【RocketMQ】RocketMQ儲存結構設計
CommitLog
生產者向Broker傳送的訊息,會以順序寫的方式,寫入CommitLog檔案,CommitLog檔案的根目錄由設定引數storePathRootDir決定,預設每一個CommitLog的檔案大小為1G,如果檔案寫滿會新建一個CommitLog檔案,以該檔案中第一條訊息的偏移量為檔名,小於20位用0補齊:

比如第一個檔案中第一條訊息的偏移量為0,那麼第一個檔案的名稱為00000000000000000000,當這個檔案存滿之後,需要重新建立一個CommitLog檔案,一個檔案大小為1G,
1GB = 102410241024 = 1073741824 Bytes,所以下一個檔案就會被命名為00000000001073741824。
資料格式
CommitLog中儲存的每條訊息的資料格式如下:
- 訊息總長度,佔4個位元組;
- 魔數,佔4個位元組;
- 訊息體CRC校驗和,佔4個位元組;
- 佇列ID,佔4個位元組;
- 標識,佔4個位元組;
- 佇列的偏移量,佔8個位元組;
- 訊息在檔案的物理偏移量,佔8個位元組;
- 系統標識,佔4個位元組;
- 傳送訊息的時間戳,佔8個位元組;
- 傳送訊息的主機地址,佔8個位元組;
- 儲存時間戳,佔8個位元組;
- 儲存訊息的主機地址,佔8個位元組;
- 訊息的重試次數,佔4個位元組;
- 事務相關偏移量,佔8個位元組;
- 訊息內容的長度,佔4個位元組;
- 訊息內容,由於訊息內容不固定,所以長度不固定;
- 主題名稱的長度,佔1個位元組;
- 主題名稱內容,長度不固定;
- 訊息屬性長度,佔2個位元組;
- 訊息屬性內容,長度不固定;
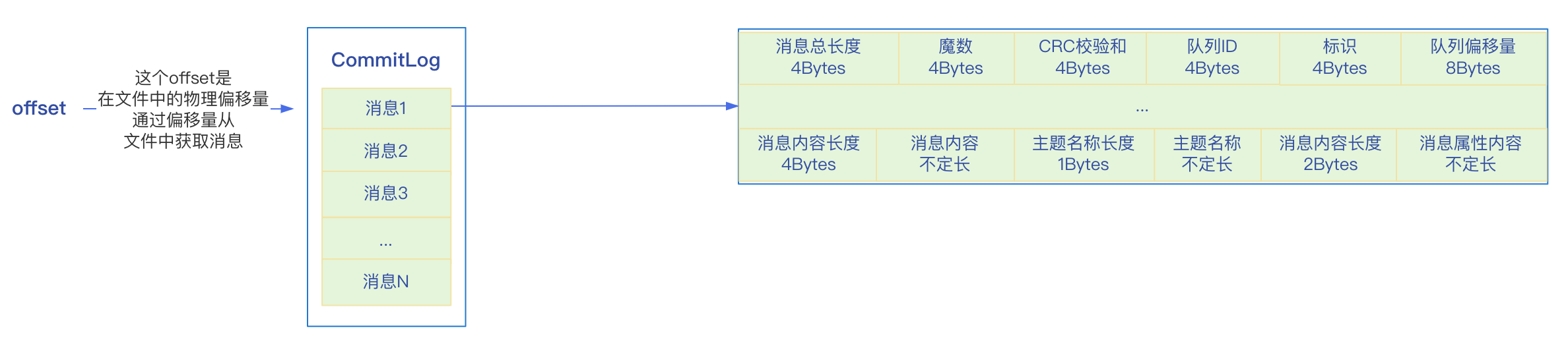
