解密Prompt系列17. LLM對齊方案再升級 WizardLM & BackTranslation & SELF-ALIGN
話接上文的指令微調的樣本優化方案,上一章是通過多樣性篩選和質量過濾,對樣本量進行縮減,主打經濟實惠。這一章是通過擴寫,改寫,以及回譯等半監督樣本挖掘方案對種子樣本進行擴充,提高種子指令樣本的多樣性和複雜度,這裡我們分別介紹Microsoft,Meta和IBM提出的三個方案。
Microsoft:WizardLM
- WizardLM: Empowering Large Language Models to Follow Complex Instructions
- https://github.com/nlpxucan/WizardLM
- 要點:使用prompt對種子指令樣本進行多樣化,複雜化改寫可以有效提升模型效果
wizardLM提出了一套指令改寫的方案Evol-Instruct對原始指令樣本進行改寫,改寫後的指令用於微調模型顯著超過了之前Vicuna使用ShareGPT微調LLAMA的效果,甚至在複雜指令上號稱超過ChatGPT。
指令改寫是使用大模型直接進行的,分成深度改寫和廣度改寫兩個型別,其中深度改寫有5種不同的改寫指令,廣度改寫有1種改寫指令。Evol-Instruct對初始的指令集,也就是52K的Alpaca指令,總共進行了4輪改寫,每輪改寫會等權重隨機選擇一種深度、廣度改寫指令,經過過濾後總共得到了250K的改寫指令用於模型微調。下圖是一個指令改寫的範例
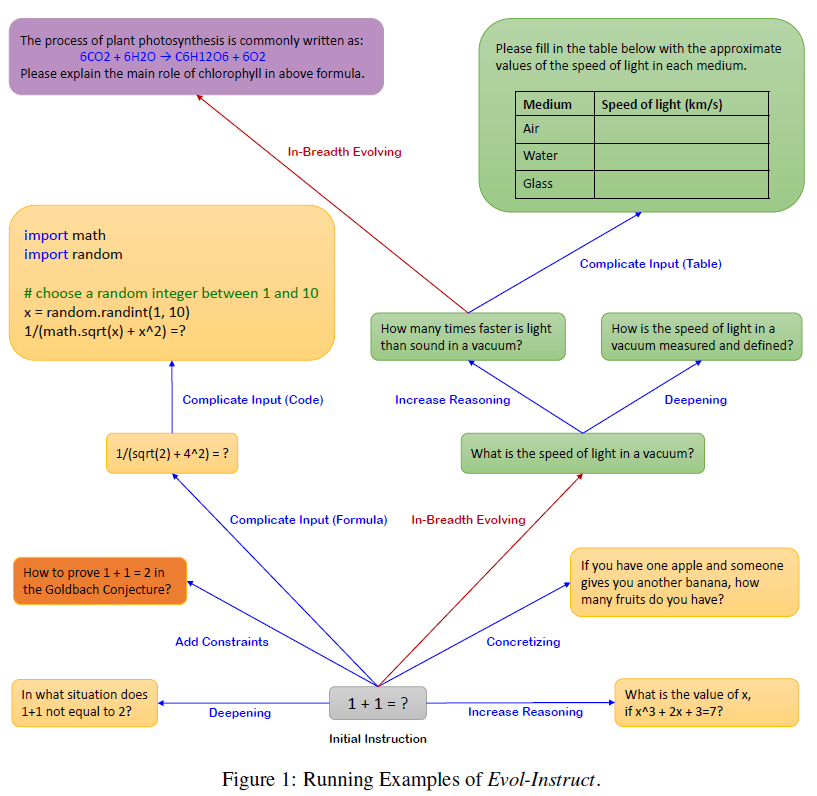
下面我們具體看下改寫指令是如何設計的
深度改寫
深度改寫把指令改寫的更加複雜,包括加入限制條件,指令複雜化,指令具象化,增加推理步驟,輸入複雜化等5種型別的指令。以下是加入限制條件的prompt指令,以下指令控制每次改寫增加的字數,以及改寫的程度,每次只增加部分難度,這樣通過多輪的改寫,就可以得到不同難度,多樣性更高的指令集。

其他的四類prompt的差異主要在高亮部分,分別為
- 指令複雜化:If #Given Prompt# contains inquiries about certain issues, the depth and breadth of the inquiry can be increased
- 指令具象化:Please replace general concepts with more specific concepts.
- 增加推理步驟:If #Given Prompt# can be solved with just a few simple thinking processes, you can rewrite it to explicitly request multiple-step reasoning.
