postman匯入請求到jmeter進行簡單壓測,開發同學一學就會
背景
這個事情也是最近做的,因為線上nginx被我換成了openresty,然後接入層服務也做了較大改動,雖然我們這個app(內部辦公類)並行不算高,但好歹還是壓測一下,上線時心裡也穩一點。
於是用jmeter簡單壓測下看看,這裡記錄一下。
這次也就找了幾個介面來壓:登入介面、登入後獲取使用者資訊介面、登入後寫資料的一個介面。
因為這幾個介面,在postman裡面有,我就懶得手工錄入到jmeter了(那種form表單,懶得一個一個弄),唯一需要解決的就是,能不能把postman裡面的請求匯出,然後匯入到jmeter裡面。
postman請求匯入jmeter
postman匯出
簡單提一句,如果請求在postman裡沒有,也可以用抓包方式(charles、fiddler),在charles裡將請求匯出為curl格式,然後匯入到postman裡面。
postman匯入jmeter的方式也比較簡單,網上有人寫了個開源庫來做這個事情。
先匯出:
最終會得到一個json檔案。
轉換json檔案為jmeter的jmx
使用了開源庫,也是java寫的:
https://github.com/Loadium/postman2jmx
我用的時候,因為我postman裡面有個請求有點問題,導致報了空指標,然後自己debug了下,解決了,所以大家可以拉我的倉庫也行:
https://github.com/cctvckl/postman2jmx
我也順便給原倉庫提了個pr。
使用方式:
$ git clone https://github.com/Loadium/postman2jmx.git
