ChatGPT 是如何產生心智的?
一、前言 - ChatGPT真的產生心智了嗎?
來自斯坦福大學的最新研究結論,一經發出就造成了學術圈的轟動,「原本認為是人類獨有的心智理論(Theory of Mind,ToM),已經出現在ChatGPT背後的AI模型上」。所謂心智理論,就是理解他人或自己心理狀態的能力,包括同理心、情緒、意圖等。這項研究中,作者發現:davinci-002版本的GPT3已經可以解決70%的心智理論任務,相當於7歲兒童。

.2023 年,面對鋪天蓋地的 AI 應用,我們人類終於意識到,有一些東西被永遠的改變了。但在這波 AI 熱潮之中,只有一個應用是真正嚇人的——ChatGPT。由於心智無法通過量化評判,但ChatGPT確實滿足智慧的定義,例如推理、計劃、解決問題、抽象思考、理解複雜想法、快速學習。但ChatGPT本質上只做一件事情:續寫。當我們給出前N個詞彙的時候,如果一個模型能夠告訴我們第「N+1」個詞彙大概率會是什麼,我們就認為模型掌握了語言的基本規律。

為什麼光憑「續寫」就可以產生智慧?以下是摘自知乎的一段回答:
「為什麼這麼一個簡單的接話茬能力讓ChatGPT看起來能夠解決各種各樣的任務呢?因為我們人類大部分的任務都是以語言為載體的。當我們前面說了一些話,它把接下來的話接上,任務就完成了。ChatGPT作為一個大語言模型,目的就是「把話接上」,而把話接上這件事情可以在不知不覺中幫我們完成各種任務。」,這也解釋了為什麼ChatGPT有時候瞎胡謅,他並沒有撒謊,他不知道對錯,他只是想把對話順利進行下去。
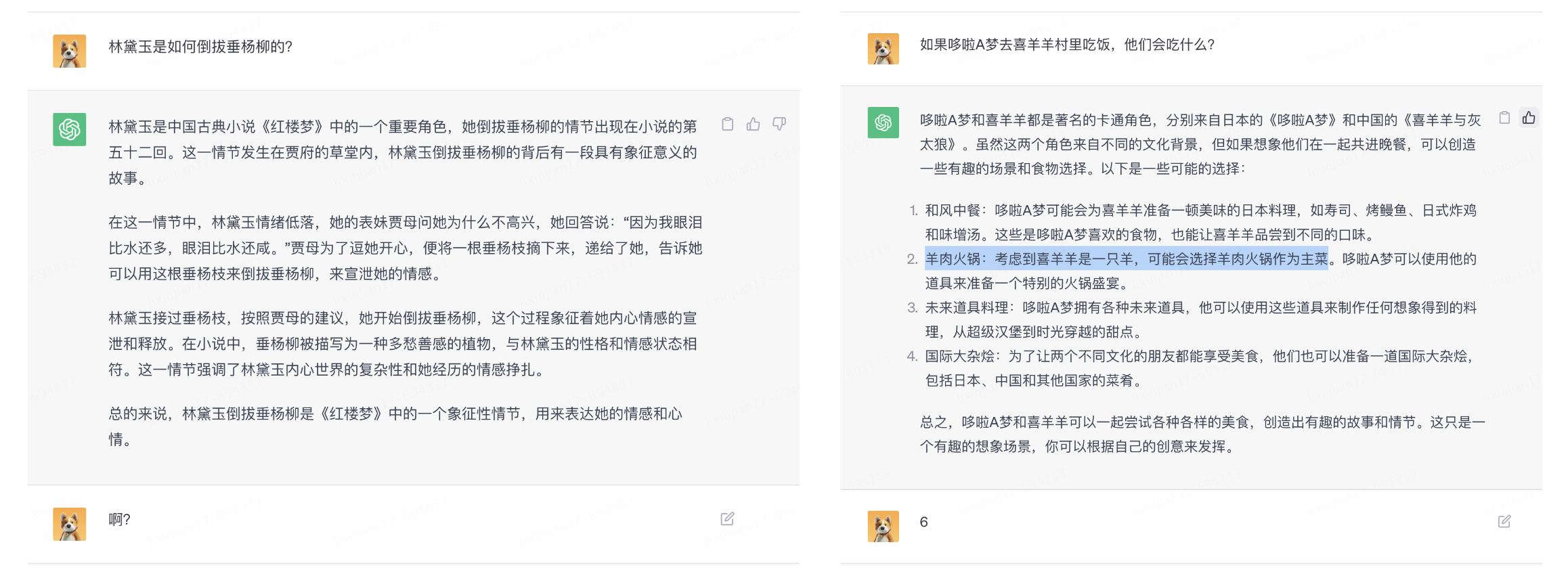
如果真的像上述所說,那GPT似乎沒有我們想象的神奇,看起來只是一個基於巨量資料和統計學的語言模型,通過它學習的海量文字預測下一個概率最高的詞。就像是有一個容量巨大的「資料庫」,所有的回答都是從這個資料庫裡拿到的。
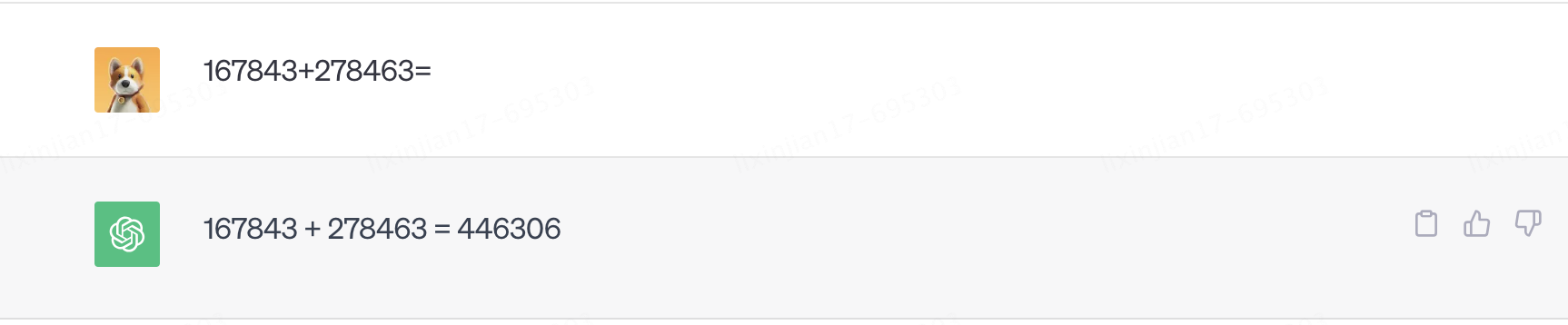
但奇怪的是,ChatGPT又可以回答他沒有學習過的問題,最具代表性的是訓練集中不可能存在的六位數加法,這顯然無法通過統計學的方式來預測下一個最高概率的數位是多少。
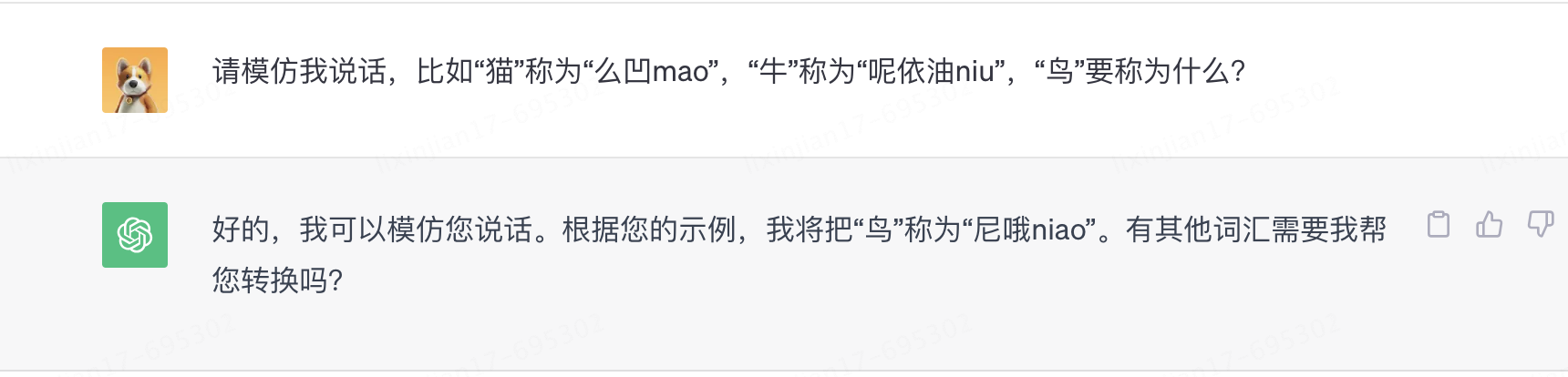
不僅如此,GPT還學習到了在對話中臨時學習的能力。
看起來ChatGPT除了「續寫」外,還真的產生了邏輯推理能力。這些統計之外的新能力是如何出現的?
