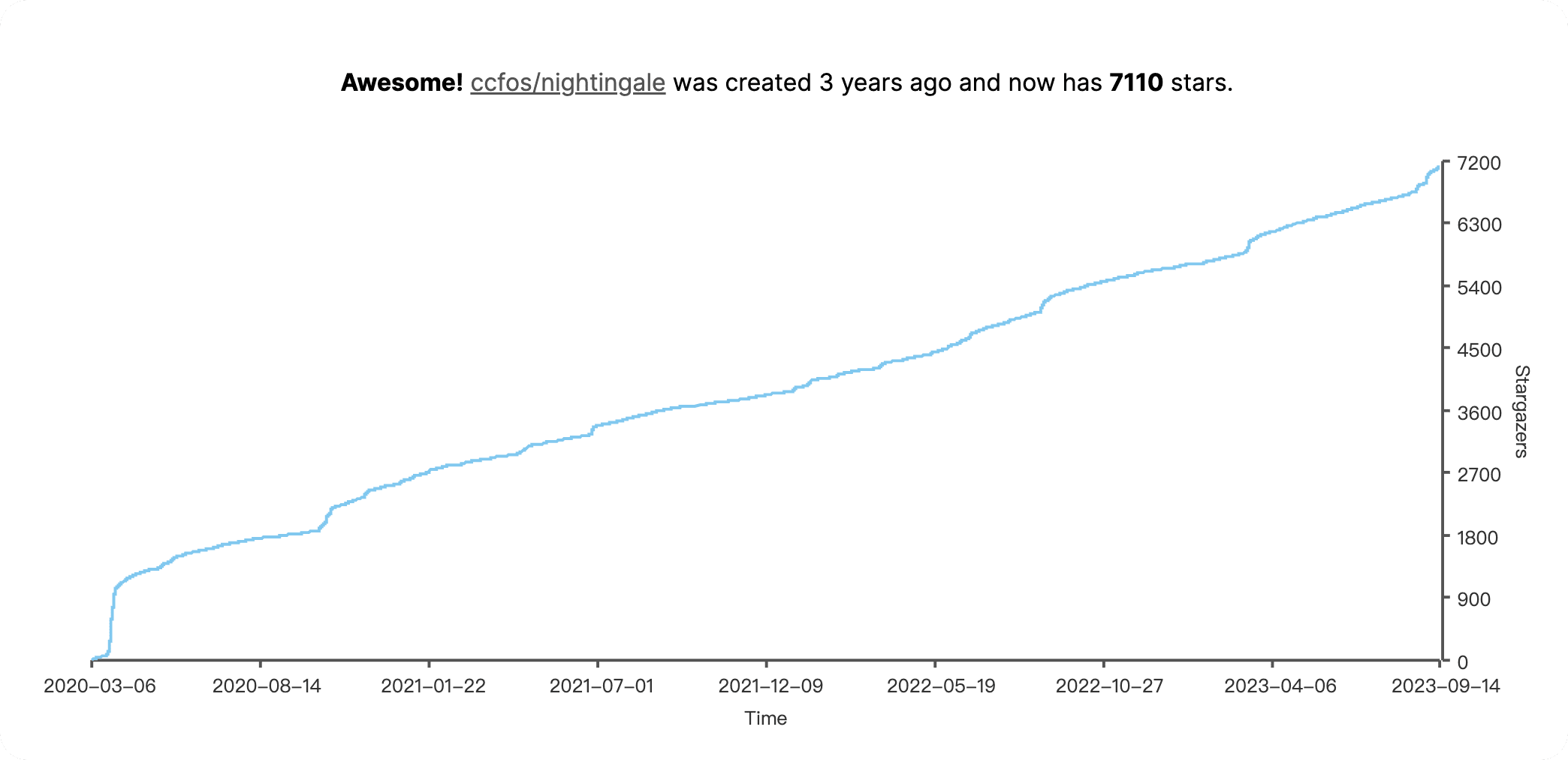
這款 7k Star 的國產監控系統,真不錯!

我們都知道天下沒有「永不宕機」的系統,但每次線上出問題都要拉出一個程式設計師「祭天」。所以一款靠譜、好用的監控工具就顯得十分重要,它可以在生產環境出故障的第一時間發出告警,並提供詳實的資料,幫助程式設計師儘早發現故障、儘快定位問題。
可以毫不誇張地說:監控就是運維的眼睛、研發的「免死金牌」,程式設計師「明哲保身、自證清白」的必備利器!
