實戰0-1,Java開發者也能看懂的大模型應用開發實踐!!!
前言
在前幾天的文章《續寫AI技術新篇,融匯工程化實踐》中,我分享說在RAG領域,很多都是工程上的實踐,做AI大模型應用的開發其實Java也能寫,那麼本文就一個Java開發者的立場,構建實現一個最基礎的大模型應用系統。
而大模型應用系統其實在目前階段,可能應用最廣的還是RAG領域,因此,本文也是通過在RAG領域的基礎架構下,來實現應用的開發,主要需求點:讓大模型理解文字(知識庫)內容,基於知識庫範圍內的內容進行回答對話
而基於知識庫的回答會幫助我們解決哪些問題呢?
- ✅ 節省大模型訓練成本:我們知道ChatGPT的知識內容停留在2021年,最新的知識它並不知道,而檢索增強生成則可以解決大模型無法快速學習的問題,訓練大模型代價是非常昂貴的,不僅僅只是金錢,還包括時間,隨著模型的引數大小成本成正相關。
- ✅ 讓大模型更聰明:很多企業內部的私有資料大模型並沒有學習,而通過RAG的方式可以讓大模型在知識庫範圍的領域進行回答,避免胡說八道,基於底層大模型的基座,可以讓我們的應用系統看上去更加的聰明。
在本文中,你將學習到:
- ✅ RAG工程的基本處理框架流程(基於Java)
- ✅ 向量資料庫的基礎使用及瞭解
技術棧
考慮到作者也是Java開發者,因此本文所選擇的技術棧以及中介軟體也是Java人員都耳熟能詳的,主要技術棧如下:
1、開發框架:Spring Boot、Spring Shell(命令列對話)
Java開發者對於Spring Boot的生態應該是非常熟悉的,而選擇Spring Shell工具包主要是為了演示命令列的互動問答效果,和本次的技術無太大關係,算是一個最小雛形的產品互動體驗。
2、HTTP元件:OkHTTP、OkHTTP-SSE
