Java爬蟲實戰系列2——動手寫爬蟲初體驗
在上面的章節中,我們介紹了幾個目前比較活躍的Java爬蟲框架。在今天的章節中,我們會參考開源爬蟲框架,開發我們自己的Java爬蟲軟體。
首先,我們下載本章節要使用到的原始碼,本章節主要提供了基於HTTPClient和WebDriver兩種方式的資料抓取器。在執行該庫之前,我們還需要準備一下我們的開發環境。
首先,我要給大家介紹一下Selenium webdriver這個開源元件,Selenium是一個用於Web應用程式測試的工具。Selenium測試直接執行在瀏覽器中,就像真正的使用者在操作一樣。支援的瀏覽器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。Selenium webdriver是程式語言和瀏覽器之間的通訊工具,它的工作流程如下圖所示。
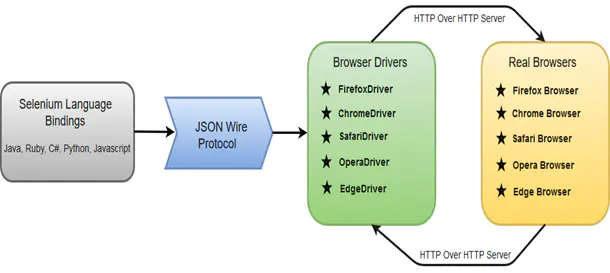
我們這裡選擇的是chrome瀏覽器,在正式開始編寫程式碼之前,我們需要安裝兩個重要的程式,一個是chromedriver,一個是chrome。
chrome瀏覽器的下載地址:https://chrome.en.softonic.com/
chromedriver的下載地址:http://chromedriver.storage.googleapis.com/index.html
注意:在安裝這兩個軟體的時候,它們的版本需要對應起來才能正常工作。
下面的UML類圖是我們本章節所使用程式的主要類結構。

例1:建立HTTP採集器和WebDriver採集器,存取URL,列印網頁內容
Page page = new Page("http://www.oracle.com/");
//建立基於httpclient的網頁內容採集器
IHttpFetcher httpFetcher = new DefaultHttpFetcher();
httpFetcher.fetch(page);
String htmlContentStr = new String(page.getContentData());
System.out.println(htmlContentStr);
//建立基於webdriver的網頁內容採集器
httpFetcher = new WebDriverHttpFetcher();
httpFetcher.fetch(page);
htmlContentStr = new String(page.getContentData());
System.out.println(htmlContentStr);
上面的例子中分別建立了兩個HttpFetcher,一個是基於httpclient的網頁內容採集器DefaultHttpFetcher,另一個是基於webdriver的網頁內容採集器WebDriverHttpFetcher。WebDriverHttpFetcher相對於DefaultHttpFetcher的主要優勢在於WebDriverHttpFetcher可以捕獲非同步載入內容的網頁詳情。
例2:利用XPath表示式獲取網頁指定元素
XPath(XML Path) 是一個表示式,用於查詢XML檔案中的元素或節點。在網路爬蟲中,它通常用於查詢Web元素。對於XPath表示式的具體語法,可以自行查閱。
Page page = new Page("http://www.bing.com");
IHttpFetcher httpFetcher = new WebDriverHttpFetcher();
httpFetcher.fetch(page);
String htmlContentStr = new String(page.getContentData());
Document document = Jsoup.parse(htmlContentStr);
Element element = XSoupUtil.getCombineElement("//*[@id=\"sb_form_q\"]", document, "http://www.bing.com");
上面的例子建立了WebDriverHttpFetcher來存取bing.com,使用XPath表示式定位了bing.com頁面上面的搜尋輸入框元素。