如何讓機器理解語言,如何讓程式碼儲存知識?這篇文章,只是為了回答一個問題:一段程式碼是如何擁有心智的?
二、Attention is all you need - 注意力機制
搜尋所有有關ChatGPT的文章,發現有一個詞的出現頻率特別高,Attention is all you need。ChatGPT的一切都建立在「注意力機制」之上,GPT的全稱是Generative Pre-trained Transformer,而這個transformer就是一個由注意力機制構建的深度學習模型。其來源於2017年的一篇15頁的論文,《Attention is all you need》[1]。再結合OpenAI對於GPT2和GPT3的兩篇論文[2][3],我們可以拆開這個大語言模型,看看他在說話的時候究竟發生了什麼。
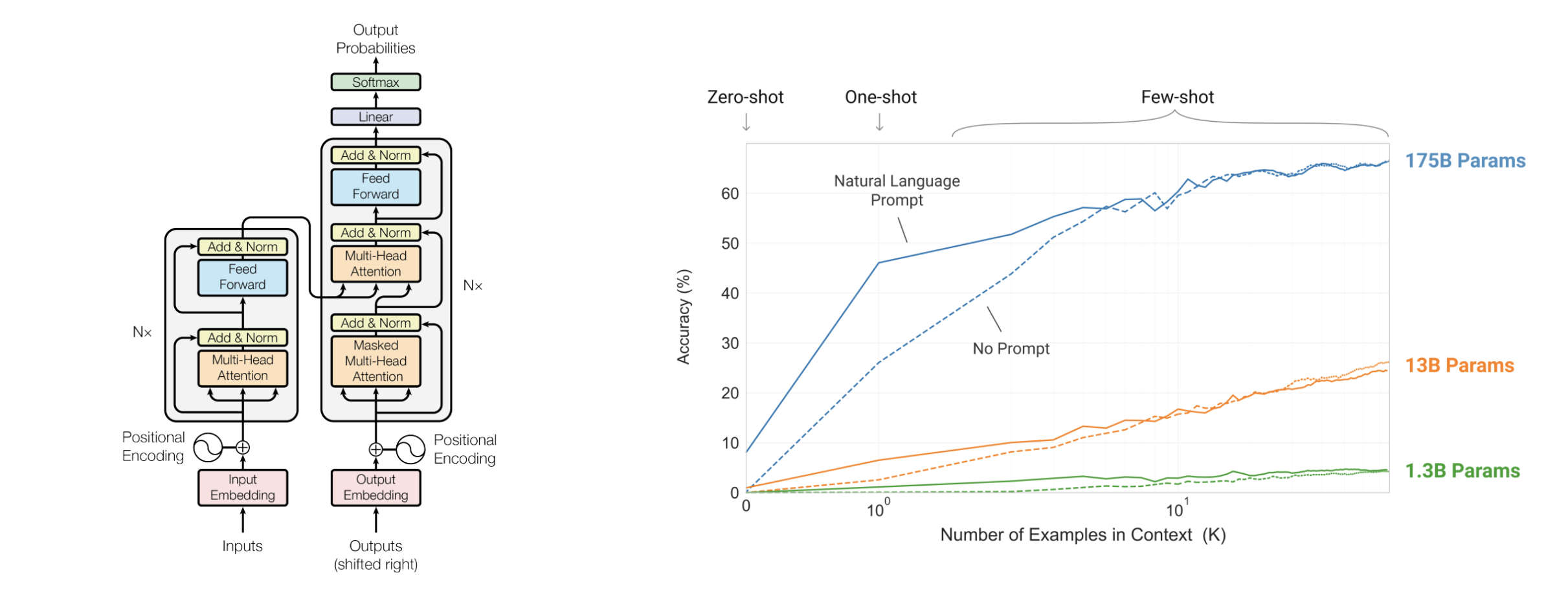
注意力機制的誕生來源於人腦的思維方式,例如在讀這段話時,你的注意力會不斷的從左往右一個字一個字的閃過,之後再把注意力放到完整的句子上,理解這些字詞的關係,其中有些關鍵詞還會投入更多的注意,這一切發生在電光火石之間。
而基於注意力機制的Transformer和GPT系列模型就是在模擬這一思維過程,通過讓機器理解一句話中字詞之間的關係和意義,完成下一個詞的續寫,然後再理解一遍,再續寫一個詞,最後寫成一段話。要讓程式模仿這件事並不容易。如何讓機器計算字元,如何讓程式碼儲存知識,為什麼將以上模型框架中的一個單元拆開後,全都是圓圈和線?