此次我們選擇的大模型是以智譜AI開放的ChatGLM系列為主,因此我們需要HTTP元件和商業大模型的API進行介面的對接,當然開發者如果有足夠的條件,也是可以在本地部署開源大模型並且開放API介面進行偵錯的,這個並不衝突,本文只是為了方便演示效果,所以使用了智譜的大模型API介面,而智譜AI註冊後,預設提供了一個18元的免費Token消費額度,因此介面的API-Key只需要註冊一個即可快速獲取。
3、工具包:Hutool
非常好用的一個基礎工具包元件,封裝了很多工具類方法,包含字元、檔案、時間、集合等等
本文會使用到Hutool包的文字讀取和切割方法。
4、向量資料庫:ElasticSearch
向量資料庫是RAG應用程式的基礎中介軟體,所有的文字Embedding向量都需要儲存在向量資料庫中介軟體中進行召回計算,當然在Java領域並沒有類似Python中numpy這類在地化工具元件包,即可快速實現矩陣計算等需求(PS:最近Java21的釋出中,不僅僅只是虛擬執行緒等新特性,提供的向量API相信在未來AI領域,Java也會有一席之地的),所以選擇了獨立部署的中介軟體。
本文選擇ElasticSearch可能對於Java開發人員也是比較熟悉的一個元件,畢竟ES在Java領域用途還是非常廣的,只是可能很多開發者並不知道ElasticSearch居然還有儲存向量資料的功能?
對於向量資料庫中介軟體的選擇,目前市面上有非常多的向量資料庫,包括:Milvus、Qdrant、Postgres(pgvector)、Chroma 等等,Java開發者可以在熟悉當前流程後,根據自己的實際需求,選擇符合企業生產環境的向量資料庫。
5、LLM大模型:ChatGLM-Std
為了演示方便,本文直接使用開放API介面的商業大模型,智譜AI提供的ChatGLM-Std
RAG工程的基本處理流程
在RAG檢索增強生成領域中,最簡單的核心處理流程架構圖如下:
