手敲,Ascend運算元開發入門筆記分享
本文分享自華為雲社群《Ascend運算元開發入門筆記》,作者: JeffDing 。
基礎概念
什麼是Ascend C
Ascend C是CANN針對運算元開發場景推出的程式語言,原生支援C和C++標準規範,最大化匹配使用者開發習慣;通過多層介面抽象、自動平行計算、孿生偵錯等關鍵技術,極大提高運算元開發效率,助力AI開發者低成本完成運算元開發和模型調優部署。
使用Ascend C開發自定義運算元的優勢
- C/C++原語程式設計,最大化匹配使用者的開發習慣
- 程式設計模型遮蔽硬體差異,程式設計正規化提高開發效率
- 多層級API封裝,從簡單到靈活,兼顧易用與高效
- 孿生偵錯,CPU側模擬NPU側的行為,可優化在CPU側偵錯
昇騰計算架構CANN
CANN 介紹網站:https://www.hiascend.com/software/cann
AI Core是NPU卡的計算核心,NPU內部有多個AI Core。每個AI Core相當於多核CPU中的一個核心
SIMD
SIMD,也就是單指令多資料計算,一條指令可以處理多個資料:Ascend C程式設計API主要是向量計算API和矩陣運算API,計算API都是SIMD樣式
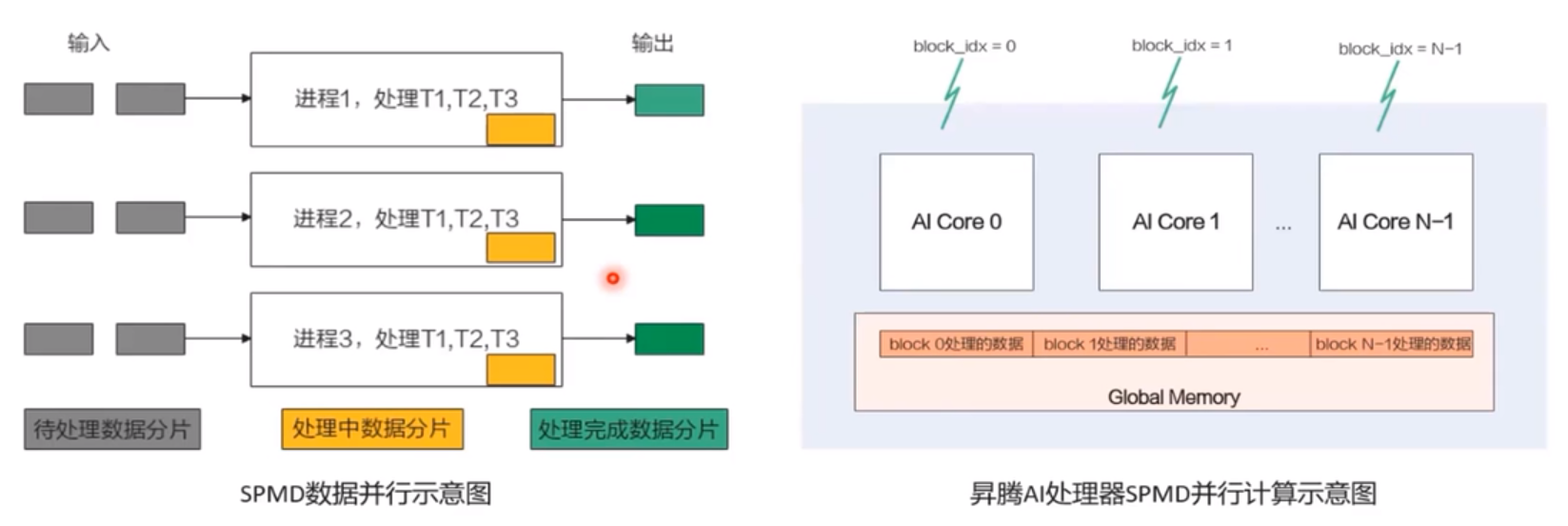
平行計算之SPMD資料並行與流線型並行
SPMD資料並行原理
- 啟動一組程序,他們執行的相同程式
- 把待處理資料切分,把切分後資料分片分發給不同程序處理
- 每個程序對自己的資料分片進行3個任務T1、T2、T3的處理
流水線並行原理
- 啟動一組程序
- 對資料進行切分
- 每個程序都處理所有的資料切片,對輸入資料分片只做一個任務的處理
Ascend C程式設計模型與正規化
平行計算架構抽象
使用Ascend C程式語言開發的運算元執行在AI Core上,AI Core是昇騰AI處理器中的計算核心
一個AI處理器內部有多個AI Core,AI Core中包含計算單元、儲存單元、搬運單元等核心元件
計算單元包括了三種基礎計算資源
- Scalar計算單元:執行地址計算、迴圈控制等標量計算工作,並把向量計算、矩陣計算、資料半圓、同步指令發射給對應單元執行
- Cube計算單元:負責執行矩陣運算
- Vector計算單元:負責執行向量計算
搬運單元負責在Global Memory和Local Memory之間搬運資料,包含搬運單元MTE(Memory Transfer Engine,資料搬入單元),MTE3(資料搬出單元)
儲存單元為AI Core的內部儲存,統稱為Local Memory與此相對應,AI Core的外部儲存稱之為Global Memory
非同步指令流
Scalar計算單元讀取指令序列,並把向量計算、矩陣計算、資料搬運指令發射給對應單元的指令佇列,向量計算單元、矩陣計算單元、資料搬運單元非同步的並行執行接收到的指令
同步訊號流
指令間可能存在依賴關係,為了保證不同指令佇列間的指令按照正確的邏輯關係執行,Scalar計算單元也會給對應單元下發同步指令
計算資料流
DMA搬入單元把資料搬運到Local Memory,Vector/Cube計算單元完成資料計算,並把計算結構寫回Local Memory,DMA搬出單元把處理好的資料搬運回Global Memory
SPMD程式設計模型介紹
Ascend C運算元程式設計是SPMD的程式設計,將需要處理的資料拆分並行分佈在多個計算核心上執行多個AI Core共用相同的指令程式碼,每個核上的執行範例唯一的區別是block_idx不同block的類似於程序,block_idx就是標識程序唯一性的程序ID,程式設計中使用函數GetBlockIdx()獲取ID
核函數編寫及呼叫
核函數(Kernel Function)是Acend C運算元裝置側的入口。Ascend C允許使用者使用核函數這種C/C++函數的語法擴充套件來管理裝置側的執行程式碼,使用者在核函數中實現運算元邏輯的編寫,例如自定義運算元類及其成員函數以實現該運算元的所有功能。核函數是主機側和裝置側連線的橋樑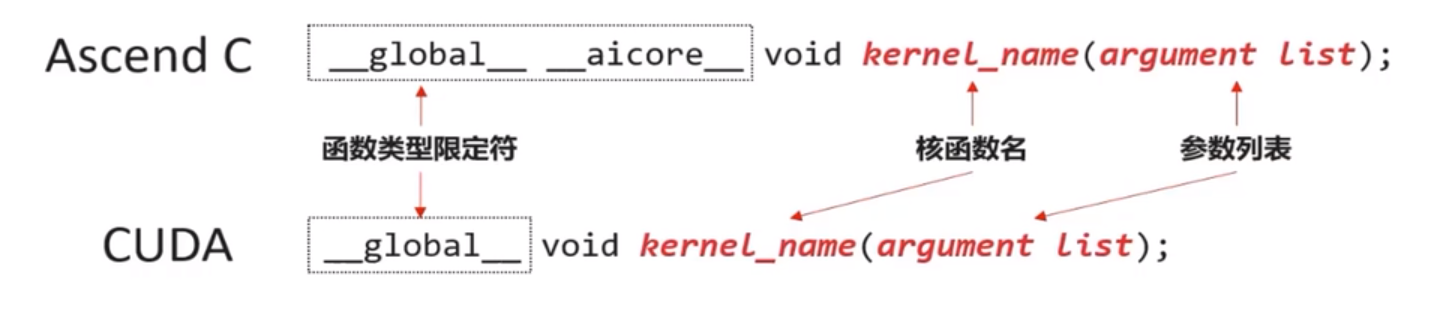
