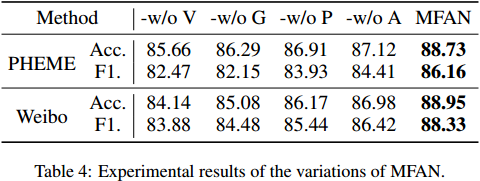
MFAN論文閱讀筆記(待復現)
論文標題:MFAN: Multi-modal Feature-enhanced Attention Networks for Rumor Detection
論文作者:Jiaqi Zheng, Xi Zhang, Sanchuan Guo, Quan Wang, Wenyu Zang, Yongdong Zhang
論文來源:IJCAI 2022
程式碼來源:Code
介紹
一系列基於深度神經網路融合文字和視覺特徵以產生多模態後表示的多媒體謠言檢測器被提出,其表現出比單獨使用文字資料更好的效能。然而,這些研究的一個共同侷限性是它們沒有同時考慮圖形社會背景,這已被證明有利於提高檢測效能。
源貼文的社會語境通常包括轉發使用者和相應的評論。基於這些實體和它們之間的聯絡,可以構造一個異構圖來建模結構資訊.然後,可以利用圖注意網路(GAT)和圖折積網路(GCN)等圖模型來聚合相鄰節點資訊,以獲得用於謠言檢測的更好的節點表示。
然而,現有的基於圖的檢測器存在以下幾個侷限性:
- 節點表示學習的質量高度依賴於實體之間的可靠連結。由於隱私問題或資料爬行的限制,可用的社交圖資料很可能缺乏實體之間的一些重要連結。因此,有必要對社交圖上的潛在連結進行補充,以實現更準確的檢測;
- 圖上相鄰節點之間可能存在各種潛在關係,而傳統的圖神經網路(GNN)鄰域聚集過程可能無法區分它們對目標節點表示的影響,導致效能較差;
- 如何將學習到的社交圖特徵與其他情態特徵(如視覺特徵)有效整合,目前的研究較少。
為解決上述挑戰,提出了一種新的多模態特徵增強注意網路(MFAN)用於多模態謠言檢測:
- 該網路可以有效地將文字、視覺和社交圖特徵結合在一個統一的框架中;
- 引入自監督損失來對齊不同檢視中的源後表示,以實現更好的多模態融合;
- 通過增強圖拓撲和鄰域聚合過程來改進社交圖的特徵學習;
- 本文的實驗表明,所提出的模型可以有效地識別謠言,並在兩個大規模的真實世界資料集上優於最先進的基線
相關工作
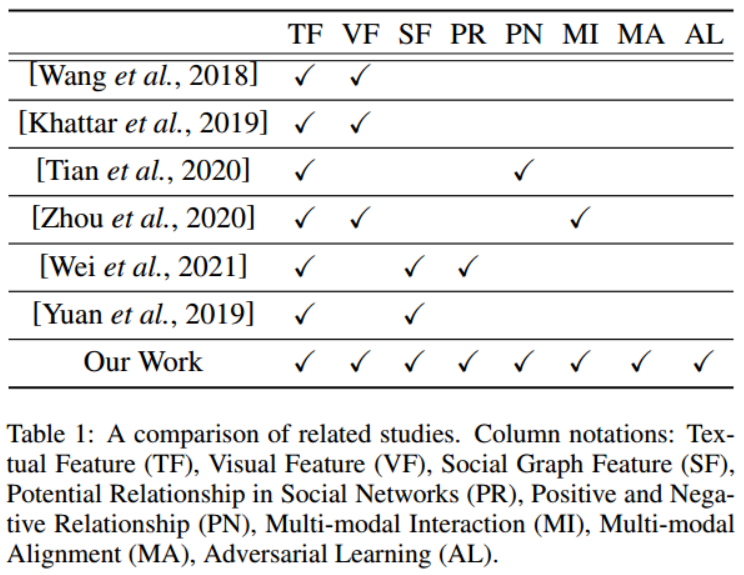
本文的工作與相關研究的比較見表1。本文工作的獨特之處在於:聯合使用文字、視覺和社會圖形特徵,涉及多模態對齊以更好地融合,並利用潛在的關係來增強圖形特徵。
問題定義
\(P= \{ p_1, p_2, ..., p_n \}\)為一組有文字有圖片的社交媒體多媒體貼文。
對於每個貼文\(p\in P\),\(p_i = \{ t_i, v_i, u_i, c_i \}\),其中\(t_i\),\(v_i\)和\(u_i\)分別表示釋出該貼文的文字,影象和使用者。\(c_i=\{ c_i^1, c_i^2, ..., c_i^j \}\)表示\(p_i\)的評論集,每條評論都是由相應的使用者\(u_i^j\)釋出的。
