使用人工神經網路訓練手寫數位識別模型
2023-10-09 21:00:15
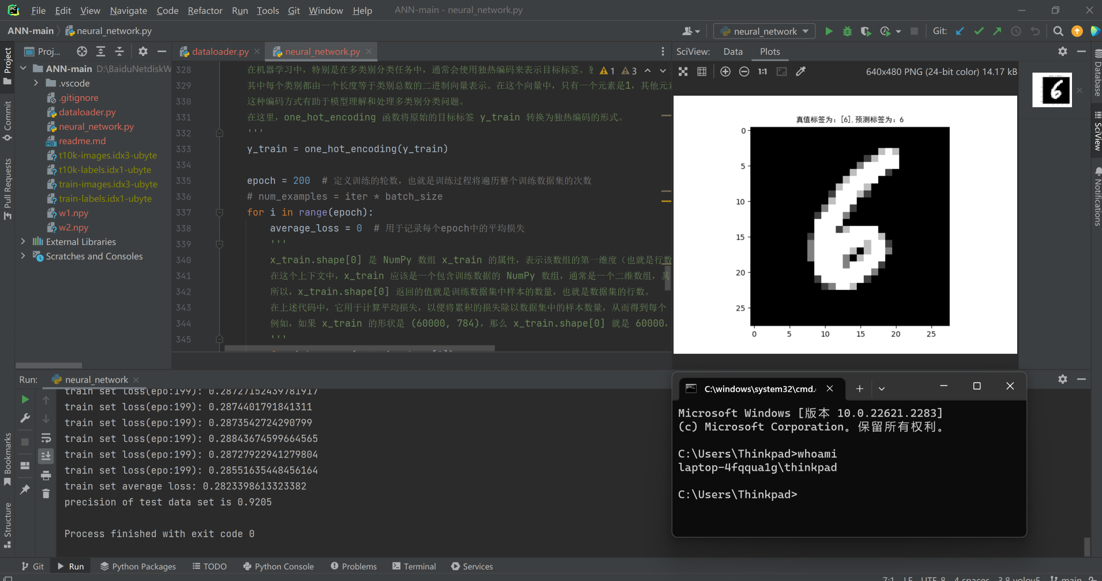
效果展示
下載專案
下載資料集(共四個)(上一步中已包含資料集,按需自己下載)

目錄結構
整體流程圖

dataloader.py
import numpy as np
import struct
import matplotlib.pyplot as plt
import os
# download the mnist dataset from http://yann.lecun.com/exdb/mnist/
# 讀取要訓練的資料集
def read_train_data(path=''):
with open(os.path.join(path, 'train-images.idx3-ubyte'), 'rb') as f1:
buf1 = f1.read()
with open(os.path.join(path, 'train-labels.idx1-ubyte'), 'rb') as f2:
buf2 = f2.read()
return buf1, buf2
# 讀取要測試的資料集
def read_test_data(path=''):
with open(os.path.join(path, 't10k-images.idx3-ubyte'), 'rb') as f1:
buf1 = f1.read()
with open(os.path.join(path, 't10k-labels.idx1-ubyte'), 'rb') as f2:
buf2 = f2.read()
return buf1, buf2
# 得到圖片資料
def get_image(buf1):
image_index = 0
'''
struct.calcsize('>IIII') 是Python中用於計算二進位制資料格式字串的大小的函數呼叫
它描述了一個包含四個大端位元組序的無符號整數的資料結構的大小
'''
image_index += struct.calcsize('>IIII')
img_num = int((len(buf1) - 16) / 784)
im = []
for i in range(img_num):
temp = list(struct.unpack_from('>784B', buf1, image_index)) # '>784B'的意思就是用大端法讀取784個unsigned byte
im.append(temp)
image_index += struct.calcsize('>784B') # 每次增加784B
im = np.array(im, dtype=np.float32) # 將圖片作為資料來源傳入numpy陣列
return im
# 得到標籤資料
def get_label(buf2):
label_index = 0
'''
用於計算二進位制資料格式字串的大小的函數
'>II' 是格式字串,它描述了要打包或解包的資料結構。
在這個格式字串中,> 表示使用大端位元組序(big-endian),
I 表示一個無符號整數(unsigned int)。
'''
label_index += struct.calcsize('>II')
idx_num = int(len(buf2) - 8)
labels = []
for i in range(idx_num):
temp = list(struct.unpack_from('>1B', buf2, label_index))
labels.append(temp)
label_index += 1
labels = np.array(labels, dtype=int) # 將標籤作為資料來源傳入numpy陣列
return labels
# 載入訓練資料
def load_train_data(path=''):
img_buf, label_buf = read_train_data(path)
imgs = get_image(img_buf)
labels = get_label(label_buf)
return imgs, labels
# 載入測試資料
def load_test_data(path=''):
img_buf, label_buf = read_test_data(path)
imgs = get_image(img_buf) # 得到圖片資料
labels = get_label(label_buf) # 得到標籤資料
return imgs, labels
if __name__ == "__main__":
imgs, labels = load_test_data()
for i in range(9):
# 將整個影象視窗分為3行3列
plt.subplot(3, 3, i + 1)
# 設定視窗的標題
title = u"標籤對應為:" + str(labels[i])
# 顯示視窗的標題
plt.title(title, fontproperties='SimHei')
# 將讀取的圖片資料來源改成28x28的大小
img = np.array(imgs[i]).reshape((28, 28))
# cmap引數: 為調整顯示顏色 gray為黑白色,加_r取反為白黑色
plt.imshow(img, cmap='gray')
plt.show()
neural_network.py