核函數是直接在裝置側執行的程式碼。在核函數中,需要為在一個核上執行的程式碼規定要進行的資料存取和計算操作,SPMD程式設計模型允許核函數呼叫時,多個核並行地執行同一個計算任務。
使用函數型別限定符
除了需要按照C/C++函數宣告的方式定義核函數之外,還要為核函數加上額外的函數型別限定符,包含__global__和__aicore__
使用__global__函數型別限定符來標識它是一個核函數,可以被<<<…>>>呼叫;使用__aicore__函數型別限定符來標識該函數在裝置側AI Core上執行
__gloabl__ __aircore__ void kernel_name(argument list);

使用變數型別限定符
為了方便:指標入參變數統一的型別定義為__gm__uint8_t*
使用者可統一使用uint8_t型別的指標,並在使用時轉化為實際的指標型別;亦可直接傳入實際的指標型別

規則或建議
- 核函數必須具有void返回型別
- 僅支援入參為指標型別或C/C++內建資料型別(Primitive Data Types),如:half* s0、flat* s1、int32_t c
- 提供了一個封裝的宏GM_ADDR來避免過長的函數入參列表
#define GM_ADDR __gm__ unit8_t* __restrict__
呼叫核函數
核函數的呼叫語句是C/C++函數呼叫語句的一種擴充套件
常見的C/C++函數呼叫方式是如下的形式:
function_name(argument list);
核函數使用內部呼叫符<<<…>>>這種語法形式,來規定核函數的執行設定:
kernel_name<<<blockDim, l2ctrl, stream>>>(argument list);
注:核心呼叫符僅可在NPU模式下編譯時呼叫,CPU模式下編譯無法識別該符號
blocakdim,規定了核函數將會在幾個核上執行,每個執行該核函數的核會被分配一個邏輯ID,表現為內建變數block_idx,編號從0開始,可為不同的邏輯核定義不同的行為,可以在運算元實現中使用GetBlockIDX()函數來獲得。
l2ctl,保留函數,展示設定為固定值nullptr。
stream:型別為aclrtStream,stream是一個任務佇列,應用程式通過stream來管理任務的並行
使用核心呼叫符<<<…>>>呼叫核函數:
HelloWorld<<<8, nullptr, stream>>>(fooDevice));
blockDim設定為8,表示在8個核上呼叫了HelloWorld核函數,每個核都會獨立且並行地執行該核函數Stream可以通過aclrtCreateStream來建立,它的作用是在當前程序或執行緒中顯式建立一個aclrtStream argument list設定為cooDevice這1個入參。
核函數的呼叫是非同步的,核函數的呼叫結束後,控制權立刻返回給主機側。
強制主機側程式等待所有核函數執行完畢的API(阻塞應用程式執行,直到指定Stream中的所有任務都完成,同步介面)為aclrtSynchronizeStream
aclError aclrtSynchronizeStream(aclrtStream stream);
程式設計API介紹
Ascend C運算元採用標準C++語法和一組類庫API進行程式設計
計算類API:標量計算API、向量計算API、矩陣計算API、分別實現呼叫Scalar計算單元、Vector計算單元、Cube計算單元
資料搬運API:基於Local Memory資料進行計算、資料需要先從Gloabl Memory搬運至Local Memory,再使用計算介面完成計算,最後從Local Memory搬出至Gloabl Memory。比如DataCopy介面
記憶體管理API:用於分配管理記憶體,比如AllocTensor、FreeTensor介面
任務同步API:完成任務間的通訊和同步,比如EnQue、DeQue介面。不同的指令非同步並行執行,為了保證不同指令佇列間的指令按照正確的邏輯關係執行,需要向不同的元件傳送同步指令