RocketMQ一般會儲存一個物理偏移量offSet,從CommitLog中獲取訊息內容。
ConsumeQueue
RocketMQ在訊息儲存的時候將訊息順序寫入CommitLog檔案,如果想根據Topic對訊息進行查詢,需要掃描所有CommitLog檔案,這種方式效能低下,所以RocketMQ又設計了ConsumeQueue儲存訊息的邏輯偏移量,offset邏輯偏移量從0開始編號,進行遞增,訊息寫入CommitLog以後,會構建對應的 ConsumeQueue檔案。
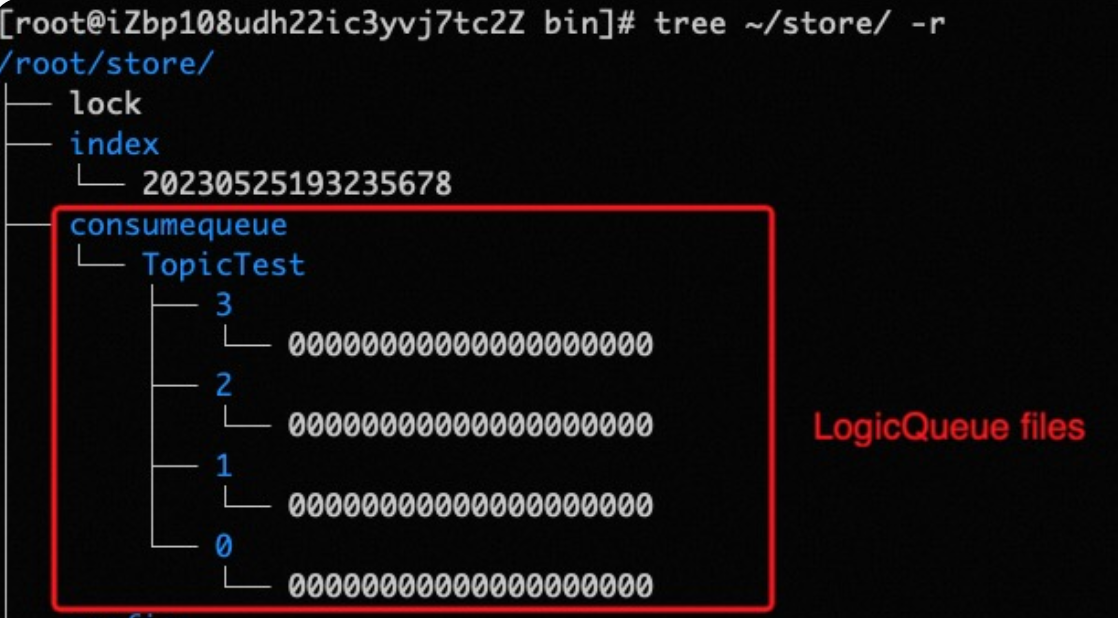
在RocketMQ的儲存檔案目錄下,有一個consumequeue資料夾,裡面按Topic分組,每個Topic一個資料夾,Topic資料夾內是該Topic的所有訊息佇列,以訊息佇列ID命名資料夾,每個訊息佇列都有自己對應的ConsumeQueue檔案:
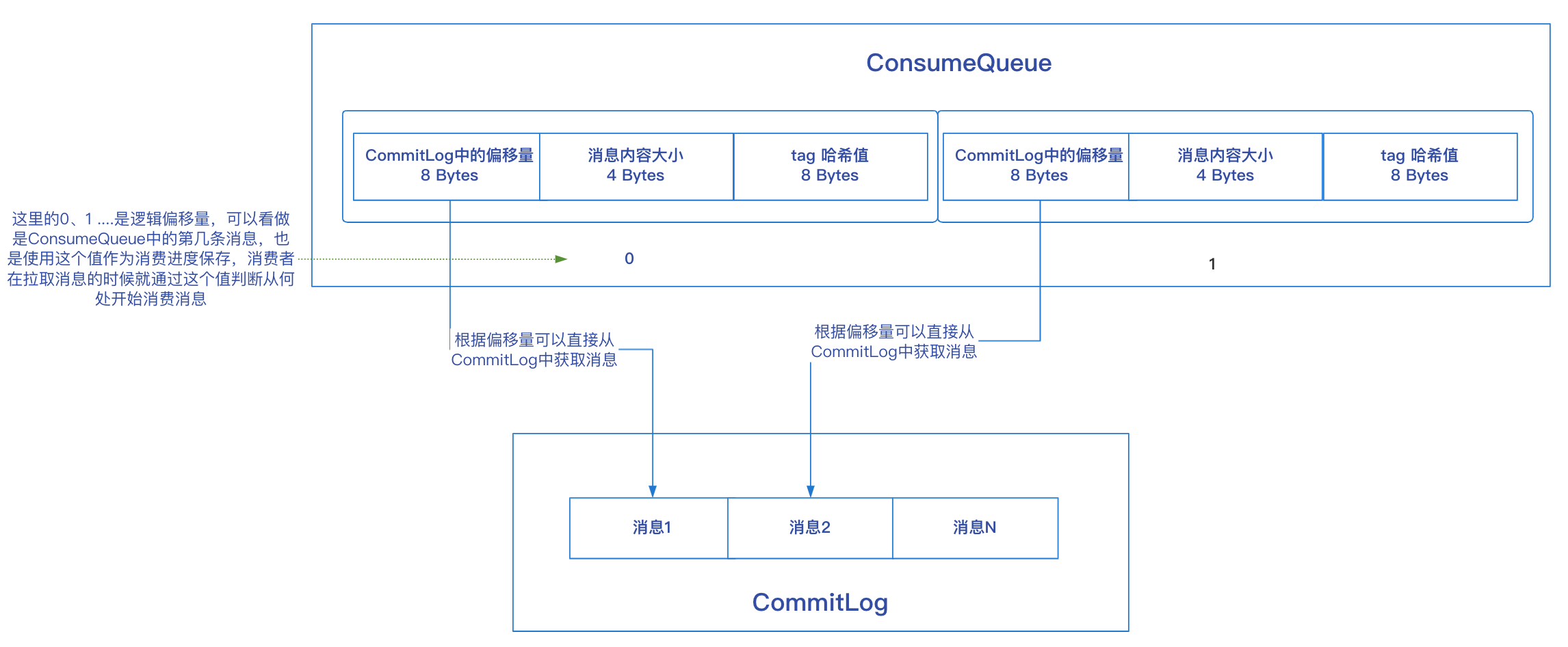
ConsumeQueue中儲存的每條資料大小是固定的,總共20個位元組,資料格式如下:

- 訊息在CommitLog檔案的偏移量,佔用8個位元組;
- 訊息大小,佔用4個位元組;
- 訊息Tag的hashcode值,用於tag過濾,佔用8個位元組;
消費進度
消費者在拉取訊息進行消費的時候,就是通過這個ConsumeQueue實現的,消費者在向Broker傳送訊息拉取請求之前,需要知道應該從哪條訊息開始消費,對於廣播模式,訊息的消費進度儲存在消費者端本地,對於叢集模式,訊息的消費進度儲存在Broker中,所以拉取某個訊息佇列的訊息之前,會向Broker傳送請求,獲取該訊息佇列的