數位時代的自我呈現:探索個人形象打造的創新工具——FaceChain深度學習模型工具
數位時代的自我呈現:探索個人形象打造的創新工具——FaceChain深度學習模型工具
1.介紹
FaceChain是一個可以用來打造個人數位形象的深度學習模型工具。使用者僅需要提供最低一張照片即可獲得獨屬於自己的個人形象數位替身。FaceChain支援在gradio的介面中使用模型訓練和推理能力,也支援資深開發者使用python指令碼進行訓練推理;同時,歡迎開發者對本Repo進行繼續開發和貢獻。
FaceChain的模型由ModelScope開源模型社群提供支援。

2.環境準備
-
相容性驗證
FaceChain是一個組合模型,使用了包括PyTorch和TensorFlow在內的機器學習框架,以下是已經驗證過的主要環境依賴:- python環境: py3.8, py3.10
- pytorch版本: torch2.0.0, torch2.0.1
- tensorflow版本: 2.8.0, tensorflow-cpu
- CUDA版本: 11.7
- CUDNN版本: 8+
- 作業系統版本: Ubuntu 20.04, CentOS 7.9
- GPU型號: Nvidia-A10 24G
-
資源要求
- GPU: 視訊記憶體佔用約19G
- 磁碟: 推薦預留50GB以上的儲存空間
2.安裝指南
支援以下幾種安裝方式,任選其一:
2.1. 使用ModelScope提供的notebook環境【推薦】
ModelScope(魔搭社群)提供給新使用者初始的免費計算資源,參考ModelScope Notebook
如果初始免費計算資源無法滿足要求,您還可以從上述頁面開通付費流程,以便建立一個準備就緒的ModelScope(GPU) DSW映象範例。
Notebook環境使用簡單,您只需要按以下步驟操作(注意:目前暫不提供永久儲存,範例重啟後資料會丟失):
#Step1: 我的notebook -> PAI-DSW -> GPU環境
#Step2: 進入Notebook cell,執行下述命令從github clone程式碼:
!GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
#Step3: 切換當前工作路徑
import os
os.chdir('/mnt/workspace/facechain') # 注意替換成上述clone後的程式碼檔案夾主路徑
print(os.getcwd())
!pip3 install gradio
!pip3 install controlnet_aux==0.0.6
!pip3 install python-slugify
!python3 app.py
#Step4: 點選生成的URL即可存取web頁面,上傳照片開始訓練和預測
除了ModelScope入口以外,您也可以前往PAI-DSW 直接購買帶有ModelScope映象的計算範例(推薦使用A10資源),這樣同樣可以使用如上的最簡步驟執行起來。
2.2 docker映象
如果您熟悉docker,可以使用我們提供的docker映象,其包含了模型依賴的所有元件,無需複雜的環境安裝:
#Step1: 機器資源
您可以使用本地或雲端帶有GPU資源的執行環境。
如需使用阿里雲ECS,可存取: https://www.aliyun.com/product/ecs,推薦使用」映象市場「中的CentOS 7.9 64位元(預裝NVIDIA GPU驅動)
#Step2: 將映象下載到本地 (前提是已經安裝了docker engine並啟動服務,具體可參考: https://docs.docker.com/engine/install/)