$ cd postman2jmx
$ mvn package
$ cd target/Postman2Jmx
$ java -jar Postman2Jmx.jar my_postman_collection.json my_jmx_file.jmx
正常的話,最終就會得到一個my_jmx_file.jmx檔案,匯入jmeter即可。
jmeter設定
匯入效果
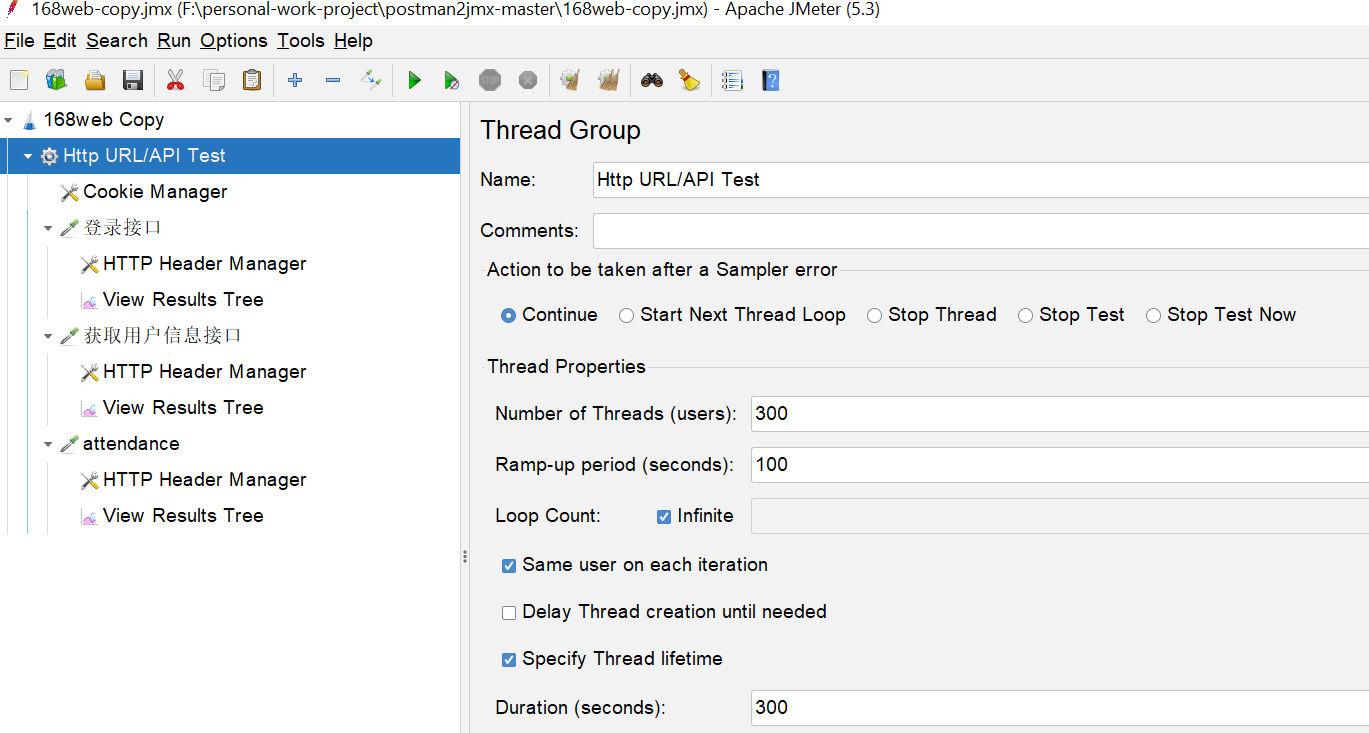
開啟這個jmx後,個人做了一點點修改,加了個檢視結果數,改了下執行緒組設定,大概如下:
我這邊專案還是依賴cookie 機制的,所以我這邊就用了cookie manager,它會自動把返回中的set-cookie,儲存到該執行緒的cookie區域,後續的請求也會自動攜帶:
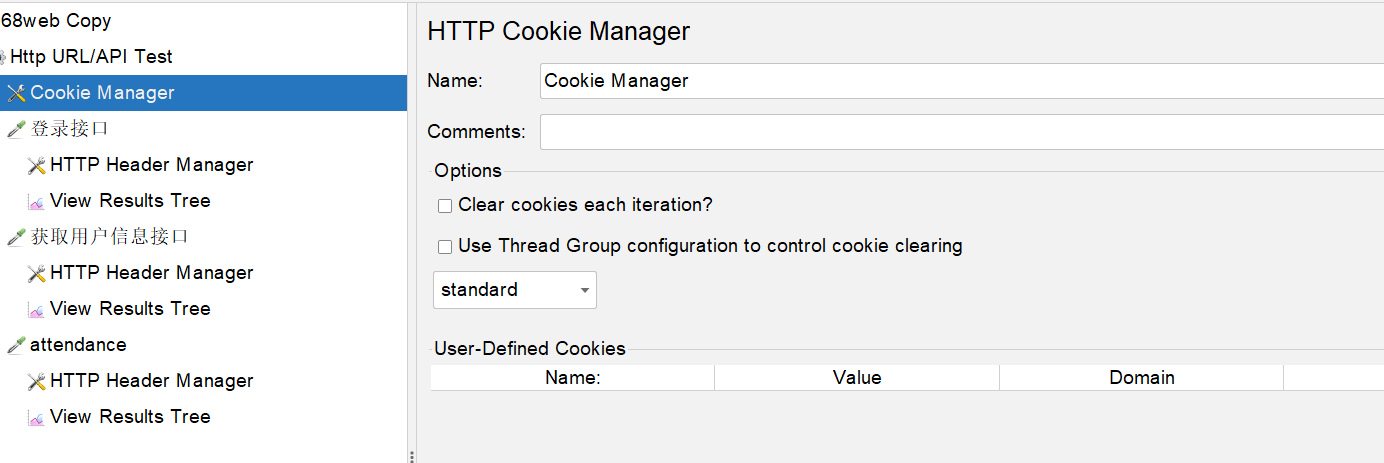
如果不瞭解,可以在該頁面點選Help,就能看到幫助檔案。
匯入的效果還是挺好的:
執行緒組中並行執行緒數的設定
一般來說,壓測的話,我們會關注某個介面的qps或tps,此時一般要增加一個listener,如聚合報告,來檢視最終介面的吞吐(tps):
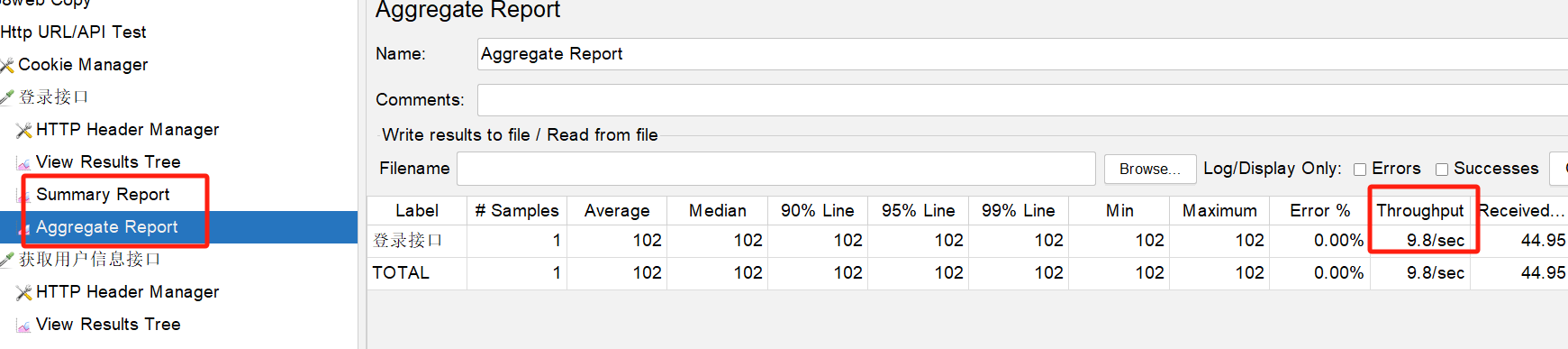
我們一般用jmeter做壓測的目的,是我需要壓測出,在目前架構、環境下,該介面的極限是多少,能達到多少筆/s,此時,就是靠不斷地加壓(比如提高並行使用者數),在壓力越來越大的情況下,系統一開始可能Throughput的值是一路增加的,但慢慢地,會到達一個拐點,到了這個點,你再加壓,Throughout也不會繼續增加了,此時,就拿到了極限tps。