消費進度,消費進度在RocketMQ的儲存目錄中有一個對應的檔案,叫consumerOffset.json,裡面的offsetTable中儲存了每個訊息佇列的消費進度,這個消費進度值對應的就是ConsumeQueue中的邏輯偏移量,它由定時任務定時進行持久化:
{
"offsetTable":{
"TestTopic@TestTopicGroup":{ // 主題名稱@消費者組名稱
0:0, // 每個訊息佇列對應的消費進度,Key中的0表示佇列0,value中的0表示訊息在ConsumeQueue中的邏輯偏移量
1:1,
2:1,
3:0
}
}
}
拿到訊息佇列對應的消費進度時,就可以根據這個值從Broker拉取訊息,Broker收到請求後,會根據這個值從ConsumeQueue中獲取此條訊息在CommitLog中的物理偏移量,根據物理偏移量再從CommitLog中獲取訊息內容返回給消費者。
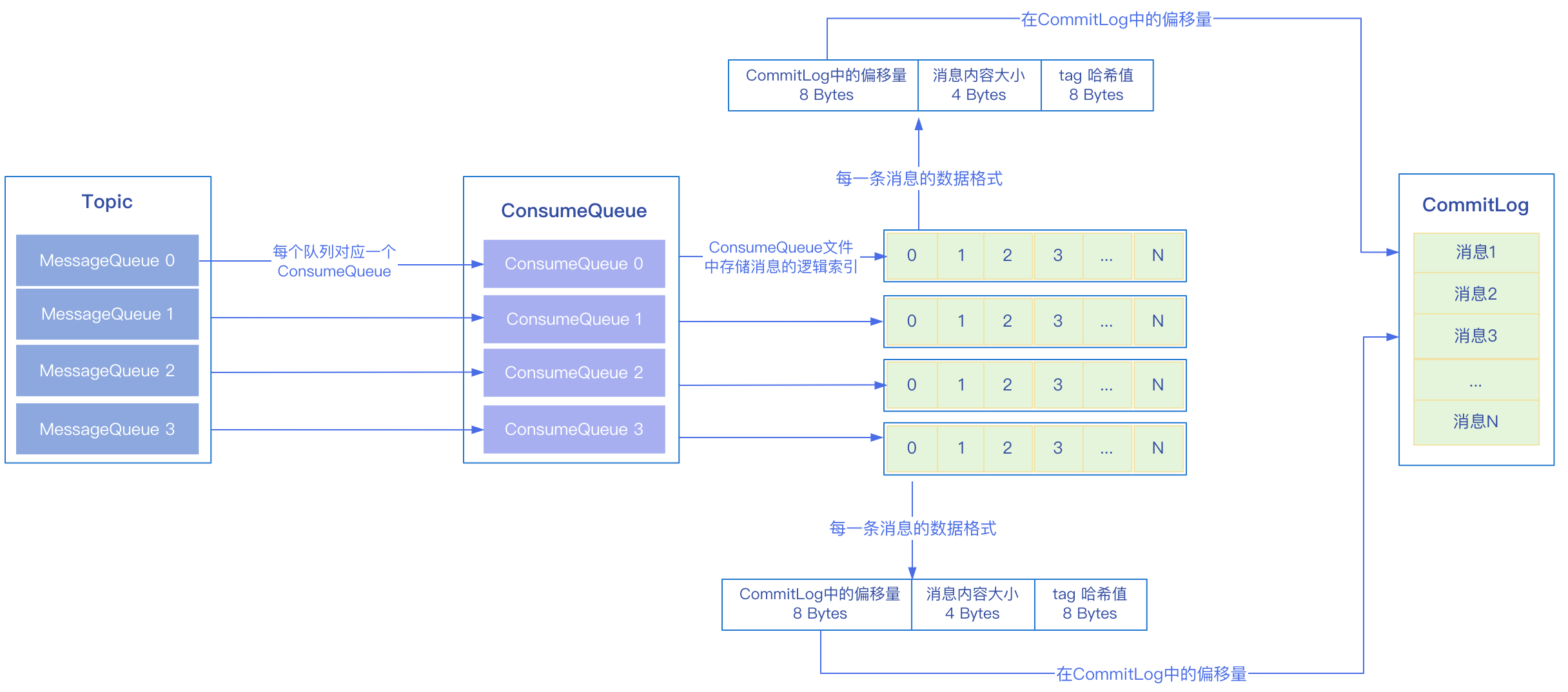
總結
當訊息寫入CommitLog之後會構建對應的ConsumeQueue檔案,每個訊息佇列MessageQueue都會有一個對應的ConsumeQueue檔案,ConsumeQueue檔案中的offset記錄的是訊息的邏輯索引,從0開始編號進行遞增,比如存入了3條訊息,那麼對應的offset分別為0、1、2,消費者在消費的時候拿到的消費進度就是這個offset,然後根據offset從ConsumeQueue檔案中獲取資料,裡面記錄了訊息在CommitLog檔案中的物理偏移量,之後就可以從CommitLog中獲取訊息內容。