Ascend C API用於計算的基本資料型別都是Tensor:GlobalTensor和LocalTensor
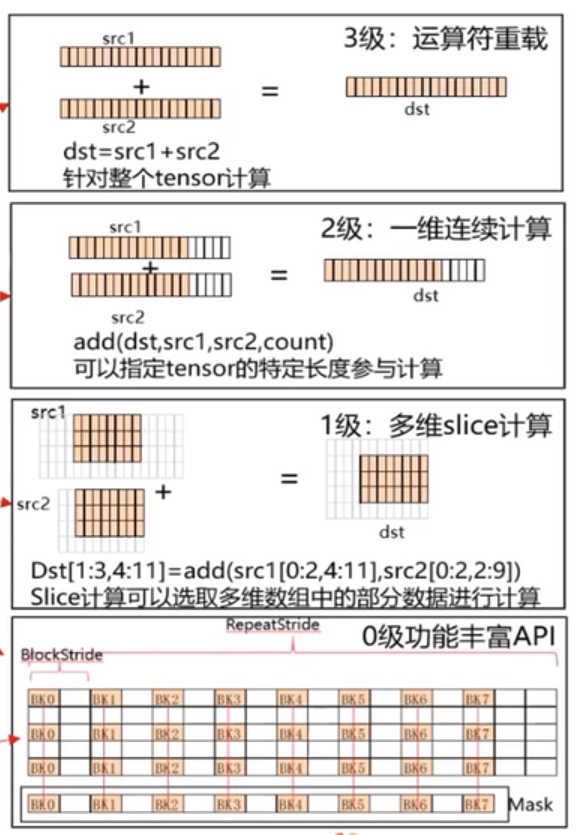
4級API定義
4級API定義:API根據使用者使用的場景分為4級
3級API,運運算元過載,支援+, - ,* ,/ ,= ,| ,& ,^ ,> ,< ,>- ,<= 實現計算的簡單表述,類似dst=src1+src2
2級連續計算API,類似Add(dst,src1,src2,count),針對源運算元的連續COUNT個資料進行計算連續寫入目的運算元,解決一維tensor的連續count個資料的計算問題
1級slice計算API,解決多維資料中的切片計算問題(開發中)
0級豐富功能計算API,可以完整發揮硬體優勢的計算API,該功能可以充分發揮CANN系列晶片的強大指令,支援對每個運算元的repeattimes,repetstride,MASK的操作。呼叫類似:Add(dst,src1,src2,repeatTimes,repeatParams);
流水程式設計正規化介紹
Ascend C程式設計正規化把運算元內部的處理程式,分成多個流水任務(Stage),以張量(Tensor)為資料載體,以佇列(Queue)進行任務之間的通訊與同步,以記憶體管理模組(Pipe)管理任務間的通訊記憶體。
- 快速開發程式設計的固定步驟
- 統一程式碼框架的開發捷徑
- 使用者總結出的開發經驗
- 面向特定場景的程式設計思想
- 客製化化的方法論開發體驗
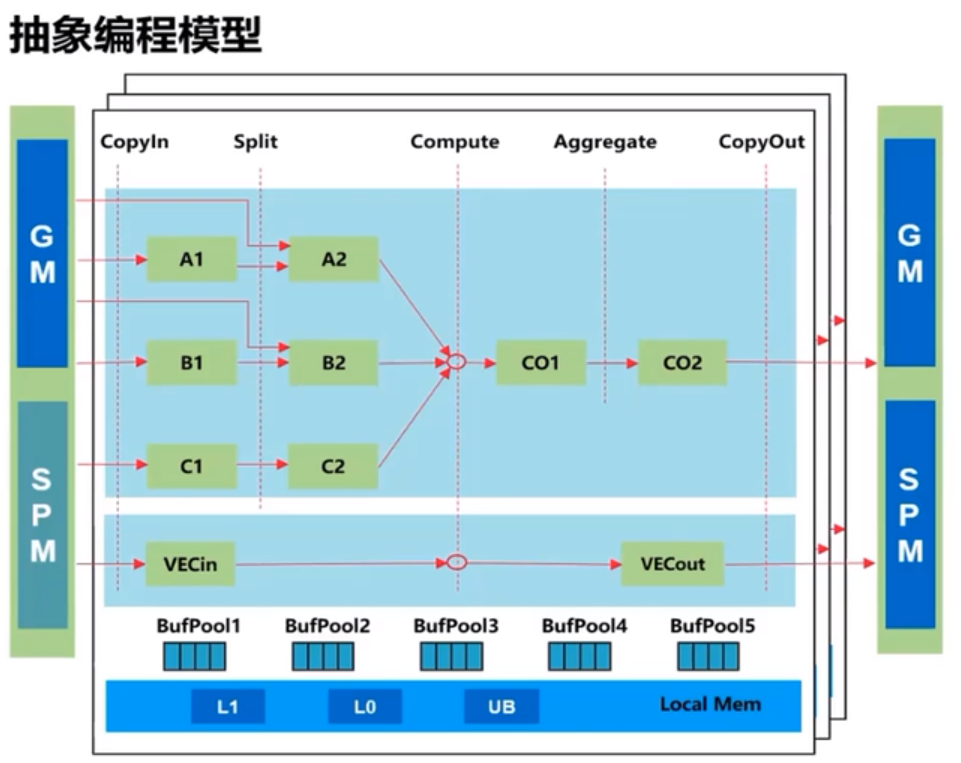
抽象程式設計模型「TPIPE平行計算"
針對各代Davinci晶片的複雜資料流,根據實際計算需求,抽象出並行程式設計正規化,簡化流水並行
Ascend C的並行程式設計式正規化核心要素
- 一組平行計算任務
- 通過佇列實現任務之間的通訊和同步
- 程式設計師自主表達對平行計算任務和資源的排程
- 基本的向量程式設計正規化:計算任務分為CopyIn,Compute,CopyOut
- 基本的矩陣程式設計正規化:計算任務分為CopyIn,Compute,Aggregate,CopyOut
- 複雜的向量/矩陣程式設計正規化,通過將向量/矩陣的Out/ln組合在一起的方式來實現複雜計算資料流
流水任務
流水任務(Stage)指的是單核處理程式中主程式排程的並行任務。
在核函數內部,可以通過流水任務實現資料的並行處理來提升效能
舉例來說,單核處理程式的功能可以拆分為3個流水任務:Stage1、Stage2、Stage3,每個任務專注資料切片的處理。Stage間的剪頭表達資料間的依賴,比如Stage1處理完Progress1之後,Stage2才能對Proress1進行處理。
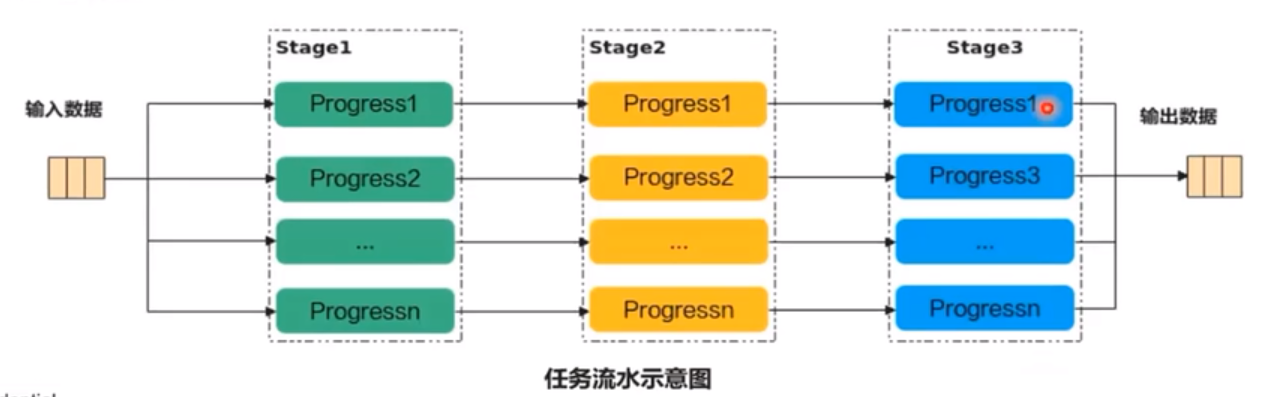
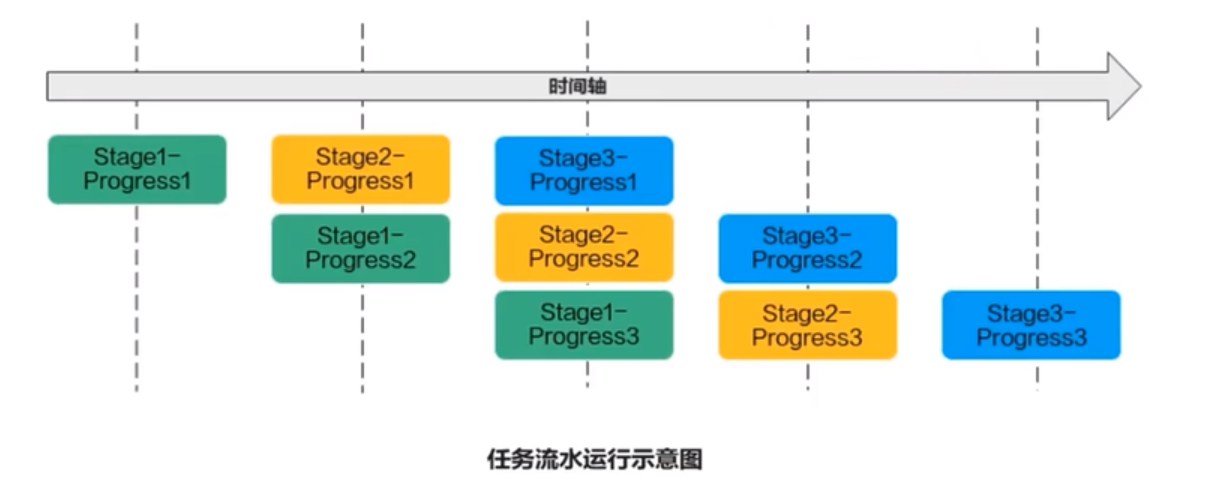
若Progres的n=3,待處理的資料被切分成3片,對於同一片資料,Stage1、Stage2、Stage3之間的處理具有依賴關係,需要序列處理;不同的資料切片,同一時間點,可以有多個流水任務Stage在並行處理,由此達到任務並行、提升效能的目的
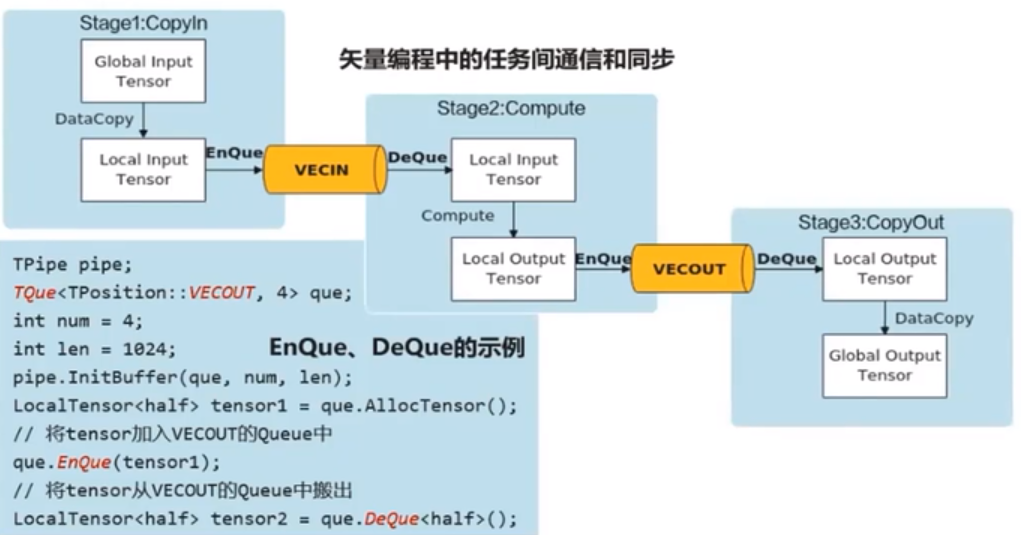
任務間通訊和同步
資料通訊與同步的管理者
Ascend C中使用Queue佇列完成任務之間的資料通訊和同步,Queue提供了EnQue、DeQue等基礎API。
Queue佇列管理NPU上不同層級的實體記憶體時,用一種抽象的邏輯位置(QuePosition)來表達各個級別的儲存(Storage Scope),代替了片上物理儲存的概念,開發者無需感知硬體架構。
向量程式設計中Queue型別(邏輯位置)包括:VECIN、VECOUT
資料的載體
Ascend C使用GlobalTensor和LocalTensor作為資料的基本操作單元,它是各種指令API直接呼叫的物件,也是資料的載體
