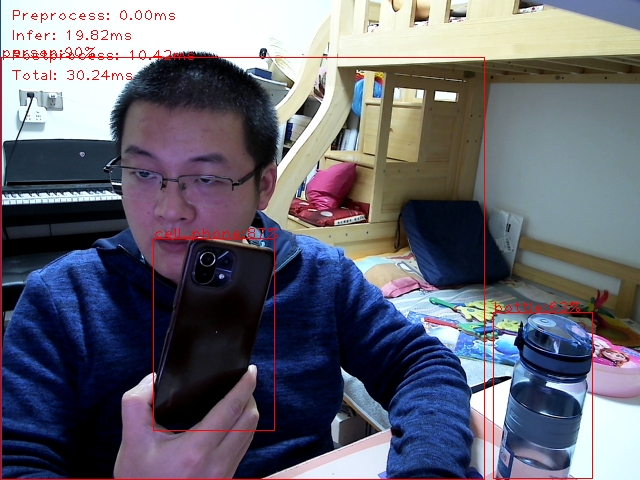
如圖,檢測出了3個物體,畫面中的人、手機和水杯,總耗時約30ms。
物體分類 - 基於yolov8的分類模型
yolov8模型提供了1000種不同的預定義分類,和上面的模型一樣,需要從yolov8官網下載並轉換,只想快速嚐鮮的朋友可以直接開啟我寫的另一個Github範例:sdcb-openvino-yolov8-cls
執行時,程式碼會讀取一張圖片,然後嘗試推測出該圖片最像1000種分類中的哪一種,在我的程式碼範例中,輸入圖片為hen.jpg:

輸出如下:
class id=hen, score=0.59
preprocess time: 0.00ms
infer time: 1.65ms
postprocess time: 0.49ms
Total time: 2.14ms
推理得到最有可能的分類是hen(母雞),信心值為0.59,總耗時2.14ms。
PaddleOCR - 混合3種模型
PaddleOCR是百度飛槳釋出了一款效能、精度都較好的開源模型。
和PaddleSharp專案一樣,我給OpenVINO.NET專案也內建了PaddleOCR的便利化專案,且API設計和PaddleSharp幾乎完全一樣,熟悉PaddleSharp的朋友應該可以很輕鬆地遷移到OpenVINO.NET,我專門為PaddleOCR提供釋出了下面2個NuGet包:
| 包名 | 版本號
|
|---|