該架構圖圖是一個非常簡單的流程圖,在RAG領域中其實有非常多的處理細節,當我們深入瞭解後就會知道
我們後續根據該圖來進行Java編碼實現。
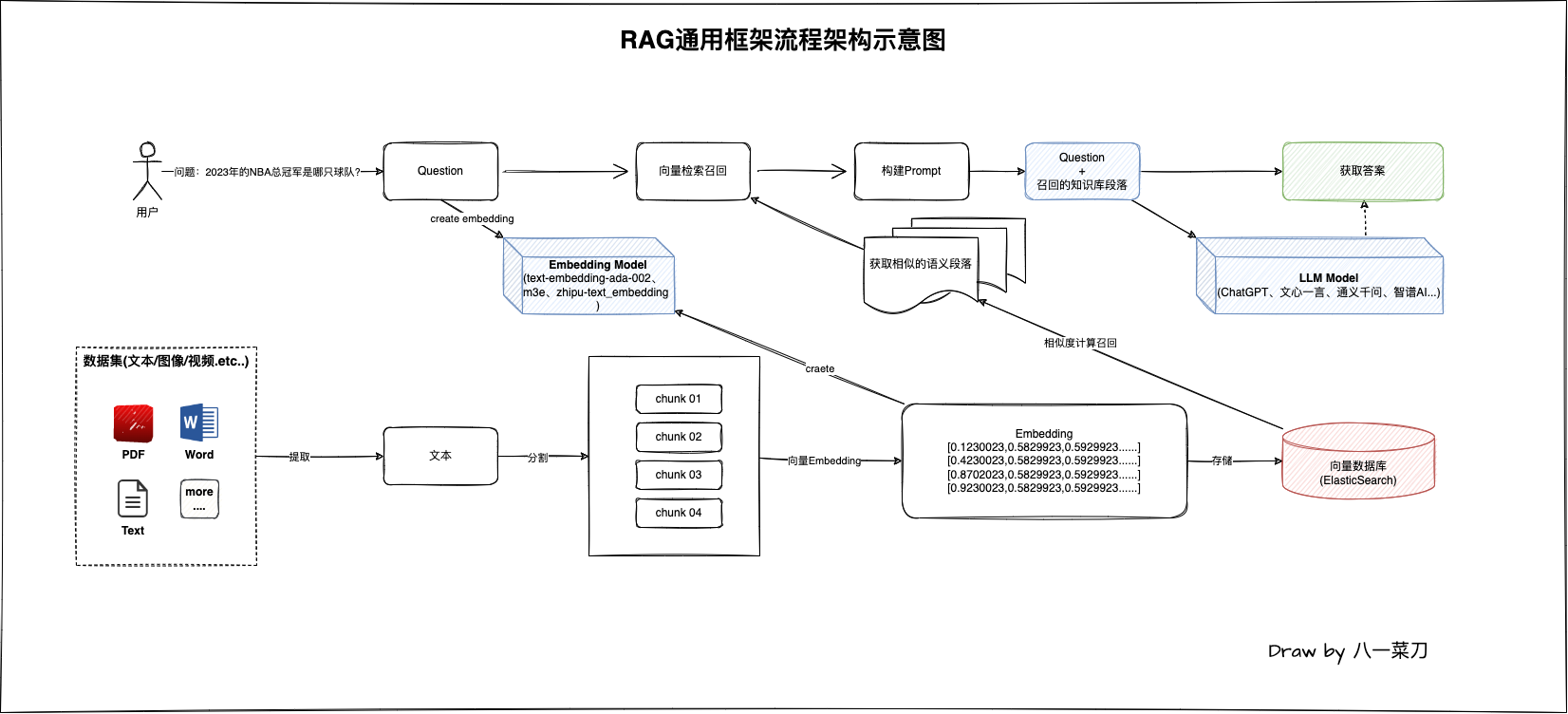
在RAG應用工程領域,其實整個程式的處理包含兩部分:
- 問答:對使用者提問的問題通過向量
Embedding模型處理,然後通過查詢向量資料庫(ElasticSearch)進行相似度計算獲取和使用者問題最相似的知識庫段落內容,獲取成功後,構建Prompt,最終傳送給大模型獲取最終的答案。 - 資料處理:資料的處理是將使用者私有的資料進行提取,包括各種結構化及非結構化資料(例如
PDF/Word/Text等等),提取文字資料後進行分割處理,最終通過向量Embedding模型將這些分割後的段落進行向量化,最終向量資料儲存在基礎設施向量資料庫元件中,以供後續的問答流程使用。
從圖中我們可以知道,在我們所需要的大模型處於什麼位置,以及它的作用,主要是兩個模型的應用:
- 向量Embedding模型:對我們本地知識的向量表徵處理,將文字內容轉化為便於計算機理解的向量表示
- LLM問答大模型:大模型負責將我們通過語意召回的段落+使用者的問題結合,構建的
Prompt送給大模型以獲取最終的答案,問答大模型在這裡充當的角色是理解我們送給他的內容,然後進行精準回答
Java編碼實踐
我們理解了基礎的架構流程,接下來就是編碼實現了
環境準備
Java:JDK 1.8
ElasticSearch:7.16.1
對於ElasticSearch的安裝,可以通過docker-compose在本地快速部署一個
編寫docker-compose.yml組態檔,當前部署目錄建data資料夾掛載資料目錄
version: "3"
services:
elasticsearch:
image: elasticsearch:7.16.1
ports:
- "9200:9200"
- "9300:9300"
environment:
node.name: es
cluster.name: elasticsearch
discovery.type: single-node
ES_JAVA_OPTS: -Xms4096m -Xmx4096m
volumes:
- ./data:/usr/share/elasticsearch/data
deploy:
resources:
limits:
cpus: "4"
memory: 5G
reservations:
cpus: "1"
memory: 2G
restart: always
啟動Es:docker-compose up -d
應用初體驗
先來看整個程式的應用效果,通過Spring Shell環境下,程式啟動後,如下圖所示:
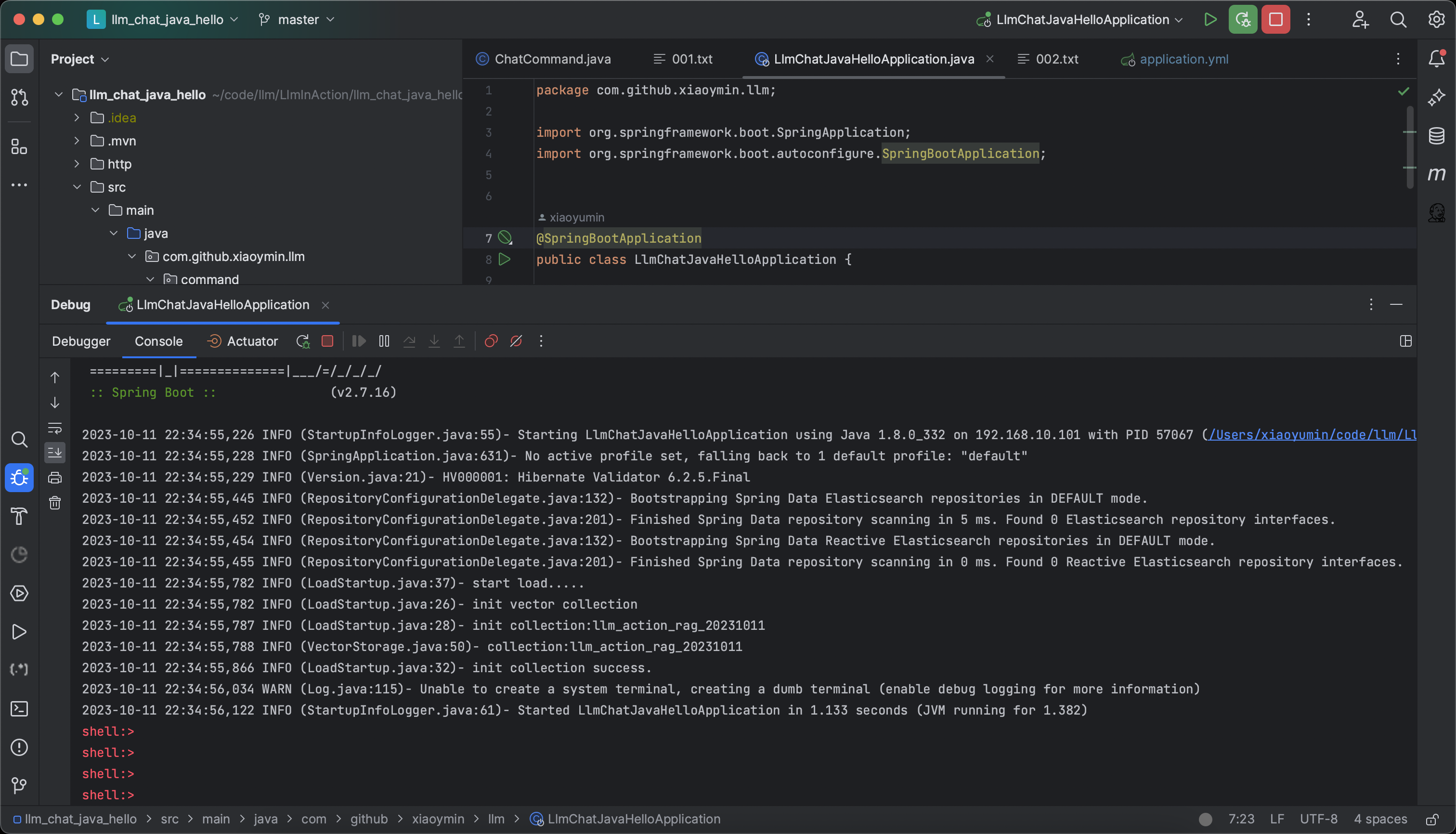
程式啟動後,在命令列終端,我們可以看到一個可互動的命令列,此時,我們可以通過add和chat兩個命令完成圖1中的整個流程
先使用add命令載入檔案,在data目錄下分別儲存了001.txt、002.txt兩個檔案,通過命令載入向量處理,如下圖:
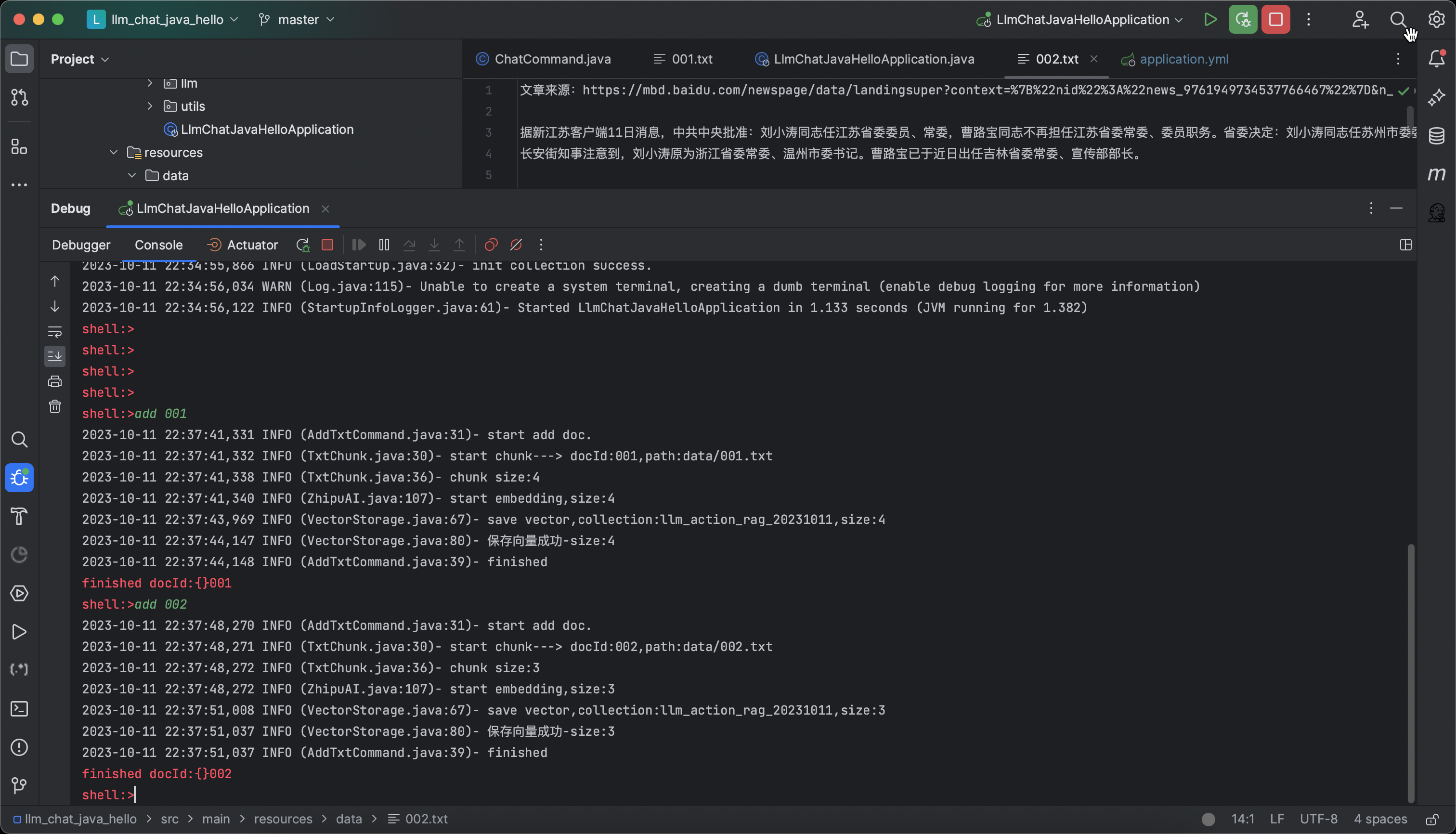
當紀錄檔顯示儲存向量成功後,此時,我們即可以通過chat命令進行對話了,我們先來看看002.txt的文字主要說了什麼內容?
data目錄下的文字,開發者在偵錯時可以自己隨意新增,網上隨便找的文章都可以
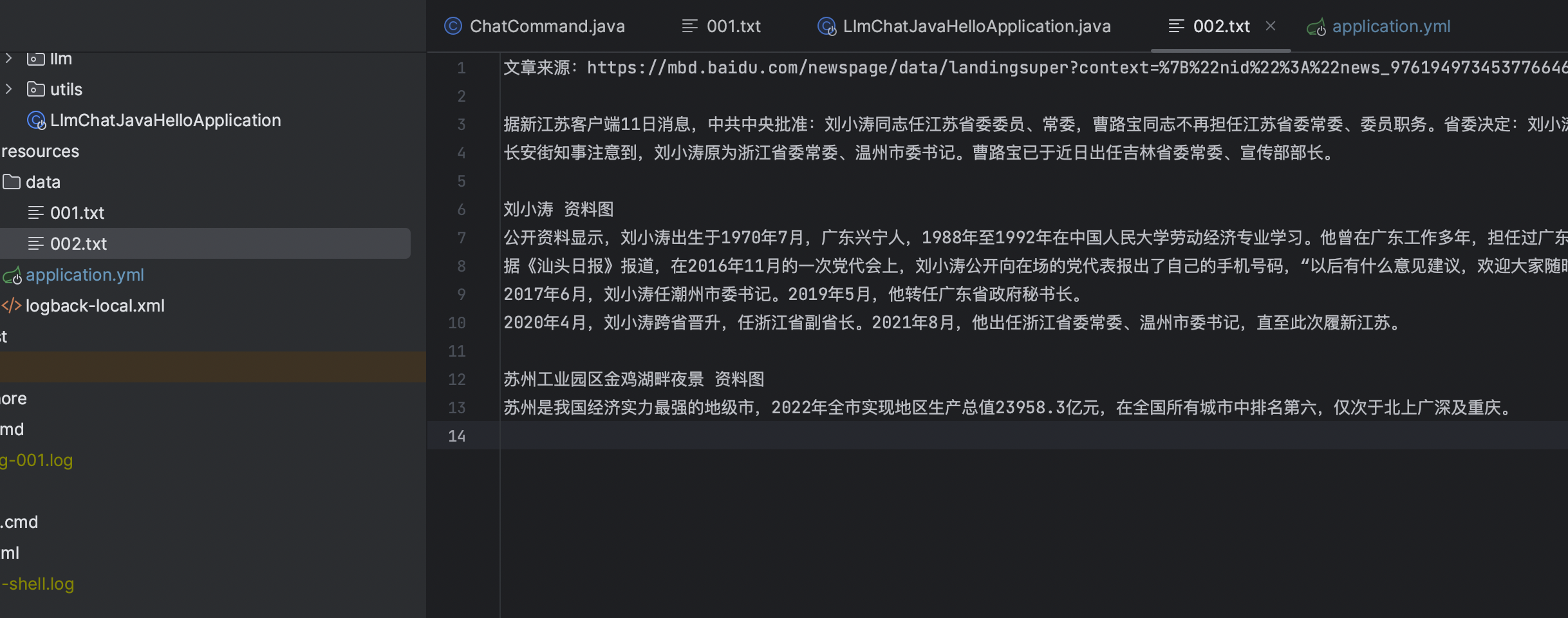
文章內容是一篇非常具有代表性的時政人物介紹新聞,那麼我們就根據該文章的內容進行問答!