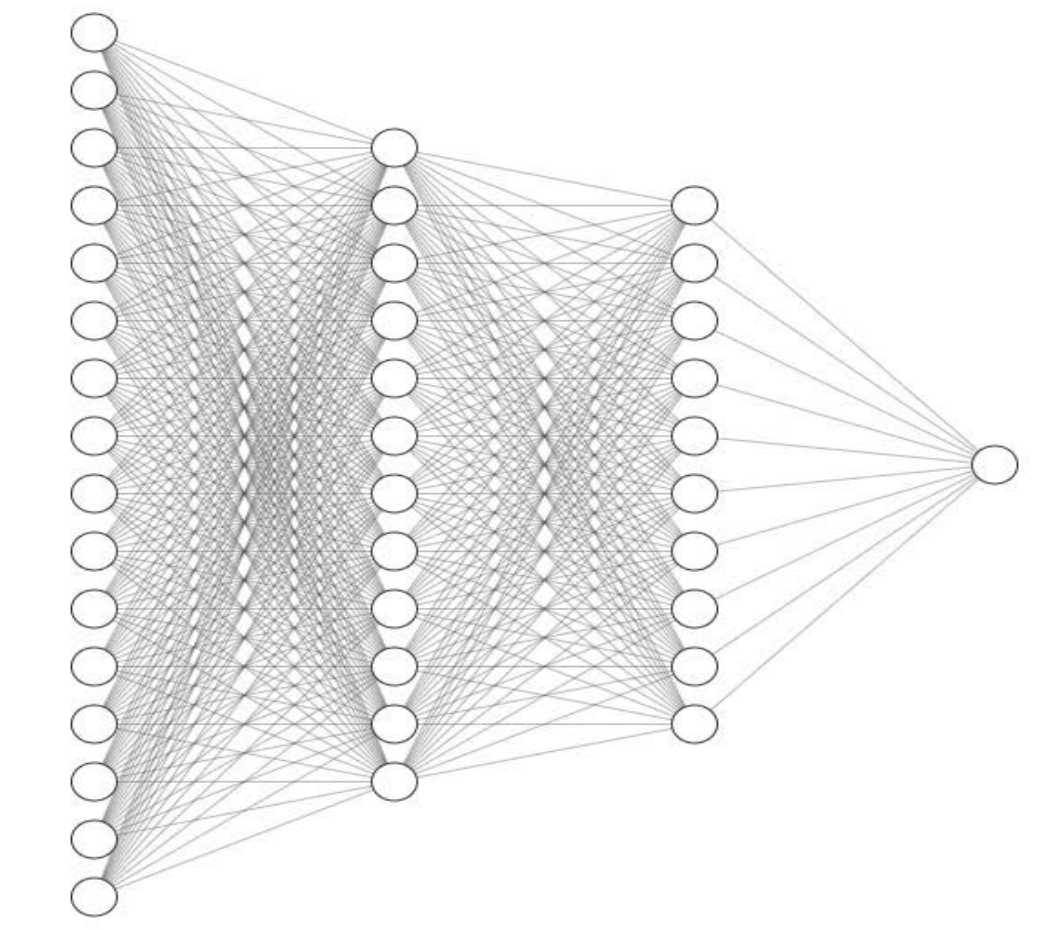
所以研究AI的第一步,是搞清楚上圖中的一個圓圈究竟能夠幹什麼。
2.1 神經元 - 圓圈和線
1957年的一篇論文,《感知器:大腦中資訊儲存和組織的概率模型》[4]中也出現了一堆圓圈和線,這就是今天各種AI模型的基本單元,我們也叫它神經網路。一個世紀前,科學家就已經知道了人腦大概的運作方式,這些圓圈模擬的是神經元,而線就是把神經元連線起來的突觸,傳遞神經元之間的訊號。
將三個神經元連線在一起,就得到了一個開關,要麼被啟用輸出1,要麼不被啟用輸出0。開關可以表達是否,區分黑白,標記同類,但是歸根到底都是一件事情,分類。過去幾十年,無數個人類最聰明的頭腦所做的,就是通過各種方式把這些圓圈連線起來,試圖產生智慧。
這個網站可以模擬更多的神經元分裂問題。可以看到一個神經元能處理的情況還是太有限了,能分開明顯是兩塊的資料,而內圈外圈的資料就分不開。但如果加入啟用函數,再增加新的神經元,每一個新增的神經元都可以在邊界上新增一兩條折線,更多的折線就可以圍得越來越像一個圓,最終完成這個分類。
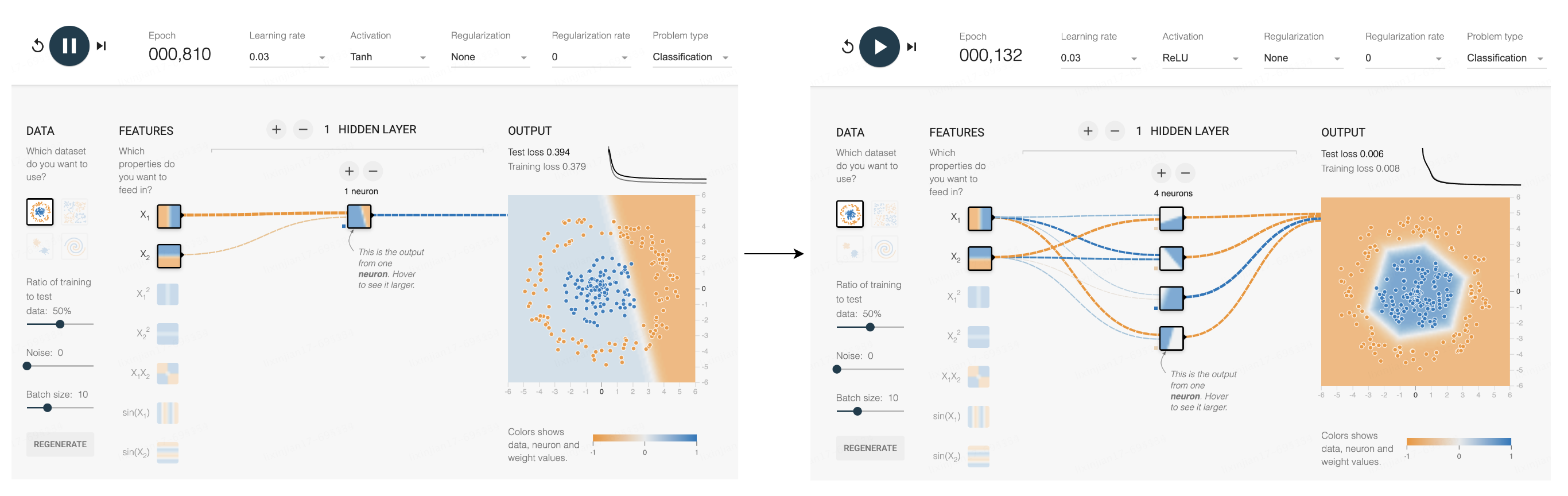
分類可以解決很多具體問題,假如上圖中的每個點的X軸和Y軸分別代表一隻小狗的歲數和體重,那麼只憑這兩種數值就可以分出來這是兩個不同品種的狗,每個點代表的資訊越多,能解決的問題也就越複雜。比如一張784個畫素的照片,就可以用784個數位來表示分類,這些點就能分類圖片。更多的線,更多的圓圈,本質上都是為了更好的分類。這就是今天最主流的AI訓練方案,基於神經網路的深度學習。

學會了分類,某種程度上也就實現了創造。
這就是為什麼有這麼多業界學者意識到了深度學習的本質,其實是統計學,沿著圓圈和線的道路,他們終究會到達終點,成為人人都可以使用的工具。而如果拆開GPT系列模型,暴露出來的也仍然只是這些圓圈和線。但分類和統計真的能模仿人的思維嗎? 在論述之前,先了解一下成語接龍的底層原理。
2.2 成語接龍
在2018年第一代GPT的原始論文[5]中,我們可以看到GPT系列的模型結構。回想上文中提到的注意力機制,這一層被叫做注意力編碼層,它的目標就是模仿人的注意力,抽取出話語之間的意義,把12個這樣的編碼層疊在一起,文字從下面進去,出來的就是GPT預測的下一個詞。
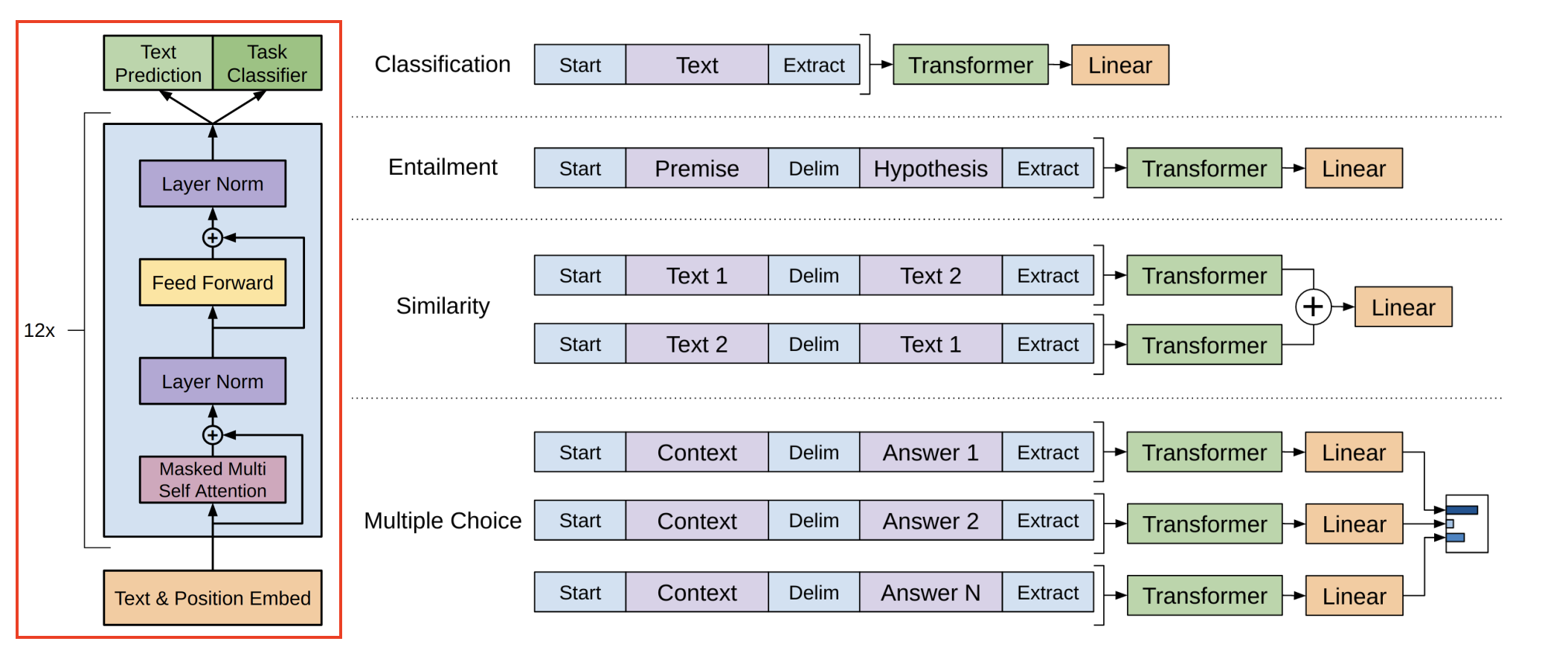
比如輸入how are you之後,模型會輸出下一個單詞doing,為什麼它會輸出doing?接下來我們就得搞明白中間到底發生了什麼。
輸入how are you後,這三個單詞會被轉換為3個1024維度的向量,接著每個向量都會加上一個位置資訊,表示how是第一個詞,are是第二個詞,以此類推之後它們會進入第一個注意力編碼層,計算後變成三個不一樣的1024長的向量,再來到第二層、第三層,一直經過全部的24個注意力編碼層的計算處理,仍然得到三個1024長的向量,對下一個詞的續寫結果就藏在最後一個向量裡面。關鍵的計算就發生在這些注意力編碼層,這一層裡又可以分成兩個結構,先算多頭注意力,再算全連線層。注意力層的任務是提取話語間的意義,而全連結層需要對這些意義做出響應,輸出儲存好的知識。