為了表示使用者在社交媒體上的行為,建立一個圖\(G = \{V, A, E\}\),其中\(V\)是節點的集合,包括使用者節點、評論節點和貼文節點。\(A\in \{ 0,1 \}^{|V|*|V|}\)是節點之間的鄰接矩陣,用來描述節點之間的關係,包括髮帖、評論、轉發。\(E\)是邊的集合。
將謠言檢測定義為一個二元分類任務。\(Y\in \{0,1\}\)表示類別標籤,其中\(Y = 1\)表示謠言,否則\(Y = 0\)。目標是學習函數\(F(p_i) = y\) 來預測給定貼文的標籤。
方法
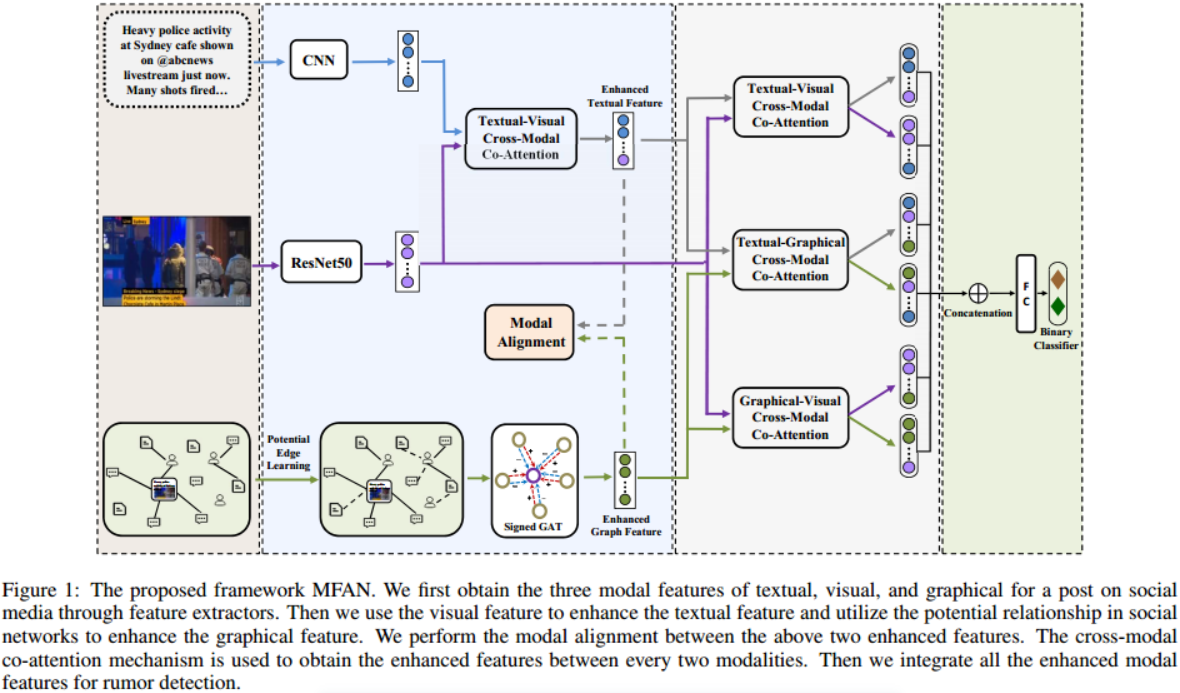
圖1:提出的框架MFAN。首先通過特徵提取器獲得社交媒體上一篇文章的文字、視覺和圖形三種模態特徵。然後利用視覺特徵增強文字特徵,利用社群網路中的潛在關係增強圖形特徵。在上述兩個增強的特性之間執行模態對齊。採用跨模態共注意機制獲取每兩個模態之間的增強特徵。然後將所有增強的模態特徵整合到謠言檢測中。
概括:重點是有效地結合文字、視覺和社交圖特徵來改進謠言檢測。為此,首先提取三種型別的特徵。
為了產生更好的社交圖特徵,提出在GAT的基礎上對圖拓撲和聚合過程進行改進。然後,捕獲跨模態互動和對齊,以實現更好的多模態融合。最後,將增強的多模態特徵連線起來進行分類。本文還採用對抗訓練來提高魯棒性。整個體系結構如圖1所示。
文字和視覺特徵提取器
文字表示
用CNN和池化來提取句子的語意特徵。
首先對於每個貼文\(p_i\),將其問題\(t_i\)進行填充或截斷,使其具有相同數量的token,即\(L\):
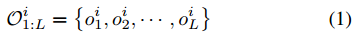
\(o_j^i\)表示 \(t_i\) 的第 \(j\) 個詞的詞嵌入。
然後,我們在詞嵌入矩陣\(O^i_{j:j+k−1}\)上應用折積層,得到特徵對映\(s^i_j\),其中\(k\)為接受野的大小。我們記為\(s^i=\{ s_{i1}, s_{i2},···,s_{i(L−k+1)}\}\)。然後,我們在\(s^i\)上使用max池,得到\(\hat{s^i}=max(s^i)\)。我們使用不同接受域\(k\in\{3,4,5\}\)的\(d/3\)濾波器來獲得不同粒度的語意特徵。
最後,我們將所有過濾器的輸出連線起來,形成\(t_i\)的整體文字特徵:
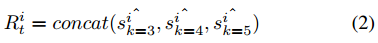
視覺(影象)表示
使用在ImageNet資料庫上訓練的預訓練模型ResNet50來提取影象\(v_i\)的特徵。
首先,我們提取ResNet50最後第二層的輸出,並將其表示為\(V^i_r\)。然後,我們將其通過一個全連通層,得到與文字特徵具有相同維數的最終視覺特徵,即
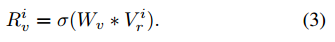
其中,\(W_v\)為全連通層的權矩陣,\(\sigma(·)\)為sigmoid等啟用函數。
增強的社交圖特徵學習
推斷隱藏關聯