- 輸入複雜化:You must add [XML data] format text as input data in [Rewritten Prompt]
廣度改寫
廣度改寫的目的就是為了擴充指令覆蓋的範圍,包括更多的話題,技能等等

改寫基本是論文最大的亮點,除此之外的細節就不多細說啦。通過4輪改寫,加上簡單的樣本過濾後得到的250K指令樣本用於模型微調,效果上在收集的Evol-Instruct測試集,Vicuna的測試集,以及更高難度的測試集上WizardLM的效果都略超過vicuna還有alapca。但略有些奇怪的是vicuna似乎表現還略差於alpaca?Anyway, LLM時代評估指標的置信度都有限,方法學到手就好,模型表現莫要太當真.......
Meta:BackTranslation
- Self-Alignment with Instruction Backtranslation
- ClueWeb資料集:https://lemurproject.org/clueweb12/specs.php
- Open Assistant資料集:https://huggingface.co/datasets/OpenAssistant/oasst1
- 要點:結合質量過濾和半監督的指令樣本挖掘方案擴充種子樣本,多次迭代後可以提高模型效果
對比以上WizardLM從指令側入手,通過改寫指令來生成更多樣,複雜的指令樣本,來擴充種子樣本集。Back Translation則是用了半監督的思路,從輸出側入手,通過從網路上爬取優質的人工編輯的內容作為輸出,併為這些輸出配上合適的指令來擴充套件已有的指令樣本集。
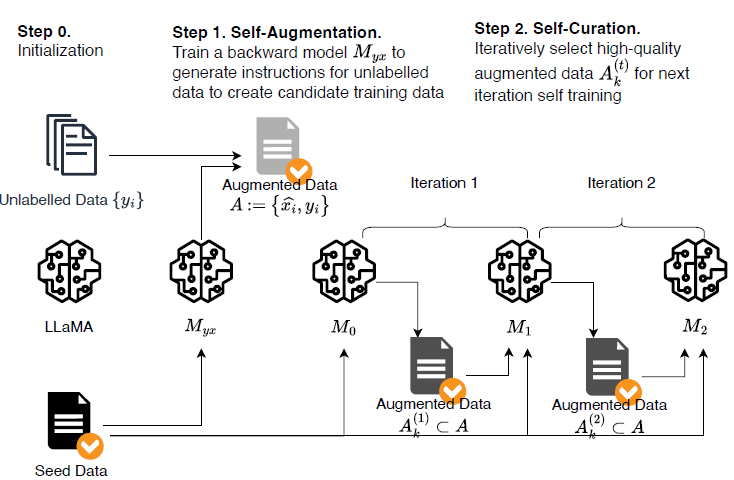
因為是先有輸出再有輸入,所以論文使用了回譯來命名此方案,核心兩個步驟如下
1. Self-Augmentation
指令生成部分,論文先使用Open Assistant裡面人工標註的3200指令樣本資料作為種子資料來訓練LLama模型,得到初版的對齊模型。SFT訓練和常規略有不同,採用了反向對齊,也就是給定Output生成Instruction(P(X|Y))的條件生成任務。
然後論文針對爬取的網頁資料,經過清洗後作為指令樣本的輸出,然後使用以上模型直接推理得到指令本身,對應以上P(X|Y)的條件生成任務。
這一步其實感覺也可以使用類似APE的prompt逆向工程方案來實現,讓模型基於輸出猜測最合適的指令是什麼。這樣SFT的模型可能也能完成這個步驟?