import numpy as np
import os
import dataloader as dl # 匯入資料載入器模組
import random
import argparse # 匯入命令列引數解析模組
import matplotlib.pyplot as plt
# 建立解析器
parser = argparse.ArgumentParser()
# 新增引數
# --data_path 的預設引數為 ’./‘ 即當前路徑
parser.add_argument('--data_path', type=str, default='./')
# 解析引數
args = parser.parse_args()
# 載入引數
data_path = args.data_path
# 啟用函數
class Sigmoid(object):
def __init__(self):
self.gradient = []
def forward(self, x):
"""
Sigmoid啟用函數的前向傳播函數。
Args:
x (numpy.ndarray): 輸入資料。
Returns:
numpy.ndarray: 經過Sigmoid啟用後的資料。
"""
self.gradient = x * (1.0 - x)
return 1.0 / (1.0 + np.exp(-x))
def backward(self):
"""
Sigmoid啟用函數的反向傳播函數。
Returns:
numpy.ndarray: 梯度。
"""
return self.gradient
# ReLU啟用函數
class ReLU(object):
def __init__(self):
self.gradient = []
def forward(self, input_data):
"""
ReLU啟用函數的前向傳播函數。
Args:
input_data (numpy.ndarray): 輸入資料。
Returns:
numpy.ndarray: 經過ReLU啟用後的資料。
"""
extend_input = input_data
self.gradient = np.where(input_data >= 0, 1, 0.001)
self.gradient = self.gradient[:, None]
input_data[input_data < 0] = 0.01 * input_data[input_data < 0]
return input_data
def backward(self):
"""
ReLU啟用函數的反向傳播函數。
Returns:
numpy.ndarray: 梯度。
"""
return self.gradient
def softmax(input_data):
"""
softmax函數用於將輸入資料轉化為概率分佈。
Args:
input_data (numpy.ndarray): 輸入資料。
Returns:
numpy.ndarray: 經過Softmax處理後的概率分佈。
"""
# 減去最大值防止softmax上下溢位
input_max = np.max(input_data)
input_data -= input_max
input_data = np.exp(input_data)
exp_sum = np.sum(input_data)
input_data /= exp_sum
return input_data
# 全連線
class FullyConnectedLayer(object):
def __init__(self, input_size, output_size, learning_rate=0.01):
self._w = np.random.randn(input_size * output_size) / np.sqrt(input_size * output_size)
self._w = np.reshape(self._w, (input_size, output_size))
b = np.zeros((1, output_size), dtype=np.float32)
self._w = np.concatenate((self._w, b), axis=0)
self._w = self._w.astype(np.float32)
# self._w = np.ones((input_size + 1, output_size), dtype=np.float32)
self.lr = learning_rate
self.gradient = np.zeros((input_size + 1, output_size), dtype=np.float32)
self.w_gradient = []
self.input = []
def forward(self, input_data):
"""
全連線層的前向傳播函數。
Args:
input_data (numpy.ndarray): 輸入資料。
Returns:
numpy.ndarray: 前向傳播結果。
"""
# 將b加入w矩陣
input_data = np.append(input_data, [1.0], axis=0)
input_data = input_data.astype(np.float32)
# 計算線性乘積
output_data = np.dot(input_data.T, self._w)