問題1:蘇州2022年全市的GDP是多少?
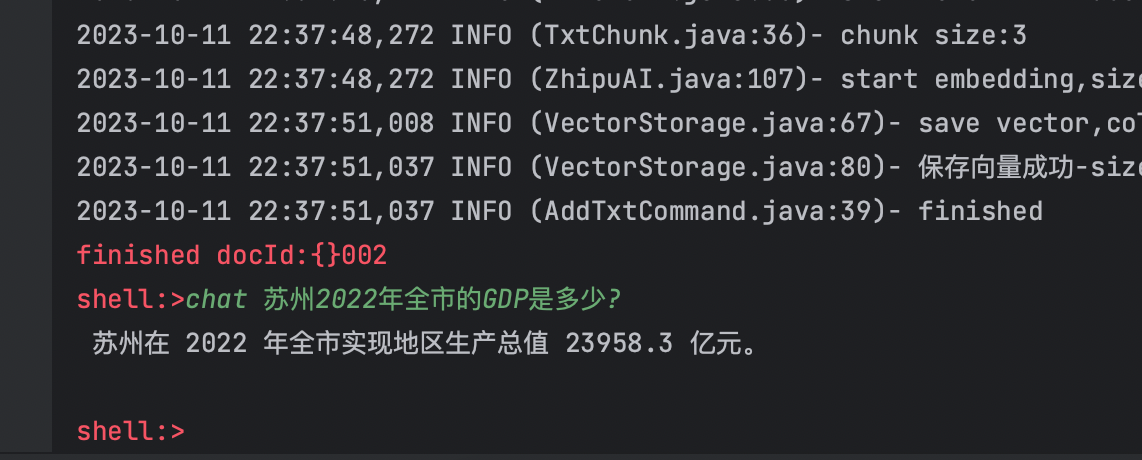
問題2:吉林省宣傳部部長現在是誰?
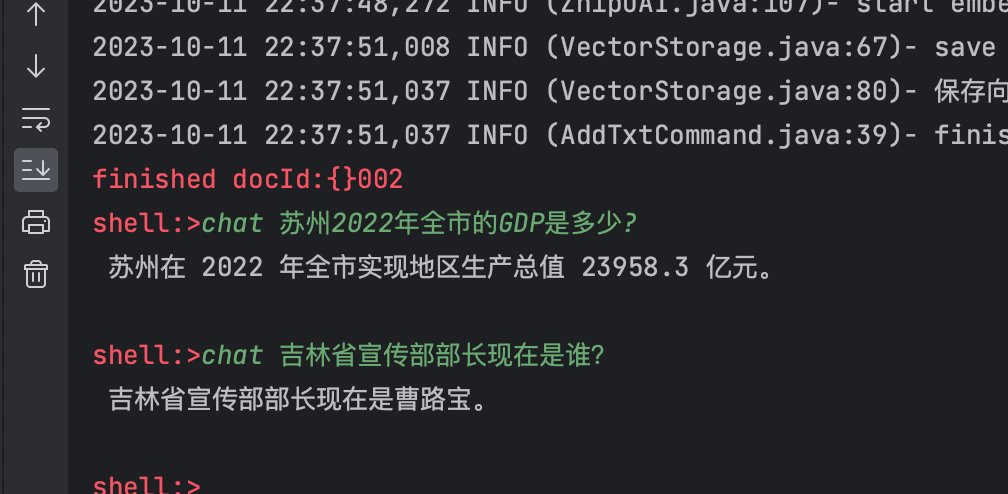
通過第一個問題,你是否可以發現問題呢?,如果你問ChatGPT一樣的問題,它能準確回答嗎?
以下是ChatGPT的回答
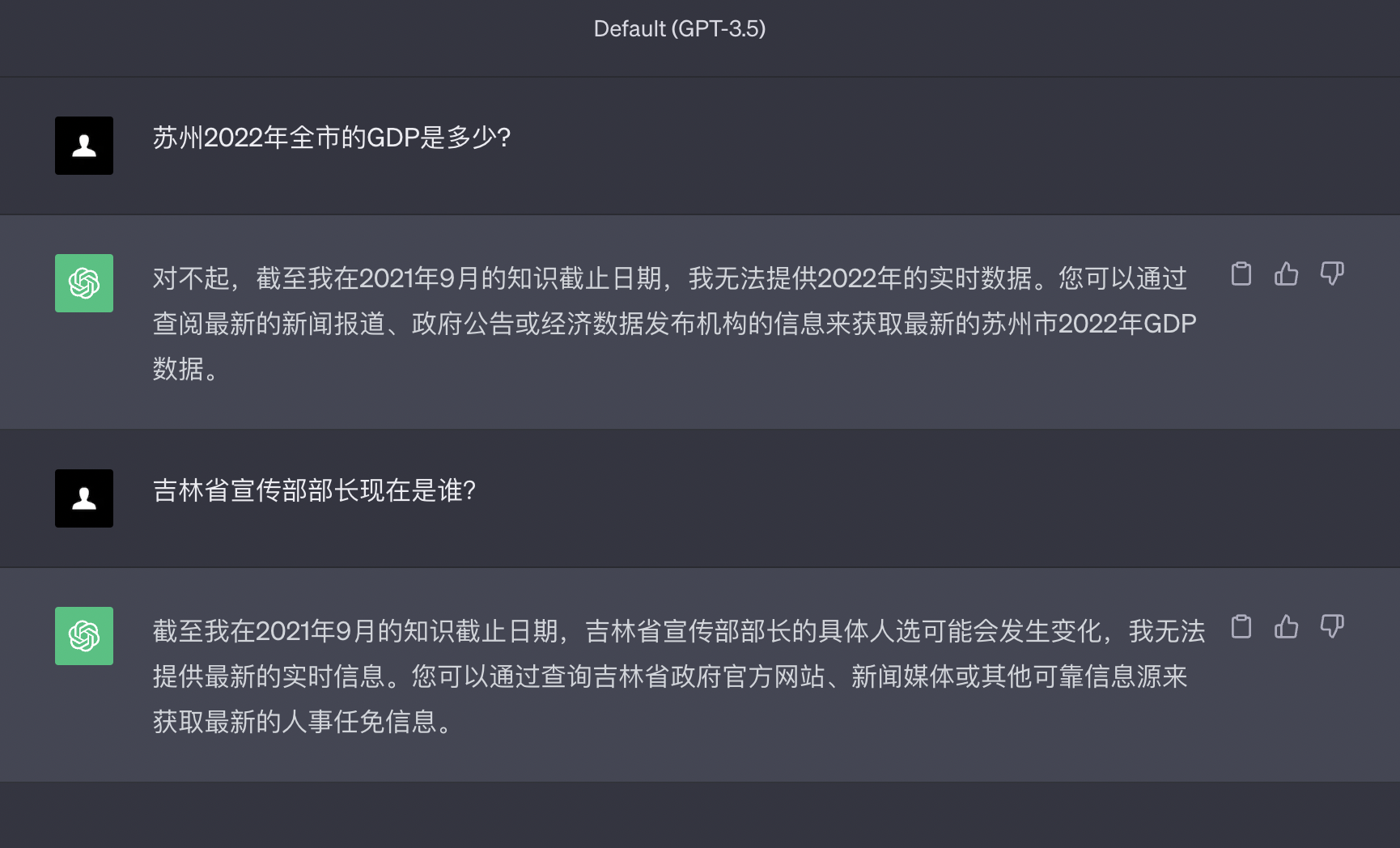
通過對比ChatGPT,開發者應該能看到一個基礎的對比效果,主要體現:
- 我們都知道ChatGPT大模型的內容日期截止到2021年,之後世界發生了什麼,它並不知道,同類的GPT大模型也會出現一樣的問題,因為訓練大模型的代價是非常昂貴的,不可能按周、月,甚至是年的頻率去更新大模型。
- 基於現有的知識回答內容(RAG),能夠有效的避免大模型胡說八道,而且回答的更精準
技術實現
進行問答體驗後,我們來看具體的Java程式碼實現。
新建Spring Boot專案,工程目錄如下:
GitHub:https://github.com/xiaoymin/LlmInAction/tree/master/llm_chat_java_hello
從上文的RAG流程圖中,我們知道了主要分兩個步驟來實現,分別是資料的向量處理和問答
由於是通過Spring Shell進行實現,因此這裡我也分開,主要實現了兩個Command命令:
- add:在data目錄下,為了演示需要,存放了兩個txt內容,可以通過
add file名稱來實現檔案的向量化流程載入處理,資料的處理開發者在實際的生產過程中可以通過定時任務、MQ訊息等方式進行非同步處理。 - chat:通過命令
chat 問題即可在Spring Shell的命令列終端進行對話,可以問data目錄下相關的問題
為了方便後續的處理,程式啟動時即會自動構建向量資料庫的索引集合,程式碼如下:
/**
* 初始化向量資料庫index
* @param collectionName 名稱
* @param dim 維度
*/
public boolean initCollection(String collectionName,int dim){
log.info("collection:{}", collectionName);
// 檢視向量索引是否存在,此方法為固定預設索引欄位
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(collectionName));
if (!indexOperations.exists()) {
// 索引不存在,直接建立
log.info("index not exists,create");
//建立es的結構,簡化處理
Document document = Document.from(this.elasticMapping(dim));
// 建立
indexOperations.create(new HashMap<>(), document);
return true;
}
return true;
}
Es中的Index的Mapping結構如下:

開發者需要注意vector欄位,欄位型別時dense_vector,並且指定向量維度為1024
向量維度的長度指定是和最終向量Embedding模型息息相關的,不同的模型有不同的維度,比如ChatGPT的向量模型維度是1536,百度文心一言也有368的,因此根據實際情況進行選擇。
而這裡因為我們選擇的是智譜AI的向量模型,該模型返回的維度為1024,那麼我們在向量資料庫的維度就設定為1024
首先是add命令實現檔案的向量化過程處理,程式碼如下:
@Slf4j
@AllArgsConstructor
@ShellComponent
public class AddTxtCommand {
final TxtChunk txtChunk;
final VectorStorage vectorStorage;
final ZhipuAI zhipuAI;
@ShellMethod(value = "add local txt data")
public String add(String doc){
log.info("start add doc.");
// 載入
List<ChunkResult> chunkResults= txtChunk.chunk(doc);
// embedding
List<EmbeddingResult> embeddingResults=zhipuAI.embedding(chunkResults);
// store vector
String collection= vectorStorage.getCollectionName();
vectorStorage.store(collection,embeddingResults);
log.info("finished");
return "finished docId:{}"+doc;
}
}
我們完全按照圖1RAG的流程架構圖進行程式碼的變現,主要的步驟:
1、載入指定的檔案,並且將檔案內容進行分割處理(按固定size大小進行分割處理),得到分割集合chunkResults,程式碼如下:
@Slf4j
@Component
@AllArgsConstructor
public class TxtChunk {
public List<ChunkResult> chunk(String docId){
String path="data/"+docId+".txt";
log.info("start chunk---> docId:{},path:{}",docId,path);
// 讀取data目錄下的檔案流