2. Iterative Self-Curation
第二步考慮以上生成的指令樣本對可能存在很多低質量樣本,因此需要進行質量過濾。質量過濾的模型同樣是基於3200個種子指令樣本,進行常規SFT得到初始模型。然後基於Prompt模板對以上得到的指令樣本進行1-5分的絕對打分。主要評估回答是否明確有用無爭議,能合理回答指令中的問題,並且回答的主語模型而非其他第三人稱,Prompt如下,

同時論文使用了多輪迭代的訓練,以上第一輪打分過濾出的高分樣本,會和種子樣本混合,重頭進行SFT。然後微調後的模型會再用來對樣本進行打分過濾,然後再混合重新SFT。
在SFT的樣本構建中,論文使用了不同的Prompt來區分樣本是來自人工標註的種子集,還是來自機器生成的擴充套件集,前者的prompt=「Answer in the style of an AI Assistant,後者的prompt=Answer with knowledge from web search,從而降低樣本間不同回答format帶來的模型學習混淆。
效果
整體效果評估,論文使用了混合測試集包括Vicuna,self-instruct, opena assistant,koala,HH-RLHF, LIMA等總共1130個指令資料。使用人工進行兩兩偏好對比,以下使用回譯訓練的HumpBack優於LIMA等質量過濾微調模型,以及Davinci,Claude等閉源模型。
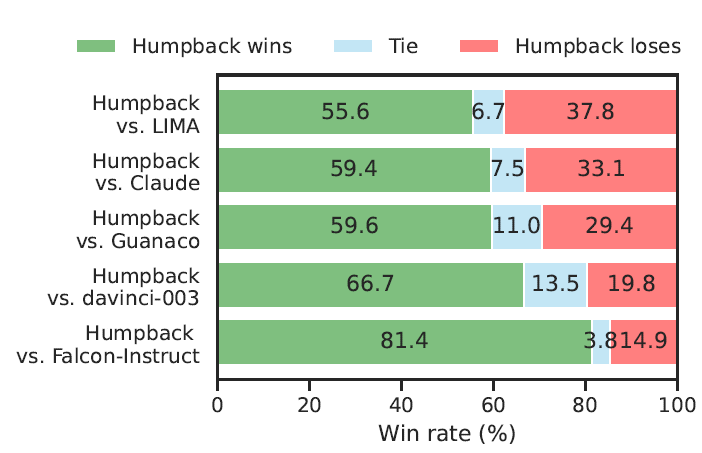
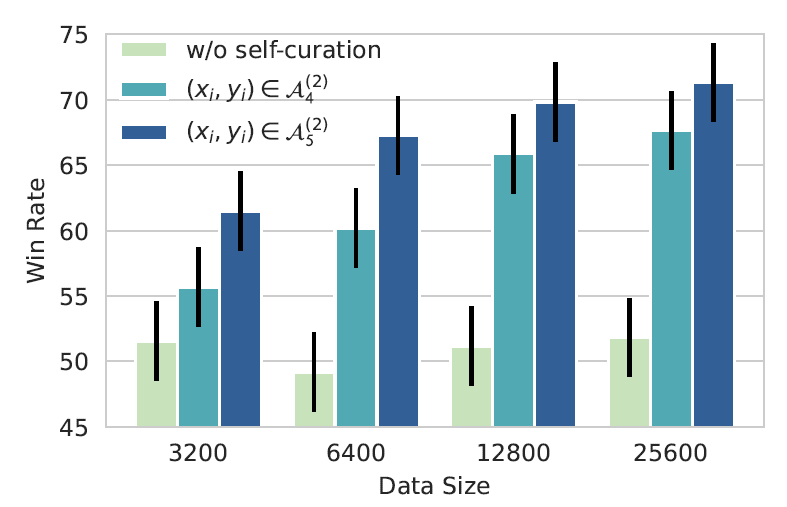
同時論文進行了消融實驗,對訓練資料的數量和質量的影響做了進一步的測試,對比了未使用Self-Curation過濾的資料集,4輪過濾的資料集和5輪過濾的資料集,不同的樣本量帶來的效果差異,主要結論有兩個
- 高質量樣本集提升數量會帶來效果提升:這裡的結論和上一章LIMA的結論有矛盾頓,LIMA中在過濾後的Stack Exchange資料集上增加取樣比例並不會提升效果。猜測這裡可能的差異有:
- Stack Exchange的指令豐富程度可能低於回譯指令,和AlpaGasus中指令豐富程度有限的話增加樣本量並不會帶來效果提升的結論一致
- Stack Exchange本身的指令質量低於回譯,導致數量增加帶來的效果增幅不明顯。Anyway LLM時代一切結論都不可盡信,只是拓寬下思路,實際情況下處理問題還是要具體問題具體分析。
- 質量的影響大於數量: 在未過濾的資料集上提升量級不會顯著帶來效果提升,簡單理解就是1個低質樣本需要很多的高質量樣本來彌補,當低質量樣本佔比太高的時候,無論如何提升樣本量都不會提升效果。
IBM: Self Alignment
- Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
- https://mitibmdemos.draco.res.ibm.com/dromedary
- 要點:使用prompt規則讓大模型Self-Instruct生成的推理樣本更加符合人類偏好,部分代替RLHF階段大量的人工標註
同樣是改寫方案,Self-Align在Self-Instruct的基礎上上,通過引入對抗指令樣本和3H相關的指令prompt,在SFT階段就讓模型進行偏好對齊。讓模型先基於外化的偏好原則生成符合3H原則的回答,再通過SFT對齊把偏好內化到模型引數中,因為指令樣本是Base模型自己生成的所以叫Self-Alignment。有些類似自監督,只不過樣本特徵被人工抽象成了人類偏好規則。
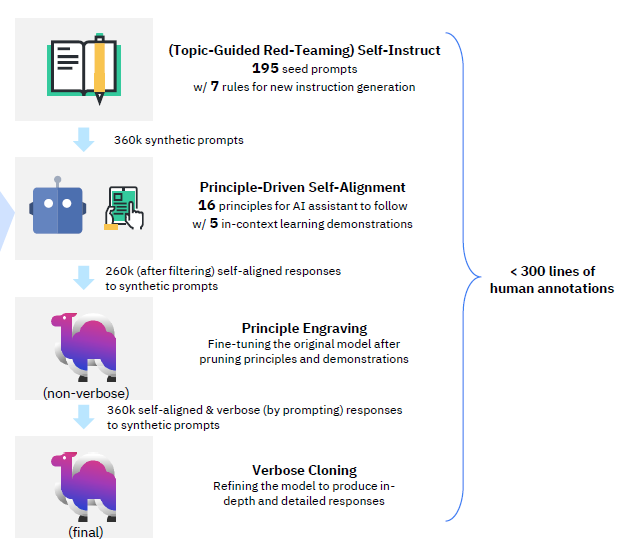
指令樣本生成分成以下4個步驟
Self-Instruct生成指令
不熟悉Self-Instruct的同學,請先看解密prompt系列5. APE+SELF=自動化指令集構建程式碼實現,原始論文基於175個種子指令通過多輪的Bootstrap讓大模型生成新的指令。