# 儲存輸入資料以計算梯度
self.input = input_data
# 更新梯度
self.gradient = self._w
self.w_gradient = input_data
return output_data
def backward(self):
"""
全連線層的反向傳播函數。
Returns:
numpy.ndarray: 梯度。
"""
return self._w[:-1, :]
def update(self, delta_grad):
"""
更新權重引數的函數。
Args:
delta_grad (numpy.ndarray): 更新的梯度。
"""
self.input = self.input[:, None]
self._w -= self.lr * np.matmul(self.input, delta_grad)
def get_w(self):
"""
獲取權重引數的函數。
Returns:
numpy.ndarray: 權重引數。
"""
return self._w
def set_w(self, w):
"""
設定權重引數的函數。
Args:
w (numpy.ndarray): 要設定的權重引數。
"""
self._w = w
# 交叉熵損失函數
class CrossEntropyWithLogit(object):
def __init__(self):
self.gradient = []
def calculate_loss(self, input_data, y_gt):
"""
計算交叉熵損失函數。
Args:
input_data (numpy.ndarray): 輸入資料。
y_gt (numpy.ndarray): 真實標籤。
Returns:
float: 損失值。
"""
input_data = softmax(input_data)
# 交叉熵公式 -sum(yi*logP(i))
loss = -np.sum(y_gt * np.log(input_data + 1e-5))
# 計算梯度
self.gradient = input_data - y_gt
return loss
def predict(self, input_data):
"""
預測函數,返回預測的類別。
Args:
input_data (numpy.ndarray): 輸入資料。
Returns:
int: 預測的類別。
"""
# input_data = softmax(input_data)
return np.argmax(input_data)
def backward(self):
"""
交叉熵損失函數的反向傳播函數。
Returns:
numpy.ndarray: 梯度。
"""
return self.gradient.T
# MNIST神經網路模型
class MNISTNet(object):
def __init__(self):
self.linear_layer1 = FullyConnectedLayer(28 * 28, 128)
self.linear_layer2 = FullyConnectedLayer(128, 10)
self.relu1 = ReLU()
self.relu2 = ReLU()
self.loss = CrossEntropyWithLogit()
def train(self, x, y):
"""
訓練函數,包括前向傳播和反向傳播。
Args:
x (numpy.ndarray): 輸入資料。
y (numpy.ndarray): 真實標籤。
Returns:
float: 損失值。
"""
# 前向傳播
x = self.linear_layer1.forward(x)
x = self.relu1.forward(x)
x = self.linear_layer2.forward(x)
x = self.relu2.forward(x)
loss = self.loss.calculate_loss(x, y)
# print("loss:{}".format(loss))
# 反向傳播
loss_grad = self.loss.backward()
relu2_grad = self.relu2.backward()
layer2_grad = self.linear_layer2.backward()
grads = np.multiply(loss_grad, relu2_grad)
self.linear_layer2.update(grads.T)
grads = layer2_grad.dot(grads)
relu1_grad = self.relu1.backward()
grads = np.multiply(relu1_grad, grads)
self.linear_layer1.update(grads.T)
return loss
def predict(self, x):
"""
預測函數,返回預測的類別。
Args:
x (numpy.ndarray): 輸入資料。
Returns:
int: 預測的類別。
"""
# 前向傳播
x = self.linear_layer1.forward(x)
x = self.relu1.forward(x)
x = self.linear_layer2.forward(x)
x = self.relu2.forward(x)
number_index = self.loss.predict(x)