消費者消費完畢之後,會儲存這個消費進度,對於叢集模式,消費進度會儲存在Borker端,Broker會定時將消費進度進行持久化,如果消費者剛啟動的時候,會向Broker發起請求獲取之前記錄的消費進度。
IndexFile
為了便於訊息查詢,RocketMQ還設計了IndexFile,支援根據Key對訊息進行查詢,在傳送訊息的時候可以設定一個唯一Keys值,用於標識這條訊息,之後就可以根據這個Keys值對訊息進行查詢。
Keys: 伺服器會根據 keys 建立雜湊索引,設定後,可以在 Console 系統根據 Topic、Keys 來查詢訊息,由於是雜湊索引,請儘可能保證 key 唯一,例如訂單號,商品 Id 等。
Message msg = new Message(topic, RandomUtils.getStringByUUID().getBytes());
// 訂單Id
String orderId = "20034568923546";
msg.setKeys(orderId);
IndexFile檔案結構
每個indexFile檔案的大小是固定的,一個IndexFile檔案大約可以儲存2000W個訊息的索引,IndexFile的檔案結構如下:

IndexHeader
index header記錄indexFile檔案的整體資訊,佔40個位元組,有以下資訊:

- beginTimestamp:當前indexFile檔案中第一條訊息的儲存時間;
- endTimestamp:當前indexFile檔案中最後一條訊息儲存時間;
- beginPhyoffset:當前indexFile檔案中第一條訊息在Commitlog中的偏移量;
- endPhyoffset:當前indexFile檔案中最後一條訊息在commitlog中的偏移量;
- hashSlotCount:已經使用的hash槽的個數;