向量程式設計任務間通訊和任務
向量程式設計中的邏輯位置(QuePosition):搬入資料的存放位置:VECIN、搬出資料的存放位置:VECOUT。
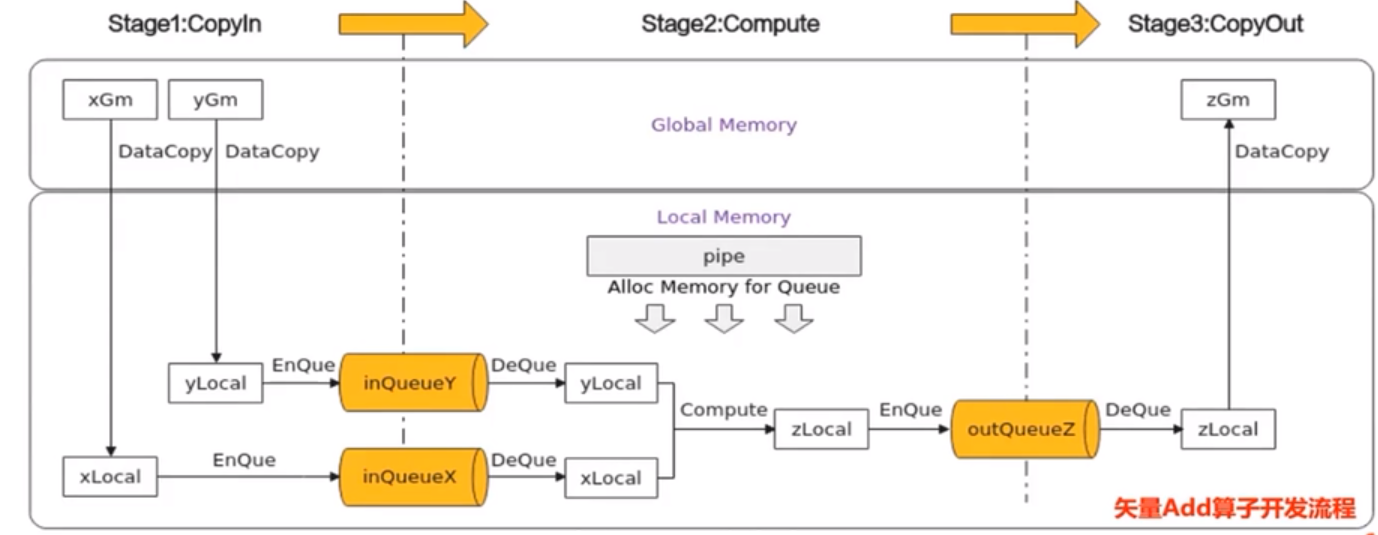
向量程式設計主要分為CopyIn、Compute、CopyOut三個任務
- CopyIn任務中將輸入資料從GlobalTensor搬運至LocalTensor後,需要使用EnQue將LocalTensor放入VECIN的Queue中
- Compute任務等待VECIN的Queue中LocalTensor出隊之後才可以進行向量計算,計算完成後使用EnQue將計算結果LocalTensor放入VECOUT的Queue中
- CopyOut任務等待VECOUT的Queue中Localtensor出隊,再將其拷貝至GlobalTensor
Stage1:CopyIn任務
使用DataCopy介面將GlobalTensor拷貝紙LocalTensor
使用EnQue將LocalTensor放入VECIN的Queue中
Stage2:Compute任務
使用DeQue從VECIN中取出LocalTensor
使用Ascend C指令API完成向量計算:Add
使用EnQue將結果LocalTensor放入VECOUT的Queue中
Stage3:CopyOut任務
使用DeQue介面從VECOUT的Queue中取出LocalTensor
使用DataCopy介面將LocalTensor拷貝至GlobalTensor
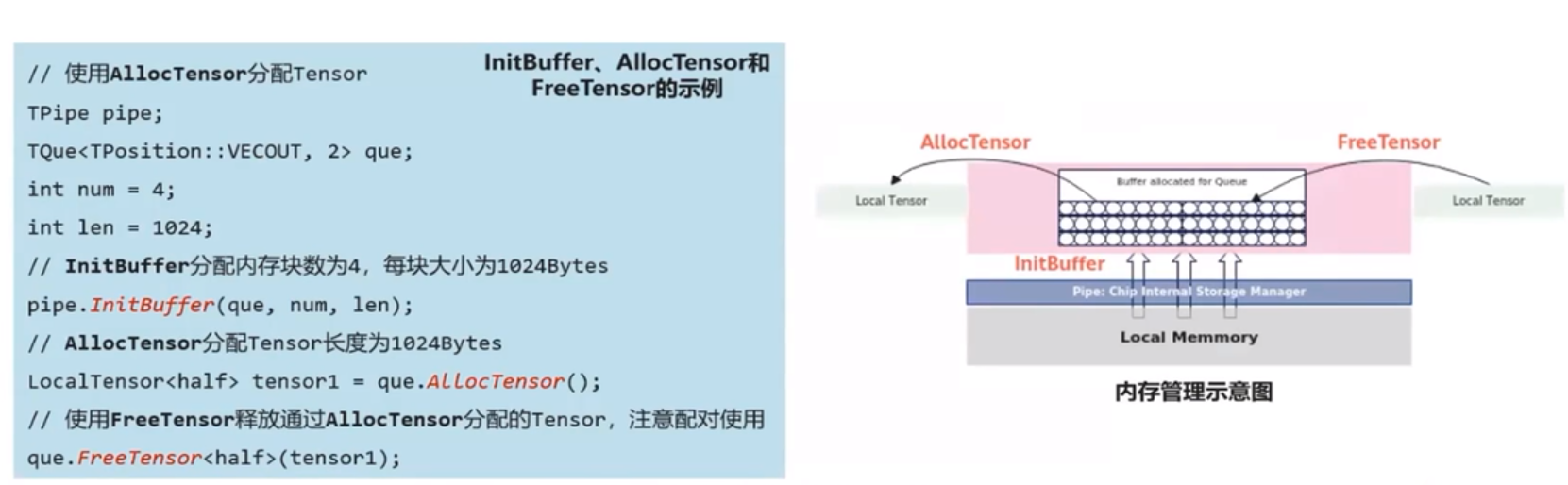
記憶體管理
任務見資料傳遞使用到的記憶體統一由記憶體管理模組Pipe進行管理。
Pipe作為片上記憶體管理者,通過InitBuffer介面對外提供Queue記憶體初始化功能,開發者可以通過該介面為指定的Queue分配記憶體。
Queue佇列記憶體初始化完成後,需要使用記憶體時,通過呼叫AllocTensor來為LocalTensor分配記憶體給Tensor,當建立的LocalTensor完成相關計算無需再使用時,再呼叫FreeTensor來回收LocalTensor的記憶體
臨時變數記憶體管理
程式設計過程中使用到的臨時變數記憶體同樣通過Pipe進行管理。臨時變數可以使用TBuf資料結構來申請指定QuePosition上的儲存空間,並使用Get()來將分配到的儲存空間分配給新的LocalTensor從TBuf上獲取全部長度,或者獲取指定長度的LocalTensor
LocalTensor<T> Get<T>();
LocalTensor<T> Get<T>(uint32_t len);
Tbuf及Get介面的範例
//為TBuf初始化分配記憶體,分配記憶體長度為1024位元組 TPipe pipe; TBuf<TPosition::VECIN> calcBuf; //模板引數為QuePosition中的VECIN型別 uint32_t byteLen = 1024; pipe.InitBuffer(calcBuf,byteLen); //從calcBuf獲取Tensor,Tensor為pipe分配的所有記憶體大小,為1024位元組 LocalTensor<int32_t> tempTensor1 = calcBuf.Get<int32_t>(); //從calcBuf獲取Tensor,Tensor為128個int32_t型別元素的記憶體大小,為512位元組 LocalTensro<int32_t> tempTensor1 = calcBuf.Get<int32_t>(128);
使用TBuf申請的記憶體空間只能參與計算,無法執行Queue佇列的入隊出隊操作
Ascend C向量程式設計
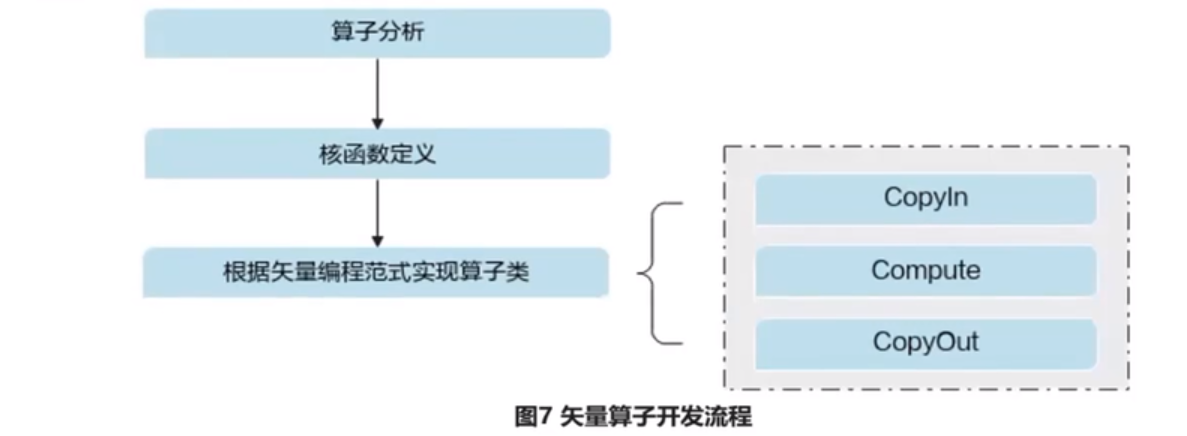
運算元分析
開發流程
運算元分析:分析運算元的數學表示式、輸入、輸出以及計算邏輯的實現,明確需要呼叫的Ascend介面
核函數定義:定義Ascend運算元入口函數