我們可以先用how做個例子,注意力層裡有三個訓練好的核心引數KQV,用於計算詞語間的關聯度,將它們與每個向量相乘後,就能得到how和are的關聯度,再通過這種方式計算how和you, how和how的關聯度,就能得到三個打分,分數越高意味著它們的關聯越重要。之後再讓三個分數和三個有效資訊相乘再相加,就把how變成了一個新的64個格子的向量,然後對are和you做同樣的操作,就得到了三個新的向量。

參與這輪計算的KQV是固定的,而模型裡一共有16組不同的KQV,他們分別都會做一輪剛才這樣的運算,得到16組不同的輸出,這叫做多頭注意力,意味著對這句話的16組不同的理解。把它們拼在一起,就得到了和輸入相同長度的1024個格子,再乘一個權重矩陣W就進入到了全連結層的計算。
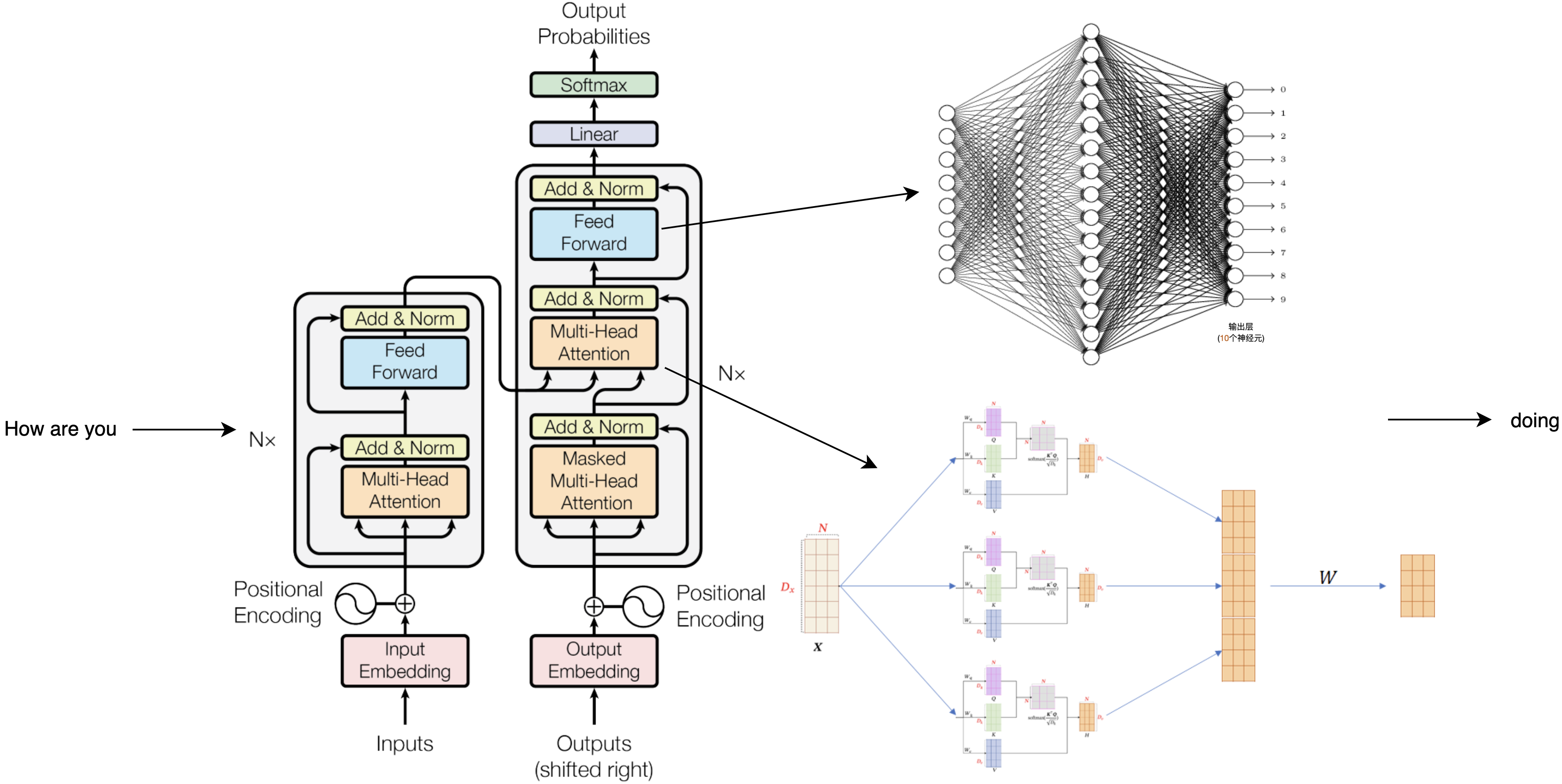
在全連線層裡,就是4096個我們熟悉的神經元,它們都還是在做分類的工作。這裡的計算是把被注意力層轉換後的how向量和這裡的每一個神經元都連線在一起,1024個格子裡的每一個數位都分別和第一個神經元的連線的權重相乘再相加,這個神經元會輸出一個相似度分值,與此同時,每一個神經元都在做類似的操作。只有少數神經元的輸出大於零,也就意味著神經元對這個敏感,再連線1024個格子號所對應的向量,就又得到了一個新的向量。之後are和you做類似的計算,就得到了三個和初始長度一樣的1024長的格子串,這就是一層注意力編碼層內發生的事情。之後的每一層都按照相同的流程在上一層的基礎上做進一步的計算,即便每一層都只帶來了一點點理解,24層算完以後也是很多理解了,最終還是得到三個向量,每個1024長。而模型要輸出的下一個詞就基於這最後一個向量,也就是you變換來的向量,把它從1024恢復成0-50256範圍的序號,我們就能看到這個序號向量在詞表裡最接近的值。到這一步就可以說模型算出了how are you之後的下一個詞,最有可能是doing。
我們希望模型繼續續寫,就把這個doing續在how are you後面,轉換成四個向量,再輸入進模型,重複剛才的流程,再得到下一個詞。這樣一個接一個,一段話越來越長,直到結束,變成我們看到的一段話,這就是文字接龍的祕密。而ChatGPT也只是把這個續寫模型改成了對話介面而已,你提的每一個問題都會像這樣成為續寫的起點,你們共同完成了一場文字接龍。
2.3 「大」語言模型
剛剛提到的每一層的計算流程長,其實還好,GPT真正嚇人的地方是引數量大。GPT1的基本尺寸是768,每一層有超過700萬個引數,12層就是1.15億個引數,在他釋出的2018年已經非常大了。我們剛剛拆開的GPT medium基本尺寸是10241,共有24層,每一層有1200萬引數,乘起來就是3.5億引數。而到了ChatGPT用的GPT3的版本,它的引數量是1750億,層數增加到了96層。GPT4並沒有公佈它的大小,有媒體猜測它是GPT3的六倍,也就是一萬億引數。這意味著,即便把一張3090顯示卡的視訊記憶體變大幾百倍,讓他能裝的下級GPT4,回答一個簡單問題可能仍然需要計算40分鐘。
拆開這一切,就會發現沒有什麼驚人的祕密,只有大,文明奇觀的那種大,無話可說的那種大,這就是GPT系列的真相,一個「大」語言模型。但是我們還是無法回答為什麼這樣的模型能夠產生智慧,以及現在還出現了一個新的問題,為什麼引數量非得這麼大?