例3:模擬輸入框內容填寫和按鈕點選
Page page = new Page("http://www.bing.com");
WebDriverHttpFetcher httpFetcher = new WebDriverHttpFetcher();
WebDriver webDriver = httpFetcher.getWebDriver();
webDriver.get(page.getUrl());
Thread.sleep(2000);
WebElement element = webDriver.findElement(By.xpath("//*[@id=\"sb_form_q\"]"));
element.sendKeys("網路爬蟲");
element = webDriver.findElement(By.xpath("//*[@id=\"search_icon\"]"));
element.click();
Thread.sleep(2000);
System.out.println(webDriver.getPageSource());
在這個例子裡面我們利用Selenium WebDriver獲取到必應搜尋引擎的搜尋輸入框和搜尋按鈕,並且實現了輸入框內容的填充和搜尋按鈕的模擬點選功能。
Selenium WebDriver主要是通過元素定位器來操作網頁上面的各個元素,只有我們定位到了元素的位置,我們才可能進一步對其進行操作。
Selenium WebDriver主要使用「findElement(By.locator())」方法來查詢頁面上面的元素。如果頁面上面存在定位器指定的元素,該方法會返回一個WebElement物件。
Selenium WebDriver共支援8種元素定位器,除了我們上面使用的Xpath定位器外,還可以使用ID,Name,TagName,CSS等多種元素選擇定位器。
例4:採集IFrame元素中的資料
IFrame是可以將一個頁面的內容嵌入到另一個頁面中的容器,在使用Selenium WebDriver定位和採集元素資料之前,我們需要先將WebDriver切換到對應的IFrame容器下才可以。首先我們看一個使用IFrame容器的網頁範例。該網頁的IFrame容器巢狀關係如下圖所示:
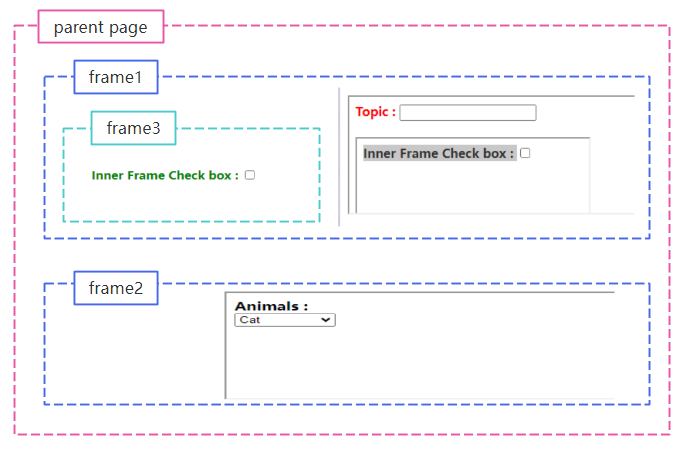
在本例中,我們將使用爬蟲技術來選中frame3容器中的checkbox核取方塊。
Page page = new Page("https://chercher.tech/practice/frames");
WebDriverHttpFetcher httpFetcher = new WebDriverHttpFetcher();
WebDriver webDriver = httpFetcher.getWebDriver();
webDriver.get(page.getUrl());
Thread.sleep(2000);
WebElement iframe = webDriver.findElement(By.id("frame1"));
webDriver = webDriver.switchTo().frame(iframe);
iframe = webDriver.findElement(By.id("frame3"));
webDriver = webDriver.switchTo().frame(iframe);
WebElement checkBox = webDriver.findElement(By.id("a"));
checkBox.click();
webDriver.quit();
例5:使用更加優雅的等待方式
目前,大部分的網頁內容都是通過Ajax或者JavaScript非同步載入的。這樣,當用戶在瀏覽器中開啟一個網頁的時候,使用者想要互動的網頁元素可能會在不同的時間間隔內載入出來。在之前的例子中,我們簡單使用了Thread.sleep()這種方式來等待固定的時間。實際上,這種方式有個弊端:網頁載入的速度受到網路質量,伺服器狀態等多因素的影響,網頁內容的載入速度很難準確評估。如果等待時間短了,使用者想要的網頁元素可能還沒有載入完成。如果等待時間設定很長,則會降低資料採集的速度。在Selenium WebDriver中,等待方式可以分為顯示等待和隱式等待兩類。具體情況看下圖:
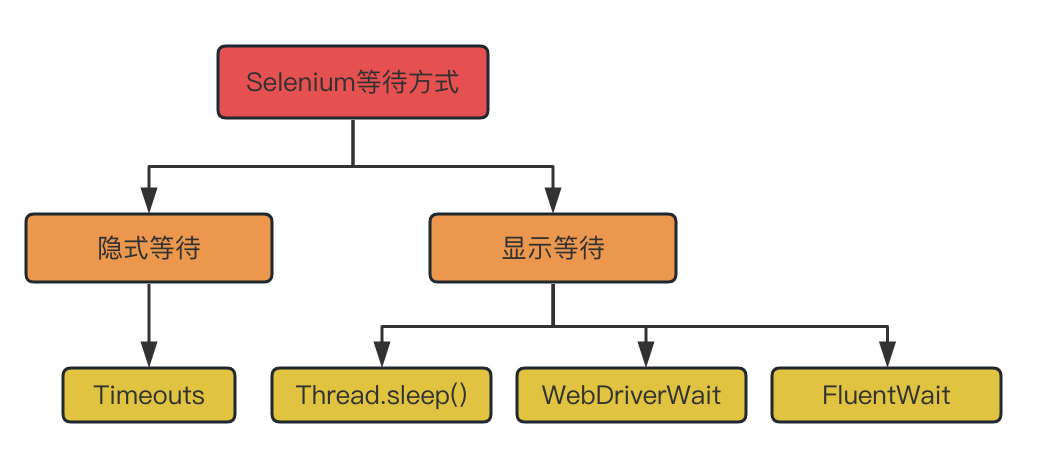
隱式等待(ImplicitWait)通常用於全域性的等待設定,設定成功以後接下來的Selenium命令執行時候如果無法立即獲取到目標元素,那麼它會等待一段時間後再丟擲NoSuchElementException異常。讓我們看一個隱式等待的例子:
Page page = new Page("http://www.bing.com");
WebDriverHttpFetcher httpFetcher = new WebDriverHttpFetcher();
ChromeDriver webDriver = (ChromeDriver)httpFetcher.getWebDriver();
webDriver.manage().timeouts().implicitlyWait(Duration.ofSeconds(2));
webDriver.get(page.getUrl());
WebElement element = webDriver.findElement(By.xpath("//*[@id=\"sb_form_q\"]"));
element.sendKeys("網路爬蟲");
element = webDriver.findElement(By.xpath("//*[@id=\"search_icon\"]"));
element.click();
webDriver.quit();
相對於隱式等待,顯示等待可以設定更加合適的等待時間,Selenium框架提供了兩種顯示等待的方式,分別是WebDriverWait和FluentWait,首先我們來看一個WebDriverWait的應用範例。
Page page = new Page("http://www.bing.com");
WebDriverHttpFetcher httpFetcher = new WebDriverHttpFetcher();
ChromeDriver webDriver = (ChromeDriver)httpFetcher.getWebDriver();
WebDriverWait wait = new WebDriverWait(webDriver, Duration.ofSeconds(10));
webDriver.get(page.getUrl());
WebElement element = wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//*[@id=\"sb_form_q\"]")));
element.sendKeys("網路爬蟲");
element = wait.until(ExpectedConditions.elementToBeClickable(By.xpath("//*[@id=\"search_icon\"]")));
element.click();
webDriver.quit();
在使用WebDriverWait的時候我們需要手動建立一個WebDriverWait物件,並且設定我們需要等待的時間,WebDriverWait物件的until會幫助我們不斷輪詢我們期望的條件是否完成,輪詢時間間隔是500ms。WebDriverWait物件實際上繼承於FluentWait物件。如果我們直接使用Fluent物件,則可以有更加靈活的等待策略和輪詢時間間隔。可以假設這樣一個場景,我們希望獲取到頁面中的某個元素,但是這個元素並不是必須的,即使最終這個元素沒有載入成功也不影響我們接下來的處理流程。這個時候,FluentWait會是一個不錯的選擇。
例6:設定WebDriver引數
一般來講,當我們在使用Selenium WebDriver採集資料的時候,我們需要對WebDriver進行一些設定,例如:無痕模式,關閉彈窗,忽略SSL證書錯誤等等。在這個例子中,我們來看一看常用的ChromeDriver設定項,更多的設定資訊可以參考設定項列表。