一、夜鶯監控
今天 HelloGitHub 給大家帶來的是一款開箱即用、預設中文、介面美觀的開源監控系統——夜鶯監控(Nightingale),100% 國產更懂你的苦。你還在為搭建/設定/調優「Prometheus + AlertManager + Grafana」的監控平臺而煩惱嗎?開箱即用的夜鶯監控輕鬆解決你的問題。
夜鶯監控是一款先進的開源雲原生監控分析系統,採用 All-In-One 的設計,集資料採集、視覺化、監控告警、資料分析、許可權管理於一體,擁有企業級的監控分析和告警能力。

夜鶯監控在運維圈裡很有名,它「出身名門」最初是由滴滴孵化並開源,在此期間沉澱了一線網際網路公司可觀測性的最佳實踐,有大廠的實踐背書可靠性和實用性上毋庸置疑。之後則捐贈給了中國計算機學會(CCF)進行託管,由運維圈的「老炮」秦曉輝等人設計、開發和維護。截止到發文前,夜鶯監控已在 GitHub 上獲得了 7200+ 個 Star、1200+ 次 Fork,發展勢頭迅猛、開源社群活躍,並且已經服務了上千家分佈在各行各業的企業。
接下來,就和 HelloGitHub 一起上手這款開箱即用的開源監控利器吧!
二、安裝啟動
最簡單的部署方式是使用 docker-compose,可實現一鍵啟動,執行下面的命令即可:
git clone https://github.com/ccfos/nightingale.git
cd nightingale/docker
docker-compose up -d