為了緩解缺失連結的問題,提出在社群網路中推斷節點之間的隱藏關聯。
根據網路同質性,相似的節點可能比不相似的節點更容易相互連線。因此,我們計算不同節點之間的特徵相似度,並推斷相似度高的節點之間的聯絡。
具體來說,定義節點嵌入矩陣\(X\in \mathbb{R}^{|V|\times d}\)。
\(X\)中有三種型別的節點,我們使用句子向量作為貼文和評論節點的初始嵌入,並使用使用者釋出的貼文節點嵌入的平均值作為初始使用者嵌入。
然後利用餘弦相似度計算節點\(n_i\)和\(n_j\)之間的相關性\(\beta_{ij}\):
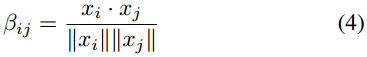
\(x_i\)和\(x_j\)是\(n_i\)和\(n_j\)的節點嵌入。
如果相似度大於0.5,則推斷它們之間存在一條潛在邊,即:
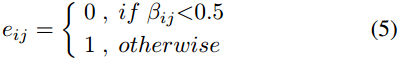
然後用推斷出的潛在邊對原始鄰接矩陣\(A\in \mathbb{R}^{|V|*|V|}\)進行增強。令\(a_{ij}\)為\(A\)的元素,\(a_{ij}=1\)表示\(n_i\)和\(n_j\)之間存在一條邊。則增強後:
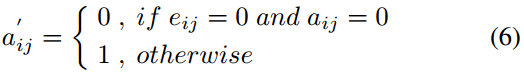
捕捉多方面的鄰居關係
使用GAT捕獲社會圖結構資訊。傳統的GAT不同,本文引入了符號注意機制來捕獲相鄰節點之間的正相關和負相關,以獲得更好的圖特徵。
GAT的關鍵是鄰域資訊的聚合。
對於節點\(n_i\)和其相鄰節點集合\(\mathcal{N}_i=\{ \acute{n_1}, \acute{n_2}, ..., \acute{n_{|\mathcal{N}_i|}} \}\),先計算節點\(n_i\)和其相鄰節點集合\(\mathcal{N}_i\)之間的注意力權重集合\(\xi_i=\{ \acute{e_{i1}}, \acute{e_{i2}}, ..., \acute{e_{i|\mathcal{N}_i|}} \}\):
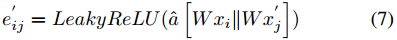
其中,\(||\)表示連線操作,\(\hat a\)和\(W\)是可學習的引數,\(x_i\)和\(\acute{x_j}\)是\(n_i\)和\(\acute{n_j}\)的節點嵌入,\(\acute{n_j}\in \mathcal{N}_i\)。
然後,使用softmax函數對注意力權值進行權值歸一化操作。
注意力權值可能出現負數(兩個節點向量方向相反),在使用softmax函數後這個值會變成一個很小的正值。
實際上,節點間的注意權值包含潛在的正、負關係,直接使用softmax函數會忽略。比如權值「-0.9」經過softmax函數後會變為0.09,但這種較大的負向關係也可能有利於謠言檢測。例如,它可以反映偽裝行為,如謠言傳播者購買一些誠實的使用者作為粉絲或評論反對源貼文,它們的節點向量可以本質上負相關。這正是現有的GATs所忽略的負相關關係。