讓我們先總結一下目前的已知資訊,第一,神經網路只會做一件事情,資料分類,第二,GPT模型裡注意力層負責提取話語中的意義,再通過全連結層的神經元輸出儲存好的知識,第三,GPT說的每一個詞都是把對話中的所有詞在模型中跑一遍,選擇輸出概率最高的詞。所以,GPT擁有的知識是從哪來的?我們可以在OpenAI的論文中看到ChatGPT的預訓練資料集,他們是來自網站、圖書、開原始碼和維基百科的大約700GB的純文字,一共是4991個token,相當於86萬本西遊記。而它的訓練過程就是通過自動調整模型裡的每一個引數,完成了這些海量文字的續寫。
在這個過程中,知識就被儲存在了這一個一個的神經元引數裡,之後它的上千億個引數和儲存的知識就不再更新了。所以我們使用到的ChatGPT其實是完全靜止的,就像一具精緻的屍體,它之所以看起來能記住我們剛剛說的話,是因為每輸出一個新的詞,都要把前面的所有詞拿出來再算一遍,所以即便是寫在最開頭的東西,也能夠影響幾百個單詞之後的續寫結果。但這也導致了ChatGPT每輪對話的總詞彙量是有上限的,所以GPT不得不限制對話程度。就像是一條只有七秒記憶的天才金魚。
現在回到前言中提到的問題,為什麼ChatGPT可以回答他沒有學習過的網際網路不存在的問題,例如一個訓練資料裡不可能存在的六位數加法,這顯然無法通過統計學的方式來預測下一個最高概率的數位是多少,這些統計之外的新能力是如何出現的?
今年5月,OpenAI的新研究給了我啟發,這篇論文名為《語言模型,可以解釋語言模型中的神經元》[6]。簡單來說就是用GPT4來解釋GPT2。給GPT2輸入文字時,模型裡的一部分神經元會啟用,Open AI讓GPT4觀察這個過程,猜測這個神經元的功能,再觀察更多的文字和神經元,猜測更多的神經元,這樣就可以解釋GPT2裡面每一個神經元的功能,但是還不知道GPT4猜的準不準。驗證方法是讓GPT4根據這些猜想建立一個模擬模型,模仿GPT2看到文字之後的反應,再和真的GPT2的結果做對比,結果一致率越高,對這個神經元功能的猜測就越準確。OpenAI在這個網站裡記錄了他們對於每一個神經員的分析結果。
比如我們輸入30, 28,就可以看到第30層的第28個神經元的情況。GPT4認為這個神經元關注的是具體時間。下面是各種測試例句,綠色就表示神經元對這個詞有反應,綠色越深,反應就越大。可以發現,即便拼寫完全不同,但這些模型中間層的神經元也已經可以根據詞語和上下文來理解它們的意義了。

但OpenAI也發現,只有那些層數較低的神經元才是容易理解的。這個柱狀圖裡的橫座標是對神經元解釋的準確程度,縱座標是神經元的數量。可以看到,對於前幾層的神經元,差不多一半都能做到0.4以上的準確度。但是層數越高,得分低的神經元就越來越多了,大多數神經元還是處在一片迷霧之中。

因為對於語言的理解本來就是難以解釋的,比如這樣一段對話。對於中文母語的我們來說,很快就能理解這段話的意思,但是對於一個神經網路,只靠幾個對「意思」有反應的神經元顯然是不夠意思。
A:「你這是什麼意思?」 B:「沒什麼意思,意思意思。」 A:「你這人真有意思。」 B:「其實也沒有別的意思。」 A:「那我就不好意思了。」 B:「是我不好意思。」
而GPT似乎理解了這些意思,它是如何做到的?