# 成功後會有以下輸出
# Creating mysql ... done
# Creating redis ... done
# Creating prometheus ... done
# Creating ibex ... done
# Creating agentd ... done
# Creating n9e ... done
# Creating telegraf ... done
啟動之後瀏覽器直接存取:127.0.0.1:17000,輸入賬號 root 密碼:root.2020,登陸後就能看到管理介面啦!
不過,我還是更推薦大家使用二進位制方式部署,因為這種方式不依賴 Docker、更穩定、升級也方便,可用於生產環境(官方推薦),部署起來也不麻煩,也就多幾行命令的事。下面是 linux x86 環境的範例和註解:
# 建立個 n9e 的目錄,後面把 n9e 相關的檔案解壓到這裡
mkdir -p /opt/n9e && cd /opt/n9e
# 下載 n9e 釋出包,amd64 是 x84 的包,下載站點也提供 arm64 的包,如果需要其他平臺的包則要自行編譯了
tarball=n9e-v6.1.0-linux-amd64.tar.gz
urlpath=https://download.flashcat.cloud/${tarball}
wget -q $urlpath || exit 1
# 解壓縮釋出包
tar zxvf ${tarball}
# 解壓縮之後,可以看到 n9e.sql 是建表語句,匯入資料庫
mysql -uroot -p1234 < n9e.sql
# 啟動 n9e,先使用 nohup 簡單測試,如果需要 systemd 託管,請自行準備 service 檔案
nohup ./n9e &> n9e.log &
# 檢查 n9e.log 是否有異常紀錄檔,檢查埠是否在監聽,正常應該監聽在 17000
ss -tlnp|grep 17000
至此,安裝部分就結束了,接下來就是上手體驗了。
三、快速上手
3.1 設定資料來源
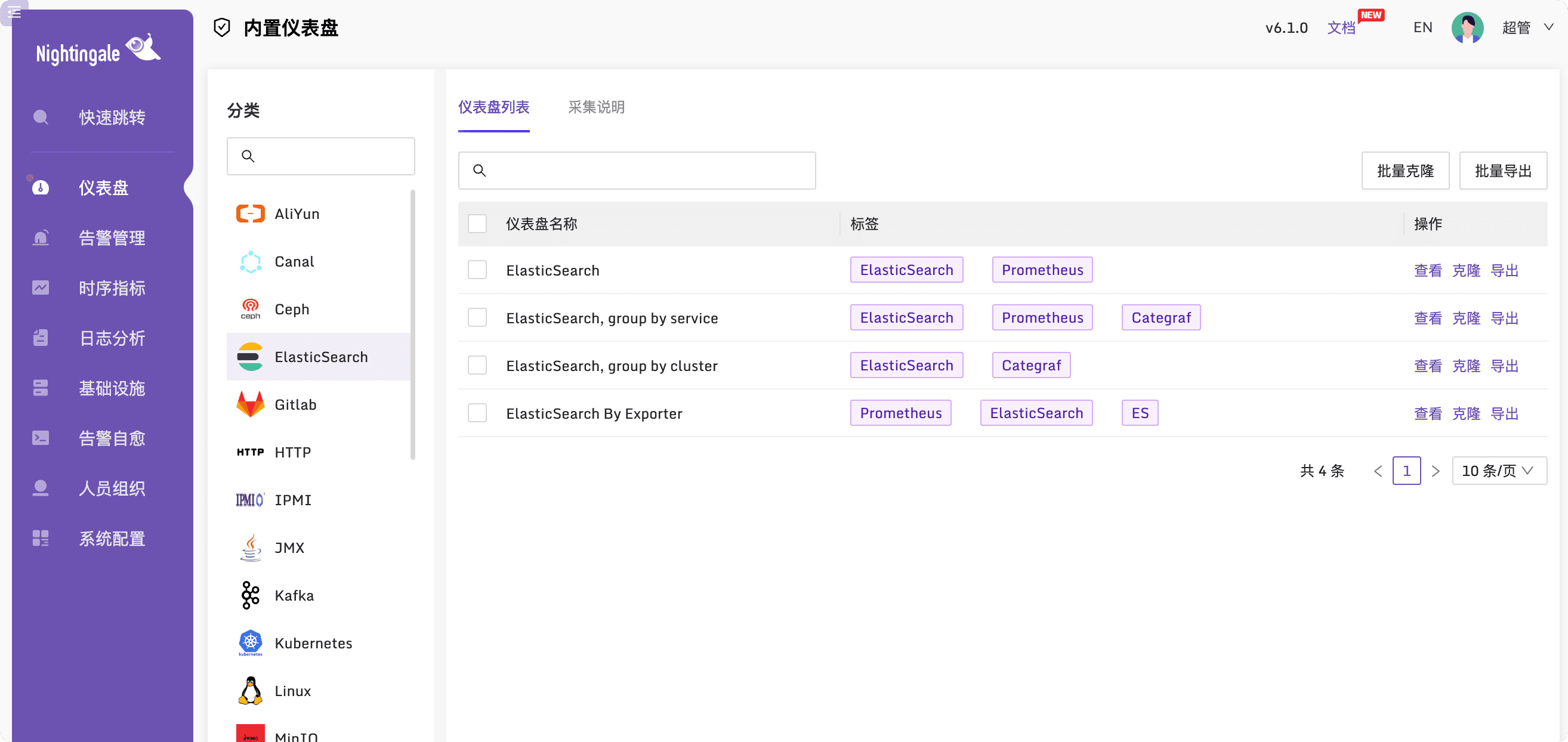
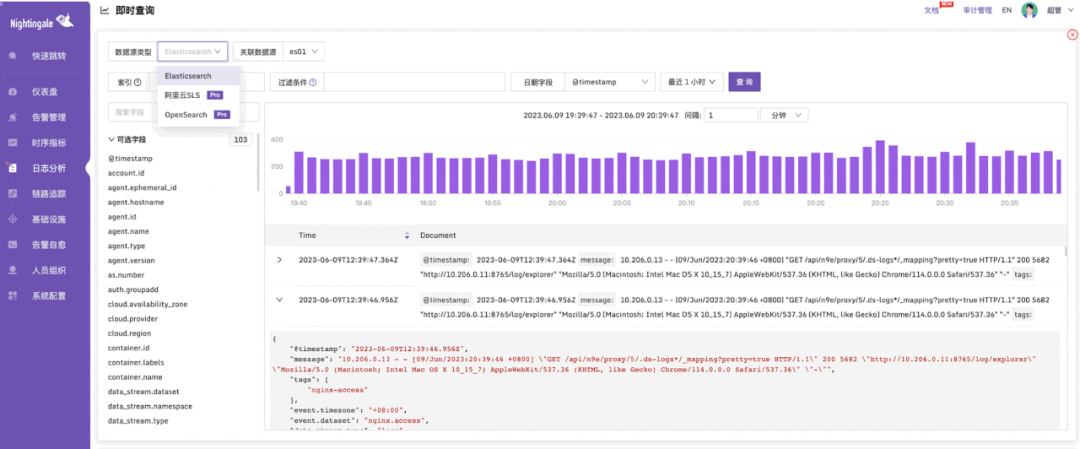
夜鶯不生產紀錄檔,只是紀錄檔的「監工」。所以安裝完第一件事就是設定紀錄檔資料,用法類似 Grafana 可直接接入資料來源,選單位置:「系統設定」-「資料來源」,目前支援:prometheus、victoriametrics、thanos、m3、elasticsearch、loki 等資料來源。

完成資料來源接入之後,就可以十分方便地通過視覺化的方式檢視紀錄檔了。
夜鶯預設提供了一些視覺化大盤(選單位置:「儀表盤」-「內建儀表盤」)和內建告警規則(選單位置:「告警管理」-「內建規則」),匯入自己的業務組(這是個管理概念,不同的告警規則和儀表盤可以使用不同的業務組分門別類管理 + 控制許可權)就能使用啦。
