機器學習即程式碼的時代已經到來
譯者注: 到底是 AI 會吃掉軟體還是軟體會吃掉 AI?為了 job security 工程師應該把寶押在哪兒?這篇 2021 年的文章提供的一些視角似乎印證了它現在的流行,有點「運籌於帷幄之中,決勝於數年之後」的意思,頗值得軟體架構師和產品經理們內省一番。
2021 版的 《人工智慧現狀報告》 於上週釋出。Kaggle 的 機器學習和資料科學現狀調查 也於同一周釋出了。這兩份報告中有很多值得學習和探討的內容,其中一些要點引起了我的注意。
「人工智慧正越來越多地應用於關鍵基礎設施,如國家電網以及新冠大流行期間的自動化超市倉儲計算。然而,人們也在質疑該行業的成熟度是否趕上了其不斷增長的部署規模。」
無可否認,以機器學習引擎的應用正滲透至 IT 的每個角落。但這對公司和組織意味著什麼?我們如何構建堅如磐石的機器學習工作流?每個公司應該聘請 100 名資料科學家抑或是 100 名 DevOps 工程師嗎?
「Transformer 模型已成為 ML 的通用架構。不僅適用於自然語言處理,還適用於語音、計算機視覺甚至蛋白質結構預測。」
老一輩人的血淚教訓是: IT 領域 沒有萬能靈丹。然而,transformer 架構又確實在各式各樣的機器學習任務中都非常有效。但我們如何才能跟上機器學習創新的瘋狂腳步呢?我們真的需要專家級的技能才能用上這些最先進的模型嗎?抑或是否有更短的路徑可以在更短的時間內創造商業價值?
好,以下是我的一些想法。
面向大眾的機器學習!
機器學習無處不在,或者至少它試圖無處不在。幾年前,福布斯寫道「軟體吞噬了世界,而現在人工智慧正在吞噬軟體」,但這到底意味著什麼?如果這意味著機器學習模型應該取代數千行僵化的遺留程式碼,那麼我完全贊成。去死,邪惡的商業規則,去死!
現在,這是否意味著機器學習實際上將取代軟體工程?現在肯定有很多關於 人工智慧生成的程式碼 的幻想,其中一些技術確實很有趣,例如用於 找出 bug 和效能問題 的技術。然而,我們不僅不應該考慮擺脫開發人員,還應該努力為儘可能多的開發人員提供支援,以使機器學習成為另一個無聊的 IT 工作負載 (但 無聊的技術很棒)。換句話說,我們真正需要的是軟體吃掉機器學習!
這次情況沒有什麼不同
多年來,我一直在虛張聲勢地宣稱: 軟體工程已有的長達十年曆史的最佳實踐同樣適用於資料科學和機器學習: 版本控制、可重用性、可測試性、自動化、部署、監控、效能、優化等。我一度感覺自己很孤單,直到谷歌鐵騎的出現:
「做你擅長的,以卓越工程師的身份而不是以卓越機器學習專家的身份去做機器學習。」 - 《機器學習的規則》,Google
沒有必要重新發明輪子。DevOps 運動在 10 多年前就解決了這些問題。現在,資料科學和機器學習社群應該立即採用這些經過驗證的工具和流程並作適當調整。這是我們在生產中構建強大、可延伸、可重複的機器學習系統的唯一方法。如果將其稱為 MLOps 對事情有幫助,那就這麼叫它!關鍵是其內涵,名字並不重要。
確實是時候停止將概念驗證和沙箱 A/B 測試視為顯著成就了。它們只是邁向生產的一小塊墊腳石,即它是唯一可以驗證假設及其對業務的影響的地方。每個資料科學家和機器學習工程師都應該致力於儘可能快、儘可能頻繁地將他們的模型投入生產。 能用的生產模型無一例外都比出色的沙箱模型好。
基礎設施?所以呢?
都 2021 年了,IT 基礎設施不應再成為阻礙。軟體不久前已經吞噬了它,通過雲 API、基礎設施即程式碼、Kubeflow 等將其抽象化。是的,即使是自建基礎設施也已經被軟體吞噬了。
機器學習基礎設施也很快就會發生同樣的情況。 Kaggle 調查顯示,75% 的受訪者使用雲服務,超過 45% 的受訪者使用企業機器學習平臺,其中 Amazon SageMaker、Databricks 和 Azure ML Studio 位列前三。