ClassPathResource classPathResource=new ClassPathResource(path);
try {
// 讀取為文字
String txt=IoUtil.read(classPathResource.getInputStream(), StandardCharsets.UTF_8);
//按固定字數分割,256
String[] lines=StrUtil.split(txt,256);
log.info("chunk size:{}", ArrayUtil.length(lines));
List<ChunkResult> results=new ArrayList<>();
//此處給每個檔案一個固定的chunkId
AtomicInteger atomicInteger=new AtomicInteger(0);
for (String line:lines){
ChunkResult chunkResult=new ChunkResult();
chunkResult.setDocId(docId);
chunkResult.setContent(line);
chunkResult.setChunkId(atomicInteger.incrementAndGet());
results.add(chunkResult);
}
return results;
} catch (IOException e) {
log.error(e.getMessage());
}
return new ArrayList<>();
}
}
2、將分塊的集合通過智譜AI提供的向量Embedding模型進行向量化處理,程式碼實現如下:
/**
* 批次
* @param chunkResults 批次文字
* @return 向量
*/
public List<EmbeddingResult> embedding(List<ChunkResult> chunkResults){
log.info("start embedding,size:{}",CollectionUtil.size(chunkResults));
if (CollectionUtil.isEmpty(chunkResults)){
return new ArrayList<>();
}
List<EmbeddingResult> embeddingResults=new ArrayList<>();
for (ChunkResult chunkResult:chunkResults){
//分別處理
embeddingResults.add(this.embedding(chunkResult));
}
return embeddingResults;
}
public EmbeddingResult embedding(ChunkResult chunkResult){
//獲取智譜AI的開發Key
String apiKey= this.getApiKey();
// 初始化http使用者端
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.connectTimeout(20000, TimeUnit.MILLISECONDS)
.readTimeout(20000, TimeUnit.MILLISECONDS)
.writeTimeout(20000, TimeUnit.MILLISECONDS)
.addInterceptor(new ZhipuHeaderInterceptor(apiKey));
OkHttpClient okHttpClient = builder.build();
EmbeddingResult embedRequest=new EmbeddingResult();
embedRequest.setPrompt(chunkResult.getContent());
embedRequest.setRequestId(Objects.toString(chunkResult.getChunkId()));
// 智譜embedding模型介面
Request request = new Request.Builder()
.url("https://open.bigmodel.cn/api/paas/v3/model-api/text_embedding/invoke")
.post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), GSON.toJson(embedRequest)))
.build();
try {
Response response= okHttpClient.newCall(request).execute();
String result=response.body().string();
ZhipuResult zhipuResult= GSON.fromJson(result, ZhipuResult.class);
EmbeddingResult ret= zhipuResult.getData();
ret.setPrompt(embedRequest.getPrompt());
ret.setRequestId(embedRequest.getRequestId());
return ret;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
3、向量處理成功後,我們即可將向量資料儲存在向量資料庫中介軟體(ElasticSearch)中,呼叫vectorStorage.store處理,程式碼如下:
public void store(String collectionName,List<EmbeddingResult> embeddingResults){
//儲存向量