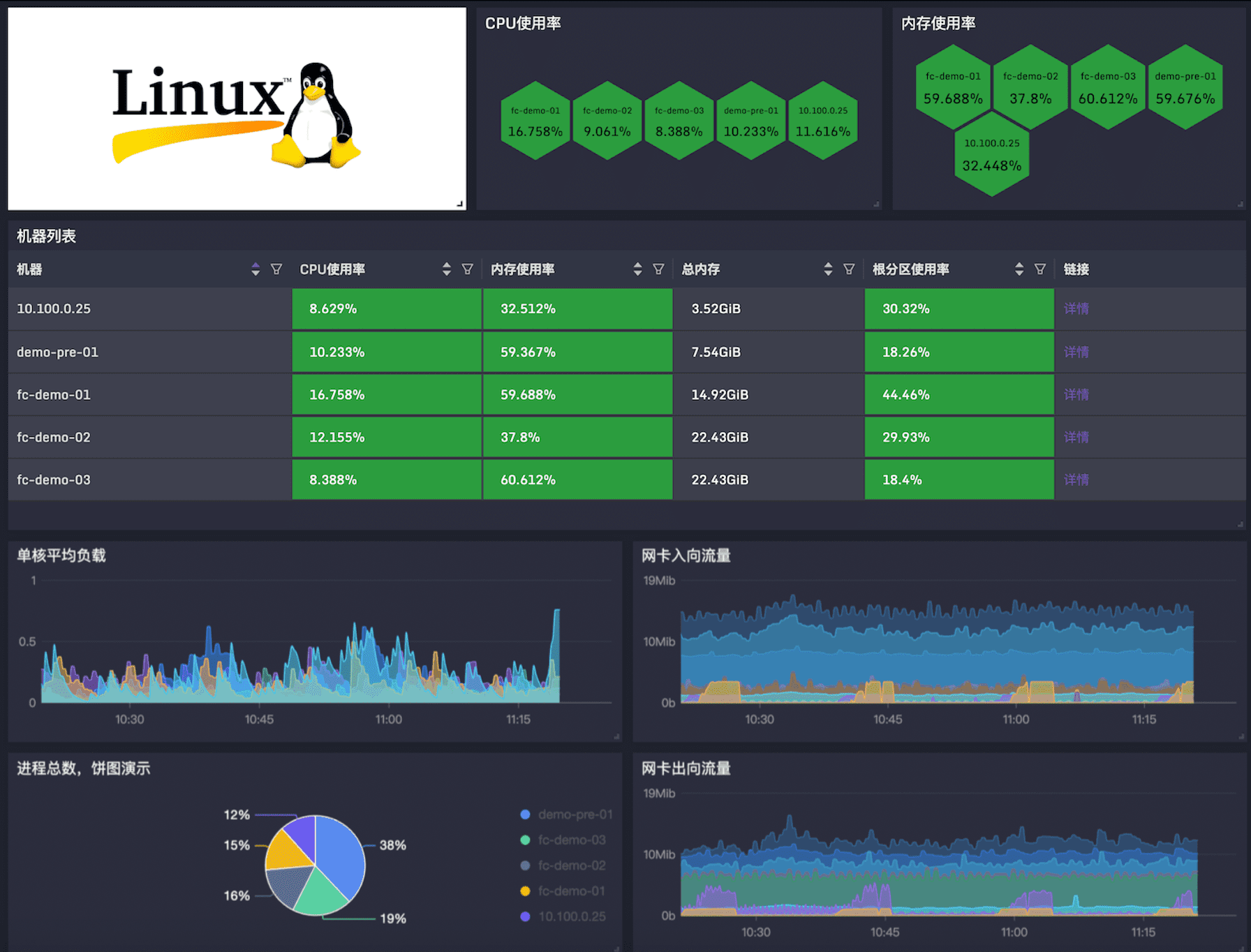
3.2 好看的儀表盤
夜鶯的儀表盤展示效果美觀、效能出眾、功能豐富,雖然還沒有 Grafana 的全面,但基本可以作為 Grafana 的國產化平替了。夜鶯的儀表盤支援暗黑主題,效果如下:
前端 GitHub 地址:https://github.com/n9e/fe
3.3 採集器
如果之前沒有做過監控資料收集,可以使用夜鶯團隊提供的採集器 categraf,這同樣是一款開源的 telemetry 資料採集器,它內建了 OS、SNMP、IPMI、MySQL、Redis、MongoDB、Oracle、Kafka、ElasticSearch、cAdvisor 等多種採集外掛。
當然,也可以使用其他採集器,比如 telegraf、grafana-agent 等,但是 categraf 的對接最為絲滑。夜鶯支援多種資料接入協定,比如 prometheus remote write、OpenTSDB、Datadog 等,接收到資料之後做統一轉換,然後轉發給後端時序庫,具體轉發給哪些時序庫可以在夜鶯的組態檔中設定。
3.4 告警管理
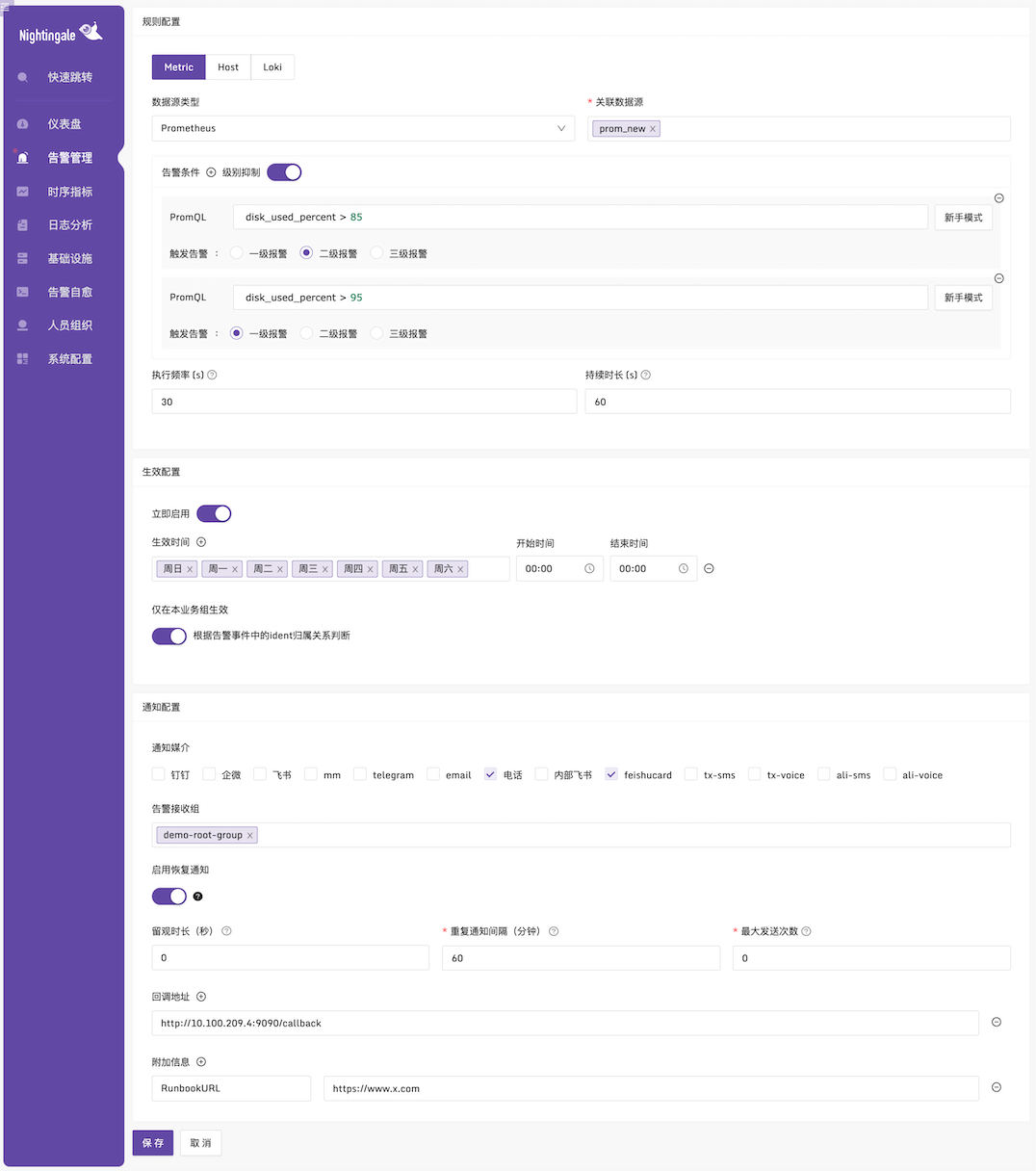
靈活的告警是優秀監控系統的標配,夜鶯在這方面做得十分出色。它可以將一套規則應用於多個資料來源,支援級別抑制、生效時間、告警遮蔽、告警訂閱、告警自愈等規則。
