JuiceFS 目錄配額功能設計詳解
JuiceFS 在最近 v1.1 版本中加入了社群中呼聲已久的目錄配額功能。已釋出的命令支援為目錄設定配額、獲取目錄配額資訊、列出所有目錄配額等。完整的詳細資訊,請查閱檔案。
在設計此功能時,對於它的統計準確性,實效性以及對效能的影響,團隊內部經歷過多次討論和權衡。在本文中,我們會詳述一些在設計關鍵功能時的不同抉擇及其優缺點,並分享最終的實現方案,為想深入瞭解目錄配額或有相似開發需求的使用者提供參考。
01 需求分析
配額的設計首先需考慮以下三個要素:
-
統計的維度:常見的是基於目錄來統計用量和實現限制,其他還有基於使用者和使用者組的統計
-
統計的資源:一般包括檔案總容量和檔案總數量
-
限制的方式:最簡單的就是當使用量達到預定值時,就不讓應用繼續寫入。這種預定值一般稱為硬閾值(Hard Limit)。還有一種常見的限制叫做軟閾值(Soft Limit),在使用量達到這個值時,僅觸發告警通知但不立即限制寫入,而是在達到硬閾值或者經過一定的寬限時間(Grace Period)後再實施限制。
其次,也應考慮對配額統計實效性和準確性的要求。在分散式系統中,往往會有多個使用者端同時存取,若要保證他們在同一時間點對配額的檢視始終一致,勢必會對效能有比較大的影響。最後,還應考慮是否支援複雜的設定,如配額巢狀、為非空目錄設定配額等。
開發原則
我們的主要考量是儘量簡單和便於管理。在實現時避免大規模程式碼重構,減少對關鍵讀寫路徑的侵入,以期在實現新特性的同時,不會對現有系統的穩定性和效能造成較大影響。基於此,我們整理出瞭如下表所示的待開發功能:
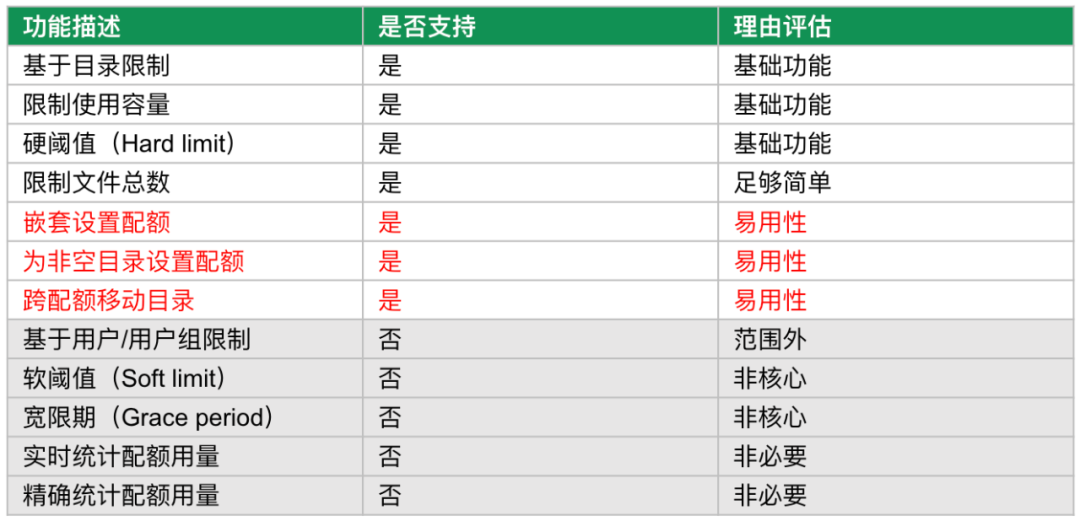
值得一提的是表中標紅的三項。一開始我們並不打算支援這些,因為它們的複雜性對配額功能的整體實現構成了挑戰,而且也不在我們定義的核心功能之列。但在與多方使用者溝通後,我們意識到缺少這些功能會導致配額功能的實用性大打折扣,許多使用者確實需要這些功能來滿足他們的實際需求。因此,最終我們還是決定在 v1.1 版本中就帶入這些功能。
02 基礎功能
1 使用者介面
在設計配額功能時,首先要考慮的是使用者如何設定和管理配額。這一般有兩種方式:
1.使用特定的命令列工具,如 GlusterFS 使用以下命令為指定目錄設定硬閾值:
$ gluster volume quota <VOLNAME> limit-usage <DIR> <HARD_LIMIT>
2.藉助已有的 Linux 工具,但使用特定的欄位;如 CephFS 將配額作為一項特殊的擴充套件屬性來管理:
$ setfattr -n ceph.quota.max_bytes -v 100000000 /some/dir # 100 MB
JuiceFS 採用了第一種方式,命令形式為:
$ juicefs quota set <METAURL> --path <PATH> --capacity <LIMIT> --inodes <LIMIT>
做出這個選擇主要有以下三點理由:
-
JuiceFS 已有現成的 CLI 工具,要新增配額管理功能只需新加一個子命令即可,非常方便。
-