根據向量程式設計正規化實現運算元類:完成核函數的內部實現
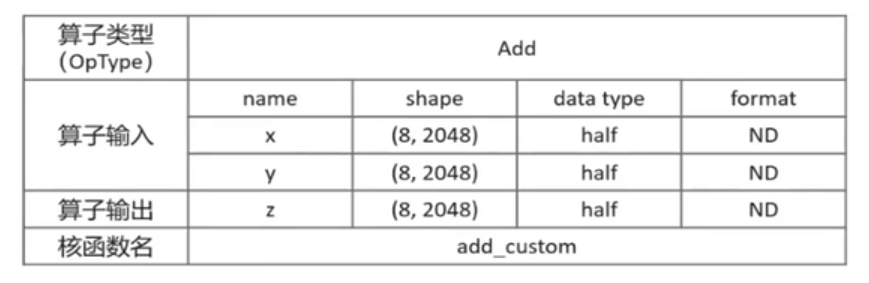
以ElemWise(ADD)運算元為,數學公式

為簡單起見,設定張量x,y,z為固定shape(8,2048),資料型別dtype為half型別,資料排布型別format為ND,核函數名稱為add_custom
運算元分析
明確運算元的數學表示式及計算邏輯
Add運算元的數學表示式為
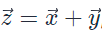
計算邏輯:輸入資料需要先搬入到片上儲存,然後使用計算介面完成兩個加法運算,得到最終結果,再搬出到外部儲存
明確輸入輸出
Add運算元有兩個:
輸入資料型別為half,輸出資料型別與輸入資料型別相同。輸入支援固定shape(8,2048),輸出shape與輸入shape相同,輸入資料排布型別為ND
確定核函數名稱和引數
自定義核函數明,如add_custom,根據輸入輸出,確定核函數有3個入參x,y,z
x,y為輸入在GlobalMemory上的記憶體地址,z為輸出在globalMemory上的記憶體地址
確定運算元實現所需介面
涉及內外部儲存間的資料搬運,使用資料搬移介面:DataCopy實現
涉及向量計算的加法操作,使用向量雙目指令:Add實現
使用到LocalTensor,使用Queue佇列管理,會使用到Enque,Deque等介面。
運算元實現
核函數定義
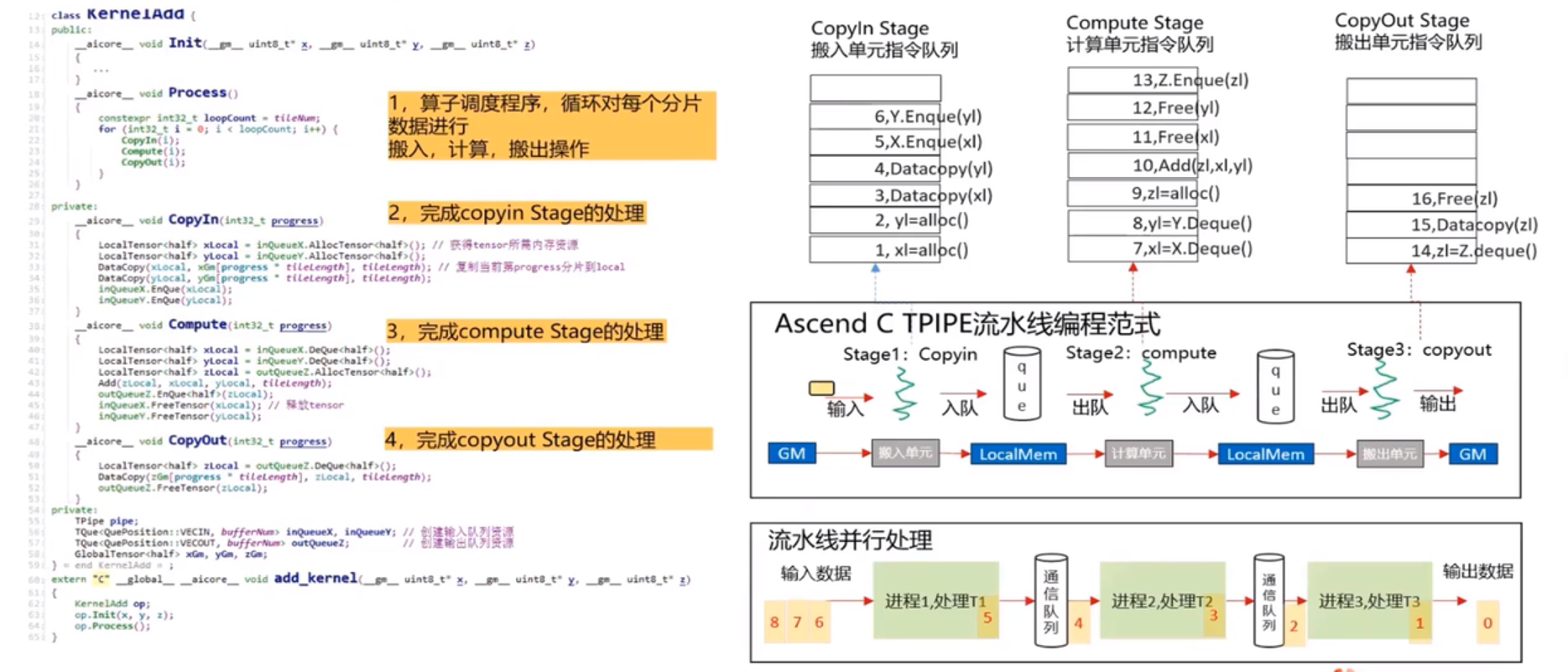
在add_custom核函數的實現中範例化KernelAdd運算元類,呼叫Init()函數完成記憶體初始化,呼叫Process()函數完成核心邏輯。
注:運算元類和成員函數名無特殊要求,開發者可根據自身的C/C++編碼習慣,決定核函數中的具體實現。
// implementation of kenel function extern "C" __global__ __aicore__ void add_custom(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z) { kernelAdd op; op.Init(x,y,z); op.Process(); }
對於核函數的呼叫,使用內建宏__CCE_KT_TEST__來標識<<<…>>>僅在NPU模式下才會編譯到(CPU模式g++沒有<<<…>>>的表達),對核函數的呼叫進行封裝,可以在封裝函數中補充其他邏輯,這裡僅展示對於核函數的呼叫。
#ifndef __CCE_KT_TEST__ // call of kernel function void add_custom_do(uint32_t blockDim, void* l2ctrl, void* stream, uint8_t* x, uint8_t* y, uint8_t* z) { add_custom<<<blockDim, l2ctrl, stream>>>(x,y,z); }
運算元類實現
CopyIn任務:將Global Memory上的輸入Tensor xGm和yGm搬運至Local Memory,分別儲存在xlocal,ylocal。
Compute任務:對xLocal,yLocal執行加法操作,計算結果儲存在zlocal中。
CopyOut任務:將輸出資料從zlocal搬運至Global Memory上的輸出tensor zGm中。
CopyIn.Compute任務間通過VECIN佇列和inQueueX,inQueueY進行通訊和同步。
Compute,CopyOut任務間通過VECOUT和outQueueZ進行通訊和同步。
pipe記憶體管理物件對任務間互動使用到的記憶體、臨時變數是用到的記憶體進行統一管理。
向量加法z=x+y 程式碼樣例 TPIPE流水式程式設計正規化
運算元類實現
運算元類類名: KernelAdd
初始化函數Init()和核心處理常式Process()
三個流水任務:CopyIn(),Compute(),CopyOut()
