Java也能做OCR!SpringBoot 整合 Tess4J 實現圖片文字識別
前言
今天給大家分享一個
SpringBoot整合Tess4j庫實現圖片文字識別的小案例,希望xdm喜歡。文末有案例程式碼的Git地址,可以自己下載了去玩玩兒或繼續擴充套件也行。
話不多說,開整吧。
什麼是Tess4j庫
先簡單給沒聽過的xdm解釋下,這裡要分清楚
Tesseract和Tess4j的區別。
Tesseract是一個開源的光學字元識別(OCR)引擎,它可以將影象中的文字轉換為計算機可讀的文字。支援多種語言和書面語言,並且可以在命令列中執行。它是一個流行的開源OCR工具,可以在許多不同的作業系統上執行。
Tess4J是一個基於Tesseract OCR引擎的Java介面,可以用來識別影象中的文字,說白了,就是封裝了它的API,讓Java可以直接呼叫。搞清楚這倆東西,就足夠了。
案例
1、引入依賴
既然是SpringBoot,基礎依賴我就不贅述了,這裡貼下Tess4J的依賴,是可以用maven下載的。
<!-- tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.4</version>
</dependency>
2、yml設定
這裡,我特地把訓練資料的目錄路徑設定在yml裡,後續可以擴充套件到設定中心。
server:
port: 8888
# 訓練資料資料夾的路徑
tess4j:
datapath: D:/tessdata
然後我解釋下什麼是訓練資料
Tesseract OCR庫通過訓練資料來學習不同語言和字型的特徵,以便更好地識別圖片中的文字。
在安裝Tesseract OCR庫時,通常會生成一個包含多個子資料夾的訓練資料資料夾,其中每個子資料夾都包含了特定語言或字型的訓練資料。
比如我這裡是下載後放到了D槽的tessdata目錄下,如圖所示,其實就是一個
.traineddata為字尾的檔案,大小約2M多。
如果你沒有特定的訓練資料需求,使用預設的訓練資料檔案即可,我這裡就是直接下載預設的來用的。
還有一點要注意的是,直接讀resource目錄下的路徑是讀不到的哈,所以我放到了D槽,訓練資料本身也是更推薦放到獨立的位置,方便後續訓練資料。
3、config設定類
我們新建一個設定類,初始化一下Tesseract類,交給Spring管理,這樣借用了Spring的單例模式。
package com.example.tesseractocr.config;
import net.sourceforge.tess4j.Tesseract;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @作者: 公眾號【Java分享客棧】
* @日期: 2023/10/12 22:58
* @描述:
*/
@Configuration
public class TesseractOcrConfiguration {
@Value("${tess4j.datapath}")
private String dataPath;
@Bean
public Tesseract tesseract() {
Tesseract tesseract = new Tesseract();
// 設定訓練資料資料夾路徑
tesseract.setDatapath(dataPath);
// 設定為中文簡體
tesseract.setLanguage("chi_sim");
return tesseract;
}
}
4、service實現
就幾行程式碼,非常簡單。
package com.example.tesseractocr.service;
import lombok.AllArgsConstructor;
import net.sourceforge.tess4j.*;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
@Service
@AllArgsConstructor
public class OcrService {
private final Tesseract tesseract;