docker pull registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.0
#Step3: 拉起映象執行
docker run -it --name facechain -p 7860:7860 --gpus all registry.cn-hangzhou.aliyuncs.com/modelscope-repo/modelscope:ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.0 /bin/bash #注意 your_xxx_image_id 替換成你的映象id
#(注意: 如果提示無法使用宿主機GPU的錯誤,可能需要安裝nvidia-container-runtime, 參考:https://github.com/NVIDIA/nvidia-container-runtime)
#Step4: 在容器中安裝gradio
pip3 install gradio
pip3 install controlnet_aux==0.0.6
pip3 install python-slugify
#Step5: 獲取facechain原始碼
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
cd facechain
python3 app.py
#Note: FaceChain目前支援單卡GPU,如果您的環境有多卡,請使用如下命令
#CUDA_VISIBLE_DEVICES=0 python3 app.py
#Step6: 點選 "public URL", 形式為 https://xxx.gradio.live
2.3. conda虛擬環境
使用conda虛擬環境,參考Anaconda來管理您的依賴,安裝完成後,執行如下命令:
(提示: mmcv對環境要求較高,可能出現不適配的情況,推薦使用docker方式)
conda create -n facechain python=3.8 # 已驗證環境:3.8 和 3.10
conda activate facechain
GIT_LFS_SKIP_SMUDGE=1 git clone https://github.com/modelscope/facechain.git --depth 1
cd facechain
pip3 install -r requirements.txt
pip3 install -U openmim
mim install mmcv-full==1.7.0
#進入facechain資料夾,執行:
python3 app.py
#Note: FaceChain目前支援單卡GPU,如果您的環境有多卡,請使用如下命令
#CUDA_VISIBLE_DEVICES=0 python3 app.py
#最後點選log中生成的URL即可存取頁面。
備註:如果是Windows環境還需要注意以下步驟:
#1. 重新安裝pytorch、與tensorflow匹配的numpy
#2. pip方式安裝mmcv-full: pip3 install mmcv-full
如果您想要使用"人物說話視訊生成"分頁的功能,請參考installation_for_talkinghead_ZH裡的安裝使用教學。
2.4. colab執行
| Colab | Info |
|---|---|
 |
FaceChain Installation on Colab |