return number_index
def save(self, path='.', w1_name='w1', w2_name='w2'):
"""
儲存權重引數到檔案。
Args:
path (str): 儲存路徑。
w1_name (str): 第一個權重引數檔名。
w2_name (str): 第二個權重引數檔名。
"""
w1 = self.linear_layer1.get_w()
w2 = self.linear_layer2.get_w()
np.save(os.path.join(path, w1_name), w1)
np.save(os.path.join(path, w2_name), w2)
def evaluate(self, x, y):
"""
評估函數,判斷預測是否正確。
Args:
x (numpy.ndarray): 輸入資料。
y (numpy.ndarray): 真實標籤。
Returns:
bool: 預測是否正確。
"""
if y == self.predict(x):
return True
else:
return False
def load_param(self, path=""):
"""
載入權重引數。
Args:
path (str): 引數檔案路徑。
"""
w1 = np.load(os.path.join(path, 'w1.npy'))
w2 = np.load(os.path.join(path, 'w2.npy'))
self.linear_layer1.set_w(w1)
self.linear_layer2.set_w(w2)
def one_hot_encoding(y):
one_hot_y = np.eye(10)[y]
return one_hot_y
def train_net(data_path=''):
"""
訓練神經網路模型。
Args:
data_path (str): 資料路徑,預設為當前路徑。
"""
m_net = MNISTNet()
x_train, y_train = dl.load_train_data(data_path)
'''
這行程式碼執行了以下兩個步驟:
1、歸一化:將輸入資料中的每個畫素值除以255。這是因為MNIST資料集中的畫素值範圍是0到255,通過將它們除以255,
將它們縮放到了0到1之間。這種歸一化有助於神經網路的訓練,因為它將輸入資料的值範圍對映到了一個更小的區間,有助於加速訓練過程。
2、中心化:從每個畫素值中減去0.5。這意味著將所有畫素值的平均值平移到0附近。
這個步驟有助於訓練過程中的數值穩定性,通常在輸入資料的均值不為0時進行中心化。
綜合起來,這行程式碼的目的是將原始的畫素值轉換為一個均值接近0、範圍在-0.5到0.5之間的歸一化值,
以更好地滿足神經網路的訓練需求。這是神經網路中常見的資料預處理步驟之一。
'''
x_train = x_train / 255 - 0.5
'''
將目標標籤(或類別)進行獨熱編碼(One-Hot Encoding)的操作。這是為了適應多類別分類問題的標籤表示方式。
在機器學習中,特別是在多類別分類任務中,通常會使用獨熱編碼來表示目標標籤。獨熱編碼是一種二進位制編碼方式,
其中每個類別都由一個長度等於類別總數的二進位制向量表示。在這個向量中,只有一個元素是1,其他元素都是0,用來表示樣本所屬的類別。
這種編碼方式有助於模型理解和處理多類別分類問題。
在這裡,one_hot_encoding 函數將原始的目標標籤 y_train 轉換為獨熱編碼的形式。
'''
y_train = one_hot_encoding(y_train)
epoch = 200 # 定義訓練的輪數,也就是訓練過程將遍歷整個訓練資料集的次數
# num_examples = iter * batch_size
for i in range(epoch):
average_loss = 0 # 用於記錄每個epoch中的平均損失
'''
x_train.shape[0] 是 NumPy 陣列 x_train 的屬性,表示該陣列的第一維度(也就是行數)。
在這個上下文中,x_train 應該是一個包含訓練資料的 NumPy 陣列,通常是一個二維陣列,其中每一行代表一個訓練樣本,而每一列代表該樣本的特徵。
所以,x_train.shape[0] 返回的值就是訓練資料集中樣本的數量,也就是資料集的行數。
在上述程式碼中,它用於計算平均損失,以便將累積的損失除以資料集中的樣本數量,從而得到每個 epoch 的平均損失。
例如,如果 x_train 的形狀是 (60000, 784),那麼 x_train.shape[0] 就是 60000,表示資料集中有 60000 個訓練樣本。
'''
for j in range(x_train.shape[0]):
# 遍歷訓練資料集中的每個樣本
# 計算並累加損失,同時更新模型引數
average_loss += m_net.train(x_train[j], y_train[j])
# 列印每2000個樣本的訓練損失,以便實時監視模型的訓練進度。
if j % 2000 == 0:
print('train set loss(epo:{}): {}'.format(i, average_loss / (j + 1)))
# 列印每個epoch的平均損失
print('train set average loss: {}'.format(average_loss / x_train.shape[0]))