Process的含義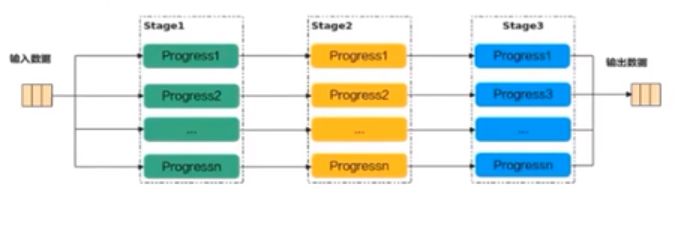
TQue模板的BUFFER)NUM的含義:
該Queue的深度,double buffer優化技巧
class KernelAdd{ public: __aicore__ inline KernelAdd() //初始化函數,完成記憶體初始化相關操作 __aicore__ inline voide Init(__gm__ uint8_t* x, __gm__ uint8_t* y, __gm__ uint8_t* z){} // 核心處理常式,實現運算元邏輯,呼叫私有成員函數CopyIn,Compute,CopyOut完成運算元邏輯 __aicore__ inline void Process(){} private: // 搬入函數,完成CopyIn階段的處理,被Process函數呼叫 __aicore__ inline void CopyIn(int32_t process){} // 計算函數,完成Compute階段的處理,被Process函數呼叫 __aicore__ inline void Compute(int32_t process){} // 搬出函數,完成CopyOut階段的處理,被Process函數呼叫 __aicore__ inline void CopyOut(int32_t process){} private: // pipe記憶體管理物件 TPipe pipe; // 輸入資料Queue佇列管理物件,QuePosition為VECIN TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; // 輸出資料Queue佇列管理物件,QuePosition為VECOUT TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; // 管理輸入輸出的Global Memory記憶體地址的物件,其中xGm,yGm為輸入,zGm為輸出 GlobalTensor<half> xGm, yGm ,zGm; };
Init()函數實現
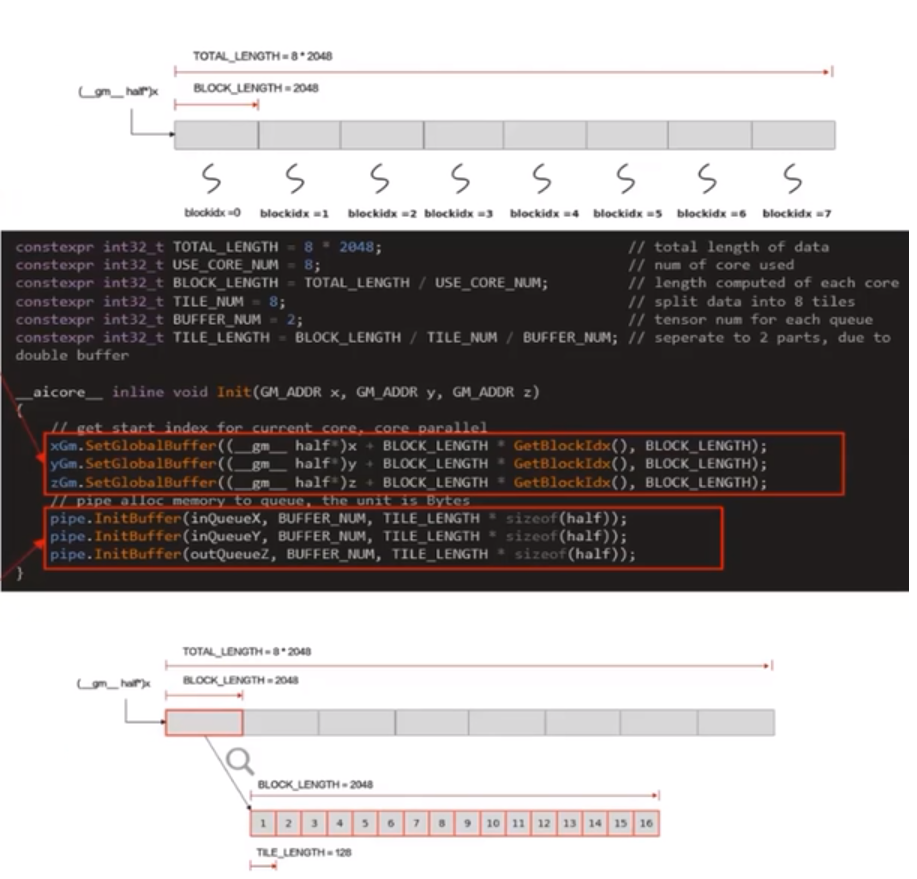
使用多核平行計算,需要將資料切片,獲取到每個核實際需要處理的在Global Memory上的記憶體偏移地址。
資料整體長度TOTAL_LENGTH為8 * 2048,平均分配到8個核上執行,每個核上處理的資料大小BLOCK_LENGTH為2048,block_idx為核的邏輯ID,(gm half*)x + GetBlockIdx() *
BLOCK_LENGTH即索引為block_idx的核的輸入資料在Global Memory上的記憶體偏移地址
對於單核處理資料,可以進行資料切塊(Tiling),將資料切分成8快,切分後的每個資料塊再次切分成BUFFER_NUM=2塊,可開啟double buffer,實現流水線之間的並行。
單核需要處理的2048個資料切分成16塊,每塊TILE_LENGTH=128個資料,Pipe為inQueueX分配了BUFFER_NUM塊大小為TITLE_LENGTH * sizeof(half)個位元組的記憶體塊,每個記憶體塊能容納TILE_LENGTH=128個half型別資料
程式碼範例
constexpr int32_t TOTAL_LENGTH = 8 * 2048; //total length of data constexpr int32_t USE_CORE_NUM = 8; //num of core used constexpr int32_t BLOCK_LENGTH = TOTAL_LENGTH / USE_CORE_NUM; //length computed of each ccore constexpr int32_t TILE_NUM = 8; //split data into 8 tiles constexpr int32_t BUFFER_NUM = 2; //tensor