log.info("save vector,collection:{},size:{}",collectionName, CollectionUtil.size(embeddingResults));
List<IndexQuery> results = new ArrayList<>();
for (EmbeddingResult embeddingResult : embeddingResults) {
ElasticVectorData ele = new ElasticVectorData();
ele.setVector(embeddingResult.getEmbedding());
ele.setChunkId(embeddingResult.getRequestId());
ele.setContent(embeddingResult.getPrompt());
results.add(new IndexQueryBuilder().withObject(ele).build());
}
// 構建封包
List<IndexedObjectInformation> bulkedResult = elasticsearchRestTemplate.bulkIndex(results, IndexCoordinates.of(collectionName));
int size = CollectionUtil.size(bulkedResult);
log.info("儲存向量成功-size:{}", size);
}
}
至此,整個文字資料的Embedding處理就完成了。
資料處理完成後,接下來我們需要實現問答chat命令,來看程式碼實現:
@AllArgsConstructor
@Slf4j
@ShellComponent
public class ChatCommand {
final VectorStorage vectorStorage;
final ZhipuAI zhipuAI;
@ShellMethod(value = "chat with files")
public String chat(String question){
if (StrUtil.isBlank(question)){
return "You must send a question";
}
//句子轉向量
double[] vector=zhipuAI.sentence(question);
// 向量召回
String collection= vectorStorage.getCollectionName();
String vectorData=vectorStorage.retrieval(collection,vector);
if (StrUtil.isBlank(vectorData)){
return "No Answer!";
}
// 構建Prompt
String prompt= LLMUtils.buildPrompt(question,vectorData);
zhipuAI.chat(prompt);
// 大模型對話
//return "you question:{}"+question+"finished.";
return StrUtil.EMPTY;
}
}
Chat命令主要包含的步驟如下:
1、將使用者的問句首先通過向量Embedding模型轉化得到一個多維的浮點型向量陣列,程式碼如下:
/**
* 獲取句子的向量
* @param sentence 句子
* @return 向量
*/
public double[] sentence(String sentence){
ChunkResult chunkResult=new ChunkResult();
chunkResult.setContent(sentence);
chunkResult.setChunkId(RandomUtil.randomInt());
EmbeddingResult embeddingResult=this.embedding(chunkResult);
return embeddingResult.getEmbedding();
}
2、根據向量資料查詢向量資料庫召回相似的段落內容,vectorStorage.retrieval方法程式碼如下:
public String retrieval(String collectionName,double[] vector){
// Build the script,查詢向量
Map<String, Object> params = new HashMap<>();
params.put("query_vector", vector);
// 計算cos值+1,避免出現負數的情況,得到結果後,實際score值在減1再計算
Script script = new Script(ScriptType.INLINE, Script.DEFAULT_SCRIPT_LANG, "cosineSimilarity(params.query_vector, 'vector')+1", params);
ScriptScoreQueryBuilder scriptScoreQueryBuilder = new ScriptScoreQueryBuilder(QueryBuilders.boolQuery(), script);
// 構建請求
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(scriptScoreQueryBuilder)
.withPageable(Pageable.ofSize(3)).build();