配額通常應由管理員來進行設定,普通使用者不能隨意更改;自定義的命令中可要求提供 METAURL 來保證許可權。
-
第二種方式需要提前將檔案系統掛載到本地。配額設定常需對接管控平臺,將目錄路徑作為引數直接包含在命令中可以避免此步驟,使用起來更加方便。
2 後設資料結構
JuiceFS 支援三大類後設資料引擎,包括 Redis,SQL 類(MySQL、PostgreSQL、SQLite 等)和 TKV 類(TiKV、FoundationDB、BadgerDB 等)。每類引擎根據其支援的資料結構有不同的具體實現,但管理的資訊大體上是一致的。在上一小節我們已決定使用獨立的 juicefs quota 命令來管理配額,那麼後設資料引擎中也同樣使用獨立的欄位來儲存相關資訊。以較簡單的 SQL 類為例:
// SQL table
type dirQuota struct {
Inode Ino `xorm:」pk」`
MaxSpace int64 `xorm:」notnull」`
MaxInodes int64 `xorm:」notnull」`
UsedSpace int64 `xorm:」notnull」`
UsedInodes int64 `xorm:」notnull」`
}
可見,JuiceFS 為目錄配額新建了一張表,以目錄索引號(Inode)為主鍵,儲存了配額中容量和檔案數的閾值以及已使用值。
3 配額更新/檢查
接下來考慮配額資訊的維護,主要是兩個任務:更新和檢查。
更新配額通常牽涉到新建和刪除檔案或目錄,這些操作都會對檔案個數產生影響。此外,檔案的寫入操作會對配額的使用容量產生影響。實現上最直接的方式是在每個請求完成更新後,同時將更改提交到資料庫。這可以確保統計資訊的實時性和準確性,但很容易造成嚴重的後設資料事務衝突。
究其原因,是因為在 JuiceFS 的架構中,沒有獨立的後設資料服務程序,而是由多個使用者端以樂觀事務的形式並行將修改提交到後設資料引擎。一旦它們在短時間內嘗試更改同一個欄位(比如配額的使用量),就會引發嚴重的衝突。
因此,JuiceFS 的做法是在每個使用者端記憶體中同步維護配額相關的快取,並將本地更新每隔 3 秒非同步地提交到資料庫。這樣做犧牲了一定的實時性,但可以有效減少請求個數和事務衝突。此外,使用者端在每個心跳週期(預設 12 秒)從後設資料引擎載入最新資訊,包括配額閾值和使用量,以瞭解檔案系統全域性的情況。
配額檢查與更新類似,但更為簡單。在執行操作之前,如有必要使用者端可直接在記憶體中進行同步檢查,並在檢查通過後才繼續後面的流程。
03 複雜功能設計
本章討論目錄配額中相對複雜的兩個功能(即第一章需求表中標紅項)的設計思路。
功能1:配額巢狀
在與使用者進行溝通時,我們經常面臨這樣的需求:某個部門設定了一個大型的配額,但在該部門內部可能還有小組或個人,而這些個體也需要各自的配額。
這裡就需要對配額增加巢狀結構。如果不考慮巢狀,每個目錄只有兩種狀態:沒有配額或者只受一個配額限制,整體維護比較簡單。一旦引入巢狀結構,情況就會變得相對複雜。例如,在更新檔案時,我們需要找到所有受影響的配額並對其進行檢查或更改。那麼在給定目錄後,如何快速找到其所有受影響的配額呢?