num for each queue constexpr int32_t TILE_LENGTH = BLOCK_LENGTH / TILE_NUM / BUFFER_NUM; //seperate to 2 parts, due to double buffer __aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z) { //get start index for current core,core parallel xGm,SetGlobalBuffer((__gm__ half*)x * BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); yGm,SetGlobalBuffer((__gm__ half*)y * BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); zGm,SetGlobalBuffer((__gm__ half*)z * BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH); //pipe alloc memory to queue,the unit is Bytes pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half)); pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half)); pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half)); }
Process()函數實現
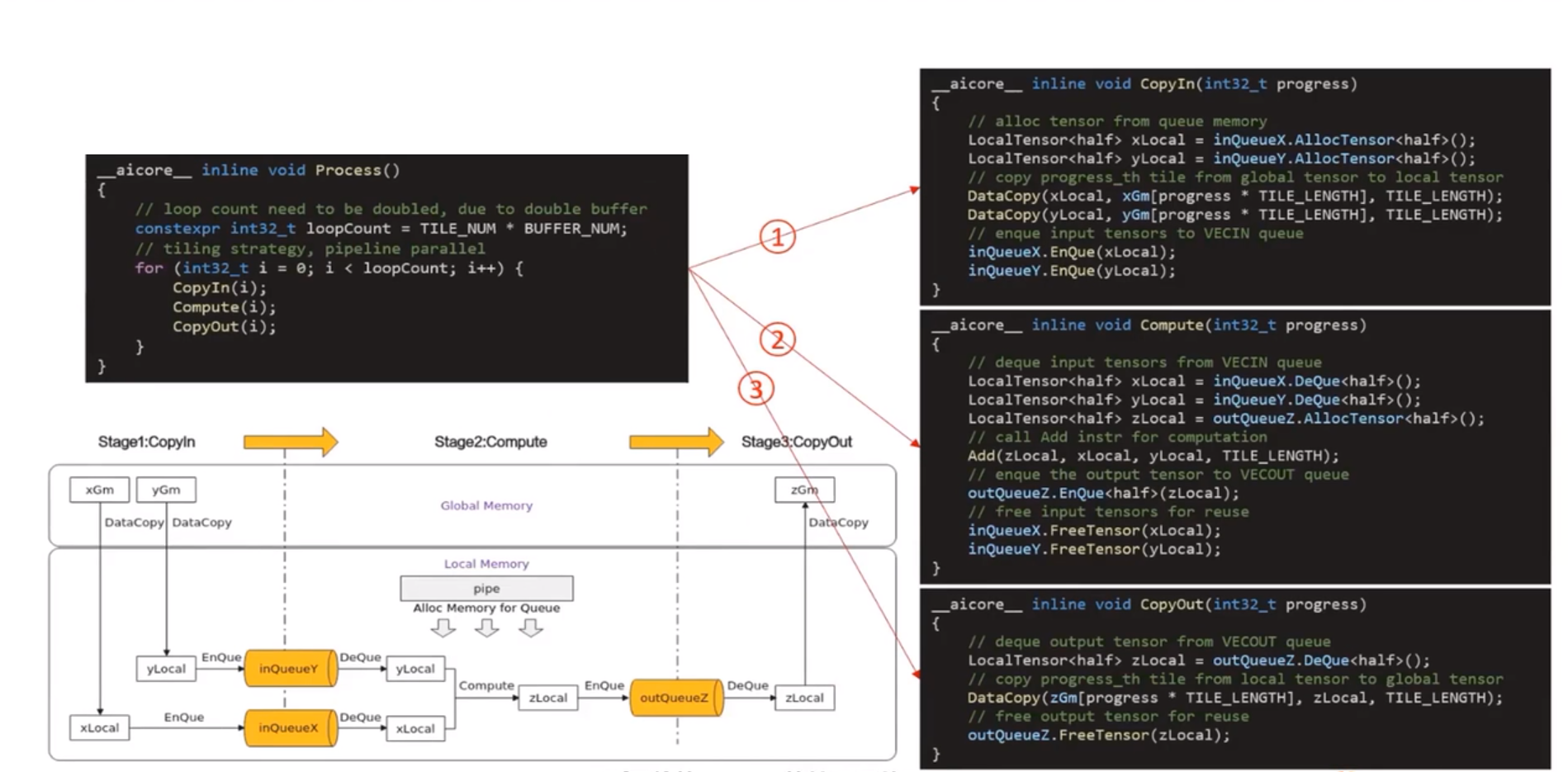
程式碼範例
__aicore__ inline void Process() { // loop count need to be doubled, due to double buffer constexpr int32_t loopCount = TILE_NUM * BUFFER_BUM; // tiling strategy, pipeline prallel for (int32_t i = 0; i < loopCount; i++) { CopyIn(i); Compute(i); CopyOut(i); } } __aicore__ inline void CopyIn(int32_t progress) { // alloc tensor from queue memory LocalTensor<half> xLocal = inQueueX.AllocTensor<half>(); LocalTensor<half> yLocal = inQueueY.AllocTensor<half>(); // copy progress_th tile from global tensor to local tensor DataCopy(xLocal,xGm[progress * TILE_LENGTH], TILE_LENGTH); DataCopy(xLocal,yGm[progress * TILE_LENGTH], TILE_LENGTH); // enque input tensors to VECIN queue inQueueX.EnQue(xLocal); inQueueY.EnQue(yLocal); } __aicore__ inline void Compute(int32_t progress) { //dque input tensors from VECIN queue LocalTensor<half> xLocal = inQueueX.DeQue<half>(); LocalTensor<half> yLocal = inQueueY.DeQue<half>(); LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>(); // call