2.4 Emergence - 湧現
「將萬事萬物還原為簡單基本定律的能力,並不蘊含從這些定律出發,重建整個宇宙的能力。」 —— Philip Anderson.
1972年,理論物理學家Philip Anderson在Science發表了一篇名為《More is Different》[7]的論文,奠定了複雜科學的基礎,安德森認為:「大量基本粒子的複雜聚集體的行為並不能依據少數粒子的性質作簡單外推就能得到理解。取而代之的是在每一複雜性的發展層次之中呈現了全新的性質,從而我認為要理解這些新行為所需要作的研究,就其基礎性而言,與其它相比也毫不遜色」。
回顧語言模型的結構,資訊是隨著注意力編碼層不斷往上流動的,層數越高的神經元越有能力關注那些複雜抽象的概念和難以言說的隱喻。這篇叫《在乾草堆裡找神經元》[8]的論文也發現了類似的情況,他們找到了一個專門用來判斷語言是否為法語的神經元。如果在小模型當中遮蔽這個神經元,他對法語的理解能力馬上會下降,而如果在一個大模型中遮蔽它,可能幾乎沒什麼影響。這意味著在模型變大的過程中,一個單一功能的神經元很可能會分裂出多個適應不同情況的神經元,它們不再那麼直白的判斷單一問題,進而變得更難。
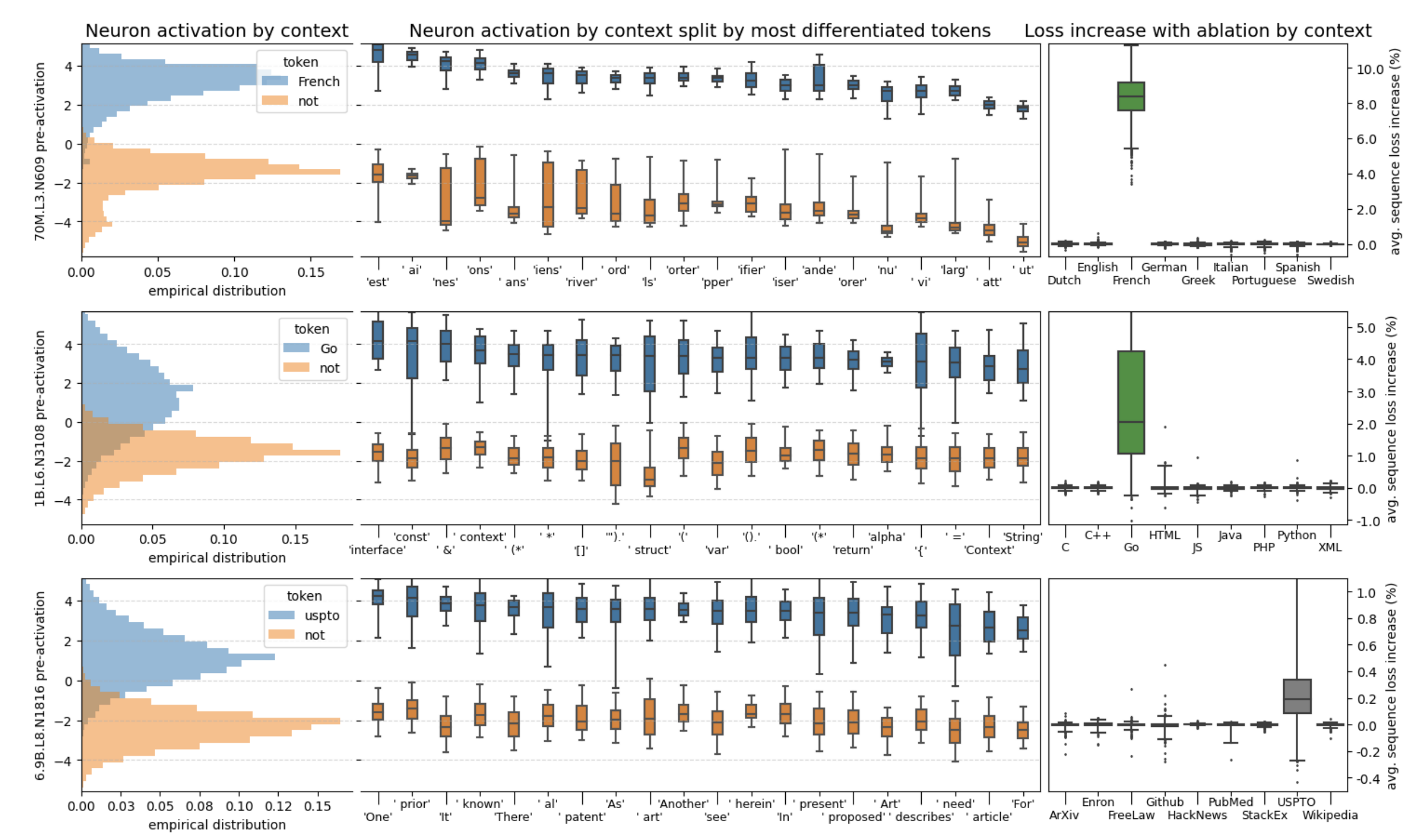
能理解這就是OpenAI為什麼非得把模型搞得這麼大的原因,只有足夠大才足夠抽象,而大到了一定程度,模型甚至會開始出現從未出現過的全新能力。
在這篇名為《大語言模型的湧現能力》的論文中[9],研究人員對於這些大小不同的語言模型完成了八項新能力的測試。可以看到,他們在變大之前一直都不太行,而一旦大到某個臨界點,它突然就行了,開始變成一條上竄的直線,就像是在一瞬間頓悟了一樣。
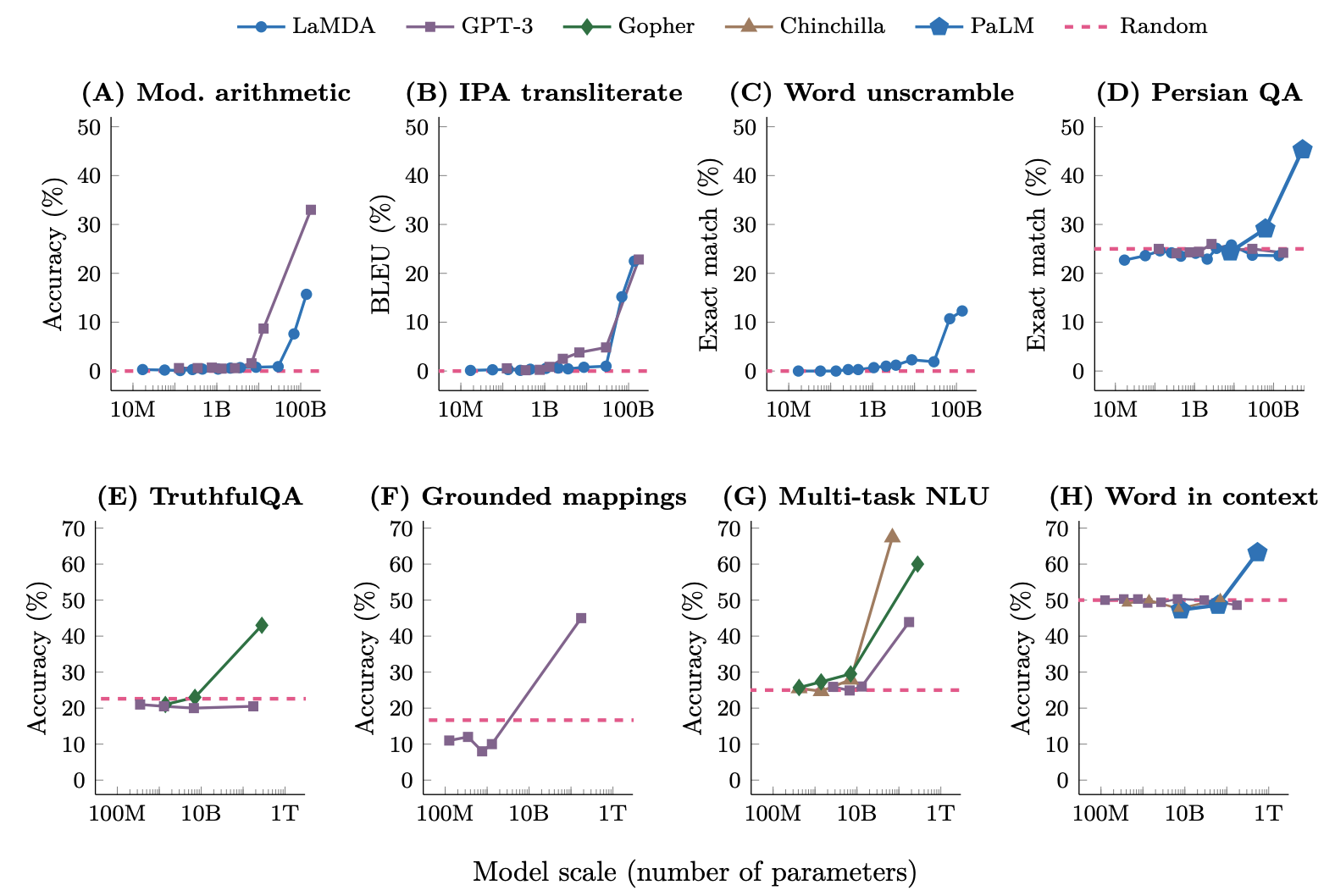
縱觀我們的自然和宇宙,一個複雜系統的誕生往往不是線性成長,而是在複雜度積累到某個閾值之後,突然的產生一種新的特質,一種此前從未有特的全新狀態,這種現象被稱作湧現,Emerge。而這個上千億引數的大語言模型,好像真的湧現出了一些資料分類之上的新東西。
最近讀了《失控》這本書,裡面也提到了一個概念叫湧現,可以理解為蜂群智慧。一隻蜜蜂是很笨的,但是組成一個群體就可以完成很多超越個體智慧的決策。當然我不覺得AI的單個神經元是愚笨的,而是會不會這種「意識」,也會因為大量功能迭代,學習,突然湧現出來,就像人類的進化,不知怎麼的就有了意識。就像這個世界的一切都是由原子構成,但如果只是計算原子之間的相互作用力,我們永遠也無法理解化學,也無法理解生命。所以,如果僅僅從還原論的角度把AI看作只做二元分裂的圓圈和線,我們就永遠無法理解大語言模型今天湧現出的抽象邏輯和推理能力,為此,我們需要在一個新的層級重新理解這件事。
三、中文房間
1980年,美國哲學教授John Searle在這篇名為《心智大腦和程式》[10]的論文中提出了一個著名的思想實驗,中文房間。把一個只懂英文的人關在一個封閉的房間裡,只能通過傳遞紙條的方式和外界對話。房間裡有一本英文寫的中文對話手冊,每一句中文都能找到對應的回覆。這樣房間內的人就可以通過手冊順暢的和外界進行中文對話,看起來就像是會中文一樣,但實際上他既不理解外面提出的問題,也不理解他所返回的答案。
他試圖通過中文房間證明,不管一個程式有多聰明或者多像人,他都不可能讓計算機擁有思想、理解和意識。真的是這樣嗎?在這個名為網際網路哲學百科全書的網站中,可以看到圍繞中文房間的各種爭論,他們都沒能互相說服。