方案一:快取 Quota 樹以及目錄到最近 Quota 的對映
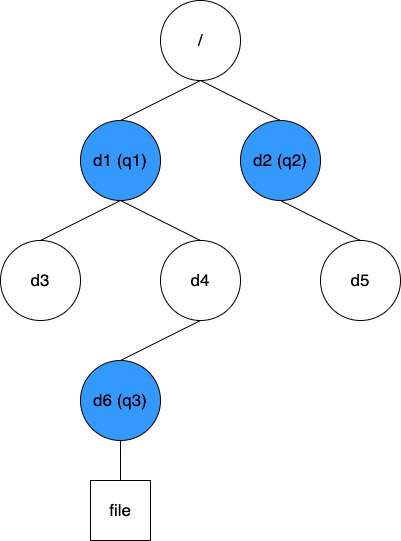
這個方案比較簡單直接,即維護配額間相互的巢狀結構,以及每個目錄到最近配額的對映資訊。針對上圖的資料結構如下:
// quotaTree map[quotaID]quotaID
{q1: 0, q2:0, q3: q1}
// dirQuotas map[Inode]quotaID
{d1: q1, d3: q1, d4: q1, d6: q3, d2: q2, d5: q2}
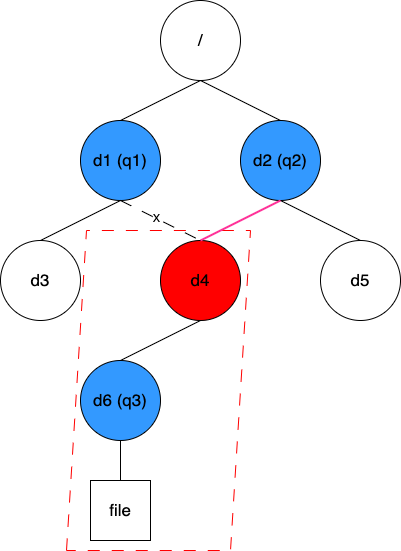
有了這些資訊,在配額更新或查詢時,我們可以根據操作的目錄 Inode 快速找到最近的配額 ID,再根據 quotaTree 逐級找到所有受影響的配額。這個方案能實現高效的查詢,從靜態角度來看,是有優勢的。然而,某些動態變化會難以處理。考慮如下圖所示場景:
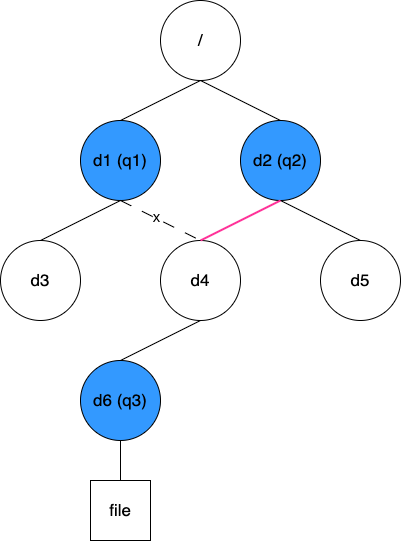
現在需要將目錄 d4 從原來的 d1 移動到 d2 下。這個操作中 q3 的父配額從 q1 變成了 q2,但由於 q3 被設定在 d6 上,這個變化很難被感知到(我們可以在移動 d4 的同時遍歷其下所有目錄看它們是否有配額,但顯然這會是個大工程)。鑑於此,這個方案並不可取。
方案二:快取目錄到父目錄的對映關係
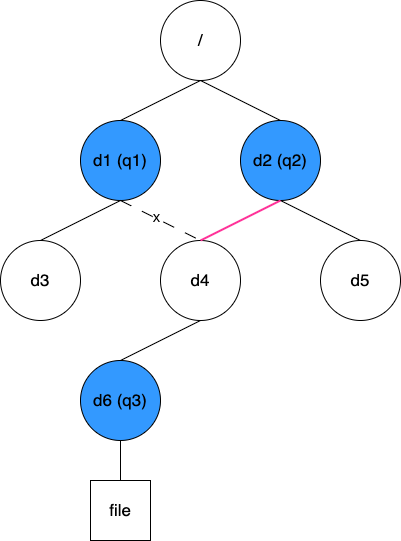
第二個方案是快取所有目錄到其父目錄的對映關係,針對上圖的初始資料結構如下:
// dirParent map[Inode]Inode
{d1: 1, d3: d1, d4: d1, d6: d4, d2: 1, d5: d2}
同樣的修改操作,這時僅需將 d4 的值由 d1 改成 d2 即可。此方案中,在查詢某個目錄所有受影響的配額時,我們需要根據 dirParent 逐級往上直到根目錄,在過程中檢查每個路過的目錄是否設定了配額。顯然,這個方案的查詢效率相比之前的方案略低。但好在這些資訊都快取在使用者端記憶體中,整體效率依然在可接受範圍內,因此我們最終採用了這個方案。
值得一提的是,這個目錄到父目錄的對映關係是常駐使用者端記憶體的,沒有設定特定的過期策略,這主要有兩個角度的考慮:
-
通常情況下,檔案系統的目錄數量不會非常大,僅用少量記憶體即可將其全部快取起來。
-
其他使用者端對目錄的更改,在本使用者端中並不需要立即感知;當本使用者端再次存取相關目錄時,會通過核心下發的查詢(Lookup)或讀取目錄(Readdir)請求更新快取。
功能2:遞迴統計
在需求分析階段,除了巢狀配額外,還出現了兩個相關的問題:一是為非空目錄設定配額,二是目錄移動之後產生配額變化。這兩個問題其實本質上是同一個,那就是 「如何快速地獲取某個目錄樹的統計資訊」。