Add instr for computation Add(zLocal, xLocal, yLocal, TILE_LENGTH); // enque the output tensor to VECOUT queue outQueueZ.EnQue<half>(zLocal)l // free input tensors for reuse inQueueX.FreeTensor(xLocal); inQueueY.FreeTensor(yLocal); } __aicore__ inline void CopyOut(int32_t progress) { //deque output tensor form VECOUT queue LocalTensor<half> zLocal = outQueueZ.Deque<half>(); // copy progress_th tile form local tensor to global tensor DataCopy(zGm[progress * TILE_LENGTH), zlocal, TILE_LENGTH); // free outpupt tensor for reuse outQueueZ.freeTensor(zLocal); }
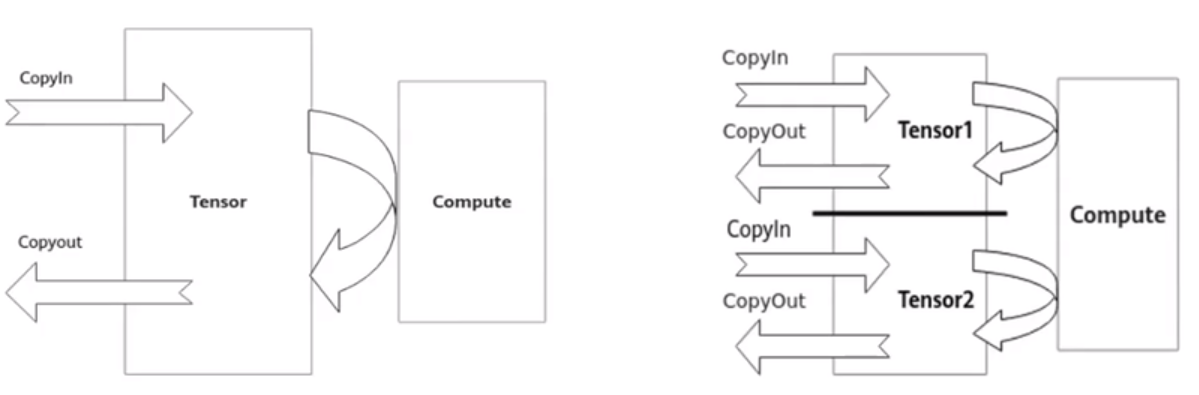
double buffer機制
double buffer通過將資料搬運與向量計算並執行以隱藏資料搬運時間並降低向量指令的等待時間,最終提高向量計算單元的利用效率1個Tensor同一時間只能進行搬入、計算和搬出三個流水任務中的一個,其他兩個流水任務涉及的硬體但願則處於Idle狀態。
如果將待處理的資料一分為而,比如Tensor1、Tensor2。
- 當向量計算單元對於Tensor1進行Compute時,Tensor2可以進行CopyIn的任務
- 當向量計算單元對於Tensor2進行Compute時,Tensor1可以進行CopyOut的任務
- 當向量計算單元對於Tensor2進行CopyOut時,Tensor2可以進行CopyIn的任務
由此,資料的進出搬運和向量計算之間實現你並行,硬體單元閒置問題得以有效緩解
Ascend C 運算元呼叫
HelloWorld樣例
執行CPU模式包含的標頭檔案
執行NPU模式包含的標頭檔案
核函數的定義
內建宏__CE_KT_TEST__:區分執行CPU模式或NPU模式邏輯的標誌
主機側執行邏輯:負責資料在主機側記憶體的申請,主機到裝置的拷貝,核函數執行同步和回收資源的工作
裝置側執行邏輯
主機側執行CPU模式邏輯:使用封裝的執行宏ICPU_RUN_KF
主要包括:
gMAlloc(…):申請CPU模式下的記憶體空間
ICPU_RUN_KF:使用封裝的執行宏
GmFree:釋放CPU模式下的記憶體空間
流程
AscendCL初始化—>執行管理資源申請—>Host資料傳輸至Device—>執行任務並等待—>Device資料傳輸至Host—>執行資源釋放—>AscendCL去初始化
主機側執行NPU模式邏輯:使用核心呼叫符<<<…>>>
重要介面- aclInit
- aclCreateStream
- aclMallocHost
- aclMalloc
- aclMemcpy
- <<<…>>>
- aclrtSynchronizeStream
- aclrtFree
- aclrtfreeHost
- aclrtDestoryStream
- aclFinalize
AddCustom樣例
Ascend C向量運算元樣例程式碼
- 核函數原始檔:add_custom.app
- 真值資料生成指令碼:add_custom.py
- CmakeLists.txt:方便對多個原始檔進行編譯
- 讀寫資料檔案輔助函數:data_utils.h
- 主機側原始檔:main.cpp
- 一鍵執行指令碼:run.sh
- 組織CPU模式和NPU模式下編譯的cmake指令碼