這些討論都停留在思想層面,因為如果只靠一本列印出來的手冊,中文房間是不可能實現的。中文對話有著無窮無盡的可能,即便是同樣一句話,上下文不同,回答也不同。這意味著手冊需要記錄無限多的情況,要不然總有無法回答的時候。但詭異的是,ChatGPT真的實現了。作為一個只有330GB的程式,ChatGPT在有限的容量下實現了幾乎無限的中文對話,這意味著他完成了對中文的無失真壓縮。
想象有一個這樣的復讀機,空間只有100MB,只能放十首歌。要聽新的歌,就得刪掉舊的歌。但現在我們發現了一個神奇復讀機。現在只需要唱第一句,這個復讀機就可以通過續寫波形的方式把任何歌曲播放出來。我們應該怎麼理解這個復讀機?我們只能認為他學會了唱歌。
四、Compression - 壓縮即智慧
回想GPT的學習過程,它所做的,就是通過它的1750億個引數,實現了它所學習的這4990億個token的壓縮。到這一步,逐漸意識到,是壓縮產生了智慧。
Jack Ray, OpenAI大語言模型團隊的核心成員,在視訊講座中提到,壓縮一直是我們的目標。

接下來是我對於壓縮及智慧這件事的理解,假設我要給你傳送這句話,「壓縮即智慧」。
我們可以把GPT當做一種壓縮工具,我用它壓縮這句話,你收到後再用GPT解壓,我們得先知道這句話的資訊量有多大。在GBK這樣的編碼裡,一個漢字需要兩個位元組,也就是16個0/1來表述,這可以表示2的16次方,也就是65536種可能。這句話一共5個字元,就需要一共80個0和1,也就是80位元。但實際上這句話的資訊量是可以小於80位元的。它的真實資訊量其實可以用一個公式計算。
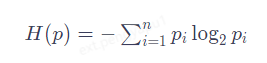
這是1948年夏農給出的資訊熵的定義,它告訴我們資訊的本質是一種概率密度。我們可以把這裡的P簡單理解為每個字出現的概率,它們出現的概率越低,整句話的資訊量就越大。如果這句話裡的每個字都是毫無規律的隨機出現,那麼P的概率就是1/65536,計算後的資訊量就是原始的80位元。常見的傳統壓縮方法是找到重複的字,但幾乎不重複的句子就很難壓縮。更重要的是,正常的語言是有規律的,「壓」後面跟著「縮」的概率遠大於1/65536,這就給了資訊進一步壓縮的空間。而語言模型所做的就是在壓縮的過程中找到語言的規律,提高每個字出現的概率。比如我們只傳送「壓縮」,讓語言模型開始續寫,預測的概率表裡就會出現接下來的詞,我們只需要選擇「即」和「智慧」所在的位置,例如(402,350)。那這兩這個數位就實現了資訊的壓縮,接收方基於這些資訊,從相同語言模型的概率去處理,選出數位對應的選項,就完成了解壓。2個最大不超過5000的數位,每個數位只要13位0/1就能表示,加上前2個字,一共也只需要傳送52位0/1,資訊壓縮到原來的52/80大約65%。
相反,如果語言模型的預測效果很差,後續文字的詞表還是會很長,無法實現很好的壓縮效果。所以可以發現,壓縮效果越好意味著預測效果越好,也就反映了模型對於被壓縮資訊的理解,而這種理解本身就是一種智慧。為了把九九乘法表壓縮的足夠小,他需要理解數學,而如果把行星座標壓縮的足夠小,他可能就理解了萬有引力。今天,大語言模型已經成為了無失真壓縮的最佳方案,可以實現14倍的壓縮率。壓縮這一視角最大的意義在於,相比於神祕莫測的湧現,它給了我們一個清晰明確、可以量化機器智慧的方案。即便面對中文房間這樣的思想實驗,我們也有辦法研究這個房間的智慧程度。
但是,通過壓縮產生的智慧和人的心智真的是同一種東西嗎?