備註:app服務成功啟動後,在log中存取頁面URL,進入」形象客製化「tab頁,點選「選擇圖片上傳」,並最少選1張包含人臉的圖片;點選「開始訓練」即可訓練模型。訓練完成後紀錄檔中會有對應展示,之後切換到「形象體驗」分頁點選「開始生成」即可生成屬於自己的數位形象。
2.5指令碼執行
如果不想啟動服務,而是直接在命令列進行開發偵錯等工作,FaceChain也支援在python環境中直接執行指令碼進行訓練和推理。在克隆後的資料夾中直接執行如下命令來進行訓練:
PYTHONPATH=. sh train_lora.sh "ly261666/cv_portrait_model" "v2.0" "film/film" "./imgs" "./processed" "./output"
引數含義:
ly261666/cv_portrait_model: ModelScope模型倉庫的stable diffusion基模型,該模型會用於訓練,可以不修改
v2.0: 該基模型的版本號,可以不修改
film/film: 該基模型包含了多個不同風格的子目錄,其中使用了film/film目錄中的風格模型,可以不修改
./imgs: 本引數需要用實際值替換,本引數是一個本地檔案目錄,包含了用來訓練和生成的原始照片
./processed: 預處理之後的圖片資料夾,這個引數需要在推理中被傳入相同的值,可以不修改
./output: 訓練生成儲存模型weights的資料夾,可以不修改
等待5-20分鐘即可訓練完成。使用者也可以調節其他訓練超引數,訓練支援的超引數可以檢視train_lora.sh的設定,或者facechain/train_text_to_image_lora.py中的完整超參數列。
進行推理時,請編輯run_inference.py中的程式碼:
#使用深度控制,預設False,僅在使用姿態控制時生效
use_depth_control = False
#使用姿態控制,預設False
use_pose_model = False
#姿態控制圖片路徑,僅在使用姿態控制時生效
pose_image = 'poses/man/pose1.png'
#填入上述的預處理之後的圖片資料夾,需要和訓練時相同
processed_dir = './processed'
#推理生成的圖片數量
num_generate = 5
#訓練時使用的stable diffusion基模型,可以不修改
base_model = 'ly261666/cv_portrait_model'
#該基模型的版本號,可以不修改
revision = 'v2.0'
#該基模型包含了多個不同風格的子目錄,其中使用了film/film目錄中的風格模型,可以不修改
base_model_sub_dir = 'film/film'
#訓練生成儲存模型weights的資料夾,需要保證和訓練時相同
train_output_dir = './output'
#指定一個儲存生成的圖片的資料夾,本引數可以根據需要修改
output_dir = './generated'
#使用鳳冠霞帔風格模型,預設False
use_style = False
之後執行:
python run_inference.py
即可在output_dir中找到生成的個人數位形象照片。
3.演演算法介紹
3.1基本原理