藉助 MLOps、軟體定義的基礎設施和平臺,將任意一個偉大的想法從沙箱中拖出來並將其投入生產已變得前所未有地容易。回答最開始的問題,我很確定你需要僱用更多精通 ML 的軟體和 DevOps 工程師,而不是更多的資料科學家。但其實在內心深處,你本來就知道這一點,對嗎?
現在,我們來談談 transformer 模型。
Transformers! Transformers! Transformers! (鮑爾默風格)
AI 現狀報告稱: 「Transformer 架構已經遠遠超出了 NLP 的範圍,並且正在成為 ML 的通用架構」。例如,最近的模型,如 Google 的 Vision Transformer、無折積 transformer 架構以及混合了 transformer 和折積的 CoAtNet 為 ImageNet 上的影象分類設定了新的基準,同時對訓練計算資源的需求更低。
Transformer 模型在音訊 (如語音識別) 以及點雲 (一種用於對自動駕駛場景等 3D 環境進行建模的技術) 方面也表現出色。
Kaggle 的調查也呼應了 transformer 模型的崛起。它們的使用量逐年增長,而 RNN、CNN 和梯度提升演演算法則在減少。
除了提高準確性之外,transformer 模型也在持續加強其在遷移學習方面的能力,這樣大家就可以節約訓練時間和計算成本,更快地實現業務價值。
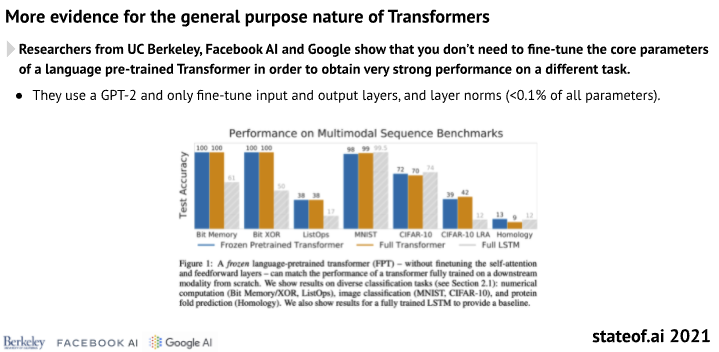
藉助 transformer 模型,機器學習世界正逐漸從「 好!!讓我們從頭開始構建和訓練我們自己的深度學習模型 」轉變為「 讓我們選擇一個經過驗證的現成模型,用我們自己的資料對其進行微調,然後早點回家吃晚飯。 」
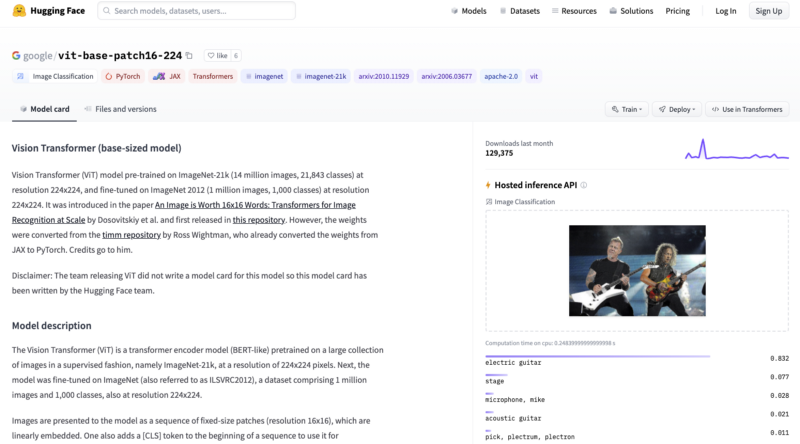
從很多方面來說,這都是一件好事。技術水平在不斷進步,幾乎沒有人能跟上其步伐。還記得我之前提到的 Google Vision Transformer 模型嗎?你想現在就測試一下嗎?在 Hugging Face 上,這 再簡單不過了。
那如果想試試 Big Science 專案 最新的 零樣本文字生成模型 呢?

你還可以對另外 16000 多個模型 以及 1600 多個資料集 做同樣的事情。進一步地,你還可以用我們提供的其他工具進行 推理、AutoNLP、延遲優化 及 硬體加速。我們甚至還能幫你啟動專案,完成 從建模到生產 的全過程。
Hugging Face 的使命是讓機器學習對初學者和專家來說都儘可能友好且高效。
我們相信你只要編寫儘可能少的程式碼就能訓練、優化和部署模型。
我們相信內建的最佳實踐。
我們堅信基礎設施應儘可能透明。
我們相信,沒有什麼比快速高質的生產級模型更好的了。
機器學習即程式碼,就這裡,趁現在!
大家似乎都同意這句話。我們的 Github 有超過 52000 顆星。在 Hugging Face 首次出現在 Kaggle 調查報告中時,其使用率就已超過 10%。

謝謝你們,我們才剛剛開始!
對 Hugging Face 如何幫助你的組織構建和部署生產級機器學習解決方案感興趣?請通過 [email protected] 聯絡我 (招聘、推銷勿擾)。
英文原文: https://hf.co/blog/the-age-of-ml-as-code
原文作者: Julien Simon
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態資料上的應用及大規模模型的訓練推理。
審校/排版: zhongdongy (阿東)