方案一:預設為每個目錄新增遞迴統計資訊
這個方案有點像前面的配額巢狀功能,只是現在需要為每個目錄都加上遞迴統計資訊,數量上會比配額多不少。它的好處是使用時比較方便,僅需一次查詢就能立即知道指定目錄下整棵樹的大小。這個方案的代價是維護成本較高,在修改任一檔案時,都需要逐級往上修改每個目錄的遞迴統計資訊。這樣越靠近根節點的目錄被修改的越頻繁。JuiceFS 的後設資料實現均採用樂觀鎖機制,即在發現衝突時通過重試來解決,在高壓力情況下,部分目錄的修改事務會衝突得非常嚴重。而且隨著叢集規模的擴大,頻繁重試還會導致後設資料引擎壓力急劇上升,容易導致崩潰。
方案二:平時不干預,只有在需要時,才對指定目錄樹進行臨時掃描
這是一個很簡單而直接的方案。其問題在於當目錄下的檔案數量龐大時,臨時掃描可能會耗時非常久。同時,這也會對後設資料引擎產生很高的爆發壓力。因此,這個方案也不適合拿來直接使用。
方案三:平時只維護每個目錄下一級子項的使用量,需要時掃描指定樹下所有目錄
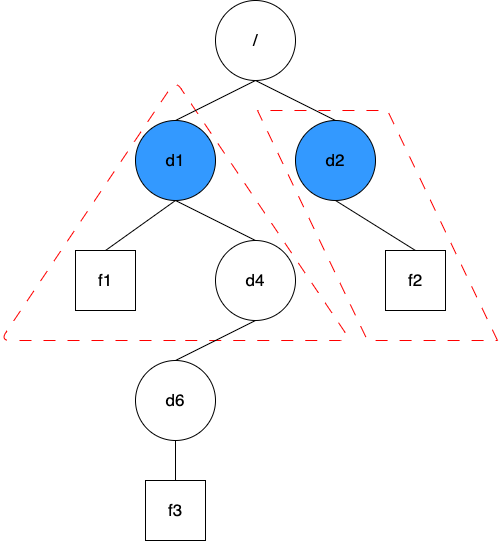
這個方案結合了前兩個方案的優點,並盡力避免了它們的缺點。在進一步說明前首先介紹兩個檔案系統中的現象:
-
在處理大部分後設資料請求時,其本身就帶有直接父目錄的資訊,因此不需要額外的操作去獲取,也不會引入額外的事務衝突
-
通常情況下,檔案系統中目錄數量會比普通檔案少 2 ~ 3 個數量級
基於上述兩點觀察,JuiceFS 實現了稱之為目錄統計的功能,即在平時就維護好每一個目錄下一級子項的統計量。當配額功能需要使用遞迴統計資訊時,無需遍歷所有檔案,而只需統計所有子目錄的使用量即可。這也是 JuiceFS 最終採用的方案。
另外,在加入了目錄統計功能後,我們還發現了一些額外的好處。比如原本就有的 juicefs info -r 命令,被用來代替 du 統計指定目錄下的使用總量;現在這個命令的執行速度又有了數量級上的提升。還有一個是新加的 juicefs summary 命令,它可用來快速分析指定目錄下的具體使用情況,如執行特定排序來找到已用容量最高的子目錄等。
04 其他功能 :配額修復
在上述的介紹中,我們已經知道 JuiceFS 在實現目錄配額時,為了追求穩定性和減少對效能的影響,在一定程度上犧牲了準確性。當用戶端程序異常退出,或目錄被頻繁移動時,配額資訊會有少量的丟失。隨著時間的推移,這可能導致儲存的配額統計值與實際情況出現較大的偏差。
因此,JuiceFS 還提供了 juicefs check 這個修復功能。它被用來重新掃描統計整棵目錄樹,並將結果與配額中儲存的值做比對。如果發現資料不匹配,系統會向您報告存在的問題,並提供可選的修復選項。
希望這篇內容能夠對你有一些幫助,如果有其他疑問歡迎加入 JuiceFS 社群與大家共同交流。