為解決此問題,設計了符號注意力GAT,捕捉節點間的正負關係:
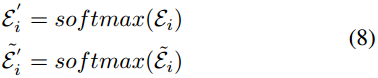
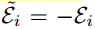
然後將兩個向量連線在一起,並通過一個全連線層來獲得最終的節點特徵。\(n_i\)的節點特徵為:
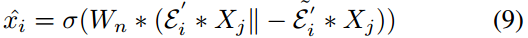
其中,\(W_n\)是全連線層的權值矩陣,\(\sigma(·)\)為啟用函數,\(X_j\)為\(\mathcal{N}_i\)的特徵矩陣。
圖特徵提取器
本節介紹如何在增強社交圖和符號GAT的基礎上獲得社交圖特徵。
首先,我們通過增加推斷的潛在邊來增強原始社交圖,並初始化圖中的三種節點型別。對於貼文和評論節點,我們使用它們的文字特徵作為初始嵌入。對於使用者節點,我們使用他們的貼文和評論嵌入的平均值作為初始嵌入來反映使用者特徵。
然後使用Signed GAT從增強的社交圖中提取圖結構特徵。對於每個節點,利用公式(9)更新其嵌入,得到更新後的節點嵌入矩陣\(\hat{X} \in \mathbb{R}^{|V| \times d}\)。
然後採用多頭注意機制從不同角度捕捉特徵。將每個head的更新節點嵌入連線在一起作為整體圖特徵:

其中\(H\)表示頭部的數量。那麼第\(i\)個貼文\(p_i\)的圖特徵\(R^i_g\)對應於\(\hat G\)的第\(i\)列。
多模態特徵融合
由於有三種型別的模態,本文采用了具有共同注意方法的分層融合模式。為了捕獲跨模態關係的不同方面並增強多模態特徵,本文使用自監督損失來強制跨模態對齊。
跨模態共同注意機制
使用共同注意機制來捕獲不同模態之間的相互資訊。它通過學習不同模態特徵之間的注意權值來增強跨模態特徵。
具體來說,對於每個模態,我們首先使用多頭自注意來增強模態內特徵表示。例如,對於文字特徵\(R^i_t\),分別用\(Q^i_t=R^i_tW^Q_t\),\(K^i_t=R^i_tW^K_t\),\(V^i_t=R^i_tW^V_t\)來計算其查詢矩陣、鍵矩陣和值矩陣。
然後,我們生成文字模態的多頭自注意特徵:
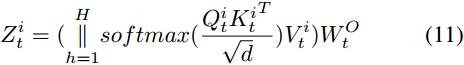
其中,\(W^O_t\)是輸出的線性變換。對\(R^i_v\)和\(R^i_g\)進行相同的操作得到\(Z^i_v\)和\(Z^i_g\)。
然後利用共注意機制生成增強的多模態特徵。具體來說,為了對\(p_i\)進行文字-視覺共注意,首先執行與上述自注意類似的操作,但將\(R^i_t\)替換為\(Z^i_v\),得到查詢矩陣\(Q^i_v\),將\(R^i_t\)替換為\(Z^i_t\),得到鍵矩陣\(K^i_t\)和值矩陣\(V^i_t\)。然後我們得到交叉模態增強特徵\(Z^i_{vt}\):