當然,我們也可能加壓到一定程度,發現介面的tps達標了,就不管了,不會繼續加壓,去尋找那個壓力不斷提升下的tps拐點。
但是,我之前一直有個問題,就是不知道jmeter裡的並行執行緒數怎麼設定,經過查閱,發現在效能測試領域,業內一般把這個值叫做 VU(virtual user)。
這個值,效能測試人員在做測試計劃的時候,就會先去根據系統的使用人員規模、系統的高峰時間有多長,來進行估算,總的來說,還是有點複雜。我這邊也是看了一本書,全棧效能測試修煉寶典,裡面第7章講了具體怎麼算。
我這邊也網上簡單查了下,比如:
https://www.cnblogs.com/gltou/p/15168252.html
通用公式
對絕大多數場景,我們用:
並行量=(使用者總量/統計時間)*影響因子(一般為3)來進行估算。
#使用者總量和統計時間使用2/8原則計算,即80%的使用者集中在20%的時間
#影響因子,一般為3,根據實際情況來
#通用公式使用了二八原則,計算的並行量即是峰值並行量。
例子
以乘坐地鐵為例子,每天乘坐人數為5萬人次,每天早高峰是7到9點,晚高峰是6到7點,根據2/8原則,80%的乘客會在高峰期間乘坐地鐵,則每秒到達地鐵檢票口的人數為50000*80%/(3小時*60*60s)=3.7,約4人/S,考慮到安檢,入口關閉等因素,實際堆積在檢票口的人數肯定比這個要大,假定每個人需要3秒才能進站,那實際並行應為4人/s*3s=12,當然影響因子可以根據實際情況增大!
它這個地鐵的例子中,算出來並行使用者就應該設定為12.