# 儲存模型引數,通常在每個epoch結束後儲存,以便稍後使用
m_net.save()
def eval_net(path=""):
"""
評估神經網路模型。
計算在測試資料集上的分類準確度(precision)或召回率(recall)
載入訓練好的神經網路模型,在測試資料集上進行分類預測,並計算模型的分類準確度,以評估模型在新資料上的效能。
Args:
path (str): 引數檔案路徑。
"""
x_test, y_test = dl.load_test_data(path)
'''
這行程式碼執行了以下兩個步驟:
1、歸一化:將輸入資料中的每個畫素值除以255。這是因為MNIST資料集中的畫素值範圍是0到255,通過將它們除以255,
將它們縮放到了0到1之間。這種歸一化有助於神經網路的訓練,因為它將輸入資料的值範圍對映到了一個更小的區間,有助於加速訓練過程。
2、中心化:從每個畫素值中減去0.5。這意味著將所有畫素值的平均值平移到0附近。
這個步驟有助於訓練過程中的數值穩定性,通常在輸入資料的均值不為0時進行中心化。
綜合起來,這行程式碼的目的是將原始的畫素值轉換為一個均值接近0、範圍在-0.5到0.5之間的歸一化值,
以更好地滿足神經網路的訓練需求。這是神經網路中常見的資料預處理步驟之一。
'''
x_test = x_test / 255.0 - 0.5
precision = 0 # 初始化一個變數 precision 為0,用於計算分類準確度。
m_net = MNISTNet() # 建立一個新的神經網路模型 m_net,這個模型是用於在測試資料集上進行分類預測的。
m_net.load_param() # 載入之前訓練好的神經網路模型的引數。這些引數包含了模型在訓練資料上學到的權重和偏差。
for i in range(x_test.shape[0]): # 遍歷測試資料集中的每個樣本。
'''
對當前測試樣本進行分類預測,並與真實標籤 y_test[i] 進行比較。
如果模型的預測結果與真實標籤一致,表示分類正確,執行下面的程式碼塊。
'''
if m_net.evaluate(x_test[i], y_test[i]):
precision += 1 # 如果分類正確,將 precision 值加1,用於統計正確分類的樣本數量。
precision /= len(x_test) # 計算分類準確度。它將正確分類的樣本數量除以測試資料集的總樣本數量,從而得到分類準確度。
# 通常,分類準確度是一個在0到1之間的值,表示模型在測試資料上的效能。
print('precision of test data set is {}'.format(precision))
def visualize(path):
"""
視覺化函數,用於展示模型預測結果。
Args:
path (str): 引數檔案路徑。
"""
# 載入測試資料
x, y_gt = dl.load_test_data(path)
# 資料預處理:將畫素值歸一化到[-0.5, 0.5]範圍
x_imput = x / 255.0 - 0.5
# 建立一個新的神經網路模型
m_net = MNISTNet()
# 載入之前訓練好的模型引數
m_net.load_param()
# 隨機選擇一個測試樣本的索引
visualize_idx = random.randint(0, x.shape[0] - 1)
# 使用模型對選定的測試樣本進行預測
y_pred = m_net.predict(x_imput[visualize_idx])
# 建立一個繪圖區域,並顯示影象和標籤資訊
plt.subplot(111)
title = "真值標籤為:{},""預測標籤為:{}".format(y_gt[visualize_idx], y_pred)
plt.title(title, fontproperties='SimHei')
# 將測試樣本的影象轉換成視覺化的形式,並顯示在圖中
img = np.array(x[visualize_idx]).reshape((28, 28))
# cmap引數: 為調整顯示顏色 gray為黑白色,加_r取反為白黑色
plt.imshow(img, cmap='gray')
# 顯示影象
plt.show()
"""
這三個函數一起構成了神經網路的訓練、評估和視覺化過程,能夠訓練模型、評估其效能並視覺化模型的預測結果。
"""
if __name__ == '__main__':
'''
train_net() 函數的作用是訓練神經網路模型。
它通過多次迭代訓練資料集中的樣本,使用反向傳播演演算法來更新神經網路的權重和引數,以最小化損失函數。
在訓練過程中,模型逐漸調整自己以提高對訓練資料的擬合。訓練完成後,模型的引數將儲存在檔案中,以備將來使用。
'''
train_net()
'''
eval_net() 函數的作用是評估訓練好的神經網路模型在測試資料集上的效能。
它會載入之前訓練好的模型引數,並使用這些引數來進行測試資料集上的預測。
然後,它會計算模型在測試資料集上的精度或其他效能指標,並列印出來,以衡量模型的效能。
'''
eval_net()
'''
visualize(args.data_path) 函數的作用是視覺化神經網路模型的預測結果。
它會載入訓練好的模型引數,並隨機選擇一個測試樣本,然後使用模型對該樣本進行預測。
最後,它會顯示該樣本的真實標籤和模型的預測標籤,以及樣本的影象,以幫助視覺化模型的效能。
'''
visualize(args.data_path)