IBM論文在此基礎上人工補充了20個不同主題的對抗種子指令。對抗樣本我們在解密Prompt7. 偏好對齊RLHF章節針對Anthropic如何設計對抗樣本進行了很詳細的介紹,這裡不再展開。IBM設計對抗樣本的原則是模型在沒有獲取外部資訊下無法回答,或者會回答錯誤的指令,例如詢問天氣,知識問答類的指令。通過補充這類種子指令,讓模型在bootstrap過程中生成更多的對抗指令,從而通過指令微調的對齊注入3H(helpful+harmless+honest)偏好。
Self-Alignment生成回答
指令生成完,下一步就是需要讓模型生成符合3H偏好的回答。論文的實現方案是通過規則指令+fewshot樣例來實現。其中規則指令總共包含以下16條原則:1 (ethical), 2 (informative), 3 (helpful), 4
(question assessment), 5 (reasoning), 6 (multi-aspect), 7 (candor), 8 (knowledge recitation), 9 (static),10 (clarification), 11 (numerical sensitivity), 12 (dated knowledge), 13 (step-by-step), 14 (balanced & informative perspectives), 15 (creative), 16 (operationa)。
以下是附錄中具體規則指令的前5條

而In-context的few-shot樣本同樣是固定的,few-shot的樣本是為了指導模型如何遵守以上16條規則來進行指令回答,並加入了類似chain-of-thought的Internal Thoughts步驟,來強化模型在不同的上文中遵從不同的規則

微調
以上兩步機器樣本構造後,經過過濾總共得到了260K指令樣本,用於模型微調。注意微調階段不會使用以上的16條規則指令和few-shot樣本,而是會直接使用回答部分。因為需要模型直接把3H原則指令通過微調內化到模型引數中,而不是基於條件上文進行符合偏好的回答。
微調的指令如下
微調後作者發現,以上構造的樣本在微調模型後存在兩個問題
- 部分回答過於簡短:個人感覺這和Prompt+few-shot的長度過長有關。因為條件上文過長,限制了下文的生成範圍,導致回答過短。通俗點就是命題作文你的要求太多自然就沒啥好寫的了。
- 部分回答未直接回答使用者指令,而是去複述wikipedia上的內容:個人感覺這同樣是以上的規則指令模型未能完全理解,影響了回答質量。
這裡其實有個疑問,就是在大量指令和In-Context條件上文下,構造出的模型回答是否本身就是有偏的???而去掉條件上文直接去擬合回答後得到的模型是否也是bias的?這個問題要是有想法歡迎評論區留言~
為了解決以上問題,論文使用第一步對齊微調後,已經內化3H原則的模型,使用以下的Prompt指令引導模型重新對以上的260K指令進行回答生成,引導模型給出更豐富,跟全面的回答。然後再使用生成的樣本進一步微調模型。

效果上在TruthfulQA的事實性評測,以及Big-Bench的3H評測上,微調後的模型相較LLama都有顯著的提升。
想看更全的大模型相關論文梳理·微調及預訓練資料和框架·AIGC應用,移步Github >> DecryPrompt
Reference
- Self-instruct: Aligning language model with self generated instructions
- SELF-QA Unsupervised Knowledge Guided alignment
- Self-Consuming Generative Models Go MAD
- Tagged back-translation.
- Becoming self-instruct: introducing early stopping criteria for minimal instruct tuning