- 級別抑制:高階別抑制低階別告警,比如磁碟利用率超過 95% 產生 P1 告警,超過 85% 產生 P2 告警,如果某一時刻磁碟利用率跑到 100%,就只會觸發 P1 告警,P2 被抑制,避免告警打擾;
- 生效時間:可設定告警規則判定的生效時間,支援設定不同的多個日期和時段;
- 告警遮蔽:減少已知告警的干擾,比如某個機器要維護,可以提前遮蔽相關告警;
- 告警訂閱:告警訊息分組通知;
- 告警自愈:告警可觸發預先設定好的指令碼,自動解決故障;
選單「告警管理」-「規則設定」的介面和範例如下:
四、深入瞭解
監控並不僅僅是視覺化+告警那麼簡單,裡面有很多道道,下面讓我們「往下」走一點,深入瞭解下夜鶯監控的架構和解決的痛點。
4.1 架構介紹
夜鶯作為一款 Go 寫的監控系統,不僅部署方便,而且整體設計上非常開放和靈活,可以和開源生態上其他軟體組合使用,適用於已有監控系統升級或從零搭建監控平臺等場景。
- 採集器:可對接 telegraf、categraf、grafana-agent、datadog-agent、以及各類 exporter;
- 儲存:可對接 prometheus、thanos、m3、victoriametrics 等;
架構圖如下:
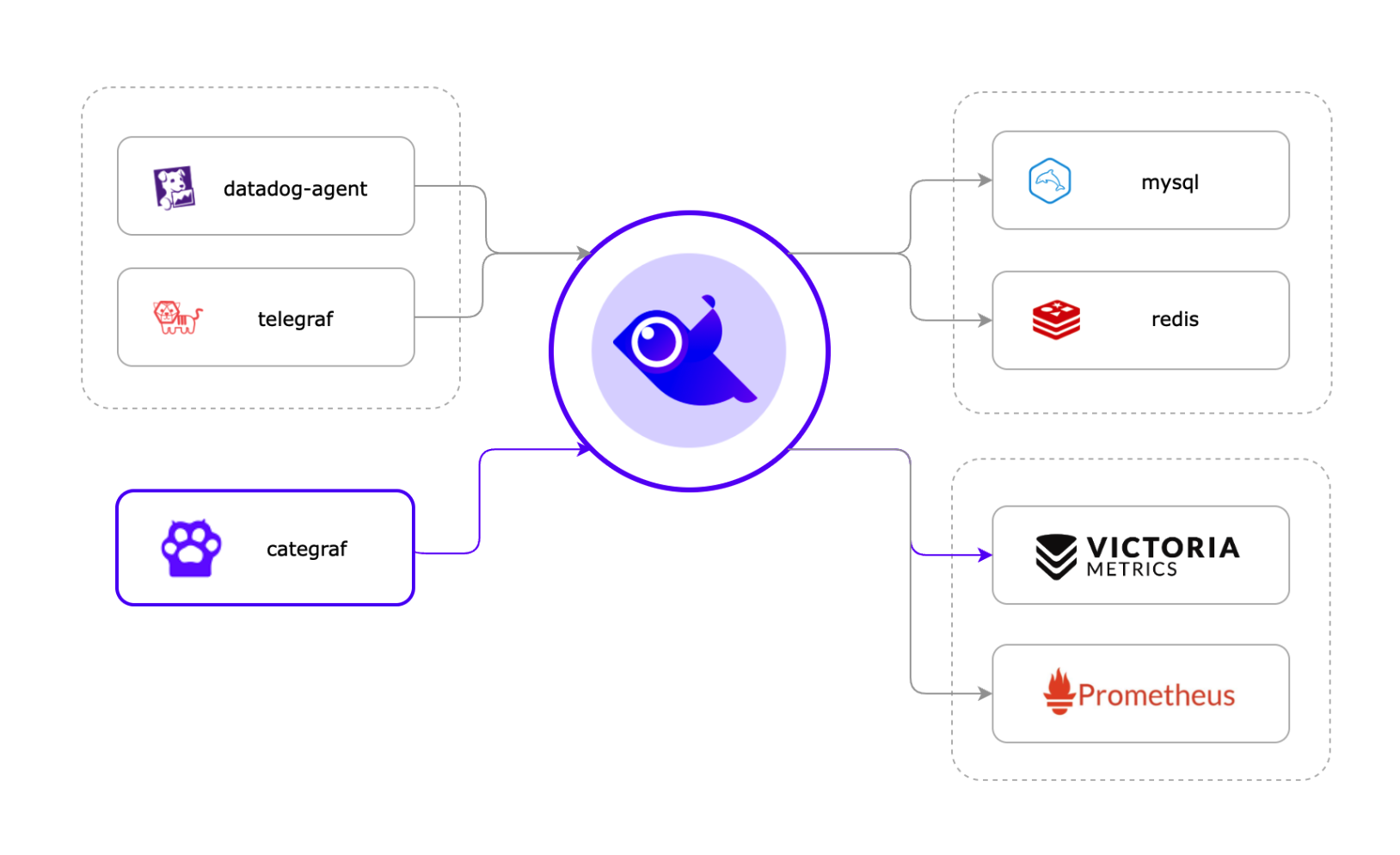
從依賴上看,夜鶯就只依賴 MySQL 和 Redis,它倆對於技術人員來說,都是非常熟悉的。除此之外,夜鶯在部署時只需一個二進位制檔案 + 組態檔,將開箱即用的精神貫徹到底!