- indexCount:索引項中記錄的所有訊息索引總數;
hash slot
RocketMQ在每個IndexFile檔案中劃分了500W個hash槽,在向檔案中新增訊息索引的時候,會取出訊息的Keys(實際會使用Topic + "#" + key進行拼裝做為IndexFile檔案的Key)計算hash值,然後對hash槽總數取餘,來判斷應該放到哪個hash槽。
index item
索引項中記錄每個Key的索引資訊,有以下部分組成:

- keyHash:訊息的key計算出來的的hashcode值,
- phyOffset:訊息在CommitLog中的物理偏移量;
- timeDiff:訊息的儲存時間減去IndexHeader中的beginTimestamp(當前indexFile檔案中第一條訊息的儲存時間);
- preIndexNo:當雜湊衝突的時候,用於指向上一個索引,可以看做當雜湊衝突的時候,使用一個連結串列將該雜湊槽下的所有元素串起來,使用頭插法增加新的元素;
訊息索引新增
舉個例子,比如現在有一條訊息,它的Key值1,假設雜湊槽的個數為10,這裡對雜湊計算簡化,直接用1對雜湊槽個數取餘,得到值為0,那麼這條訊息將落入雜湊槽0的位置,然後會在索引項區域建立該訊息的索引資訊:
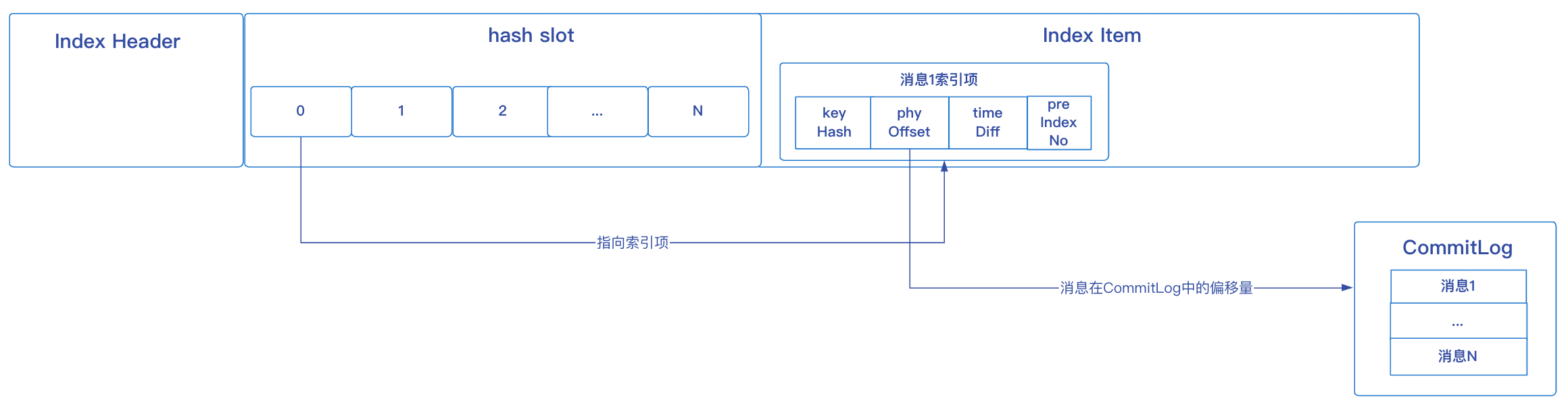
如果新增一條訊息2,它的Key值為2,用2對雜湊槽個數取餘,依舊得到雜湊槽0,此時產生雜湊衝突,將雜湊槽0處儲存的值改為訊息2的索引項,並將訊息2索引項中的preIndexNo指向訊息1的索引項,形成一個連結串列:

參考
孤翁-進階篇 RocketMQ 原理之key查詢
遲鈍先生-RocketMQ的Index File