然後,另一個文章裡的例子,這種是根據PV來計算:
根據PV計算
並行量=(日PV/統計時間)*影響因子(一般為3)
#日PV和統計時間使用2/8原則計算,即80%的使用者集中在20%的時間
#影響因子,一般為3,根據實際情況來
#PV公式使用了二八原則,計算的並行量即是峰值並行量。
例子
比如一個網站,每天的PV大概1000w,根據2/8原則,我們可以認為這1000w,pv的80%是在一天的9個小時內完成的(人的精力有限),那麼TPS為:1000w*80%/(9*60*60)=246.92個/s,取經驗因子3,則並行量應為:246.92*3=740
所以,最終算出來,其實並行使用者數也不是很高,一般的系統,感覺jmeter裡的並行執行緒數控制在500內就夠了,再不行的話,1000內都足夠了。如果超出1000了,看看是不是考慮用多個jmeter範例進行分散式壓測,因為一般像大公司那種比較大的業務,壓測都是分散式壓測,壓測機叢集都好幾十臺起步。
當然,如果非要拼命在單個jmeter範例(也就是一個java程序)提升執行緒數,可以看看下面這篇文章:
https://www.blazemeter.com/blog/jmeter-maximum-concurrent-users
看看是如何靠增加堆大小之類,來提升到10000個執行緒的,不過我反正是不建議,畢竟機器一般也才幾核、幾十核為主,開那麼多執行緒會導致頻繁的執行緒切換。
執行緒組中其他屬性的設定
以下圖為例:
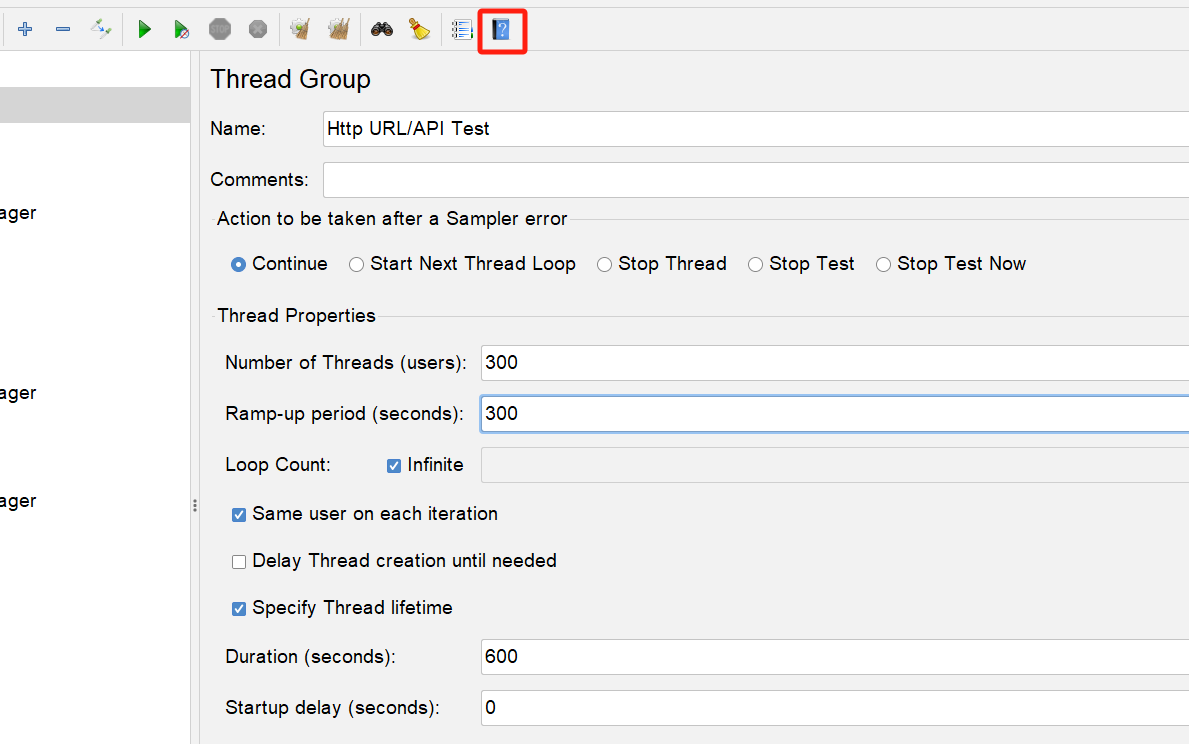
300個執行緒,但是Ramp-up period 是300s,意思是在300s內將我那300個執行緒啟動起來,也就是1s增加1個;如果你設為1的話,300個執行緒就會在1s內啟動,我感覺對電腦衝擊比較大,還是平緩一點好。
Loop count我這裡是設定為無限,那,難道整個指令碼就一直跑嗎,當然不是,可以看到,我上圖設定了Duration為600s,也就是說,指令碼總共跑10分鐘。
可以預測的是:
在前300s,會逐步從1個執行緒增加到300個執行緒;在後面300s,就是300個執行緒同時去跑指令碼,這時候的壓力是穩定的300 virtual user或者說300執行緒產生的並行。
jmeter執行
嚴格壓測時,我們一般不在GUI裡面去執行,而是採用cli方式。
比如,在windows下用cli方式壓測:
F:\apache-jmeter-5.2.1\bin>jmeter -n -t Test.jmx -l result.jtl -j test.log
或者在linux下壓測:
./jmeter -n -t Test.jmx -l result.jtl
長時間壓測
nohup ./jmeter -n -t Test.jmx -l result.jtl 2>&1 &
壓測時,會產生這樣的輸出:
summary = 3801 in 00:00:40 = 94.5/s Avg: 417 Min: 13 Max: 3817 Err: 0 (0.00%)
表示現在是壓測開始後的第40s,3801是總共發出去的請求,94.5/s是這期間的tps,後面就是平均數、最小、最大、錯誤數
過一陣後,會連著出現這樣的:
summary + 2590 in 00:00:35 = 74.3/s Avg: 1076 Min: 97 Max: 9799 Err: 0 (0.00%) Active: 151 Started: 151 Finished: 0
summary = 6391 in 00:01:15 = 85.1/s Avg: 684 Min: 13 Max: 9799 Err: 0 (0.00%)
為+的那一行,表示的是增量,從上一行結束後,過去了35s,這35s期間產生了2590個請求,這期間的tps是74.3
為=的那一行,就是從指令碼開始到目前為止,總的指標,如6391這個請求數,就是40s時候的請求數3801 + 增量的2590.
順便給大家看下,我這次上線前,為了測試下穩定性,壓了18個小時:
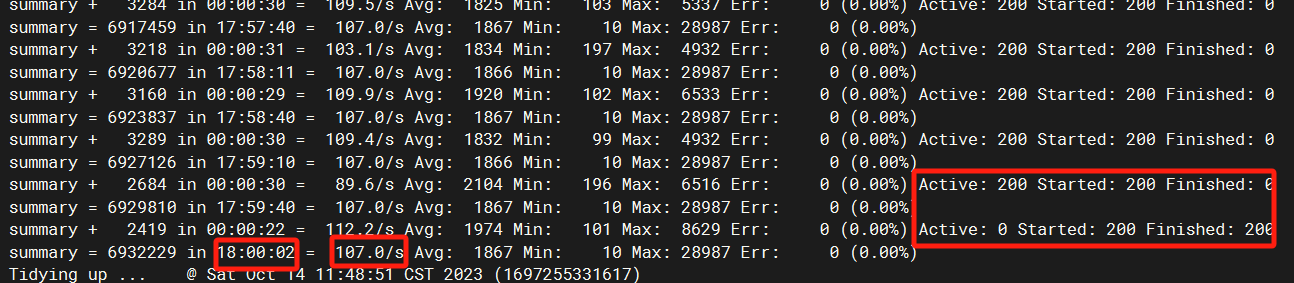
另外,後面的Active那些就是活躍執行緒數,我是用200並行壓了18小時,第二天去,發現系統還是挺穩定。