4.2 專案結構
下面簡單介紹一下夜鶯的專案結構,即核心功能模組介紹,方便想要深入瞭解夜鶯的同學快速進入原始碼。
➜ # 夜鶯的目錄結構介紹
.
├── ...
├── alert 告警引擎相關邏輯,對 Prometheus、Loki、TDEngine 等資料來源做異常資料判斷併產生告警事件。
├── center Web 後端的邏輯。
├── cli 命令列工具,用於 v5 版本升級 v6 版本時的資料遷移。
├── cmd 入口包,所有的二進位制的 main 函數入口都在這裡。
├── conf 組態檔在記憶體裡對映的資料結構。
├── docker 容器相關的檔案,包括 Dockerfile 和 docker-compose 等,資料庫的建表 SQL 也在這裡。
├── etc 組態檔,重點關注 config.toml,如果使用了邊緣機房的部署方案,還需要關注 edge.toml。
├── integrations 整合目錄,包含比如 MySQL、Redis、Elasticsearch 等各個監控目標的內建儀表盤、告警規則等。
├── models 資料庫操作相關的程式碼。
├── pkg 通用 lib 庫。
├── prom Prometheus 相關的程式碼,包括 remote write 寫資料以及查詢介面的封裝。
├── tdengine 查詢 TDEngine(時序資料庫)相關的程式碼。
├── storage MySQL 和 Redis 的初始化連線相關的程式碼。
└── pushgw Pushgateway 相關的程式碼,用於接收 remote write 資料、opentsdb 格式的資料、datadog 格式的資料、open-falcon 格式的資料,然後統一做格式轉換寫入後端儲存。
4.3 多機房場景
你是否遇到過需要監控多機房的場景?
目前,大多數公司都有很多機房,它們分佈在不同的區域,這讓監控變得不再簡單。因為如果機房之間網路鏈路很好,那麼只需要部署一套監控系統就搞定了。但如果機房之間的網路不太好,無法做到監控資料實時、可靠的上傳,但是告警規則又想在一箇中心管理。
這個時候就需要高階部署方案,夜鶯就提供了現成的邊緣機房部署方案,可以方便地解決上面的問題。架構圖如下:
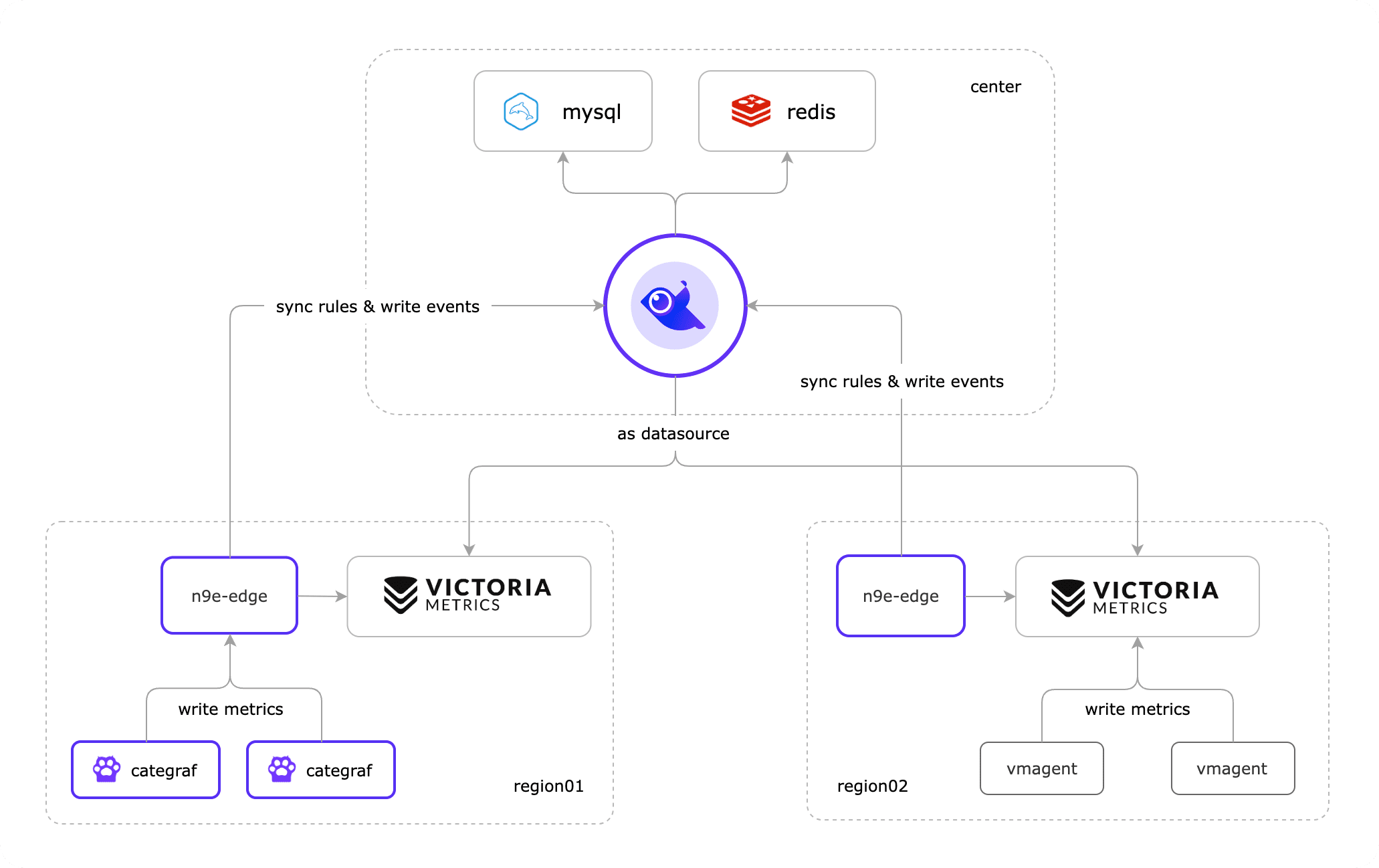
通過夜鶯提供的高階部署方案,即在網路不好的機房(邊緣)部署(下沉)時序資料庫和告警引擎(n9e-edge),從而保證資料不丟失和告警規則的同步,輕鬆構建統一的監控中心,實現多機房監控只需管理一套告警規則和視覺化平臺。
真·企業級監控和告警一體化解決方案!
五、最後
開源的監控系統,目前用的比較廣泛的是 Zabbix 和 Prometheus,但它們或多或少都有一些不擅長的場景。
Zabbix 擅長裝置監控,對各類作業系統、網路裝置有較好的相容適配,但是不擅長微服務和雲原生環境的監控。
- 不擅長動態變化物件的監控:Zabbix 是資產管理式,在雲原生環境下,資產是動態變化的,比如 Pod、Service、Deployment 等。
- 不擅長微服務的監控:在微服務和雲原生環境下,監控指標爆炸性增長,而且指標有不同的維度描述,Zabbix 使用關係型資料庫儲存時序資料,不擅長處理這種大規模的多維度的指標資料。
Prometheus 擅長微服務和雲原生環境的監控,基本已經成為 Kubernetes 的標配,在雲原生環境下非常流行,但它也有缺點。
- 設計上偏工具化,使用組態檔來管理規則,缺少許可權化管理的 WebUI。
- 使用 Prometheus 的公司通常會不止一套,比如每個 Kubernetes 一套 Prometheus,多個 Prometheus 可能有很多相同的規則,管理起來比較重複。
- 其他一些小點:告警引擎是單點,告警事件沒有持久化;告警規則缺乏一些更為靈活的設定,比如生效時間;
夜鶯作為一款開源的雲原生監控系統,在雲原生方面有著先天優勢,而且使用國外的開源監控專案,最擔心的就是沒有技術支援,夜鶯作為「100% 國產」開源專案,在技術支援上分為社群支援和商業支援(響應更及時)兩種,服務的企業使用者已有上千家,比如移動、聯通、電信、米哈遊、莉莉絲、方正證券、國泰君安、海底撈、海康、搜狐、新浪等,分佈在各行各業。

最後,還是那句話:開源不易如果覺得夜鶯監控不錯的話,就請給個 Star 支援一下,試用反饋遇到的問題,也是對開源的一種支援!
沒有能搞定一切的銀彈,或許這也是技術一直在更新迭代的動力之一吧! 所以不要停下學習的腳步