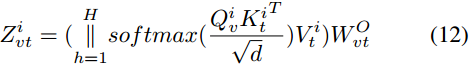
其中,\(W^O_{vt}\)是輸出的線性變換。
注意,\(Z^i_{vt}\)表示利用視覺特徵基於相關性得到的增強文字特徵。基於相同的共同注意過程,我們可以通過交換兩種模態在公式(12)中的作用,得到增強的視覺特徵。
多模態對齊
基於共同注意機制,我們可以獲得利用視覺特徵增強的文字特徵等。但對於原帖,其不同形式的表述應具有內在聯絡。這種模態之間的聯絡不包括在共同注意機制之內。因此,引入了多模態對齊,通過加強文章的增強文字特徵,使其接近增強的圖形特徵,以改進在每個模態中學習到的表示。
具體來說,對於貼文\(p_i\),其增強的圖特徵\(Z^i_g\)和增強的文字特徵\(Z^i_{vt}\)被變換到同一模態特徵空間:

其中,\(\acute{W_g}\)和\(\acute{W_t}\)是可學習的引數。
然後用模態對齊的MSE損失來縮小\(\acute{Z^i_g}\)和\(\acute{Z^i_t}\)的距離:
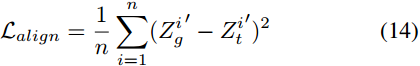
然後得到對齊的文字特徵\(\widetilde{Z^i_t}\)和圖形特徵\(\widetilde{Z^i_g}\),用於下面的多模態融合。
融合上述多模態特徵
再次對三個模態特徵對\(\widetilde{Z^i_t}\),\(\widetilde{Z^i_g}\)和\(Z^i_v\)執行上述的跨模態共注意機制,最終得到6個跨模態增強特徵:\(\widetilde{Z^i_{tv}}\),\(\widetilde{Z^i_{vt}}\),\widetilde{Zi_{gt}},\widetilde{Zi_{tg}},\widetilde{Zi_{gv}},\widetilde{Zi_{vg}}。然後將它們連線起來作為最終的多模態特徵:

對抗性訓練分類
將貼文\(p_i\)的最終多模態特徵\(Z^i\)輸入到全連線層中,預測\(p_i\)是否為謠言:
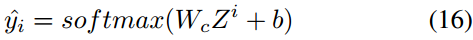
然後使用交叉熵損失函數:
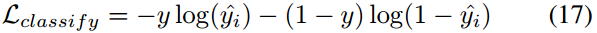
最終的損失可以表示成:
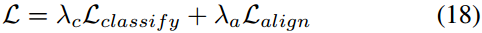
其中\(\lambda_c\)和\(\lambda_a\)用來平衡兩種損失。

由於社交媒體中的文字內容可能不遵循嚴格的語法規則,為了適應這種語法的不規則性,我們在文字嵌入層面新增了對抗性擾動,以增強模型的魯棒性。我們使用了PGD,這是一種廣泛使用的對抗性訓練方法。具體來說,我們在每次訓練迭代中計算文字特徵的梯度,並使用它來計算新增到文字特徵中的對抗性擾動。然後我們在更新後的文字特徵上重新計算梯度。我們重複這個過程\(k\)次,並使用球面空間來限制擾動的程度。最後,將上述對抗梯度累積到原始梯度,然後用於引數更新。
實驗