ArrayList<String> arguments = Lists.newArrayList(
"--allow-running-insecure-content",
"--allow-insecure-localhost", //忽略SSL/TLS errors
"--disable-gpu", // 關閉GPU硬體加速
"--headless", //開啟無頭瀏覽器模式
"--window-size=1920,1050", //設定瀏覽器視窗大小
"--disable-blink-features=AutomationControlled",
"--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36", //自定義user-agent名稱
"--cache-control=no-cache");
ChromeOptions options = new ChromeOptions();
options.addArguments(arguments);
例7:Selenium WebDriver設定自定義請求頭(custom headers)
很多的時候,我們在採集資料的時候需要設定一些自定義的HTTP請求頭,例如:我們想指定對某個網站連結存取是從什麼地方跳轉過來的,我們就需要設定referrer header。但很遺憾的是Selenium WebDriver並沒有給我們提供設定HTTP請求頭的介面。
今天就給大家介紹一款可以設定自定義請求頭的利器BrowserMob Proxy(簡稱BMP)。它是一款開源軟體,它不僅可以用來監控網路通訊而且可以控制網路請求和響應的內容,它還可以將頁面內容載入的效能資料匯出到HAR檔案中以便開發者可以進一步分析優化自己的網站響應速度。CMP不僅可以作為一個獨立的代理伺服器工作,而且可以和Selenium框架結合在一起使用。因為CMP是基於Java語言開發的,所以它可以很方便地嵌入到我們的Java程式中。CMP的下載地址是:https://github.com/lightbody/browsermob-proxy。
在本例中,我們主要示範下如何使用BMP來設定HTTP請求頭,具體範例程式碼如下:
Page page = new Page("http://www.cnblogs.com/kaiblog/");
Map<String, String> headers = new HashMap<String, String>();
headers.put("Referer", "http://www.baidu.com/");
// start the proxy
BrowserMobProxy proxy = new BrowserMobProxyServer();
proxy.addHeaders(headers);
proxy.setMitmDisabled(true);
proxy.start(0);
// get the Selenium proxy object
Proxy seleniumProxy = ClientUtil.createSeleniumProxy(proxy);
// configure it to webdriver
WebDriver webDriver = WebDriverFactory.createWebDriver(seleniumProxy);
webDriver.get(page.getUrl());
webDriver.quit();
proxy.stop();
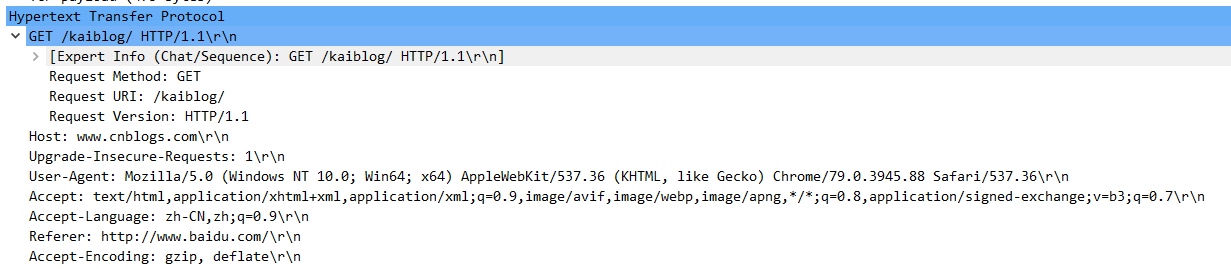
通過抓取網路封包我們可以看到Referer請求頭已經設定生效了。
總結
在本章節中,我們分別基於HttpClient和Selenium框架對網頁內容進行了採集,基於Selenium框架的採集器相對於基於HttpClient的採集器在採集動態網頁資料上面具有不小的優勢,也避免了對加密Javascript的逆向分析。但是這並意味著使用Selenium WebDriver去採集網頁內容就不會被目標網站發現了,使用Selenium WebDriver模擬驅動的瀏覽器與真實的瀏覽器在指紋特徵上面還是有諸多不同的,在下面的章節中,我們會進一步詳細介紹。