SearchHits<ElasticVectorData> dataSearchHits = this.elasticsearchRestTemplate.search(nativeSearchQuery, ElasticVectorData.class, IndexCoordinates.of(collectionName));
//log.info("檢索成功,size:{}", dataSearchHits.getTotalHits());
List<SearchHit<ElasticVectorData>> data = dataSearchHits.getSearchHits();
List<String> results = new LinkedList<>();
for (SearchHit<ElasticVectorData> ele : data) {
results.add(ele.getContent().getContent());
}
return CollectionUtil.join(results,"");
}
這裡主要利用了ElasticSearch提供的cosineSimilarity餘弦相似性函數,計算向量得到相似度的分值,分值會在區間[0,1]之間,如果無限趨近於1那麼代表使用者輸入的句子和之前我們儲存在向量中的句子是非常相似的,越相似代表我們找到了語意相近的檔案內容,可以作為最終構建大模型Prompt的基礎內容。
向量矩陣的計算除了餘弦相似性,還有IP點積、歐幾里得距離等等,根據實際情況選擇不同的演演算法實現。
3、向量召回Top3得到相似的語意文字內容後,我們就可以構建Prompt了,並且傳送給大模型,Prompt如下:
public static String buildPrompt(String question,String context){
return "請利用如下上下文的資訊回答問題:" + "\n" +
question + "\n" +
"上下文資訊如下:" + "\n" +
context + "\n" +
"如果上下文資訊中沒有幫助,則不允許胡亂回答!";
}
而在構建Prompt時,我們可以遵循一個最簡單的框架正規化,RTF框架(Role-Task-Format):
- R-Role:指定GPT大模型擔任特定的角色
- T-Task:任務,需要大模型做的事情
- F-Format:大模型返回的內容格式(常規情況下可以忽略)
4、最後是呼叫大模型,實現sse流式呼叫輸出,程式碼如下:
public void chat(String prompt){
try {
OkHttpClient.Builder builder = new OkHttpClient.Builder()
.connectTimeout(20000, TimeUnit.MILLISECONDS)
.readTimeout(20000, TimeUnit.MILLISECONDS)
.writeTimeout(20000, TimeUnit.MILLISECONDS)
.addInterceptor(new ZhipuHeaderInterceptor(this.getApiKey()));
OkHttpClient okHttpClient = builder.build();
ZhipuChatCompletion zhipuChatCompletion=new ZhipuChatCompletion();
zhipuChatCompletion.addPrompt(prompt);
// 取樣溫度,控制輸出的隨機性,必須為正數
// 值越大,會使輸出更隨機,更具創造性;值越小,輸出會更加穩定或確定
zhipuChatCompletion.setTemperature(0.7f);
zhipuChatCompletion.setTop_p(0.7f);
EventSource.Factory factory = EventSources.createFactory(okHttpClient);
ObjectMapper mapper = new ObjectMapper();
String requestBody = mapper.writeValueAsString(zhipuChatCompletion);
Request request = new Request.Builder()
.url("https://open.bigmodel.cn/api/paas/v3/model-api/chatglm_std/sse-invoke")
.post(RequestBody.create(MediaType.parse(ContentType.JSON.getValue()), requestBody))
.build();
CountDownLatch countDownLatch=new CountDownLatch(1);
// 建立事件,控制檯輸出
EventSource eventSource = factory.newEventSource(request, new ConsoleEventSourceListener(countDownLatch));
countDownLatch.await();
} catch (Exception e) {
log.error("llm-chat異常:{}", e.getMessage());
}
}
SSE流式的呼叫我們使用了okhttp-sse元件提供的功能快速實現。
好了,整個工程層面的Java程式碼實現就已經全部完成了。
最後
以上就是本片分享的全部內容了,通過Java開發語言,實現一個最小可用級別的RAG大模型應用!相信你看完本文後,也能夠對AI大模型應用的開發有一個基本的瞭解。
如果你也在關注大模型、RAG檢索增強生成技術,歡迎關注我,一起探索學習、成長~!

附錄
本文程式碼Github:https://github.com/xiaoymin/LlmInAction
智譜AI:https://open.bigmodel.cn/