個人寫真模型的能力來源於Stable Diffusion模型的文生圖功能,輸入一段文字或一系列提示詞,輸出對應的影象。我們考慮影響個人寫真生成效果的主要因素:寫真風格資訊,以及使用者人物資訊。為此,我們分別使用線下訓練的風格LoRA模型和線上訓練的人臉LoRA模型以學習上述資訊。LoRA是一種具有較少可訓練引數的微調模型,在Stable Diffusion中,可以通過對少量輸入影象進行文生圖訓練的方式將輸入影象的資訊注入到LoRA模型中。因此,個人寫真模型的能力分為訓練與推斷兩個階段,訓練階段生成用於微調Stable Diffusion模型的影象與文字標籤資料,得到人臉LoRA模型;推斷階段基於人臉LoRA模型和風格LoRA模型生成個人寫真影象。
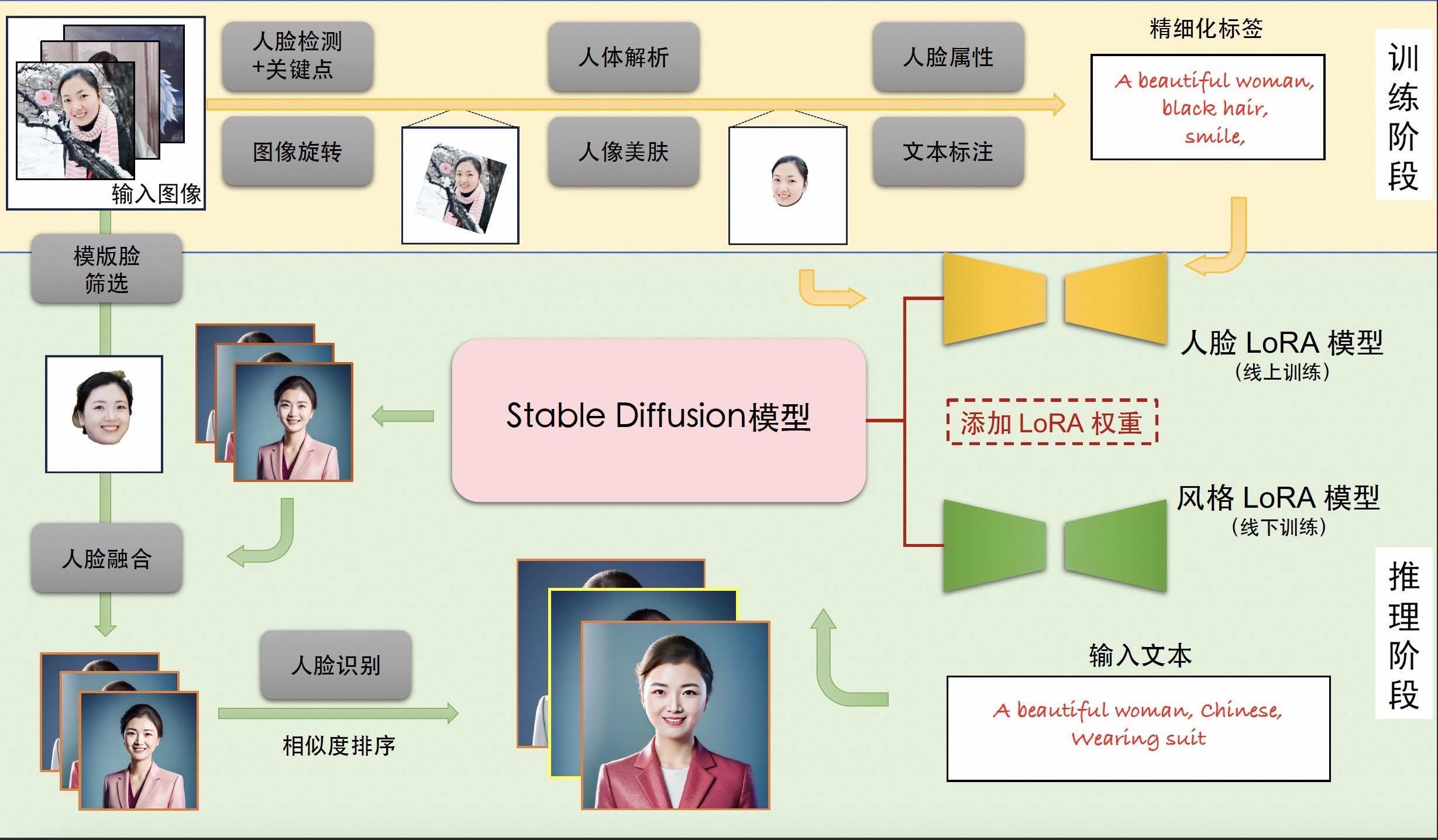
3.2訓練階段
輸入:使用者上傳的包含清晰人臉區域的影象
輸出:人臉LoRA模型
描述:首先,我們分別使用基於朝向判斷的影象旋轉模型,以及基於人臉檢測和關鍵點模型的人臉精細化旋轉方法處理使用者上傳影象,得到包含正向人臉的影象;接下來,我們使用人體解析模型和人像美膚模型,以獲得高質量的人臉訓練影象;隨後,我們使用人臉屬性模型和文字標註模型,結合標籤後處理方法,產生訓練影象的精細化標籤;最後,我們使用上述影象和標籤資料微調Stable Diffusion模型得到人臉LoRA模型。
3.3推斷階段
輸入:訓練階段使用者上傳影象,預設的用於生成個人寫真的輸入提示詞
輸出:個人寫真影象
描述:首先,我們將人臉LoRA模型和風格LoRA模型的權重融合到Stable Diffusion模型中;接下來,我們使用Stable Diffusion模型的文生圖功能,基於預設的輸入提示詞初步生成個人寫真影象;隨後,我們使用人臉融合模型進一步改善上述寫真影象的人臉細節,其中用於融合的模板人臉通過人臉質量評估模型在訓練影象中挑選;最後,我們使用臉部辨識模型計算生成的寫真影象與模板人臉的相似度,以此對寫真影象進行排序,並輸出排名靠前的個人寫真影象作為最終輸出結果。
3.4模型列表
附(流程圖中模型連結)
[1] 人臉檢測+關鍵點模型DamoFD:https://modelscope.cn/models/damo/cv_ddsar_face-detection_iclr23-damofd
[2] 影象旋轉模型:創空間內建模型
[3] 人體解析模型M2FP:https://modelscope.cn/models/damo/cv_resnet101_image-multiple-human-parsing
[4] 人像美膚模型ABPN:https://www.modelscope.cn/models/damo/cv_unet_skin_retouching_torch
[5] 人臉屬性模型FairFace:https://modelscope.cn/models/damo/cv_resnet34_face-attribute-recognition_fairface
[6] 文字標註模型Deepbooru:https://github.com/KichangKim/DeepDanbooru
[7] 模板臉篩選模型FQA:https://modelscope.cn/models/damo/cv_manual_face-quality-assessment_fqa
[8] 人臉融合模型:https://www.modelscope.cn/models/damo/cv_unet_face_fusion_torch
[9] 臉部辨識模型RTS:https://modelscope.cn/models/damo/cv_ir_face-recognition-ood_rts
[10] 人臉說話模型:https://modelscope.cn/models/wwd123/sadtalker
4.更多內容
- 測試圖片







- 部分效果


更多優質內容請關注公號:汀丶人工智慧;會提供一些相關的資源和優質文章,免費獲取閱讀。