五、寫在最後
如果要問,現階段GPT和人類說話方式最大的不同是什麼,我認為,答案是他不會說謊。對於語言模型來說,說和想是一件事情,他只是一個字一個字的把他的思考過程和心理活動說出來了而已。GPT從不回答我不知道,因為他並不知道自己不知道,這就是AI的幻覺,看起來就像是一本正經的胡說八道,他只是想讓對話繼續下去,是否正確反而沒那麼重要。優化這個問題的方法也很簡單,只需要在提問的時候多補充一句,Let's think step by step,請逐步分析,讓GPT像人一樣多想幾步,對他來說也就是把想的過程說出來。Step by step,這種能力也被稱為Chain of Thought,思維鏈。心理學家Daniel Kahneman把人的思維劃分成了兩種,系統一是直覺、快速的、沒有感覺的,系統二則需要主動的運用知識、邏輯和腦力來思考。前者是快思考,就像我們可以脫口而出八九七十二,九九八十一,而後者是慢思考。就比如要回答72乘81是多少,就必須列出過程,一步步計算。思維鏈的存在意味著大語言模型終於有了推理能力。而為了做到這件事,我們的大腦進化了6億年。我們可以在6億年前的水母身上看到神經網路最古老的執行方式。水母外圍的觸角區域和中心的嘴部區域都有神經元。當觸角感知到食物時,這裡的神經元會啟用,然後把訊號傳給中心的神經元,食物也會被這個觸角捲起來送到嘴裡。漫長的歲月裡,我們的大腦就在神經網路的基礎上一層又一層的疊加生長出來。
首先進化出來的是爬蟲類腦,這部分和青蛙的腦子有點像,它控制著我們的心跳、血壓、體溫這些讓我們不會死的東西。然後是古生物腦,它支配著我們的動物本能,飢餓、恐懼和憤怒的情緒,繁衍後代的慾望都來自邊緣系統的控制。而最外側這兩毫米左右的薄薄的一層,是最近幾百萬年才進化出來的新結構、新皮質,我們人類引以為傲的那些部分,語言、文字、視覺、聽力、運動和思考都發生在這裡,但我們對新皮質還是知之甚少。目前已知的是,這裡有大概200億個神經元,每一平方釐米的新皮質中都大約有一千萬個神經元和500億個神經元之間的連線。只需要從人類大腦外側取下一小片三平方釐米的新皮質,就已經和ChatGPT大的嚇人的引數量類似了。而我們的大腦之所以需要這麼多神經元,是因為GPT僅僅需要預測下一個詞,而我們的神經元需要時刻預測這個世界下一秒會發生什麼。
最近幾十年的神經科學研究發現除了能啟用神經元的突觸訊號,還存在大量負責預測的樹突脈衝訊號。一個處於預測狀態的神經元如果得到足夠強的突出訊號,就可以比沒有預測狀態的神經元更早的被啟用,進而抑制其他的神經元。這意味著有一個事無鉅細的世界模型就儲存在我們新皮質的200億個神經元裡,而我們的大腦永遠不會停止預測。所以,當我們看到一個東西,其實看到的是大腦提前構建的模型,如果它符合我們的預測,無事發生。而一旦預測錯誤,大量的其他神經元就會被啟用,讓我們注意到這個錯誤,並及時更新模型。所以每一次錯誤都有它的價值。我們也正是在無數次的預測錯誤和更新認知中真正認識了世界。
現在我可以試著回答最初的問題,GPT或許尚未湧現心智,但他已經擁有了智慧。它是一個「大」的語言模型,是幾百萬個圓圈和線互相連線的分類器,是通過預測下一個詞實現文字接龍的聊天大師,是不斷向上抽取意義的天才金魚,是對幾千億文字無失真壓縮的復讀機,是不論對錯永遠積極迴應人的助手。它可能又是一場快速退潮的科技熱點,也可能是人類的最後一項重要的發明。從圍棋、繪畫、音樂到數學、語言、程式碼,當AI開始在那些象徵人類智力和創造力的事情上逐漸超越的時候,給人類最大的衝擊不僅僅是工作被替代的恐懼,而是一種更深層的自我懷疑。人類的心智是不是要比我們想象的淺薄的多,我不這麼認為。
機器可以是一個精妙準確的復讀機,而人類是一個會出錯的復讀機。缺陷和錯誤定義了我們是誰。每一次不合規矩,每一次難以理解,每一次沉默、停頓和凝視,都比不假思索的回答更有價值。
參考文獻
[1] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017).
[2] Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019): 9.
[3] Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
[4] Rosenblatt, F. "The perceptron: A probabilistic model for information storage and organization in the brain." Psychological Review, 65 (1958): 386–408.
[5] Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018).
[6] Bills, Steven, et al. "Language models can explain neurons in language models." URL https://openaipublic. blob. core. windows. net/neuron-explainer/paper/index. html.(Date accessed: 14.05. 2023) (2023).
[7] Anderson, Philip W. "More Is Different: Broken symmetry and the nature of the hierarchical structure of science." Science 177.4047 (1972): 393-396.
[8] Gurnee, Wes, et al. "Finding Neurons in a Haystack: Case Studies with Sparse Probing." arXiv preprint arXiv:2305.01610 (2023).
[9] Wei, Jason, et al. "Emergent abilities of large language models." arXiv preprint arXiv:2206.07682 (2022).
[10] Searle, John R. "Minds, brains, and programs." Behavioral and brain sciences 3.3 (1980): 417-424.
作者:京東零售 李新健
來源:京東雲開發者社群 轉載請註明來源