/**
* 識別圖片中的文字
* @param imageFile 圖片檔案
* @return 文字資訊
*/
public String recognizeText(MultipartFile imageFile) throws TesseractException, IOException {
// 轉換
InputStream sbs = new ByteArrayInputStream(imageFile.getBytes());
BufferedImage bufferedImage = ImageIO.read(sbs);
// 對圖片進行文字識別
return tesseract.doOCR(bufferedImage);
}
}
5、新增rest介面
我們新建一個rest介面,用來測試效果,使用上傳圖片檔案的方式。
package com.example.tesseractocr.controller;
import com.example.tesseractocr.service.OcrService;
import lombok.AllArgsConstructor;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
@RequestMapping("/api")
@RestController
@AllArgsConstructor
public class OcrController {
private final OcrService ocrService;
@PostMapping(value = "/recognize", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public String recognizeImage(@RequestParam("file") MultipartFile file) throws TesseractException, IOException {
// 呼叫OcrService中的方法進行文字識別
return ocrService.recognizeText(file);
}
}
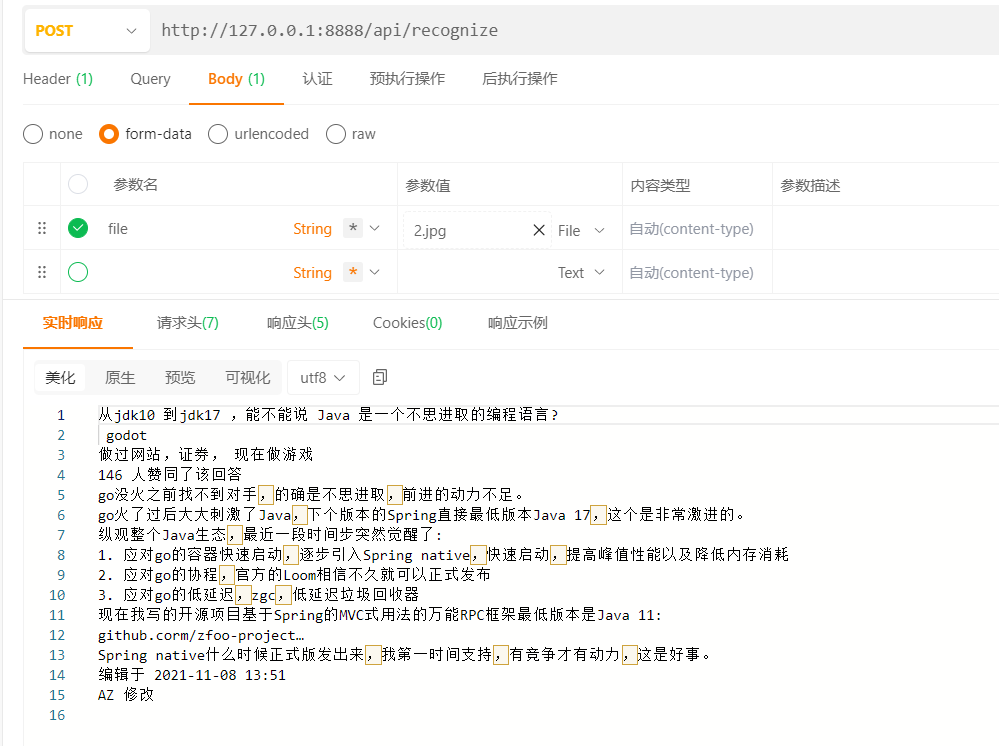
6、測試效果
這裡我用ApiPost工具來測試下最終效果
我準備的一張圖片如下,是從知乎上隨便擷取的一張。
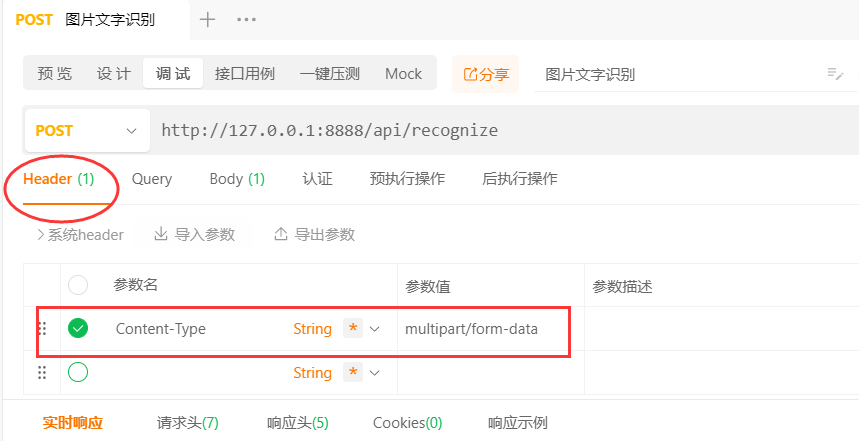
我們調介面試一下,這裡要設定Header的Content-Type,別忘了哈。
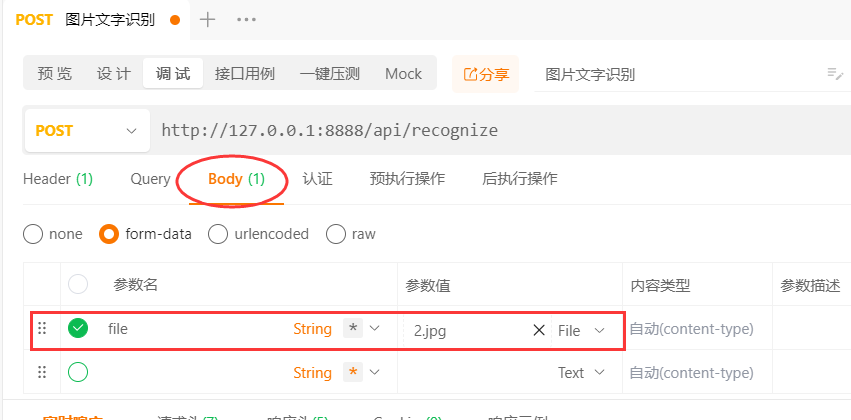
這裡是body中的引數,我們選擇form-data中的File屬性,表示以上傳檔案形式來調介面。
看下效果,其實還是挺不錯的,我和圖片比對了一下,基本上都識別出來了。
相關地址
1)、Tesseract-ocr官方Github地址:https://github.com/tesseract-ocr/tesseract
2)、Tesseract-ocr安裝下載:https://digi.bib.uni-mannheim.de/tesseract/
PS:這裡我沒有用官方Github檔案中給的地址,因為太慢了,找了一個下載比較快的,你們可以往下拉找到win64位元的安裝即可,如果沒有訓練需求,不用下也可以)
3)、訓練檔案:https://digi.bib.uni-mannheim.de/tesseract/tessdata_fast/
PS:在2)的路徑下,有一個tessdata_fast目錄,點進去就能直接下載到預設訓練檔案,這種比較簡便,省去了前面安裝下載的過程。
4)、案例程式碼:https://gitee.com/fangfuji/java-share
PS:程式碼放在Gitee上,在同名博文目錄裡面,包含程式碼+安裝檔案+訓練檔案。
總結
是不是非常簡單xdm,反正我覺得挺有意思的,後面抽空再試試訓練資料。
好了,今天的小知識,你學會了嗎?
如果喜歡,請點贊+關注↓↓↓,持續分享乾貨哦!